Curious to know if anyone has written programs for their own, regular, & personal use. And if so what they are? E.g. A colleague of mine tracks all of his homes energy use through a custom program which disaggregates the energy consumption per device and outputs a report to a tablet.
Hundreds! Doesn't everyone? Most of them are just bash scripts, many of which have now reached a complexity so high that I wish I'd started writing them in a different language but it's too late now. The majority of the rest are Python.
Off the top of my head, the most used ones are:
* A replacement front-end for "tar" and various compressors
* A script to synchronize my music library to a compressed version for playing in my car
* A secure-but-readable password generator
* A system to batch compress folders full of video files. (For ripped blu-ray discs, mostly.)
* A replacement front-end for "ffmpeg", see above
* A "sanity check" program for my internet connection to see if the problem is me, or Comcast
* A front-end for "rm" that shows a progress bar when deleting thousands of files. (Deletes on ZFS are unusually slow.)
> * A replacement front-end for "ffmpeg", see above
I have one of these too... It's kind of frightening how hard ffmpeg is to use without some kind of custom frontend. I have probably dozens of bash/python scripts to invoke ffmpeg for different common tasks.
- One to extract audio
- One to extract all the individual streams from a container
- A couple different transcoding scripts
- One specifically for gifs
- One to crop video
- A few that I can't remember the purpose of... and can't tell from reading the source
You could threaten to kill me and I wouldn't be able to user ffmpeg from memory. I just don't have to use it often enough. So I created a script w/ the settings I usually want to encode certain things that I need to encode semi-often. It definitely doesn't make it easier to remember ffmpeg command line options because I don't have to use them.
kubectl and our home grown command line tools to interact with our build and deployment? I know most of it by heart of course because I use it daily. I really don't like some of the scripts that we have and do it "by hand" instead because I have to use it all often enough that I want to know what is really going on underneath in case things don't go the way they should (and there's always something). I am able to diagnose and fix or work around all these issues with ease because of it, while lots of other people just run the wrapper scripts and if something doesn't work they very often aren't able to even troubleshoot the simplest problems. I'm that guy w/ ffmpeg ;)
I'm pretty sure you meant this in a different way but it reminded me of another thing I see a lot with people.
They have these huge lists (written down in some tool or another) of commands to do specific things and they copy and paste them. It's heart wrenching to see them search for these sometimes (even if they find them) and then they copy and paste them. But they sometimes (many times) don't work or are super simple things. Like the `kubectl get pod` thing I mentioned, they might have that in one of those lists under some heading like "dev environment commands" or somesuch together with 10 or 15 others.
Because they never actually tried to understand the simple logic and meaning behind these command line tools and only ever copy and pasted, they get very easily tripped up by even the simplest things, such as replacing the parts that need to be adjusted for their specific situation, even if clearly marked, such as `kubectl -n <yournamespace> get pod` (or one that comes up even more often in troubleshooting sessions 'The command from the docs does not work and I made sure I copy and paste so I don't mistype it' and if you ask what they did it was `kubectl -n examplenamespace get pod`). Or they might have written down a command from the onboarding docs that combined multiple things into one command line. To fix issues with their environment, they have to basically nuke everything and start from scratch, because only then will their copy and pasted command actually work. They haven't learned to decompose these and use the parts individually or recompose them.
I agree that keeping a cookbook of stuff pasted from the internet without knowing the fundamentals is an anti-pattern.
For me (and probably for GP), my cookbook is stuff that took me more than a few minutes of tinkering or reading manpages to figure out, and it’s stuff that I use maybe once every couple weeks — not often enough to memorize, and annoying if I have to figure it out again.
It’s the ‘wrong’ way to think about it in the sense of subjectivity : powerful in this context means lots of arguments and config settings you have to learn, memorize or look-up.
That means you have to become an expert level user to become fluent (where the user would call it “easy”)
It’s an UX that would exclude entry level computer user (since entry level here means not even knowing where the shell is for ffmpeg) and would perhaps be a barrier intermediate computer users.
ffmpeg arguments generally compose pretty well, although it's powerful enough that (as other comments have mentioned) for special use cases you do often have to look things up.
If you can remember 3 or 4 things you can do most stuff without looking anything up, however:
-i -> input file
-vcodec / -acodec -> video and audio codec; "copy" specifies copying the input stream
-vn / -an / -sn -> disable the video / audio / subtitles in the output file
-ss / -t -> specify the start time and length of the conversion from the input file
So, just by looking at the above, you can easily see how to extract audio (or any individual stream). For gifs specifically I would recommend using gifski which has much better results anyway. For cropping, I don't find the `-vf crop` syntax too bad.
But when you have differing behaviour based on argument position like putting -ss / -t before the -i or after (fast seek vs accurate seek), it gets confusing pretty fast.
I wrote one of those last week as a sort of poor man’s video editor. Besides aliases for common commands (like extracting a time range without re-encoding), it also takes the tedium out of repeatedly typing file names. Output file names are generated based on the input file name, with a prefix that auto-increments like sql. Input files can be referenced by prefix. It makes a huge difference.
I certainly have. Interestingly, one was the same "sanity check" program for my internet connection, because of the same ISP you mention. Amazing coincidence...I don't think. :-)
I ginned up a "wait for the internet to come back up" script that repeatedly pinged something with one packet, and used the Mac 'open' command to play an mp3 file once the ping succeeded. Unsexy, but when you can't google up a better solution...
I like this idea. Some company that I may or may not work for either does or does not install malware on our computers, extending the boot sequence and something in the network layer that makes it take MINUTES for anything http to be usable, even after the DE is loaded. Would love to add such a script to my login’s boot sequence
Chalk me up to that too. And my brother. Originally I'd used Ping Plotter. When I went 100% Linux I stopped using that. My brother ended up putting together a Grafana board tied to influxdb & infping and monitors several friend and family internet connections complete with alerts.
Here [0] is a screenshot of the Comcast cable connection from a year and a half ago. I have since switched to AT&T gigabit fiber. Here [1] is a screenshot from today.
I get more calls from users of my apps that have Comcast as the access provider than any other, and by far. The first thing I do when they have connection issues is check downdetector.com
I run a server that lets me receive calls wherever I am (SIP or forwarding, as required) and send messages. Like a self-hosted Google Voice but more flexible and with a greater choice of numbers + forwarding destinations.
All my server does is respond to HTTP requests from Twilio and send HTTP requests when I send a message.
Somewhere in the Twilio interface, you can define a SIP endpoint, but I forget where it is. That's enough for placing calls and does not require running a server.
Almost forgot to mention that I receive text notifications via pushover because I am not an Apple developer ... so no app for me.
It's cool that you do that, but "Doesn't everyone?" implies to me that you might be a bit out of touch. This is common among a certain type of person and unheard of for everybody else.
Yeah, that's the thing I think you imagine is true but actually isn't. I'd guess that the majority of HN readers don't do this, assuming they represent average technical employee across the industry. They probably _could_ if they needed to.. but I bet they don't. (Just based on my sample of: all the people I've worked with).
> I'd guess that the majority of HN readers don't do this, assuming they represent average technical employee across the industry.
That would be the disagreement then I think: you and him have different models of the majority HN reader. Based on my experience in the industry and on hn, I also don't think the typical hn commenter represents the average technical employee. Perhaps the typical hn reader does, but then I have a lot less information about that group.
I don't think it's right to say he's "out of touch" for an off the hand remark like that, even regardless of this discussion.
e: also, there is a poll option for hn posts, it might be interesting to find out more about who does/doesn't do this.
Yeah, I'm an engineer. I'd guess that neither I nor most of my coworkers do. It's much more common amongst lower-level engineers than, say, product engineers. Heck, I work full time in Python + Typescript and I don't even know Bash. I never even have things I want to script. Most of my time is spent making sense of code, not doing any sort of complicated repeatable task.
> A "sanity check" program for my internet connection to see if the problem is me, or Comcast
It's funny, I've never thought of doing this, but now realise it would be quite handy. Not just for connectivity but also some quick bandwidth/latency tests, and perhaps even a few basic internal network checks too.
The number of times I'm trying to troubleshoot Zoom calls these days... it would be handy to have a little bash script to run to rule out obvious issues.
For my specific use case, a big one would also be a quick automated check for whether my primary network connection is Wifi or Ethernet since I swap between the two and often forget which I'm currently using (which can impact connection quality if it's not the one I intended).
Looks pretty interesting! On my cursory glance it doesn't seem to by obvious what flavours of scripts it supports, other than the JS examples. Is it restricted to just Javascript?
I love pronounceable passwords, but there's research indicating that such generators typically produce lower than expected entropy. Do you mind sharing what algorithm you use?
The 84-bit number 10231239242746186561668573 can be represented as: ...
In 12-bit words of 5 letters or less: hits towel bloke gala blah jimmy barry
Diceware is good too.
A word of warning: be careful playing around with stochastic text generation if you're susceptible to delusions and hallucinations. You'd have to be pretty far gone to think "hits towel bloke gala blah jimmy barry" was a message from God, but of course we all know people who have fallen into that kind of belief, and the strain on credulity gets smaller as the text model gets more sophisticated.
Wouldn't a generator like this significantly increase risk of succumbing to dictionary attacks? I probably just don't understand part of what it's doing, but I'm curious.
It depends on what your baseline is. With knowledge of the generation algorithm, a dictionary attack on a password generated that way will definitely succeed, but on average it will take 2⁸³ tries (twice that at worst). At a billion tries per second this is 300 million years, almost long enough for the Sun to engulf the Earth if your attacker devotes only a single CPU to the task. There are commonly used password hashing algorithms that can only do a few hundred tries per second per CPU, which pushes the average success time to a quadrillion years, fifty thousand times the current age of the universe.
By contrast, trying every phrase of 20 words or less in every book that has ever been published would only take something like 129 million × 19 × 500,000 = 1.225 quadrillion tries. At a billion tries a second, that's only two weeks. (And if the password hash is inadequately salted, the attacker can use a rainbow table and put in that effort ahead of time and distribute it across all the victims.)
An attacker with more resources might devote a million CPUs to the problem, which would cut the time to success from 300 million years down to only 300 years (assuming a billion tries a second). In the next few decades it will become practical to devote much larger amounts of computation to problems like this, so such an attack might succeed, but currently it is beyond the capabilities of all but a few adversaries. And, as I understand it, Grover's algorithm will enable a large enough quantum computer to solve your password in only 2⁴² tries, which is only about four trillion tries, under an hour at the billion-tries-per-second speed I suggested above. I'm not sure, but I think it would need to prevent qubit decoherence for that period of time.
You can get equivalent security with a shorter password that looks like random gibberish, such as b7fc d750 9a52 ad6a e48c a, eedgckeimbjdefhcjclmghh, mgujdlrgdfmadtlidu, 1qvrx21zego0scvyi, 17uUPBKnfX7fSNY, >4h)&crV,+E{O, or 宜潨阰揫難侌, but those are a lot harder to memorize. They're shorter to type, though, and they're less vulnerable to side-channel attacks.
Looking random isn't good enough, though. They need to actually be random.
Please don't use $RANDOM or $((RANDOM)) or standard `shuf` for password generation. These RNGs are not cryptographically secure. Use input from /dev/urandom instead.
Modulo operations like these are another thing to avoid. To get equal chances for each word, the simplest thing to do is e.g.
do
wordlistlength = 10e3
randomnumber = os.urandom(1) * 256 + os.urandom(1)
while randomnumber > wordlistlength
return wordlist[randomnumber]
(Adjust if your list length is greater than 255×256+256, of course.)
Further, I see that cracklib-small is 52k words. That's not good or bad, but it makes the default 4-word phrase 52e3⁴ ~ 63 bits of entropy, which isn't terrible but in my opinion on the short side as a default. It will be perfectly fine if you only ever want to defend against online attacks, but in some cases (think disk encryption or password manager) offline cracking should be kept in mind and for the rest you should usually use a password manager anyhow (so then memorability doesn't matter).
Or perhaps more succinctly: please don't roll your own crypto.
I understand that this is of course very unlikely to be abused if it's just for yourself and nobody knows of this weakness in your credentials (security through obscurity works... until it doesn't), but one day someone will use this as inspiration or it will spread somehow, say through an HN comment... just use good password generators or at least keep insecure ones secret.
Btw: many standard Debian(-based) installations have /usr/share/dict/words available so you don't need an extra install; I haven't seen cracklib used before but that might just be me.
LCGs are multiply followed by add followed by modulus, which is usually implied by a mask or a native word bit length rolling over. You should observe that multiplies have patterns in the lower digits which an add will only offset, and the modulus will only throw away high bits rather than mix them back in to the low bits. Consider the low digit in multiples of 7 (what you'd get picking a number between 0 and 9 inclusive via modulus):
The lowest digit has the sequence 7418529630 repeating, which isn't very random. Modulus preserves low order bits and throws away the magnitude of the number. The result is that if you want to get half-decent low-valued random numbers from an LCG, you should take x/range * limit rather than %. You can do this with integer arithmetic via multiply and shift if you have an integer twice the size of your LCG.
But again, don't use an LCG for generating your password.
[1] I looked at the source. Bash looks like it tries to use random(3) if it's available, otherwise it seems to use this, which doesn't have an add:
Sometimes I use passages from books. Easy to remember a >60 char password, can always check the book and it brings back to memory a book that I enjoyed each time I use it. For PINs I like to use a long sequence of digits of a physical/mathematical constant.
From books? Having anything that's natural language will kill your entropy, way way below correct horse battery staple. Moreso if it's indexed by Google Ngrams.
Yes. But it’s much more dramatic in the movie when the villain runs his finger along the spines of the books in your library idly but then his eyes narrow and he aggressively pulls a book off the shelf and flips it open to a well worn spot. Checkmate!
Just FYI, if there is an incentive to get your password, there are existing programs to match arbitrary length strings from books or any text source. One such program has been used to steal cryptocurrency from wallets that are generated from a passphrase like NXT.
Look at diceware.com for a good way to do that. You can calculate the entropy without "research". I use a simple python script for the purpose, filtering out the words < 7 chars long from /usr/share/dict/words instead of bothering with the official diceware list. Example output: "snored-Hoff-virtue-tab-eroded-Perl's" with estimated 87 bits of entropy. If you write the phrase on a piece of paper and refer to the paper when typing the phrase into a computer, then after a few uses you will remember the phrase without any special memorization effort. At that point you can shred or burn the paper, or possibly record it in an offline encrypted file requiring its own security efforts.
Also take a look at the EFF’s wordlists [1] as an alternative to the Diceware list. Quoting from their blog post, here are some issues with the Diceware list that they have resolved:
- It contains many rare words such as buret, novo, vacuo
- It contains unusual proper names such as della, ervin, eaton, moran
- It contains a few strange letter sequences such as aaaa, ll, nbis
- It contains some words with punctuation such as ain't, don't, he'll
- It contains individual letters and non-word bigrams like tl, wq, zf
- It contains numbers and variants such as 46, 99 and 99th
- It contains many vulgar words
- Diceware passwords need spaces to be correctly decoded, e.g. in and put are in the list as well as input
I haven't seen those in a while now. For random sites you should use a password manager anyway though, not try to remember a thousand passphrases. You're going to end up reusing passwords if you try to memorize them all, or else you'll have to write some down and then you are already using a password manager :). Or you use a system and then 1-2 cracked passwords/-phrases will likely break them all.
Note that this advice is for the average, common site. If you have special considerations for your bank, broker, or similarly high-value sites, different advice might apply of course (but this is not really the place for that and there are already enough recommendations online).
For ages I remembered this as 'battery-horse-staple-correct' but then I see loads of people saying 'correct-battery-horse-staple' so now I think I'm the one who is wrong.
I wonder which way round is actually the right way to say it?
ok typo on my part... anyhoo - does "correct" go at the front or back?! Because the way I read it, the speech bubble saying 'correct' is after the horse and the other two words.
I always find those annoying to copy (we use a lot of shared credentials, like when the customer gives us 3 accounts with different permission levels to pentest an application with) and it also simplifies the command to not have to specify all those symbols. You can also avoid the whole `fold` thing by just telling `head` to give you a certain number of -c instead of a certain number of -n.
</dev/urandom tr -dc a-zA-Z0-9 | head -c 16
(Then again, you were proposing an alias, so then command complexity/memorability doesn't really matter.)
Security level: log((26+26+10)¹⁶)/log(2) ~ 2⁹⁵ (95 bits of entropy), comparable with adding those 12 extra symbols: log((26+26+10+12)¹⁶)/log(2) ~ 2⁹⁹. (Adding a character makes more sense than adding a symbol if you want more security, all else being equal of course.) If a stupid application still has outdated password requirements (thankfully this is rare among the applications I use) then one can of course add the classic ! at the end.
Right, I forget that it's not the default to print a \n as the first character of your PS1. Doesn't make sense to me that this isn't the default, as there are quite a few commands that might not end with a newline and then it messes up the prompt position, and it doesn't impact backwards compatibility to add it now.
Arch Linux. When using Zsh the last char is always a '%'. When using Bash it does no show a '%' but there's no line break. Possibly an weird interaction with my $PS1.
You can replace "cat /usr/share/dict |" in that invokation with "</usr/share/dict" and it will be equally easy to switch between tr and sed. Yes, you can put that redirection at the start, not just at the end of a command line. Although I admit I still haven't got used to doing it.
> Please don't use $RANDOM or $((RANDOM)) or standard `shuf` for password generation. These RNGs are not cryptographically secure. Use input from /dev/urandom instead.
When using shuf for cryptographic purposes, I'd first check if it advertises as being able to be a secure cryptographic token generator when provided with a secure random source. It might very well use modulo operations, for example.
Yeah, I think OP might be more interested in "what is the most elaborate program you wrote only for your personal use?" Most of my personal programs have been command-line script. I have written a couple of single-page web apps and a Mac app once. These were more learning projects than programs I used long term.
* A replacement front-end for "tar" and various compressors
Could you elaborate on this? I feel like this is something that could save people hours of time. I'm so incredibly sick of the various decompression flags and tools, (de)compressing something on the commandline should be as easy as it is with a GUI.
I've memorized a total of two commands from decompressing things (`tar xfv $file` and `unzip $file`) and one for compressing (`tar cf $archive.tar $file1 $file2 $directory`) which seems to have done everything I've wanted for more than 20 years of unix usage. Is there something I'm missing out on? Sometimes, a `gunzip` or `7z` has been needed, but they are far apart that I can look it up each time. I'm not sure how I can save hours of time as non-tar or non-zip files is not something I often come across.
I just use dtrx: https://github.com/moonpyk/dtrx. That only does decompression, but that's generally good enough for me and supports basically everything (even more exotic stuff like Java JARs and DOCX, which are both ZIP archives under the hood).
If you're using GNU tar, there are four short options to specify compression/decompression: -Z for compress, -z for gzip, -j for bzip2 and -J for xz.
Using long options, you can specify --compress, --gzip, --bzip2, --xz for the same, or even --lzip, --lzma, --lzop or --zstd for others.
That's exactly why people hate tar/UNIX generally. Tons of parameters that don't EVEN CLOSELY represent their purpose. For example: -j -J if noone told me, I'd assume they were "join" or "jump", or something.
PS: zcvf zxfv, and, - surprise, surprise! - by default tar deletes source archive!
I made a program to gender swap any text you put into it and then got a book deal to rewrite and illustrate Fairy Tales. It’s been published around the world.
The idea is to shine a light on the original versions but it also creates a lot of never-written-before characters. A lot of brave princesses and lady-beasts, but also men desperately wanting children and being rewarded for kindness.
I wrote the gender swap algorithm in Swift. It seemed like it would just be a simple auto replace type thing when I started but there’s some weird things in English, for example with his/him/her/hers where they don’t swap back and forth sensibly and you have to understand the context.
It was his > it was hers.
It was his sword > it was her sword
So I ended up down this rabbit hole of natural language processing to break up each sentence into verbs, nouns etc to work out the correct words to use. Even tried training an AI to do it based on the finished swapped text but a whole bunch of rules worked more reliably.
This is great, thanks - this was actually my initial idea and it sat there in my head for 5 years and then morphed into doing a book.
We’re doing a sequel this year and I’m going to redo the website with the aim of turning genderswapping into a movement and getting other people to join in. I’ll link this this for sure!
Sounds like an interesting challenge although I’ll admit on this one I would have just went to fiver and hired someone to edit the existing text. My guess is under and week and a couple hundred bucks at most and you’d be set.
I think this is a case of "chop your wood and it will warm you twice"... ie. the value derived from this exercise was not just from the outcome, but also the journey there!
Totally agree and get it, I do it selectively as well - and on this one, I don't think I would have enjoyed the challenge of it so I would have just outsourced the work to be done manually. It's such a straight forward thing to explain to someone else, I think most gig workers that spoke english reasonably well could quickly knock it out. Actually, so much so that since most of these stories are fairly short and you probably end up proofreading them dozen of times as you tweak the code and/or review the outsourced work for accuracy/completion... so I might have just done it myself manually and it would have taken probably less than a dozen hours without the communication overhead of going through fiver or similar. It's more of a do things that don't scale approach I suppose as myself with a toddler that loves reading stories I value my time above all else and could find a dozen more interesting things to hack on in my limited free time (highly subjective I know, just my hot take on the topic at hand).
One reason it was nice was to instantly swap the story and get to read it back as if it’s new.. if I’d had to swap it all myself I’d already have been bored of it by the time I was done! Also allowed swapping lots of versions to see which I liked best.
But I have to admit too, that I just wanted to see if I could make it work ;)
Those who don't know history are doomed to repeat medireview mistakes.
(I'm old enough to remember when Yahoo's attempt at preventing cross-site scripting, blindly replacing eval with review, resulted in such shenanigans as "Please reviewuate my CV for Professor of Medireview History". Some of the corruptions persisted outside of Yahoo mail when people emailed text to themselves as a form of file transfer. Yes, this went into production in one of the two largest email providers at the time.)
People need to stop thinking this bot was a serious attempt. It is very obviously a troll making fun of people who advocate for gender neutral phrasing.
I made myself a Chrome extension called Headlamp that puts a red dot by each link, button, text box, etc., and clears them as I click or type while I’m testing a web app.
When I hand off a build to a client, if all the red dots are gone, I know I’ve at least TOUCHED everything.
If I’m working with another engineer, we can both see the dots in our browser and collaborate to clear them all while we test.
Sure! It’s not really bulletproof yet and could use some more features, but I’d love to get your feedback and bug reports. I’m thinking about turning it into real product…
Cool product, it's something I'd personally be interested in if free or one-off license, but as someone who just dabbles now and then (but including sometimes for business stuff) it's nowhere near worth the monthly cost for me. $50 one-off would frankly be possibly more than the value I'd get, but I'd definitely buy it in the hope it would be useful. (Appreciate, I'm not everybody and just because that's where I fit it doesn't mean your pricing needs to be aimed at me.)
I'm not even a dev, as I said I'm just a dabbler so certainly wasn't suggesting they build a business plan around my willingness to pay, was just adding a data point in terms of hobbyist interest :)
Maybe I misunderstood from glancing at the pricing table, what is the difference between "public projects" (free) and "private projects" (enterprise $50/m)?
My assumption from glancing at the page was that I'd only be interested if I could have the full version, and that I might be willing to buy a license to own it but not to pay a subscription to keep using it. Mainly because I don't mind an impulse purchase that's half hoping to turn out worth buying and half supporting a dev / product creator I think worth supporting, whereas if something wants money every month I want to actually know it's going to be a good use of money long-term, which is a much higher bar to clear in my mind.
A side-thought: if it turned out to be a useful enough tool that I started getting colleagues to use it, and incorporating it in work done for clients, then I'd prefer it to be open source and ideally easy to customise / potentially white label.
I don’t know what to do about pricing, only that I’m leaning towards a freemium model where hobbyists and occasional users pay nothing.
It is a cloud-based service with ongoing costs to pay and work to be done, so I think it’ll be subscription-based.
I would love to do this full-time if there is enough interest to justify the effort.
For now, I’m really excited about welcoming some real users other than myself and getting lots of bug reports and feature requests. Please give it a try and get in touch with me over email!
I created a program that prints QR codes onto sheets of peel-and-stick labels. When someone scans the code, they are directed to a simple web app that manages food sharing with my four roommates.
We noticed that we buy a lot of the same things (bananas, avocados, eggs, etc), so we implemented a system where anyone can stick a QR code onto something they want to share, and anyone else can scan it to record what they took. For example, this morning I pulled a carton of eggs out of the fridge, scanned it, recorded that I took 3, and a Splitwise expense was automatically updated between me and the person who bought the eggs (much easier and less awkward than handing someone 75 cents). Everyone is logged into the application via Splitwise OAuth, and all products/expenses/debts are automatically simplified within Splitwise and updated via the API - so the app is pretty much a wrapper over Splitwise specifically for granular sharing of food.
Lol do you really need to criticize someone else's code written by that person to solve their own problem in their own sphere based on your personal (sharing-positive) ideology? This is peak Hackernews.
Live and let live is what I say. Writing code for yourself and your own problems is fun.
Long-term sharing breaks down when one person feels they are contributing more than another. For low-price household items like toilet paper, soap, etc, and common kitchen items like olive oil, flour, etc, we all still pitch in to a fixed "house fund" since it takes more time to split it evenly. But for everyday quantity-based items, it has helped us all stop over-purchasing and throwing out as much fresh produce, and any roommate can opt-in to share as much/as little as they want.
Yea. I might set something like this up if I had awful roommates or some special reason why we couldn’t share. Otherwise, a shared fund for pantry items seems like less hassle for the same outcome.
I use a regular desktop printer and feed in sheets of sticky address labels (the 1" x 2.625" and 2" x 2" squares are ideal). I wrote a Java program to output QR codes with random IDs onto a PDF document, and generated one long PDF such that I could pre-print a couple thousand labels.
I chose a different system, you can buy something for yourself or you can buy something for everyone in which case the price is shared between everyone. Is it less fair? Perhaps the unfairness does accumulate (for example, I'm the only vegetarian here, but meat still gets added to the shared budget, but in exchange I eat more non-meat than others), but it would be really inconvenient to have, say, 3 packs of cheese (you can't just take an entire pack of cheese, so it can't be shared with your system). Also I don't need any labels!
Are you maintaining a per item price list? Is is generic or updated after each trip to the market?
0.25 per egg assumed the dozen cost $3 but what happens when I go to a value brand and my cost is $2 or the fancy $5 dozen eggs. Does the roommate have to update the price per item for everything they buy?
How do things like a bag of chips work? Cost per weight probably makes the most sense but the overhead of such a system seems enormous.
Also, what happens when your roommate gets mad at you because they bought those eggs for a specific meal they planned on cooking for dinner and now have to go to the store for more or change their plan? This is the main reason I most had a no sharing rule with my roommates.
To initialize an item, you take a QR code off a sheet of QR stickers (each one has a random v4 UUID as part of the web app URL) and choose a sharing method. In the case of eggs, I would simply enter whatever I paid for the eggs, and it is up to the roommate that scans the code to decide whether to take it or not.
There are four "sharing schemes" supported so far - share by quantity, by rotation (so someone can join the rotation to replenish something like a spice), by percent (so someone can offer/claim 25% of a leftover pizza), or the whole item (probably ideal for the bag of chips example).
The whole system is very hands-free and opt-in, and everything stays synchronized with Splitwise (I wanted to add some screenshots of that bit, but my roommate's names were all over - I might set up an example or GitHub repo for this project some day).
Decades ago I had a friend that needed to scan his CD cover to start selling it online. I only had a Linux machine. So I looked up the documentation for the HP scanners, found it was well documented at the protocol level, so I bought one.
I wrote some CLI tool that could trigger a scan and read the data back, into a file. Worked well enough, but I wanted a GUI.
I started thinking I wanted to make a GUI for it. I started thinking "I'll need to do X like xv does, I'll need to do Y like xv does, I'll need to do Z like xv does..." Clearly, what I needed to do is extend xv so it could do scanning. I spent a weekend making the prototype, and it worked brilliantly.
xv was open source but licensed $25 for commercial use. I made a deal with the author, John Bradley to become a reseller for xv. Over the next few years I sold, I don't remember exactly, but maybe thousands of copies. To people, to government labs, to businesses large and small. It was the beginning of a company that I ran until around 7 years ago, and that just shuttered for good a few months ago, 25 years later.
All for program I wrote to scan a friend's album cover art.
I created a program that outputs one of my kid's name if the day of year is even, the other kid's name if it's odd. I use it to determine who's turn it is to take a shower first. They'll argue with me and each other all day long but for some reason they will not argue with the computer.
I do that too! One of my kids was born on an odd year, month, and day, while the other was born on an even year, month, and day. They know who is who and they don't argue with the calendar. (We do it by day of month and we find another way to decide if we need to on the 31st.)
Even if the decision was merely day-of-week based, that doesn't buy the key characteristic the author values (I assume): the kids will accept the Algorithm's ruling
Heck yes, all the time. While it seems like the major computer/OS vendors these days are trying to turn computers into limited purpose appliances, I was first exposed to computers as a child in the late 70's, when it was expected that anyone who owned a computer would also want to program it for their own purposes. My own personal projects tend not to be very large in scope, but can be quite handy. Some examples include:
- A Pomodoro timer that has exactly the features and user interface that I want
- A script to perform backups of select files and directories from a source drive to a specified backup volume
- A "pixels-per-inch" calculator that allows me to compare the resolutions of displays that I may be interested in purchasing; by entering the width and height of a display in pixels, and its diagonal in inches, it calculates the density in pixels-per-inch, and the dot pitch in millimeters
- Various user-friendly graphical interfaces to aid in solving different types of puzzles (think sudoku-like logic puzzles)
- Programs to actually solve various types of puzzles all on their own (I've written over 70 of these in the last 10+ years!)
- Various command line scripts for code management tasks (i.e. useful for sofware development itself)
I have a pixels-per-inch calculator too, but mine is an Excel spreadsheet. Lets me see all the displays I've been interested in or own, even things like phones.
Yes, for over 30 years. I could never list them all. Nearly every thought I have becomes a program. I've written x86 asm game hacks (DOS era), 2D tile games (80's), Windows MIDI composers, game frame languages, ray-tracing renderers, OpenGL visualization, PID controllers, camera controllers, video controllers, circuit simulators, flight controllers, so so so many games, scripts for analyzing data, scripts for scraping websites, ODBC readers for my cars, FM synths, game solvers, and that's just stuff in C, not even getting started with the bazillion websites.
Over decades, programming becomes such a part of your life, that it is simply the way you move about the world, and think about it.
I wish I could shift my thinking to do this. I've been a web developer for 17 years and love programming. But any time I've tried to build my own projects or products, it's usually a revamp of an existing product or game, and I quickly lose interest.
I lack the ability to see everyday "issues" that could be resolved with programming. But if someone asks me to solve an issue with a program, I could probably come up with something pretty quickly.
Curious if anyone else has this problem, or have found a way out of it?
In fact, I'm not sure how to decide if something actually IS finished. Sometimes I just want to understand something, and when I get to that point, I call it done. I just like to learn.
Like with my FM synths: I made a TX802 clone a long time ago (in software), and once I got to a certain point I was like, "Yep, got it." I just wanted to construct something that could implement the FM algorithms and a filter. That's all. I could have made a fully-fledged MIDI synth, but I just wanted to understand synthesis. Or with ray tracing: once I got spheres, cubes, transparency, and reflections and a simple scene text-file syntax, I was like: I should add NURBS, but that was way too complicated, so I called that "done" because I understood how it worked.
You can ALWAYS keep going. Nothing is ever really done. When you lose interest, that's just your brain saying, "I learned enough, let's do something else!" Think of your brain on hobbies like a Golden Retriever: short attention span but always happy!
That's not a bad outlook and I had never thought of it that way. Even if I don't finish the project, at least I'm actively coding and having fun. Thanks!
If you don't need/want it yourself, and no one's paying you to do it, yes, you'll lose interest. I don't have your problem; I reach for code as a solution pretty quickly. Probably key is I'm not trying to "finish" personal projects or make a product, just doing as much as I need at the time.
Since you know web development, maybe install TamperMonkey and start "fixing" or improving websites you use regularly. You can often make a significant difference to your experience with a few lines of code written in a few minutes (changing/adding CSS rules, making links visible instead of hidden in dropdown menus, reordering/recolouring things, presenting information in a more sensible way, adding shortcut keys, converting static tables to DataTables, etc.). Over time some of my user scripts have grown to many hundreds of lines, and even been adapted to be essential components of workflows of me and my colleagues. They make my job/life easier dozens of times a day.
(Most of these are for internal websites or idiosyncratic to my needs, so there's no point in sharing them.)
You're probably going for things that are too large in terms of scope and/or scale and don't really solve any need for yourself. Think about bite-sized problems that will help you with your day to day work/hobbies and don't try to solve them in an 'enterprisey' or bullet-proof way... think the simplest thing that can possibly work. Then over time, start getting more ambitious. It doesn't matter if it only works for 2% of cases (as long as it's the 2% you care about), runs slowly, is a memory hog, crashes every 8th time you run it or any number of other things you'd never dare do for 'production' code. Assume it's a throwaway project and then be pleasantly surprised if it isn't.
The way out for people like you and me is to realize that most problems don’t need to be solved with software. When you find an effective solution that doesn’t involve code or computers at all, you can congratulate yourself.
Working on self-directed projects didn't come naturally to me either and I had to learn how to get over this motivation issue.
It's taken me 10 years of working on side projects to finally be able to figure out which things I will actually finish vs. which ones I just like the idea of and will invariably give up on. It's some combination of what do I think is useful to myself or others, what can I turn into a small prototype in a short amount of time, and what can I actually accomplish in a short time [1].
Accountability was important for me to launch three side projects in the last year. I declared to my friends on New Years that I was going to make and launch a game that I had designed within that year. I kind of entangled my desire to finish projects with my desire to follow through with what I commit to.
I didn't actually finish it in that year, I finished it in January of this year, but I tried! I set it down a lot and ended up getting stuck multiple times. Probably because of that pesky day-job and regular life. My friend asked me if I had launched, and that caused me to put in a final weeklong sprint and launch it. If I knew how close I was to finishing I would have finished it months earlier. I ended up simplifying a lot of code in the first few days of that last sprint and all of a sudden finishing seemed possible.
Because I devoted myself to launching that one game, I have since been creating more and more things and launching them or getting them to a stage where they're generally useful.
In my case, having the confidence from finishing one project made it easier to start newer projects because I knew whether I could finish them based on my past success.
>>> I lack the ability to see everyday "issues" that could be resolved with programming.
Almost every idea that I have could initially be conceptualized as a revamp of an existing product or game, but I'm super excited about them because they're my revamp that I'll gain a skill from and will help me to work on more complicated things later.
I take notes whenever I have an idea and will expand on ideas that I'm still interested in later. I basically use the snowflake method, creating more elaborate detail about the ideas I'm most interested in. Sometimes they evolve a lot after expanding on them too.
Honestly 99% of my ideas are terrible, so I trained myself to try to write down every idea that I have and then later on when I'm itching to start a new project I can decide whether it's a project that I will actually finish vs. ones I just like the idea of.
I don’t see it in the Dutch iOS App Store. You should add it there (most people speak perfect English here so you don’t need to worry about translations).
I wrote a scraper for various dating websites that would automatically generate activity on my behalf according to several empirical criteria (very simple stuff, no ML!), so that I could minimize the amount of time spent manually fishing.
It worked amazingly well, it got me hundreds (yes, 100+) of dates, incredible dating stories and a lifetime of memories, all in a semi-automated way without me requiring to “swipe right” or similar. As a matter of fact, my current girlfriend (of 5 years) was found through the software. She knows it and laughs about it.
Clearly the software didn’t do anything magical, I would have likely gotten the same results had I spent the time to individually message and interact with the 100s of women the software did in a semi-automated way, but it was really nice to save my time.
That guy used k-Modes to game the questions on OKCupid to maximize his matches, which is (well the line here is fuzzy) an ML technique. So probably not?
Tons. Way too many at times. I build a lot of tools to make it easy to consume and produce media/social media offline (these flows usually involve turning things into email or Usenet articles and then transmitting them on a private network) both because it lets me control how/when I consume media and also because it's just plain fun.
Other than that though, I have a system that helps my D&D group (which meets weekly and has for years) choose what to order for dinner. The system keeps track of a number of restaurants in our area (hand annotated) and chooses 5 restaurants from different food genres and excludes the genre of food that was picked the previous week. The restaurant choices are placed in a ranked choice poll which I monitor and close manually to choose dinner. The ranked choice poll has been helpful when a restaurant actually ends up closed so we just step down the list and pick the next in ranking.
Admittedly this is a technical solution to a mostly social problem, but my D&D group has some neurodivergent personalities that are really bad at coming to consensus. Also, the system pretty much runs itself at this point as the restaurants are kept in a sqlite database and the code is so simple that it never really changes.
I wrote a mapping program that could display maps, my location on them, time estimates to a down-road position, etc.
"Why not Google Maps?"
Several reasons: Google Maps requires a cell connection. (They have offline maps now — they didn't at the time I built the tool — but my offline maps are far more controllable in what data I pull down. And if I need data I haven't got, and I have a cell signal, I can fetch it on the fly and add it to the offline cache.)
Google maps was much worse at the time about finding rest areas. They're better marginally better now, but it's still pretty tedious to do on mobile. (There's no general search for it; you can search rest areas and usually get rest areas + junk, but you also really want to also search at the same time for, e.g., Flying Js, Loves. Contextual knowledge about the road would be good too, in case I'm on a turnpike. Also, still waiting for it to realize that, if I'm looking for gas, food, etc. … I want it downroad.) Admittedly my own implementation could have been better here, but I also lack the nice datasets that Google has…
OSM's map data is, in my opinion, better.
The GPS device I have can acquire a signal pretty much instantly. The phone … cannot. Useful in situations where we needed a quick answer, b/c things are happening at 60mph.
Though, we did end up supplementing the program with the phone. (On-the-fly routing is better in Maps, b/c it's a really tough problem, and I didn't build an interface into OpenRoute or whatever its called.)
My entire linux Desktop feels this way! It's my favorite part of working in a barebones Linux distro like Arch. I've got to build everything from the ground up. Need a screenshot program? OK... let's pull in Flameshot. Where's it going to host that image? Well, let's create a watch folder and shuttle everything off to a GCP static bucket.
Window manager? I3... heh, let's build a bunch of scripts. Vim? Well... man, that's a whole ecosystem of tooling I an hack together and write against.
I do this as a designer. I'm actually not a fantastic programmer, I just like the flexibility of building tools that are specific to me. My entire desktop feels like a love letter to building cool things the way I want.
I live by them; I probably couldn't name them all, they've become so embedded in my flow.
Probably the most important part of my flow is the following; it's a method for doing a personal "inbox" GTD style, 100% reliant on email + zim-wiki. I have a script that, when called manually, searches for new "inbox-marked" emails (i.e. ONLY those sent from me to me), and copies them to my zim notebook (specifically, to the page corresponding to "today" in the journal) as an open checkbox item.
Supporting that is-
- Desktop: a little shell script that pops open a zenity window to send such an email
- Smartphone: An android app called Blitzmail that does that and only that.(pops a window and sends to an address with no other interaction)
This replaces a LOT of things for me and helps prioritize immensely, (i.e. strongly prevents "email inbox as to-do list" which is a bad idea)
I created "Kid Money Manager", a tool to help manage my son's virtual account. He wasn't old enough to open his own bank account when I started, but we needed some way to track his "earnings" (returning bottles for their deposits or gifts from grandparents) and spending. It has both a Web UI and access via SMS text messages. We mainly use the text messaging—entering transactions at the store, etc.— since I didn't want to write a dedicated phone app for such a simple interaction.
I also recently wrote "Format Hero" (https://formathero.dev), because I could never remember which letters to use in Java's DateTimeFormatter. Was also a good demonstration of Hexagonal Architecture and, of course, I live coded it, TDDing all the way. Source is at https://github.com/jitterted/format-hero. Still some work to do on that one, but filled my immediate need.
I work as a water engineer, specializing in building hydraulic models so water utilities can simulate their network.
A big part of that is calibrating them which can be time consuming, you look through hundreds of options. I create a few web based apps to help grind through these tasks but ultimately they were for my own use as a consultant to close projects quickly.
I did pull out the engine as its own open source library for other to use, and that ended up helping me get my current role where I can now maintain it and be paid at the same time.
Dozens if not hundreds (my github recently exceeded 100 repos; more than half are personal projects)
What I've done at every job I've had (in software) is convince my boss "it's just a little code, let's open-source it! Maybe it'll go viral and a community will form to contribute & make it better!"
Which basically never happens (well it did once, in a big way) -- but when I'm working my next gig, guess what? I can use all that code again. And this time I can honestly recommend, "Let's use this thing on github, it does what we want & it's open source!!"
I have a fun one. The front door to my house had an automatic door opener, paired with a single-button remote control to unlock and open the door. The remote control was annoying to carry and use. (This was before IoT became a thing.)
I pried open the remote, soldered on an extra circuit bypassing the push switch, and hooked it up to an Arduino. When a packet is sent over serial, the Arduino simulates a button push:
This was paired with a tiny web server to do the serial write:
#!/opt/bin/python2.6
PORT = 5525
import BaseHTTPServer, SocketServer
class LoccaHTTPRequestHandler(BaseHTTPServer.BaseHTTPRequestHandler):
server_version = "LoccaServer/1.0"
def do_GET(self):
if self.path.startswith("/trigger"):
serial.write('A')
self.send_response(200)
else:
self.send_error(404)
serial = open("/dev/ttyACM0", 'wb', 0)
httpd = SocketServer.TCPServer(("", PORT), LoccaHTTPRequestHandler, False)
httpd.allow_reuse_address = True
httpd.server_bind()
httpd.server_activate()
httpd.serve_forever()
Finally I threw together an iPhone app with the most basic UI imaginable: a static full-screen photo of the remote; tap once, it fires off a HTTP request, and the door swings open:
At one point I had a gist with a bunch of links to a web server that controlled some home automation stuff. Add a link to your Home Screen and you’re good to go! Easy to share as well
After a quick burst of manic energy during exam phase, I decided to solve the pigeon problem on my balcony once and for all (and in a humane way).
So I bought a cheap electric water gun from Amazon, built in WiFi using an ESP8266 and a relay shield; 3D printed a window mount for my old iPhone (running a webcam app) and hacked together some openCV code in python.
After all this was working on my desk, I had the pleasure to discover that the PCB Antenna of the ESP is to weak to receive WiFi on my balcony so I connected the ESP to my (current) iPhone hotspot and wrote a small go relay for my server so that my laptop can send the shooting commands to the water gun ~~over the internet~~. Oh and while I was at it, I added a Siri Shortcut, so it’s voice controllable, too. (They are surprisingly hacker-friendly)
The surprising thing is, that this Ruben Goldberg machine actually works really well and without much fiddling.
You can take this JavaScript snippet and save it as a clickable bookmark (hence the name bookmarklet) in you browser. I've named this "re-open in Nitter". I deleted my Twitter account a while back but sometimes I get handed a Twitter link. This snippet let's me quickly re-open the link in Nitter which is a nag-free way to browse Twitter without having an account. :)
I have a strange problem with my monitor that I solved with a program.
Basically, I use a USB switch to switch my mouse, keyboard, and webcam between my personal desktop computer and the MacBook I use for work. I tried a full KVM switch at first, but every time I'd switch it to my MacBook, Windows on my PC would flip its shit. With the primary monitor disconnected, it would move everything to the secondary monitor, which was fine, except that when I moved the KVM switch back to my PC, it would move everything back to my primary display, whether or not it was originally on my primary or secondary. Additionally, since my two monitors are different resolutions, all my window sizing was wrong.
I tried to get around this by plugging my PC into my monitor's Display Port and plugging the MacBook into an HDMI port and just telling my monitor to switch inputs, and for the most part it works, but at 1 PM every day, if my monitor is set to HDMI, it drops the DP connection, making Windows think it lost the monitor, putting me back at square one.
So I wrote a simple program in Python that sits in my notification tray. I can tell it to save or restore all my window positions. So if Windows loses the monitor, after it comes back, I can restore everything to where it was.
As a bonus, I also added a "Easy Copy/Paste" menu to quickly copy emojis like ¯\_(ツ)_/¯ and ಠ_ಠ to my clipboard.
I love writing personal programs - you get to re-invent the wheel your own way to learn exactly how things work, with no code reviews or people shouting "[BLAH] ALREADY DOES THIS".
Sometimes you just want to code and see if you can recreate BLAH for yourself.
My oddest program was called 'heater' - it variable settings from warm -> hot and would peg the CPU at different rates (at the time I was in an unheated office, and rather than go buy a heater - I did what all programmers do and re-invent the wheel)
Any time I find myself doing something twice on a computer, I try and think if it would be easy to write some tool and do it if the value makes sense. Usually these are teensy little utilities that might pull data from websites, wrangle text and handle common files in my life, let me know upcoming meetings and connect to them, or even just little hobbies like making a scraper and local database of recipes vs manually going to that js heavy website prone to link rot.
All these exist on the command line, some are short functions in my bashrc, and some are more substantial written as discrete scripts and run via launch daemons. Not having to worry about gui or capturing each and every test case makes solutions fast and only a couple to a few dozen lines most of the time. I don't worry about awkard characters in my strings and all the esoteric regex and special cases that would need to go into a production ready script, because i simply don't use those characters in strings or do anything funky that stack overflow comments like to bring up as a potential pitfall. Makes it easy when I am my own client. plus it makes it easy getting all these programs to some new computer of whatever OS when all I need to do is pull a git repo full of these scripts to install.
Hacker News is part of my daily life. I try to follow the top stories every day when I have the opportunity. In order not to miss important stories on my busy days, I prepared a notification service. It was a very simple, ~40-line PHP script that sends me notifications for stories with over 200 points. I have been using this service for 7 months and I no longer worry about missing important stories.
Finally, I made this service available to everyone so that it can be useful to others. I have also obtained the necessary permissions from the HN moderators to share such a service with you. So, I hope you will not miss important stories from this awesome platform with the help of this service.
Because I was already have Pushover account for mobile notifications, and started using directly without extra payment or application.
Now I checked after your question, I found this[1] good service, but do you have any suggestion about receiving mobile notifications from RSS (for iOS)?
And you can consider my personal project as an alternative.
I have the feeling I am creating one every two weeks. If you tolerate windows, C# is a great multi-purpose language to develop quickly tools across desktop GUI, CLI and websites.
A UI over ffmpeg to look into downloaded movies and add/remove/rename/change default tracks without recompressing (or re compressing certain tracks only). And to autorename files with imdb titles and ids. And another one to collect timestamp from videos to edit out segments. Or to merge videos, auto finding the best size, fps, etc.
Own mp3 player with ability to exclude songs, import files from different sources and sync playlists with itunes on windows through COM. (Had so many bad experiences with itunes that I don’t trust it as my reference for song data, ratings and playlists and only use it to sync iphones).
Various tools to edit and manipulate gpx (fix time zones mostly and apply gps to photos) or srt files.
All sort of web scrapers.
A nimbletext-like on which you can drop files
A home website that contains the downloadable imdb data to manage my movie library and suggest movies I don’t own already.
Music sorter to try new songs with fast keyboard shortcuts to fast forward/flag/discard. Same for photos.
Lots of CLI tools: CLI for my domain names (for instance to maintain a dyndns-like subdomain). My own ACME client for wildcard certs that also updates various softwares with the new certificate (IIS, mail server, will look into synology soon). Tool for wake-on-lan my devices. A tool to auto-update the other tools based on a central repository. Various commands to put in a powershell script to send notifications, update my own "dead man snitch" website. Watch new real estate transactions in my neighbourhood on land registry (UK).
Also under the "If you tolerate windows" umbrella, PowerShell.
I've been a die-hard Linux user since the middle of high school, but during some work recently, I was pleasantly surprised by how quickly I could get a basic GUI for a PowerShell script I was writing.
Back in the day we used to clean them up and release them to Freshmeat. Clones of Freshmeat still exist today, but the kids today don't know about it, so nobody uses it, so it's mostly just old apps that are still maintained. But Freshmeat used to be the very first site you'd visit to find open source apps. Sooooo much easier than today where you have to search and search through various sites and still you're only seeing the most popular projects.
I wrote a web tool that automatically syncs all my brokerage transactions from multiple brokerages (either using their APIs or web scraping). It also grabs daily closing prices of my stocks and relevant foreign exchange rates from public sources, and then presents me with a bunch of graphs that I find relevant. It does my capital gains tax calculations every year.
It took me probably 6 months of hacking on it in my free time.
In fact, there existed no other alternatives at the time (~2017). Especially none that did things like adjusting the cost basis of each security based on the foreign exchange rate on the day of purchase, and tracking gain/loss correctly in Canadian dollars. I also needed it to sync with my work's group RRSP provider which doesn't offer a standard API.
I don't know if this market has improved in the last 5 years, but I have a system I'm happy with now. :)
I have the same issue with having multiple brokerage accounts. I haven’t signed up for Personal Capital because I read that they try to upsell you on wealth management services by phone periodically, plus I am uncomfortable giving my brokerage login credentials to them (or any other third-party service). So I was wondering if you were in the same boat!
Yeah I was definitely uncomfortable about giving brokerage logic credentials to anyone. Some brokerages can give you a read-only API key you can supply to an app, which is nice for systems like this. Maybe see if yours do that?
Wealthica is a Personal Capital competitor. Maybe take a look at them?
I wrote a fairly large and involved desktop app in Python and PyQt5 to enable me to execute a project I was on where I the functional safety engineer for some fairly serious industrial Burner Management Systems, for a lithium processing plant.
The app enabled me to define the behavior of the BMS system as a state machine represented by a table (using PyQt tableview). It also simulated execution of the code as would be implemented, one scan at a time.
Once there, I added a bunch of tools to print out reports/documentation, run diff against models, extract transition comments where certain tags or similar existed (eg show all transitions with a comment that include "IEC 61511"), version tracking, etc etc etc.
It might sound slightly a trivial problem on first description, but one of the systems had ten burners and it ended up being a hierarchical set of 15 state machines 3 deep and it would have been almost impossible to define the behavior on paper - simulation picked up heaps of minor sequencing issues and allowed us to correct them before actual software was written and tested.
Basically, I ended up with an executable specification (not far off the IEC 61499 dream) that self documented. I could have made it write the core PLC code and export it as XML for import to the PLC programming tool, but it was sort of break even to go that far on SIL 2 systems, so I did not go the full distance on that. At one stage it looked like we might go SIL 3, so this would have been useful in that case.
In the end, I put in maybe 1200 hours to build this, in my spare time. Lots of late nights for well over a year, but I don't think we could have really done the project well without it, or something like it.
I looked at it, and decided to actually commercialize it in the form where I could maybe sell/give it to random punters was whole new level of effort. Plus it seemed to be the sort of software that people go broke trying to sell and support, so I just use it for my own purposes now.
I have written many web applications for my own use, where I do not have to take the extra effort to bulletproofing applications for unintended use (validation and verification requirements etc). Three applications stand out:
1) a web application to manage customer Q-tagged VLAN Ethernet circuits within specific color-coded optical fibers of municipal fiber-to-the-home cables (12, 36, 48 and 96 fiber cables). The application enabled fiber optic physical plant to be optimized for customer Ethernet circuits, reducing the cost of implementing customers considerably below industry average.
2) a double-entry bookkeeping system optimized for the monthly US Bankruptcy Court Chapter 11 financial reporting requirements to manage the same company as debtor-in-possession when our largest customer(s) filed bankruptcy during the dot com bust (circa 2001), forcing us to also file for protection. This enabled us to successfully double our customer base, double our revenue and retire all debt while reorganizing in bankruptcy.
3) a general accounting web application emerged from these experiences specializing in multi-currency accounting of businesses specializing in asset management (features that Quickbooks etc just do not have). This built on my personal situation of being a citizen of more than one country.
All 3 of these were developed using PHP/MySQL and I have refactored them over the decades up to PHP ver 8 / MySQL ver 8 running on the latest Ubuntu LTS server version. As I am the sole user (with a few personal assistants), I have been able to focus on the addition of features and capabilities rather than user support, security and general hardening of the applications.
Also a disassembler, editor, file dumpers of various formats, directory comparators, accounting aids, audio file declicker, hard disk driver, a program that would image a floppy disk, VT52 emulator, etc.
Like many people of this community I have written multiple scripts and programs for my own use. Recently I was bored with Tinder, so I wrote a small CLI to automate the likes on Tinder. It's totally stupid and just likes everyone, but I found that it's easier to filter out uninteresting candidates afterwards instead of having to swipe manually in the app.
Another recent thing (this one is open source, search for "5hay/notionbackup"): I wanted regular backups of my Notion workspace, so wrote a little program in Go that does that. I'm doing weekly backups and pushing it to my Google Suite with rclone (encrypted).
I wanted to quickly hack together something and was too lazy to reverse engineer their private API. So I settled for their web app and Playwright (cross browser Puppeteer alternative). The auth stuff for their web app is stored in IndexedDB, so for it to work with Playwright you have to replicate the DB inserts.
It's pretty straight forward because Playwright is easy to use and has good documentation. You just need to have some basic CSS skills to find the correct selectors, but it's really not complex (Instagram and other big sites make it a bit harder).
I could run the script in a cronjob, but I decided to just start it manually whenever I want. So I have it connected to a Telegram bot of mine where I can just tell the bot to like the next n people.
I might write a small blog post about it at some point.
Absolutely. Most of the software I've written is for my personal use. I enjoy automating and customizing things on my computer, usually by plugging in my own scripts into the programmable environments. I'm also extremely fond of reinventing the wheel on purpose.
My biggest personal project is a streamlined android app I use to easily track my own job performance and statistics. I can back up my performance claims with real data, negotiate more valuable terms and identify optimization opportunities. It's helped me increase my profits by about 60% and also allowed me to work a lot less hours because I know how much time I need to accomplish each task and can optimize the use of my time accordingly.
I don't feel comfortable publishing things on github without at least polishing them a bit first and I no longer have enough free time or motivation to do it. Sometimes I come across an interesting concept that I just have to implement to convince myself it works and that I'm not insane for thinking it. Usually lose interest after it's proven, finishing it is a lot of work and it just feels pointless.
> I've written scripts the automate the creation of parts like screws that can be imported into 3D CAD tools.
Cool!
I found a really cool plugin for Inkscape that computes gear parameters (I have access to both laser- and water-jet cutters). That kind of stuff is really useful for non-machinists like myself.
> Libraries for STM32 chips so that I could easily go from idea to something I could test.
I discovered CubeMX about, gosh, at least 10 years ago, and it changed my life. I went from Arduino to STM32 and suddenly i have all kinds of peripherals. Their stuff is awesome.
Yes - I wrote a full DVD authoring workflow to take weekly anime fansubs and produce finished DVDs for friends with either bad internet connections or who preferred to watch in their living rooms.
This was before having an HTPC or media center was a mainstream idea.
All you did was add in the video files sorted by file name in a subdirectory and add a main menu image template, a main menu audio file, and episode select image template (the layouts were static so that the same dvdauthor XML could be used) and it would stitch together a DVD with an intro video, main menu screen with subtitle, play, and episode select options, and generate episode select screens by taking thumbnails from the video files.
Last time I used it was about five years ago before same day/date streaming of anime really took off. I still hack on it from time to time. I don't really have a use for the output, but it's nice to maintain it as the tools it use change/update and as I learn new things.
Hundreds. Look, computers are tool builders and tools hosts, so when you need a tool you build it, if an adequate solution is not already available.
And tools can be anything: organizers, information accessors, information processors, learning aids...
As already mentioned, months ago I had to build a full word processor for Android. I just needed it and what was available was faulty. Worth mentioning because I had to laugh in front of the odd situation of having to build a Word Processor from scratch in 2021 - but there you go, you may need anything.
Most recent program: I wanted time-lapse photos of some potted plants I'm trying to grow. So I stuck QR codes on the pots and take a picture of each one each day with my phone. That goes to Google Photos, and a cron job scans new photos, recognizes the QR code, and copies the photos into directories for each plant with filenames that sort chronologically. Most of the plants died. I am a better programmer than gardener.
Most used program: I keep a journal of practical daily happenings in Emacs org-mode, organized hierarchically by year/month/day. It was too much hassle to add new entries (I'm lazy), so now I have a utility that inserts journal entries in the correct place from the command line, e.g., "add-journal 'talked with roofers to get estimate'". It's turned into an ad-hoc database for recording things like my weight, also, which gets parsed and turned into a graph.
> It was too much hassle to add new entries (I'm lazy), so now I have a utility that inserts journal entries in the correct place from the command line
Tons and tons of them over the years. I wish I'd kept better track of them because I've caught myself reinventing the wheel now and again.
- When I was a kid using a DOS PC I'd write them in Microsoft QuickBASIC or Turbo Pascal and compile them to EXEs. (I used to drag a few particularly useful ones around with me until a few years ago when the prevalence of 64-bit Windows made running them on a stock Windows machine impossible.) I had stuff there like a random password generator, dumping files to VGA mode 13h (to visually look for patterns in data), drop the DTR on a serial port (to hang up a modem from the command line), search/replace on INI files, and lots of others I've forgotten.
- I wrote a proto-Markdown text processor back in high school when I was taking notes on a vTech Laser PC4[0]. It took files from the vTech and rendered output files with Epson printer formatting codes, centered text, made headings, etc.
- I regularly use a script I wrote to import my phone backups' SMS logs and dump them into my IMAP mailbox. I love being able to search all my email and SMS communication in the same interface.
- I have a podcatcher I wrote bolted onto my (heavily forked) tt-rss[1] installation to download podcasts to a local webserver for archiving and playing.
- My father persists in using a DOS accounting package for his business. A small program I wrote ingests check printing output from the DOS app (meant for dot matrix tractor-fed checks) and reformats it for sheet-fed checks in a laser printer.
- Front-end scripts for lots of command line utilities so that I don't have to remember obscure options for common tasks.
I made a headless sqlite dbms (not nearly as feature rich as the real thing) for my own embedded development. It can show the values of any table, view specific cells, update cells with a text editor interface, beautifies json, and takes in SQL queries as well.
Got some bugs with formatting complex lines of text, but it works well enough for me. I plan on porting to Rust one of these days.
My main group of friends with whom I play videogames on a daily basis is on Telegram. We use voicechat and stream our gameplay on discord for others to watch/comment in a more private setting (other tools are too public). I wrote a bot that notifies on the telegram group whenever someone starts a stream on discord so others jump in and join the game/stream. Discord shares which game/activity through their API so we know exactly what someone is playing. I also add some personalized randomized spice depending on who is streaming and what they are playing to the telegram bot messages so we can laugh about it.
Whenever the bot has gone down (I turned off the home server or whatever) my friends complain, so I know the bot is fulfilling its purpose :)
One thing I do (and am curious if anyone else does anything like this) is I dynamically generate PDFs, generally to print out planning sheets and stuff. I like using templated printouts for planning my day/week, because I can scribble over them and break out of the predefined structure when necessary. But I also like digital calendar-type tools for their extra powers - they can pull in weather forecast data, events from shared work calendars, stuff like that. So I have a script that dynamically generates a day-planning PDF in my preferred tabular format, augmented with info from digital sources, before sending it to my printer. It's the best of both worlds.
Market Alerter - I created an app that alerts\emails you if your chosen stock meets some condition. There are many other sites that already do this. However, I wanted it to be able to expressions of one or more stocks. For example, if you want to monitor West Texas Intermediate (WTI) crude price or Brent crude price, you can do it easily. If you want to monitor the crack spread (WTI - Brent), existing solutions are limited. I made this to allow monitoring of combinations of stocks\commodities.
Options Simulator - An extended family member asked me to create a small simulator to help forecast the outcome when making options trades.
I don't know that I'd consider most of them "programs", but I've written hundreds of small helper scripts of various sorts over the years. Most of them aren't even published anywhere, not out of a desire to keep them from the light, but more because I write them, use them, and forget about them until they are rediscovered years (decades?) later.
One of the simpler scripts I wrote that I actually published is a little helper to output WiFi signal strength on Macs into printable glyphs so that you can include it in your prompts on the terminal.
I'm a scientific programmer so almost all my software is for my own personal use.
I'm just kidding, I'm assuming these are not for fun projects (because in that case, idk dozens to idk how many at this point) but general programs for my use as utilities beyond just the fun for programming, and I'm guessing scripts don't count, well once upon a time I made a notes app but that has fallen into disuse unfortunately.
Looking at the comment section, uh, scripts that are just wrappers for various tools (rsync, ffmpeg, others) are a dime-a-dozen I guess, I have so many in my ~/bin directory that I've forgotten what some of them do at this point.
Oh yeah, once upon a time I made a background changing app that just changes my desktop background based on the time so I would have backgrounds that matched the time of day, I did it in CL just because I loved learning CL but I have no real reason to use it in my work. I was going to make it automatically change the timestops based on the season, so evening photos etc change as the length of day changes, and make it based on the sunrise equation[0], but I sort of dropped it a few years ago and haven't really touched it since. You know I might do that again, just for an excuse to learn Lisp again.
I wrote a set of python scripts to pull down economic and stock market data. It pulls down several different data sets mostly from the Fred API service at the Federal Reserve. Using Jinja templates and Matplotlib for graphs, it builds a set of latex files and spits out a PDF that I can review. That way I don't have to look at 4 or 5 different sites to get the overall market picture I want. Essentially my own newsletter... to myself... okay, is that healthy?
I have GoPros on my bike and often when I arrive to work/home I forget to turn them off and the batteries die, so I wrote an app so I can shout across the room, "Hey Siri, stop all cameras".
I don't use it anymore myself and got a bug report last week. It's a couple of years since I've written any Swift at all, so I'm not mad keen on working on it, and I feel a bit bad that I have published it and it's not working. I never put the code on GitHub because the reverse engineering of the Bluetooth was somewhat incorrectly documented in the code and I didn't want to share bad information. Now GoPro have an SDK I could use.
Similarly, I wrote a Siri Shortcut for checking where the nearest Jump (bikeshare) bike is (Python on AWS Lambda). Then Uber sold Jump to Lime and there is no API access for me anymore (Sacramento).
Yes. Typely [1]. Made it to aid in writing better articles for myself and some employees at the time. Decided to put it up there after a while and is now being used in many schools around the world. This is the only one that was made for me initially - I have a lot of other projects but they are made for aiding my businesses or to try new ideas.
I spent a week or two creating a trading tool for the popular video game EVE Online. The tool identifies regional arbitrage opportunities between large market hubs and allows me to prioritise the movement of goods to maximise profit while minimising time investment. It also helps me update orders efficiently.
As it provides a decent competitive advantage I have no plans to publicise it, although it is on Github as a portfolio piece.
I've written a quick and dirty Django app to organize computer history literature (papers, manuals, books, etc). Every document includes an embedded pdf and is tagged with authors, institutions, and topics. It supports cross-references between documents. I also added a feature to mark a document as read and when it was read.
It has helped me wrap my head around certain areas of computing without getting lost in a pile of pdfs.
Every so often I want to derive a fraction from a decimal value, such as 0.571 => 4/7. The key point is I want good approximations, not exact values. That is, I rather get 4/7 than 571/1000. I had found a tool at one point that did it, but it stopped working, so I made my own.
You seem to be sort of doing this by brute force; a non-brute-force way to do this is with Aryabhata's Pulverizer Algorithm to get a continued fraction you can then truncate to get convergents.
So 571/1000 = 0 + 1/(1 + 1/(1 + 1/(3 + 1/(47 + 1/3)))), or, in the notation that is conventional for continued fractions, [0; 1, 1, 3, 47, 3]. The truncated convergents are [0], [0; 1], [0; 1, 1], [0; 1, 1, 3], [0; 1, 1, 3, 47], and the full fraction. These convert back to rational numbers respectively as 0, 1, 1/(1 + 1/1) = 1/2, 1/(1 + 1/(1 + 1/3)) = 4/7 (your desired approximation), and 1/(1 + 1/(1 + 1/(3 + 1/47))) = 189/331. Except for 0, these are exactly the same ones your program finds, but the Pulverizer only required four divisions. (The difference in efficiency is insignificant for manually entered fractions with a modern computer, though.)
This is explained in places like HAKMEM, the Machinery's Handbook, and I think the Aryabhatiya. But I don't read Sanskrit, so I've never read the Aryabhatiya.
I always get a sense of achievement when I side-step the analysis of a problem with a stupid, straight-forward simulation script (usually probability questions).
It may burn several seconds of CPU and get me only 3 significant digits where a one-step solution exists. But I'm confident in the result because the script is near-impossible to get wrong, compared to some theory I just learned. Or a probability distribution that turns out to have conflicting definitions for what its parameters mean.
I made a command line music playing frontend. It has a list of all my music as a flat text file, then if I run "music" it shuffles randomly, or I can add a regex as an argument to pick the files from the list. It works surprisingly well - given my folder structure I can just type in "music <artist>" or "music <genre>" or "music <specific song>" and it just does it. It also has a flag for turning shuffle mode on or off.
Very simple, but very comfortable for me.
I also created my own TODO / dashboard app, where all tasks are on a schedule (do this every x days) and I can enter a value each time I complete a task. These then show up as graphs on my dashboard - helpful for tracking weight etc. I also graph a bunch of random things automatically in the same system (how many unread emails I have).
It also tracks how many tasks are overdue so I can measure my general ability to get stuff done, and if it gets overwhelming I can tweak the settings so it just shows me a few things (or more realistically I tweak the task to either not need doing/tracking, or I slow down it's cadence).
Several, but not many that I actually used daily/weekly for an extended period of time.
I am not a huge fan of podcasts but I do listen to a select few. I am also weird and only listen to them on my main machine at home while doing something else.
I was a huge fan of Juice[0] but it hadn't been updated in ages and at some point its TLS parts were too old and I gave up updating it to Python 3 after a quick try. So I wrote my own Podcast library thing in C++/Qt which talks to a backend, where the data is stored.
And I wrote a soup.io clone in Clojure that I use mostly for song bookmarking via youtube (but so I can play them). Then I stripped nearly all of the soup features and now it's just a tumblelog I guess. Then after many years I rewrote it and didn't open source the rewrite.
And as you mentioned, the odd metrics/scraping/whatever job that's being run every night and where I actually look at the output several times per week, in one case it's an actual program, yeah.
Dozens, one of the more outwardly useful ones notifies me of a certain band's latest LP drop (basically just queries shopify's public-facing JSON for any shop you give it).
I've also got a stupid one: a mouse waggler. My work enforces screen lock times to be 5 minutes, and I have two computers, one on an air gapped network. So when development happened in the air gapped PC, and I inevitably had to look up docs for something, I would always be prompted for my password. So, I made a program that nudged my mouse just slightly every five minutes. That has essentially turned into my Windows API test bed. Someone will ask, how hard will it be to implement X for Windows? I'll try and find a use for it in this waggler, and look how to implement it.
This has also lead to the waggler part being obsoleted by one function call:
I also made a mouse jiggler because of a former job’s inflexible screen locking policy.
I made mine hardware with a small MCU that plugged into USB and looked exactly like my work-issued mouse (vendor id, device id, etc)
It was hardware because I didn’t want it to show anywhere (we were technically not allowed to install unapproved software even if it meant we couldn’t do our job and it was a selectively enforceable fireable offense)
It worked very well and was shaking 5px left 5px right every minute. It was so little that you wouldn’t notice while actively using the computer.
I have a fairly large blu-ray collection (~300 movies, ~15 complete TV series). I rip them and serve them with Jellyfin, which works, but due to codec annoyances, I need to transcode them to run on web browsers, and the SBC I'm running Jellyfin + ZFS on is not really fast enough to transcode in real time.
Since I have a ton of little SBCs sitting around my house, I decided to write a clojure app the queues up and transcodes my movies to H264. It uses Docker Swarm to handle distribution of nodes, RabbitMQ to queue up the movies, and core.async to handle local queuing within the application, and uses the Java NIO filesystem stuff to handle any kind of atomicity.
It's hardly the "first" or the "best" at what it does, but the advantage of writing your own is of course that you can tailor it exactly to your setup, and of course it was fun to write.
At a few months old I created BabyDots [0] as she loved this YouTube video of dancing dots [1] which really settled her when she was upset as a young baby.
At over a year old I added BabyPhone [2] to let her talk to family and have them “talk back” to her even when they were not available. I missed the timing on this and she didn’t enjoy it at all until literally this week when she started talking back to the little baby on the other end of the phone.
At 18 months old I made a book-building app [3] that takes titles of pages on Simple English Wikipedia, and creates pages for a book that can then be exported as a PDF and printed (or viewed on the phone). It also has a website [4] on a free heroku dyno which definitely won’t take much traffic. This was because when she gets interested in, e.g. planets, I don’t want to have to order a book on planets, I want to print one out 5 minutes later to keep her interested.
One of my proudest moments was at my new job where a team member said during our first standup “I have your baby dots app installed and although we don’t do screen time, the music really sooths our kid during nap time!”.
So much shell scripting and use of `fzf`. I make things I enjoy and will be happy using and since I spend a lot of time in the terminal, it makes sense to make things like this for me.
- wgetcheck (Python): Downloads a file with wget and verifies a provided hash, for my convenience. Also automatically verifies internal checksums in zip, gz, and other archives, and verifies the size and MD5 checksum provided in a HTTP header. I'll probably next add verifying the provided size of the file to provide some sort of basic check for files without provided checksums. This all would probably be better done by a browser extension, so maybe I'll write one later.
- freeze (Python): A script to update a hash file (same format as shaXXXsum) by adding new files and noting which no longer have matching hashes. Optionally sets the files as immutable [0] to prevent them from being modified or deleted. Intended to be used on files which aren't supposed to change or change infrequently.
I've been writing programs for myself since I started programming on a Tandy Level I. I'm always working on some project or other. Most of them are too big for me, but I do them so I can learn how the real things work. Currently writing an html user agent, but it's not even off the ground yet. I have a program that uses something like genetic algorithms to play go, but it's not doing very well relatively speaking. I wrote a program to resize files using an underlying floating point grid whose size you can specify that tends to work okay. It's slow, but I use it for resizing files for smaller displays and just to tinker with.
There are staples I keep coming back to. I'm always trying to write a reverse ray tracer that shoots photons from light sources and tracks them around to see if they hit a pinhole camera, but they are of course way too slow. I've played with some ideas for compressing images, and I've taken a few runs at the hutter prize (compressing wikipedia). Writing a massive text-based old-school rogue-like is something I keep coming back to.
I used to mod games, and have played with some programs designed to edit different file types I was trying to reverse engineer. I've played around with trying to optimize sha-256 hashing, but haven't gotten anywhere. I also have tons of shells scripts that do various things.
I usually write in straight C these days, though I've tried various programs in D, Free Pascal, Ada, Java, assembly, Perl, BASIC (back in the day) and probably others I've forgotten. I remember in high school writing a game with a friend for one of the early Tandy machines in assembly on paper and then hand-assembling it to machine code and using poke in BASIC to put it in memory and then executing it. We didn't have access to an assembler.
I haven't ever given out any of my code, I just use it to play with ideas and to keep my skills up.
I was so bored at my last job that I wrote my own version of Minesweeper that works in your terminal. You can try it out by running: `docker run -it --rm ghcr.io/pdevine/bombitron`.
It works pretty well w/ Linux, and also iTerm2 on macOS (if you enable mouse reporting events). It's a hot mess if you use Terminal (but no one uses Terminal, right?)
I made macOCR[1], it is an app that I used for years to make office work easier.
It is a command line app that enables you to turn any text on your screen into text on your clipboard. When you envoke the ocr command, a "screen capture" like cursor is shown. Any text within the bounds will be converted to text.
You could invoke the app using the likes of Alfred.app, LaunchBar, Hammerspoon, Quicksilver, Raycast etc.
I only released it to the world when I swapped the backend out from being Google Vision to Apple's built-in OCR APIs.
I also made a "life management" app marcusOS [2], that does all the usual things you'd expect.
I wrote a PPPoE client with failover so I can keep the session even when one of my gateways fails or is rebooted (this lets me do regular maintenance without interrupting my internet connection); I put it on github[1], but I doubt anyone will use it. I hope there are few people left with the scourge that is PPPoE, and my OS choice means many people would need to switch OSes to use it, so yeah. Also, I don't care to make it easy to use or to promote it, really. (I've mentioned it once or twice and did a Show HN that got less than ten votes, which I kind of expected).
I've also got my personal (network) monitoring software, some 'IoT' stuff to capture temperature and humidity data around my house, and I'm working on a ESP32 based alarm clock pulling data from iCalendar feeds.
I have just made a little machine learning model to help me go through the 27k photos from my ten years of cell phone cameras (should this go up on the wall? y/n), and am using a Jupyter notebook for the tick tock of data labeling, image classification, data labeling the most ambiguous, reclassification, etc. Hope to write up soon
I was addicted to refreshing websites - twitter, reddit, etc etc. So I wrote an extension to essentially pull new posts for me every 10 minutes - its actually saved so much of my time.
I self-host everything, and I wrote an authentication framework, which I call "Fancy Auth". It is configurable by YAML and works like a proxy in front of all my web apps. It's like a glorified Basic Auth, but can connect to LDAP, htpasswd files, can login with QR Code and Magic Link or via SSH.
I've created a multithreaded python daemon which every 5 minutes scrapes all currently online cammers on chaturbate and streams to file the ones I've marked as favorites. I've got a text file with tags for each favorited streamer so I can change which ones are being downloaded depending on mood.
I once wrote a fusker for a paid porn site I realised just had its shit hanging out in the open. 4 days of runtime and I had a collection that left me wondering what the hell was wrong with me.
I had been accruing bookmarks in Google Bookmarks since 2008, then saw it was going to be shut down[0]. I liked the workflow and the core features seemed simple enough, so I made a cheap clone - Strudel Bookmarks [1] (I was planning a move to Austria at the time). The code is terrible so I never open sourced it. Took it as an opportunity to try a couple of pieces of tech out... much respect to Hasura[2].
When I bought my "new" truck a few months ago, I wanted to load some songs for it to play over USB, but its stereo system only supports artists and albums (via ID3), entirely ignoring playlists or whatever folder structure there is (it just recursively traverses every folder looking for songs). I ended up writing a script[1] which churns through the myriad songs I downloaded via youtube-dl and sets their artist/album/title tags based on the folder and file names (i.e. $ARTIST/$ALBUM/$SONG.mp3). In hindsight I probably could've done this as part of the youtube-dl download process somehow, but it works well enough.
thanks for the link! i had not seen this. after a cursory read, it looks good, and probably has more features. typically i prefer not to use 1k loc and 9 dependencies if 100 loc and 1 dependency will suffice, unless there is a compelling reason to do so.
I created a program that allows me to control the max charge level of my laptop battery on linux, and persists the change through reboot. Written in rust, and I use it several times per week.
I designed it for my system, but it should work on any linux system with a battery, kernel version 5.4+, and systemd.
Keeping your battery charged at 100% for extended periods can reduce the overall life. Apple recently(?) switched to charging phones and laptops to 80% and delaying the remaining 20% until it was expected to be needed (like for the phone, charging overnight completes before the alarm goes off, the laptop will finish charging at the end of the workday before I move from my desk to my living room). I don't know what Windows does, and Linux is too large a target to make any universal statement about how it might treat charging and batteries.
I made a desktop note-taking app for myself because I wasn't happy with any existing options, and it's been great: https://github.com/brundonsmith/writer
- Plaintext
- Single list of notes
- Notes are auto-titled based on the start of the content, and auto-deleted when empty
- Sorted based on recently modified
- Pick a folder on startup, and notes are loaded from/saved to the folder as plain text files (one note == one text file). I use a folder that lives on my Dropbox so I get backup and syncing
- Text is centered and finite-width when full screen, so line wrapping is natural
- All UI except your text disappears when typing, and reappears when you move your mouse
- Light/dark mode toggle
- Made with Electron, so it's cross-platform and easy to modify
I played a D&D character that was, until recently, about as stupid as they could come. Think "Makes Forest Gump look intelligent". A monk who quoted scripture at random that had zero relation to the matter at hand. Never got anyone's name right (always got the first letter right)
So I wrote a discord bot. First in python, then eventually in rust (just because). The bot has a few commands, one to return a random quote from a database, one to add a quote to the database, and one to return a random name that starts with the specified letter.
Of course, things being what they are in D&D, he's suddenly a lot smarter, and the bot is no longer useful. Fun though, an interesting learning exercise.
Many, one fun one that comes to mind is last year I made a Python debugger to output error traces exactly how I want to see them. It can display local variables, print the surrounding lines of code and parent function & class name at each trace for context.
I also made a custom debugging print function to print variable names as well as their value with only having to write "print(var)". It also will print the parent function and class names for context. I use this tool more than the debugger day to day now.
I know there are existing alternatives for one or both of these but there's nothing easier than tweaking a tool you wrote yourself. Plus I learned a lot about Python in the process!
I'm a so called "scientific" programmer, meaning that I use programming as a problem solving tool, and not to create software for others to use. Programming is a lot easier when you're the only user. Here are some items:
* A ransomware detector based on accessing my home network file server via an all-Linux chain that stores file hashes and watches for changes.
* Converting PayPal transaction history from PDF to the numbers needed for my tax return, and some similar tax related scripts.
* Anything involving measurement or data logging, such as temperature, etc. During one episode, I sorted out whether my home furnace was operating intermittently.
I won't count hobby related stuff, which is innumerable.
I'd be curious to know how many people haven't made the equivalent of https://lgms.nl/p/ip/, at least if you're from before when icanhazip became popular
Lots, sometimes intentionally, sometimes not. I'd say most of the things I have on my github I wrote for myself and then put them up just in case someone else might find them useful.
OTOH I thought some people would enjoy this but no one did so unintentionally it's just for me.
I use nearly it every day on one or more of Windows, Mac, Desktop, Laptop, and VR (via Oculus Rift's ability to show the desktop in VR). It does have a couple of semi-showstopper bugs that I need to fix but I'm lazy and it continues to mostly meet my use-case well enough that I haven't gotten around to fixing it.
The most polished and useful program I've made for personal use is an emacs minor mode that lets you scroll down top lines in a file. I was tired of having to always look all the way at the top of the editor window to read the top lines of a file or small files.
The most complicated one I created was a widget showing the status of the factory where I was working at the time.
This wasn't strictly speaking for personal use, but I created it and I was the only one who used it as far as I know.
The info was the same as the main status screen, but I made it frameless and always on top of other programs, and gesture aware. It was about 150 px by 700 px, with little blinkenlights for the statuses. It hung out on the right side of my screen and I could see at a glance whether things were running or not. There was a button to summon the main screen for more details.
The main work was understanding how to handle windows, and UX refinements.
I created a very simple CLI tool for logging amateur radio contacts. There are tons of programs doing this but there was too much clicking, thinking, selecting etc involved or were overloaded with distracting stuff.
I want to play with the radio, not with the tool that should help me with that.
My software simply does the following in the order I want it to do:
* asks me for a call sign
* shows info about the call sign gathered from a API
* shows previous contacts with this station
* asks for date, time, band, report, comment and prefills what it can
* submits this information via an API to an online logbook service
I have created a webapp (very ugly, but it works) to control my bar lighting. It's a wall of 3 rows of ~12 bottles. Each bottle can be highlighted individually, per group, or I have configured a few animations.
It's 3 bands of Adafruit Neopixels, which means I could play with colors as well, and it's driven by a Raspberry Pi 1 (accessible on local network only).
Fun fact: it runs on a computer PSU: the Raspberry is low power enough that it run on the stand-by rail, and the PSU is only turned on (by the Pi) when the lighting is on.
Due to how custom and crude it is, I never considered open-sourcing it. It's a fun party trick when I have guests though.
A simple HTML app packaged via Phonegap for mobile. Server uses Google sign-in and rejects any sign-in apart from mine. Has a URL to generate an OTP token that allows connecting a mobile second in next 60 seconds. Once connected saves the device token in a free-mLabs DB (encrypted). Similarly, generate a webhooks URL for each service and wire. Hosted for free on Heroku!
I've been liberally trading cryptocurrencies for the past several years and ended up with a bit of tax nightmare, with thousands of trades across many exchanges. I found my self with little choice but to write my own capital gains calculator. At the time I needed it, I couldn't find a suitable open source solution, and I have privacy concerns about paid services. It's no longer just for "personal use", as I've recently published it on GH https://github.com/dleber/capitalg
I'm very curious to take a look at this. Built something similar a few years ago because none of the tax software sufficient accomplished what I needed. Mine takes a list of transactions + transfers, and allows me to audit the balance in each wallet (to spot check and make sure I didn't miss anything). It creates csv exports that I feed into bitcoin.tax and use for tax lot selection.
I'd like to update it to handle optimized tax lot selection, so I'm curious to see how you built that part. Longer term I'd like it to automatically import transactions for me, but haven't made it that far.
Yeah bunch of scripts mostly. Things I find most useful are tamper/grease monkey scripts that makes interacting with common websites easier.
- I play a lot of chess and I want to click a button to copy the chess PGNs from chess.com easily while playing a game: https://pastebin.com/UKVUXQxc
- Another one is to grab property info from Redfin and paste it in google sheet for easier analysis and comparison b/w properties: https://pastebin.com/EmH66Q0r
Most of my light bulbs are color-temperature-adjustable. So I wrote a small program which varies the color temperature throughout the day and night.
I started by matching it to the solar elevation, but ultimately I like it more just on a fixed schedule. I've also programmed it to make a more dramatic warm shift near bedtime, and to fade up a bedroom light when it's time to wake up.
Due to the inevitability of scope creep this system also now tracks the charging status and position of my robot vacuum, and I'm working to expand it to collect the 15-minute-interval usage data from my electric provider's website.
I was about to make something just like your light bulb system for my own home (minus the vacuum part anyway). Any chance that code is open source? Very interested in any other details you’d be willing to share.
It's not open source, but the good news is it's relatively simple. My bulbs are Hue bulbs which use their bridge/hub, which just plugs into ethernet and provides a REST API.
The basic loop, run once per minute is:
- Make one API call which returns the id/on/off/brightness of every bulb
- For each bulb that is on, set its color temperature (this has to be one API call per bulb because there is no way to bulk update a list of bulbs. Bulbs can be put into at most one "room" and you can bulk set a whole room but not a subset of bulbs in that room)
As far as scheduling color temperature goes - I just define a few keyframes based on minutes since midnight local time, and then linearly interpolate to get the color temp. Over 24 hours the steps are so small that the change is basically imperceptible.
Hue bulbs, the kind that talk to a central bridge over, I believe, ZigBee.
The bridge just hooks up over ethernet and provides a locally accessible no-nonsense REST api that is surprisingly well documented (sadly requires logging in with a free account: https://developers.meethue.com/develop/hue-api/ ).
Authentication is simple. Press the big button on the bridge, hit an API endpoint within 30 seconds, and you get an auth token.
The only other requests I needed were a GET to list the id and status of all bulbs, and a POST per bulb that is on to change its color temperature (you cannot set color temp of a bulb that is off).
I have many apps and scripts over the years, but the ones still in use are:
1. StrongLift 5x5 tracker. This is a python CLI based script that tracks 5x5 (Strong Lift) program. I haven't used it in awhile, but a few friends still do.
2. HNews calendar style home page. I wrote this as a way to reduce my daily HN screen time but don't want to miss anything. So I created an app (django on raspberry pi) that downloads from HN API and group HN articles by date and point in a calendar style page. Pretty useful, but the code is still in Py2 and awful.
3. A crawler that downloads swim school class availability so I can sign my kids up.
I have created a personal finance tool that Works-For-Me and requires no sharing of login credentials with third parties.
Something that scrapes financial transactions from bank and credit-card accounts in a fully automated way where possible, and semi-automated way where necessary, dumps those transactions into a database, automatically categorizes them, and creates dashboards for commonly used views and analyses.
An old IRC channel I was on migrated to Slack, so I wrote a Python script that logs it in an IRC log-like format, like I use to do on the IRC channel.
I wrote an Android app that tracks my movements if I am moving, and sends it to a server. I wrote it all in about a week in 2018. Have not had time to update it but it works well enough. Have not done much with the data yet, but it has been useful when I am trying to remember when I went somewhere and for things like that.
I use other things, but they're mostly open source programs that I modified slightly for my purposes.
Most of the programs I wrote were for my own needs. I've open-sourced many of them, but some are really just for me and closed-source:
- A scraper to get thousands of quiz questions from popular German TV shows and then import them into an Anki deck.
- Sync app between Foobar2000 and Plex playlists.
- A script to enter Steam giveaways for me. After winning over 1000 Steam games and DLCs, I've turned the script off (mainly due to playing more console games lately). I might do a write-up about this one someday.
- A movie management web app. It's been running for 7 years with low maintenance effort.
What are these? Are they run by steam itself or from random people? I got some results searching, but nothing that looked like it’s an “official” thing.
I was using SteamGifts [0], but there are more. It's not an official Valve platform. The giveaways mostly come from regular people, usually offering leftover keys from game bundles. Some game developers also drop hundreds of keys in a single giveaway - those are listed at the top and provide some visibility/marketing for them. From a user perspective, you are automatically given some "entry points" every time a new giveaway is created (to a max. cap) and you are free to spend them however you want (higher game value = more entry points required). There never was a way to get more "entry points" by paying money. People creating giveaways can set a minimum "user level" to enter the giveaway. You can only get higher levels by creating a giveaway yourself. So the more you contribute, the better games and the less entries you can expect.
In summary, it is just a matter of the number of your giveaway entries to win something. So I've written a bot to enter giveaways automatically, preferring ones with the least entries to get a higher chance of winning. For reference, "I" have entered 289k giveaways and won ~1070 games since 2013 (with a fully automatic bot since ~2016).
One program that I am particularly happy with is a calendar generator for Scribus.
The Python script generates a year calendar, which I then print as a book. It helps me to plan my art career by week, by month, and by quarter. The custom layout somehow makes me take all the planning very seriously. And there is a lot of room for sketching.
Another recent project is a personal mind map, which I can extend to my own needs. It is heavily inspired by Kinopio, which, unfortunately, is not open source.
I am always amazed that not everybody is using computers and programming in this way.
A heck of a lot. Some scripts, other GUI, but out of all the one-offs there are mainly 2 I use every day:
- s3d: fast(ish) image viewer. Basic but it gets the job done.
- Thoth: Text editor with FTP and note-taking features. Even though I uploaded it 2 years ago https://www.mirrorisland.com/thoth but I haven't needed to update anything on it because it does what I need just fine. I also use it to read error logs on various websites via FTP.
I created two web apps to help when playing the boardgame Gloomhaven. Both were coded in Elm and were done partly because I had a need for them but mainly just for the joy of coding in Elm. I'll link the github repos of both, the demo is linked in the README for each.
The first app is Battle Objectives [0] which I made so that my group could play with some "enhanced battle objectives" I found online. The fan-made enhanced battle objectives are freely available on Boardgame Geek but I didn't want to print out and cut out all the cards so I coded them into an app. I linked this app on BGG but didn't think it was getting any use from anyone outside my personal Gloomhaven group. But I also found out while writing this post that someone forked Battle Objectives to translate it to German so I guess someone was using it! [1]
The second one is Hitdeck [2] which I made to automate the tedium of reshuffling my hitdeck and of rebuilding it to add and remove cards as the game went on.
Edit: I almost forgot I coded a complete emulation of a solo card game called Friday [3] [4]. I enjoyed the card game a lot but it's well suited to many fast paced rounds and I got tired of having to shuffle all the cards so I made an app to emulate all of that. It's unfortunately just for me because I never got around to adding a tutorial or anything so unless you already know the rules of Friday you'll be pretty lost trying to play.
I haven been working on my own version of docker-compose that can also work with podman.
But the draw for me here isn’t that i wanted to replace docker-compose, or even use podman specifically, but rather that I wanted to have a one stop shop for generating conteinerized projects using my most used languages and frameworks without having to have any tool chains installed locally, and as a bonus point have a wrapper to be able to issue commands inside those containers without having to use the full docker-compose incantations or having to shell into the running containers.
It’s not a full replacement, and I wouldn’t use this in production. It is more meant to help lower the friction for starting new learning projects.
Right now I can do things like
`wizard new rails -d postgresql MY_PROJECT` or `wizard rust test` or `wizard start`
It is mostly cli for now but I’ve started working on a nice TUI for it as well.
No good reason for this other than not wanting to depend on environment managers, tool chain managers, or a combination of different tools.
I don’t use docker-compose for almost anything now, but projects generated with my tool are fully docker-compose compatible as I also create a docker-compose file when creating a new project with my tool. It’s been a really fun learning exercise and I learned a LOT about docker and the docker api in the process
I had a nice little Python hack that would watch the weather and set the color of a light in the foyer based on the weather, and override that with a dim red at night because I really did not want a bright blue light when I got up late on a rainy night. I never set up the lights after moving across the country so it’s been dormant.
(There are services out there that can set the color of a light based on the weather, OR on the time, but I’ve never found anything that can do both.)
I later created a few games with Unity and Godot which I shared with friends. They were pretty interesting 2d platformer games. I never uploaded these games but some of my friends still play the color shooter game I made with Godot.
As my programming got better, I started creating slightly advanced software like this music player that I had been using for a while as my default music player. I decided to upload the software on 6th April 2022 for public use https://play.google.com/store/apps/details?id=media.mp3playe...
I have been editing code for the last 15 years in an editor that I wrote for myself only.
Most recently, I wrote a "wgrep" program that scans an input of 5-letter words and extracts those that could be a Wordle solution, given a guess and its result on the command line; and another program that determines the best Wordle guess from a list of remaining words (where "best" means "minimizes sum of squares of counts of words with the same outcome").
I created an offline version of YouTube (for Mac). I use Downie to download videos I'm interested in (usually videos download in 10-30 seconds). Then I go to the web app and click play. Using a shell command, it launches IINA and starts playing the video.
I have a mark watched and delete button so that YT's algorithm still works to surface interesting videos.
Having offline videos allows me to watch videos like I couldn't before (even on a stable 1Gbps connection). I can fast-forward instantaneously and there are no ads. Subtitles are also downloaded and a thumbnail.
Another nice feature inherent of offline video is if you want to grab your laptop and go somewhere (I'll sometimes go to the park and eat), you don't have to worry about your video stopping because you don't have internet/need to tether.
The whole app is contained in one executable file (you'll need Ruby) and stores its data in the JSON files that Downie provides.
I've written and still writing small tools to help with my work or personal computing life all the time. Some of them live long and become sophisticated tools, some of them stay as small scripts to help with mundane tasks.
I've also built a backup tool for SMB shares [0], a simple time tracker [1], and a semi-sophisticated tool for helping me managing PXEBoot symbolic links[2].
Currently I'm working on, albeit slowly, on a tool for organizing Pocket (https://www.getpocket.com) items.
I built a Crypto prices chrome extension that shows the top 10 Crypto coins and their prices. All right under my browser, so I don’t have to go to any other website. It’s so helpful, and I love it. I use it every day.
Absolutely tons - my personal gitlab instance has 152 projects in it. I can't imagine not doing this - it makes my life a ton easier. It means I have little tools that work just the way I want, and usually takes less time that trying to wrangle someone else's into working.
The things that I use (or used to use) a fair bit though:
- a whole set of tooling to take my FLAC/ALAC music collection and transcode it to 256k AAC for my phone (including generating an iTunes library XML file I can just import into Music.app)
- tools to automatically scrape content from various websites and alert me / automatically download things
- a client for SchedulesDirect to feed into tvheadend
- various little game-related tools (often to edit data files)
- a slideshow app
- a Formula1 news aggregator
- tools to pair with RTL-SDR to scrape the readings from my neighbours' temperature sensors
- a simple webui to libvirt
- a game boy emulator (this was really fun!)
- a transparent tls proxy to evade geoblocking - uses the SNI hostname from ClientHello to push traffic to different VPN endpoints so I can watch things like F1TV live from the UK
- tools to scrape the DSL stats from my modems when I used to have DSL for diagnosing faults
I also write a ton of small scripts for work use - eg:
- a tool to allow me to pick ECS containers from a list for aws ecs execute-command
- wrappers around the AWS API to generate and update launch templates
I wrote a ton, like most people. The most complex ones would have to be Tax Helper, an extensible accounting tool to get my taxes done in a minute:
https://github.com/DexterLagan/tax-helper
Last one I'd consider strictly personal would be Todo Master, an advanced todo with calendar, preset/macro facilities for generating dev reports and tons of other features only I would find a use for:
https://github.com/DexterLagan/todo-master
I made a Firefox extension (and accompanying autohotkey script) because muting Twitch streams of League of Legends esports broadcasts in between games with my mouse was irritating and I could find no existing way to do it with a keyboard shortcut. https://github.com/RheingoldRiver/MuteTabsMatchingPattern
I'm a consultant who fills out a timecard every week. I made an integration for Toggl (https://track.toggl.com) that summarizes my week, and makes it easier to transfer my time into the timecard. It's mostly for my personal use, though a few coworkers also use it.
When starting my freelance career back in 2012 I had a pretty simple idea on how to track time using only google calendar and this tiny web app I wrote. Used it literally every workday since then, and even got a colleague (another freelancer) to use it with the quote “the first time tracker to ever work for me, and I’ve tried a lot!”. He is still using it last time I checked.
So I guess it is actually used by one more person than me!
I'm generally eager to share what I make, and have written quite a few open source tools. It's gratifying to polish up a piece of software to a high standard ...
But deliberately not sharing your creation, keeping things idiosyncratic and a bit chaotic also has it's charm :) The bliss of knowing that you don't have to worry about code quality or users asking for new features!
I wrote some simple tools, e.g. a note-taking app, and scripts to organize photo's. I also wrote a time tracker :) but I open sourced that one (it's called timetagger).
I wrote a Poker 'tournament clock' application for macOS that I use to run home games. There are many of these out there, mostly commercial software, but I didn't really care for any of the existing ones. I display it on my living room TV and it can be remote controlled over the network from a phone or Apple watch at the table. Never got around to releasing it, as it's mostly a hobby project.
Ignoring that I write software to analyze biological data in a lab, so everything I write is really just for me (and includes a lot of infrastructure type code like a sub-request authentication server for nginx)…
Two programs that to wrote just to make my life easier: one for viewing tab delimited data in a tabular TUI, and another for getting data from my server back to my local machine without using scp. The second one is actually quite handy. To use it, you start a daemon on your local machine. Then when you SSH to the server, it creates an SSH tunnel back to the local daemon. The tunnel is setup to use a Unix socket, so you don’t have authentication issues to worry about (just file permissions). Then to send a file back to your local computer, it’s just “rtun send remote1 {remote2…} local”. The best part though, is if you want to view a remote image, you can run “rtun view file1 {file2…}” and it will open the image locally (it transfers the file as a temp file and calls “open”, etc). When you generate a bunch of figures remotely, being able to open them locally from the remote command line is very helpful.
I wrote a tool to convert a YouTube playlist url into a RSS podcast url compatible with podcast player apps. I use it a lot. handsfreeyoutube.vercel.app
I wrote a simple app to turn an inperson tabletop conversation game accessory (pieces of paper) into something that can be used remotely in a pandemic.
totpal.vercel.app
And I wrote a bunch of debugging/diagnostics tools for node.js. some for fun, some I actually needed.
NPM: debugging-aid
I really didn't plan on writing my own tech stack, because that's the last thing you typically do in a startup, especially if you're the sole founder. Nim has some basic web functionality in the form of Jester and Karax, so I went with it, despite Nim being relatively unknown compared to Python.
A big reason I went with Flutter is because I realized that the mobile market is huge and a lot of people want an app. Flutter can also be used on the web and the desktop. I'm always thinking about reusability of code. What I ended up with is a Flutter rendering engine which can be powered by the back-end in Nim. However the SDK is language agnostic, really, so I'm adding Python support too (Dart is included as it's needed on the front-end). Any desired language can be added in theory, as long as it can produce JSON and send it over a socket.
Yes. There are far too many to mention all of them, but here are some that are probably among the more recent.
Windows clipboard capture to file tool. Any new image placed on the clipboard is written to a sequentially-numbered file so that I can just hit various Print-Screen key combinations or I can right click an image in a browser and click Copy to capture it.
Python / PIL scripts to arrange directories of images into seamlessly connected wallpaper images.
Lots of email automation scripts, both sending and receiving. ( Pruning spam, marking all of my unread messages read, sending alerts for blog post updates. )
Scripts to convert filenames to all lowercase in a folder.
Startup scripts that forcibly turn off Windows options that I don't want because Windows update sometimes re-enables these.
Python/Bash + Cheese - Poor man's security system. I used an old netbook with the camera pointed at the inside door of a house I used to own take a picture of the door area and send it to me via email so that I could monitor to see if anyone had been inside while I was gone for an overnight trip.
Custom RSS aggregator scripts ... sends results to me in email so that I keep a record of the articles by day.
Out of frustration with the built in Mac Notes app, and with the loading times of Notion, I made my own while waiting in airports on the way to and from a holiday:
It was a handy excuse to try out YJS, as I (for no good reason) wanted it to sync live without conflicts, despite it not really being a multiplayer application. It can be opened across tabs on the same machine with updates propagating live across tabs, or by signing in with Google, can be opened across devices/browsers (with live syncing via websockets). I needed this so I could sync notes between my work and personal laptops.
Some other features:
- Keyboard friendly (but very mouse unfriendly)
- Markdown 'preview': typing markdown adds styles without changing what you typed. For example, '#' will still be visible in headings. The only markdown supported is headings, bullet points, and inline code.
- Good luck getting any use out of it on mobile
- Is a PWA, so I can open it on Mac with CMD+Space, 'notes', Enter
It does exactly what I need it to do and nothing more, and is extremely user-unfriendly.
I'd definitely like to, the only thing holding me back is getting the code to the point where I wouldn't be embarrassed by it - it was a very rushed job, and parts of it are incredibly hacky. So it's mainly a question of finding the time.
I made a video player for studying languages (Chinese in my case) its fully keyboard driven and allows marking areas of the video to be looped, so I can play through the video and efficiently mark all the areas with speech, then loop through those and navigate between them. I can also write a note for each marked area, which I use to transcribe and translate the video content.
For our sisters birthday, my brother created an iPhone app called kat in a kan. Just like a vintage toy called cow in a can. When you tipped the can upside down, it would make a moo sound. Ours made four different animal sounds. I drew child quality pictures of animals such as pig, moose, chicken hawk, and wildcat. Select an animal and tip your phone and it made the animal sound. Our sister loved it.
I have an ESP8266 running a tiny webstack on my local wifi that is wired to a low voltage relay that turns on my hot water heater (tankless). Combined this with a Apple shortcut so I can tell Siri to turn on the device (send a post request to the unit). Basically just a hacked together system to avoid using Homekit. It's been running great for 6 years with no maintenance so no complaints.
I love writing those ! They are (mostly) short to write and provide tons of value because they are tailored for you. And for the code/language, you get to choose your level of hackyness vs cleaness.
I personally wrote:
* Scripts to command my window manager (i3): move workspace to other screen, create a temporary workspace, move a window to a new workspace
* CLI scripts to send an ascii version of my calendar to Telegram / Slack
* Scripts to generate complex transactions for the accounting of my consultancy company (eg. salary with the social taxes distributed to the right accounts). I use Ledger, so I also use its Python library to read all the transactions and output benefits/expenses/... graphs with matplotlib. Thanks to the matplotlib-backend-kitty project, I can have the graphs directly in my terminal.
* Scripts to send convert ePub/mobi and send PDFs to my reMarkable, also a fake printer that directly sends the PDF to the reMarkable
* A Pomodoro service with the possibility to subscribe to specific events, eg. play a gong sound when a pomodoro starts
If we exclude smaller scripts then one thing that stands out is a small CLI application (written in nodeJS) which takes all emails from Gmail marked with a special label and uploads their attachments to special Dropbox folder for my company accountant.
So forwarding invoices to my accountant is as easy as throwing a special label onto the email and boom, done.
Was totally worth automating, been using it for like two years now.
For you Elden Ring fans I created a little rune calculator app for me and my friend.
I thought to throw it on reddit, and several thousand users later I'm happy I did!
I've spent <10 hours on it and did it to learn some next.js & preact, and as a bonus, people have been using it.
I wrote one to organise the highlights and notes I make on the Kindle paperwhite eReader. It takes in the .txt file with the highlights and outputs a folder with every book as a txt/md file which contains all the highlights from that particular book. I use it every week when I review what I've been reading. It's a really simple JS file but when it worked it felt like magic.
Another useful one was an Alexa skill to pick which kid at random had to do something (like get their shower first). Leaving it up to chance felt fair in a way that “JFC, it doesn’t actually matter!” didn’t.
I have written these sorts of things, but I do try and put them up on GitHub if I think they’ll be useful to other people. I wrote a tool unimaginatively named wsl-ssh-pageant [0] which I wanted because I use a YubiKey for my SSH key. It has been by far my most popular GitHub project.
I do have other things as well, some on GitHub some not. A scraper to notify me when a local gym booking website changes for a time I’m interested in. A bridge between a BroadLink RM4 and HomeKit for some fans [1] - I wanted to avoid home-assistant. A script to grab my power consumption data. A shim to make gpg-agent compatible with launchd’s socket activation protocol [2].
Oh yes, there are a few things that I have built for my personal use over the years. A few of them I have started publishing on the iOS Appstore.
1) The most used one: An iOS app that I use to push myself articles from RSS feeds. I can send notifications via post request to a webserver (similar to services like Pushover). On the device I can select to read later or read directly. Inside the preview of the notification I have placed a WebView so that I use rich html content as preview. The app itself is a RSS reader that I built to learn SwiftUI [0].
2) More recently: A cron+python script that fetches the current queue from my sonos. It creates a list of viral songs and creates our flat-charts from the songs that either myself or my flatmate have added to the queue since last execution of the script.
3) An iOS app to help me create timelapses by taking one photo per day. For instance, I used it to create a timelapse of a blooming tree in spring. It uses OpenCV for image alignment.
4) An iOS app to track my camera setup for film photography [1], and a small flashcards iOS app I use for language learning [2].
5) A website with a covid map of the region i live in (because there was none).
I recently wrote a tool that allows me to copy AWS secrets to another aws account for testing. It ended up being far simpler than doing a copy-paste for doing it repeatedly. I plan to write a few more in the appropriately named repo.
Lots of small little scripts lying around in bin/, some of them for extracting information or downloading stuff from certain websites, some for small admin tasks.
Possibly the most useful for others is a small wrapper around pdftk that splits a PDF file into smaller ones based on the "bookmarks" (the chapter annotations that many PDF readers show as outlines in a side bar).
> Possibly the most useful for others is a small wrapper around pdftk that splits a PDF file into smaller ones based on the "bookmarks" (the chapter annotations that many PDF readers show as outlines in a side bar).
I'm interested in this if you are willing to share.
I've built tons. Most of them don't stick for long. One that has is a file-cabinet organization tool - https://github.com/robacarp/place
- it moves files into place within my filing system
- renames the file so that even if it's moved _from_ the filing system I can see where it came from (eg sent in an email)
- uses a custom TUI engine I built for this specific task https://github.com/robacarp/keimeno
----------------------
Another is a clean, bare bones, web-extension mode "picture on a new tab" extension. When I came back to firefox a few years ago I couldn't find one amongst the clutter on AMO so I put together https://github.com/robacarp/photographic_start
This is my favourite passtime. So so many little scripts. Some fun ones:
* cli tool to diff changes to a branch since the last revision you looked at when it has been rebased (only if you haven’t git gc’d!!)
* use fzf to choose from pulseaudio sinks/sources, changing the default and applying it to all current audio streams (ex.change mic or to headphones)
* change the default linux webcam by renaming devices, runs as a udev hook.
* various arch tools. Automatically download mirrorlist and enable the fastest 5 sources. Download/extract a package from the aur. Fzf multiselect all of the .pacnew files, vimdiff them, and delete the .pacnew files for files that changed. Also my own install script with choices for ext4 or zfs.
* use mplayer to play a video as the background on all monitors. I downloaded several 10hrs of ocean/forest sounds and alternate between them.
* tool to convert restructured text to html email in mutt
* using xargs to parallelize updating my most common config repos
* index all git repos on disk, then either fzf choose from or choose best match and cd into it. Not my idea, but I love it so much!
* makefile for my i3 config that looks at avail displays and gives me 10 monitors per display with the same hotkeys (like dwm).
* choose from several presets and recompile st with a different colourscheme.
* categorize all of my bank transactions to monitor my spending over time.
* a cli DM with different Xorg configurations and window managers (music keeps playing, fuse mounts retained). Useful for multimonitor games that require different setups.
* wine, proton scripts to manage prefixes and cd to common windows directories within them.
1) backed up simply by storing in Google Drive (no special servers or DBs)
2) was principally for Markdown, but capable of storing entries of any type
3) dispensed with any form of folders in favor of tagging and a powerful search, using only the filename to store the tags
I couldn't find anything I really liked, so built https://github.com/mieubrisse/cli-journal . Haven't needed to modify the code in 2 years and it's still working great.
I'm currently (lazily) working on Montu, a terminal app that will read in a Markdown checklist and allow you to check things off with Vim-like bindings while editing the underlying checklist: https://github.com/mieubrisse/montu . It started with my desire to automatically check off the parent checkbox when you check off the children, and grew from there.
- Text snippet app to reply to support request emails. Use this to reply to about a dozen emails each day. I have over 300 snippets.
- App to got through a folder with my bank statement PDFs and produce a number of transaction and investment reports (calculates IRR and other metrics).
- An app to simulate all possible portfolio combinations for a given set of assets (this was before https://portfoliocharts.com)
- An egg timer that you can start before you set the time right after you put the eggs into the water. Those seconds are precious. Wrote this as a gift for somebody.
- App to generate monthly invoices for my app sales.
- A nice frontend to manipulate csv files.
While I was looking for an apartment, an app to look for new listings and notify me right away (often the nice apartments would already be gone by the time the daily email reached my inbox).
A workout timer. Simple app that tells me the time every 15 seconds. Throws in the occasional Tony Horton quote for motivation.
Those are just the main ones (as in not small, and used every day), and ones that fit what I assume your criteria: ones with no expectation of users other than me. I find myself fixing problems all the time by writing code.
Browser based game where you try to pick two matches cards. When the pandemic started, I played this a lot with my kids (they were better every time). Got tired of shuffling cards and laying it out and I wanted to learn Javascript, so.
My daughter had to learn spelling of a few words every week in Grade 2. To help her test it, I wrote a Windows desktop app that would say the word and she had to spell it.
I had too many tags that it became useless so I had to retag all my links in Pinboard, the website doesn't let you do it in bulk so I made a Windows desktop app (also wanted to try out XAML).
I combined a series of state collected freshwater bio/fisheries data into a web app that maps it out per lake. I use it for discovering and targeting specific fish species within a given area (town/county). I used it with much success during ice fishing season and have started using it for canoe trips to target bucket list species I want to catch.
Yep! Made a note app for tracking HN users. Fun making it build React in Greasemonkey before the toolchains matured to make it kinda trivial. It ran off of a real database because I use a few different computers, so localstorage wasn't the right thing.
Stock research platform using relatively cheap ($X00/yr)fundamental data & free pricing APIs.
Had a fun "fight" with a major pricing website for a game. When your (rate-limited! trying to be nice!) crawler needs to turn to OCR to defeat css spriting and they're leaving comments in the HTML though... a bit too combative. Fun project making it work though.
Any game with an economy I end up making stuff for. Personally, I wish games weren't so hostile to automation or user time these days!
I also once SaaS'd a weird file format translator thing on heroku for myself; sometimes old formats or algs do really just disappear!
I've made some small modules for my MagicMirror but haven't had inspiration on further stuff for that just yet.
One of my first projects was a simple stochiometry calculator library in Common Lisp, for high school chemistry class(for my own use only). It had classes for acids and bases and I could do things like make a 1 liter solution of water and add x moles of some previously defined acid. It would then do the appropriate "reactions" and end up containing the appropriate equilibrium concentration of said acid, its conjugate base, and H3O+. And I could calculate the pH etc. It was very SICP inspired. And it allowed me to check my work during tests. It was also an excellent way of learning to do this type of stochiometry by hand.
I made attempts to extend it to various org-chem concepts, but it quickly became far too difficult in terms of modeling the molecules and reactions at that point and I quickly gave up on it. That taught me a valuable lesson as a budding developer: Some problems are just too hard, and the sooner you realise, the better.
I created an accounting system for self-employment activities that does everything: invoicing, tracking expenses and assets, capital cost allowance depreciation of assets.
I have a web app called Tamarind (acronym for throwaway mail alias randomization is not defeatable). I can create randomized e-mail aliases there which instantly go live. Likewise, delete them. Each entry is associated with a memo field that can contain URL's (these get rendered into links). Also a date of creation. The UI lets you edit the order: selecgt entries by checkbox and move them up and down, or to the top or bottom. There is a regex search box. It can authenticate the user using SASL or IMAP4. It works by editing a mail aliases file; your mail server has to know to include that one. It can work with the main /etc/aliases; Tamarind will avoid modifying any parts of the file it doesn't know about, confining itself to the area between its markers.
Took about a year to finish a TradingView like app, with features TradingView doesn't have and missing features it has that I don't care about. Intention from the start is it's just for myself, as making publicly available would take longer plus time needed to support, which may or may not be recoupable even if I charge for it.
Darn yes. I built a web based RSS Feed Reader that can also subscribe to e-mail newsletter. It is really just a stream. No nagging, if there are unread messages. Categorisation and search are only second class citizens.
I found that everything else will overwelm me time and time again.
I really wanted to publish it for others to use. Without any serious subscription or payments, maybe patreon.
The "problem" is, that I'm based in germany and you can't just have a website, that integrates other peoples content without having a good lawyer, I guess.
Plus it would be a really good idea to block any scripts that feed creators put in their stuff to f*ck with other peoples systems. But you're not allowed to change feed content, or at least that might be a concern.
Not to speak of if people subscribe to illegal stuff and you show it on your site (even only to them), maybe?
Too much uncertainty, so I'm nearly sure I will stay to be the only citizen in this neighbourhood.
This probably isn't quite what OP had in mind, but I put together a number of Python and Bash scripts to control my home media center. Then I used the iOS Alfred app to give them a front end on my phone as a remote. I also made them actionable with various flags so I could call them by typing them into the Mac Alfred app.
Power on / off home theater device and set inputs
Power projector on / off and set inputs
Make calls to both at the same time working together
Call AppleScripts to control music playing through the stereo from a connected Mac mini
I also built a tool for a friend in Bash and AppleScript. It watches a list of his favorite streamers and then calls to the Downie video download app to begin recording their streams. He runs it on a headless Mac mini checking each person in the list every two minutes.
Of all the things I've made for myself or others, these are the two that would most resemble a user-facing GUIable end-product.
I got so sick and tired of `rm -rf node_modules` that I made a tool to do it for me, recursively, and eventually supporting tons of different project types thanks to open source contributors.
Most are just one-off utilities to solve a problem. Some people would do them in bash, or python, or PowerShell. I do them in C#, because I know it well, and can code it without thinking...
A Few 'Big' programs I've written are:
- Custom SMTP server to proxy in front of an Exchange Server - ran 24/7 for over a decade until last year when I migrated to Exchange Online.
- Gopher Client for Windows which people actually use! [1]
- A application launcher/dock thing that sits at the top of my screen with drop down menus for apps sorted into categories, because I cannot stand the windows Start menu.
- A similarly useful transparent current-month calendar that sits in the bottom right of my screen at all times, which saves me having to click on the clock to find out what date 'next Wednesday' is etc.
- An RSS reader in PHP that I use multiple times a day. It's different to most others in that it only shows the current items in the live RSS feed for a site - it has no history. I prefer that, so I don't get anxiety with unread items.
A nice recent one that's only been in constant use for a few months is a Python script that dumps all the data from my weather station and logs it into a MariaDB table. I'm not doing anything with the data just yet, just collecting it. Once I have enough back history to play with, I'll write a web app to display it all nicely.
I could go on and on.... my 'Source Code' folder is massive, full of useful stuff, and half-written ideas.
Much depend on what you call "program", in "scripting" terms I've written very many, countless, most buggy limited wrapper but very useful time-savers, an example (witch was derived by many others similar, I can't remember them all, this is my version) http://ix.io/3Vbk like this I have around 20+ in use, some written years ago and left almost untouched, some evolved. In "config-as-programs" terms my Emacs config, witch is actually an elisp program is around 4800 lines, my NixOS config, witch is in Nix language, so another program, is a bit more than 1500 SLoC etc. If you means large WebApps, GUIs etc no, I've write some small GUIs and very few WebUIs for some relatives/friends but not for my own personal use...
- A program for backing up my Master of Orion Save Files
- A program for finding the best planet in Master of Orion
- A program for calculating my walking pace from time and milage
- Many simulations for various games
- Several Markov Decision Tree solvers (fairly simple dynamic programming)
- Many game strategy solvers
- Programs that process my life documentation notes - miles of jogging/walking per month, energy level, wake up time, productivity
- Many programs for testing mathematical theories or other math research for fun
- Physics or Astro-physics simulations
- Investment simulations
- CPU Benchmarking programs
- Programs for drawing graphics - spirals, mathematical objects, ...
- Lots of programs for Project Euler or LeetCode - just for fun.
(I probably write around 100 small programs a year for myself, mostly for fun.)
- Web page diff notifier with various heuristics, sms/email notifications, screenshot logging, and js page support.
- Linux keyboard macro tool.
- Dozens of scripts that I use daily to automate parts of my desktop, eg detecting where my laptop is plugged in (or not) and change the display setup, backups, grabbing the local weather report from the most reliable source, etc.
- Simple password manager with Google Secret Manager as a backend.
- A whole bunch of user scripts that fix issues on web sites that I use frequently.
- One or two browser extensions that also fixes web sites. Keyboard shortcuts for the HBO video player. Intercepting requests for certain web sites to swap some calls to a different backend.
- Fork that adds some features to a screen locker.
- Random name generator based on Markov chains in combination with user input and randomness.
And many more! It was fun to see what others are doing, thanks for sharing, everyone.
It's probably not completely correct and there's probably issues stemming from the fact that text in web browsers is UTF-16 not UTF-8, but I've used it to quickly figure out that someone's input wasn't being parsed correctly because the spaces were actually non-breaking spaces for example. It can be used for noticing when some text has a letter that looks the same but is actually a different letter than you think (homoglyph attack) or to see what makes up an emoji.
1. https://github.com/hamon-in/invoice - A command line invoicing system. I wrote this to handle invoicing for my freelancing and later my company. I wanted to build something similar to ledger-cli for invoices and use a single sqlite db for all things including config
4. https://github.com/nibrahim/showkeys - I wrote this to allow display of keys on the screen while recording technical screencasts. I was recording a series on Emacs at the time
There were a few others that never saw the light of day but these were the ones I wrote and still use/used. There are also several smaller shell scripts, makefiles, elisp snippets etc.
Auto-folders are explicitly banned by basically all online poker sites.
They are practically cheating. Of course if it folds certain hands a 100% of the time, then it’s just horrible for you, because no hand is a fold 100% of the time.
Even 72o is playable from the big blind if you’re the one closing the action and the price is right.
You should probably consider an autohotkeys script, or a mouse with macro buttons.
I used yt-dlp to download the metadata for the whole SNL youtube channel, over 6000 clips. I loaded it into a database and wrote a Flask app to let me browse through each episode quickly and choose which clips to download. Now I have about 500 of my favorite clips available locally on my Plex server.
I took a year to write an app to manage my stock portfolio... Everything from stock selection based on fundamental value analysis to tax loss harvesting and gains capturing. I used the Interactive Brokers API to manage my funds and get data along with a Schwab scraper to sanity check data. I currently track 36,000 stocks from every major market on earth. My portfolio is balanced primarily between Japan, US, Australia, and European markets. I manually blocked China and Russia to due to governmental risks in those countries. I now can just run this program with no supervision. Returns have been 20-40% a year with very low risks as I am looking at companies with very high revenues and profits compared to their market price with no bad years in the last 5-10 years.
I have some useful ones for everyday things, converting one thing to another. Renaming things. Moving things around.
But the most interesting ones I have are the ones that do illegal things. Like download things from other countries, store them on a remote box, do everything behind a pseudonym not associated with my personal online profiles. A lot of NFT mining stuff, so everything becoming available and its prices (if guessable), some of this stuff I share with a small circle but I am not stupid so I don’t like sharing any of this code and it’s not even on my primary computer. Just sits in a nondescript raspberry pi. One of the more illegal but traceable ones was with crypto trading (where I was inflating the price of a coin by a few percentage points), I had to stop because it could be tied back to me.
I've built several personal projects to be honest; background jobs, tasks automation, telegram bots to find a house to rent or buy, most of them are kept provate.
The two I'm most proud of are a web analytics that, coincidentally, I've made public today after a few weeks of work:
I developed it for collect data for my personal website and it is working well so far, really happy of it.
The other one is a Google Chrome extension to manage bookmark because I think the default one is a mess and very unpratical to use. I haven't worked on it for a while:
Dozens, at least. Everything from: NAS apps that download television Electronic Programme Guides and automatically schedule recordings; to personal radio stations that integrate text-to-speech, calendar entries, local news headlines and the family Slack channel with the music on my home server. Utilities for managing the books I read and videos I watch, utilities to randomly insert quotes in my email signatures. And that's before we look at any of the work-related software.
Mostly these are written in Object Pascal via Lazarus and compiled natively for the target platforms, or they're web apps written in javascript and/or PHP. Many use SQLite for data storage; some just use an .ini file if the data is simple and not too volatile; a few are written against a MySQL back end.
A few that I've written to scratch my own itch or fill a need. Some of which I ended up sprucing up a bit and publishing publicly.
sitesync - Program that could sync files and folders on local file system and remote (FTP or SFTP). Mainly used to help maintain a web site that other people were also modifying. It allowed me to develop on my local copy and push changes without clobbering anything someone else had changed. (Unpublished)
erudite - [0] - Pull articles from Instapaper or Pocket and add to your ebook library (including Hacker News integration that includes URLs for corresponding posts!)
bday - [1] - The super simple birthday and anniversary reminder program. Wrote for myself but several family members also like it. Originally on Windows and then ported to Linux as well.
moviesschedule - [2] - Tracks Australian movie release dates and can even maintain a Google calendar of the movies you are interested in.
coffeegrinder - Java program to help fold automation of coffeescript compilation to javascript. Included optional GUI for viewing javascript version updates whenever the .coffee file was saved. (Unpublished)
bom - A little web-site and FTP scraper to retrieve local weather info from the Australian Bureau of Meteorology. (Unpublished)
bgdicecalc - Little GUI program to easily figure out probabilities for various dice rolls in Backgammon. Want to convert this to a web-page some time. (Unpublished)
feedme - Web-site scraper to create RSS feeds of various comic strips (e.g. Dilbert) with the image directly in the feed. (Unpublished)
I ended up with so many random git repos, shell scripts and other miscellany that I ended up writing a tool to manage that stuff using a yaml file so that it's easy to transport and recreate my setup anywhere.
"garden" is kinda like a mashup of the flexibility/power of shell scripts with the convenience of being able to declare your development environment.
Most recently, I've been building a small server for myself to track my day, todos, and just act as a frontend for some easy scripts (eg. just a direct line to running date to get timestamps). It's been a joy to use htmx and flask and just crank out features quickly.
I've written many scripts and programs to make my life easier (and just for fun, really). Here are a few of my most used programs:
- A service that constantly checks for freelancing/contract jobs that meet my list of criteria, then sends a desktop+phone push notifications for me to take a deeper look.
- An automatic backup service that uses Borg and triggers when I connect my external hard drive to my computer. It handles all kinds of failures and knows how to organize my stuff too.
- A savings and spending tracking and reporting dashboard, because I just couldn't find one that "clicks" with me.
I think most of my programs are just automating things I use regularly, but isn't that the point of software, really?
If you don't mind me asking, do you run the first one on your local computer or do you use some kind of cloud service like ec2 so it runs constantly without worrying about down time?
I originally wrote a web app to track my finances in 2003 using classic ASP and T-SQL. In early 2017, I rewrote it from scratch, still using T-SQL, but with C#.NET and jQuery. Lets me review my budget, ensure my net worth is heading in the direction I want, make sure all my payments get made, and ensure my account balances never get too low (with a light forecasting element.)
Ideally I'd open source it, focus on the API documentation so anyone could write a back end, and iron out a few more front-end bugs, but since it gets the job done for me, the motivation never quite strikes me.
I use YNAB4 through wine and wrote a little CLI utility to ingest CSV statements and format them to what YNAB expects (with currency conversion at the transactions rate for that day). It works well and is all local.
I have a hobby-project where I collect stickered Laptop-Lids [1], and since I get most photos from twitter or by mail, they are often not centered and straight, but somehow skewed. I made a small MacOS-App [2] with Swift that allows me to click on the laptops corners, and export a cropped image (using CIPerspectiveCorrection). Photoshop has this exact feature under "perspective crop", but I wanted to do some Mac-Dev and save some time by not having to boot PS.
Yes, I tend to write small programs like that all the time, it's one of the reasons I like computers, to write programs to do things.
A few I remember:
The FinalKey, hardware device that acts like a keyboard, is a password manager.
OSGG, a lander game I actually want to play.
Chromogen, a bash script that generates lovely static image albums.
"sovs" at work, which fetches a fresh source tree because our procedure requires calling multiple programs with multiple parameters.
Lots of one-off things to fetch something out of some file or do some task on a set of files, for example, I made a utility that let me batch cut video files by giving a list of start-end times.
My memory fails me, and I think it means I should probably be better at keeping those utilities around and organized..
I had access to flight information through an API that my work pays for and I rarely care exactly what day to arrive or depart. So I created an application that would dump all flights to a destination over a range of leaving and return dates. It dumped all the data into SQL database so I could filter on price, number and duration of layovers, class, etc. It was incredibly useful for really dialing into what I wanted (no layover over 3 hours, less than $X, etc). Using Google flights is painful by comparison.
Unfortunately I no longer have access to that API. The last time I flew I did this process manually and slowly discovered I should leave on a weekday and leave on a weekend for the best flight.
Yes. Programs that read from stdin, like filters, for making HTTP requests, processing HTML and other marked up forms of text, extracting URLs, encoding/decoding HTML or URLs, extracting binary files from HTTP responses, and so on. The programs I write can be linked together through UNIX pipes and and can do things that programs written for other people, such as curl, cannot do. These programs can in turn be used in scripts that perform more specific tasks, such as the energy consumption monitoring example. I generally do not need any help from browsers or "web APIs" because I have programs to process data/information from the web in any format. All I need are URLs.
I created a web app for doing personal accounting with GnuCash files [1]. The mobile app for GnuCash was abandoned around 2018 from what I can tell, and it never had synchronization, so you couldn't easily use it on both mobile and desktop at the same time.
I'm one of only two users as far as I know. It's in a public repository, but I doubt anyone has used it. Personally, I use it nearly every day, and it has enough features that I rarely have to use GnuCash anymore.
The app isn't the most beautiful thing in the world, but it works just well enough to be usable.
Right before seeing this, I was using a JavaFX application that I wrote to extract highlights from videos that I shot this past weekend for my daughter's volleyball team.
I wanted tool where I can zoom in using the mouse wheel and have the zoomed clip extracted. Needed the basic features of HUDL (https://www.hudl.com/), but the generated videos are local files and not controlled by HUDL.
Another UI tool I wrote and use is a tool that scans a directory for JPEG files and uses the EXIF data to create a hierarchy of directories in <YEAR>/<MONTH> format and moves the files to the directory corresponding to its creation date.
Years ago, I wrote a complicated Perl application designed to address the fairly strange way that my first wife and I thought about finances. We had two orthogonal ways of dividing up our money: purpose and location. So perhaps we had $1000 for some purpose, but it was actually invested in 4 different locations. The Perl script did some early web scraping to get the balances from each of the locations where we had money, then did the math to divide those balances up based on allocations, and finally presented it to us as a "bank statement" broken down by purpose rather than by location.
I haven't used that approach to money in a couple of decades, but it was very useful for a while.
I started using python scripts to invest in the stock market when nobody did that and earned some money.
I modified a digital hygrometer and thermometer so I can register the temperature cycles inside and outside my house. I also do it with my plants in the garden.
I reverse engineer all my GPS(garmin) clocks so I can store or upload GPS coordinates and tracks without some stupid and inefficient web app that the manufacturer controls for me.
I reverse engineered and hacked the routers from old Internet providers and posted the instructions on the internet for others to replicate.
I scan and OCR and process every single ticket and receipt... Do the same with books.
I also have friends that do the same kind of things so it is kinda normal to do those things all the time.
I recently developed a command line chat app that I can self-host, to chat with my friends from the terminal and regain control over my chat data and metadata. I self host the back end in Linode and just for the lolz and "Unix portability" I wrote it entirely in C. I don't really expect this to be useful to anybody else than me and the couple of friends that also use it. I can now chat from the terminal during my working hours and my colleagues think that I am doing something mystical in the terminal or developing in Vim.
Loads, but funnily enough they're something I rarely, if ever, use. Most of it has been dev tooling stuff, especially for game dev, but I've also worked on a few projects for my personal life as well (which again, I never ended up using).
Yes of course. Multiple programs in various languages. I find it helps to learn a language or concept by coding up a personal project to achieve the goal I set. I've written web applications and desktop applications, working on writing a few mobile apps too.
Static blog generator from markdown to HTML - Golang
Selfhosted HTML LAN dashboard - PHP
GPIO garage door opener on a PI - Golang
CLI Geoip lookup from mmdb to stdout - C
SNMP client - C
Various web sites - python/flask, bare HTML/JS, Golang
User login 'guardian' daemon (time frame for kids login / tracking) - Golang
Spotify listener - Golang
Web scrapping bots - python
Reverse regular expression (regex pattern to strings that should math) - Golang
CTF score keeping/flag tracker - Golang
And many other small snippets in Perl, Python, C, shell, etc just for one offs or scripting needs.
I'd been dealing with an RSI issue for about six years and had largely given up programming because of it, seeing no way around—then had an idea for a new kind of code editor that would let me program with motion sensors instead of seated with mouse + keyboard: http://symbolflux.com/projects/tiledtext
Once I was far enough in I saw the tech could be generalized beyond my own personal use case (it is vaporware though, never got the level where others could use it)—but 99% of the drive was just making something so that I personally could code without pain again.
I didn't go the voice route because I'd read stories about people messing up their vocal chords that way—but it's something that could be looked into more closely for sure.
(This was also 2006 - 2012; the voice packages I tried then were rough, surely improved now. Then again, my RSI issues area nearly absent now :)
I've built a lot of "cheat" programs for games. Ranging from full on bots to something that just gives me information to act upon.
I also built a very rudimentary market analysis program for Eve Online back when I played, to help me play the market and optimize what I would build/mine/etc.
I have a simple chrome plugin that will auto-fill a form for me with random junk. This makes manually testing a UI with forms a lot faster.
Back when I had a lot of DnD books in pdf form, I built a program that would let me create a set of bookmarks across all the PDFs. DnD likes to spread classes and spells across multiple books, so this made it a lot easier to find stuff.
Probably it doesn’t count yet but I have a substantial spreadsheet (20+ sheets) that tracks all my financial life: net worth over time, expenses, taxable lots positions and loss harvesting opportunities, RSU vesting, investment returns, 1040 tax approximations, ideal portfolio allocations and rebalance thresholds, taxable equivalent yields for municipal bonds, safe withdrawal rates approximations, …
I built that incrementally over 10+ years out of necessity and one day I’d like to convert it to a little SaaS and see if anyone would pay money for it. Probably not but it would be a fun exercise so I could add automatic scraping of bank/financial accounts.
I created a simple command line utility [1] to convert between rotation representations. If anyone has ever dealt with 3D rotations (e.g., euler angles, quaternions, rotation matrices) you probably know that it can be frustrating to know what conventions people are using, especially with euler angles (e.g., intrinsic, extrinsic, passive, active, etc.). So I made a tool where you can explicitly set those conventions with explanations on what they all mean.
I regular refer back to the README myself or test out some conventions with the tool.
I'd be surprised if there existed a significant number of software development professionals who could answer a flat 'no' to this (although I'm certain there exist some amount who only do it when it is more direct a solution than anything else, and not for its own sake).
Most of the code I write for personal use is for one-shot scrapers or "query this database and fiddle with that information to give me something interesting"--the only things larger in scale than that which I continue to work on are a Discord bot and... well, I had been working on a Slay the Spire mod and it's been rotting for quite a while.
Lots! Mostly little scripts. Even a single function is a complete program, like the one I wrote to check for a domain drop, which I then snagged! Of course the dotfiles and dotemacs must be mentioned too.
Two days ago I realised it has no if statements! Now that is going to become a design goal ... I need to add 2 or 3 things to make it fit my requirements, but I'm going to keep the if-s out without resorting to weird contortions.
The only two programs I've written since my retirement were entirely for personal use: one to help with attribute-point assignments in an RPG, and one to pick apart GPS-data files (Garmin FIT) to show me views that neither Garmin nor Strava will. I'm fortunate that I have the skills to do this, but I think in the future such "personal programming" will be commonplace even for people who have never worked as programmers. Meanwhile, knowledge of programming plus one other field is often a ticket to stable employment with a good work/life balance (unlike tech itself which tends to lack such balance).
1. A minimal "docker-compose without docker" tool. That allows me to run a group of backend web services with a single command and multiplex the terminal output.
2. A browser chooser that I set as my default browser, and which pops up a UI that allows me to choose which browser (and if Chrome, which chrome profile) I want to open links in. Super handy for making sure links get opened in the browser (profile) that has the correct cookies for that account. There are other tools that do this, but they are either written in Electron (slow) or don't support chrome profiles, or don't support macs.
In a few years, I intend to embrace marketing. However, now I am on the pathless path wandering. I'm writing a post about it, and I'm kind of fine if no one uses it. Sure, it would be amazing if others would see the neatness, but I'm not really in a space for responsibility yet.
Perhaps, I'm going slow on building yet another deck builder with it (as I'm looking into which components to buy versus build for the IDE aspect), but I'm basically retired.
My home automation software is janky and bad but it works the way I want it to. It's technically open source but I wouldn't recommend it to anyone. I actually run the same software in my car, mostly to handle music, but it has some car-specific features. A fun bit of tech debt here: I wrote it solely for myself but I'm married now, so figuring out how my wife will interact with it (other than texting me to send it a command) has been an interesting new problem to consider.
My library website is similarly jank on the level that mostly only I should use it, though I have worked on generalizing it a bit.
Yep, mostly to do with saving articles and replacing my use of Pocket.
I host a simple API that converts web pages to markdown files using headless browsers and save them into my cloud storage. I can now read the pages offline and free from clutter using a simple markdown viewer or use my own personal website to read them online.
I also have an email address that converts the mails received in it and turn them to markdown files using the same headless browser mechanism. Now my local text editor can sort of act as a mail inbox of its own.
I'm pleasantly surprised by the things I could accomplish with Shortcuts (Mac, iOS) + some webhooks.
Latest one is written in Kotlin and compiled to a single executable.
While I know many here dislike “crypto,” it’s used to calculate some details on some OpenSea NFTs I’m interested in. The details on each NFT are varied, but two of these NFTs can have their details combined to create a “more powerful” NFT. Don’t think I should bother going into more detail, but the code calculates every permutation of the details for all the NFTs to identify the best combinations. Didn’t take long to write and I did it for fun as I never compiled Kotlin down to a stand-alone executable and I wanted to give it a try.
A few ones, mostly scripts, a few personal webpages with a blogging platform, webscrappers and plugins for language learning in Anki, and a chatbot. For sure more software as part of software development which would be more likely "for work" than "for myself".
However very few of those pass the test of time, as it is hard and costly to maintain the quality of a comercial product which has invested the time in usability etc.
Software is a lot of work, but getting started is fun and people can achieve a lot within the few hours. The last touches is where the real greatest effort has to be brought in.
Lots! The most fun one recently is a set of Python scripts for getting audio easily onto my iPhone, where it can be played with Decoupled (https://decoupled.app). That app is awesome, but it doesn't support playlists, so the main thing my script does, beyond the logic of sending the files (via FTP), is use ffmpeg to change the "artist" and "album" metadata for all songs in the playlist, so that I can browse by (playlist tag)/playlist where it'd usually be artist/album.
All the time. Most recent was a little node app to quickly create Google Meet meeting links. For example when using MacOS Calendar and wanting to schedule in a video call. There isn’t an official Google Meet API so you have to create a Google Calendar event via the API and then add the meeting to that.
This was wrapped in a MacOS Automator workflow, which in turn was wrapped by a keyboard trigger in BetterTouchTool. So now, when I hit Cmd Shift M, a Google Meeting link is created and pasted wherever my cursor happens to be!
It makes a little boing noise too when it pastes the URL which never ceases to please me.
Not for myself, but I once developed an app that would export notes from my dad's Bible concordance app to google docs for backup. At the time, I knew how to use the LAMP stack, so that's what I used, LOL.
I created a program that I could point at any directory and it would copy all the photos to my external backup drive. It would organize them by year and month from either the metadata or the filename. It would ignore duplicates based on file size or timestamp. I had a low-resolution filter to make sure I wasn't getting thumbnails.
I had photos on all sort of old phones, old laptops, and various external drives for both me and my partner that I wanted to organize to make sure nothing is lost. This program allowed my to just run through everything and let to do all the hard work.
Some of the more useful (to me) scripts that I've hacked together:
- Flash card generator that combines ffmpeg, waifu2x, and other libraries to upscale clipart and turn them into flashcards for use in a classroom. Sizes it for printing on a number of standard paper sizes. It was really useful for when I used to teach children.
- Tunneling script that, in a much less elegant way, did what ngrok does before ngrok was a thing.
- Backup and restore scripts to reprovision my linux computers.
- Pomodoro timer that can warn you (text-to-speech) and optionally set your monitor brightness to 0 for N minutes to force myself to take breaks.
A note taking app that does exactly what I need, and I can expand it. I will soon add sharing of notes with my wife.
A home dashboard that gathers information from family calendars, school timetables, weather. All this readable from distance.
A chores app (that also displays on the dash above) with info about whose turn it is to fold the laundry, get out garbage etc. It worked for some time and then we reverted back to everyone yelling at everyone to do it.
All of these already exist but I wrote them to exactly meet my needs, and nothing more. Plus I learned quite a bit about Go, TS and Vue.
I have tonnes. Sometimes they're applications, sometimes they're libraries. Recently I've been interested in random experiments to push my exposure to ideas in strange ways. Most recently I wrote a redis module for encryption (https://github.com/chayim/redicrypt). My current project asyncronously fetches me status from various services (GitHub, Jira, Travis) so that I can track all sorts of things.
Personal use is the biggest driver of my ongoing learning.
The magic here is that there is a lot of hidden, intrinsic value that comes from doing this sort of thing, which isn't immediately obvious to others, and often even you at the time.
I have noticed a trend, when creating software and technology projects for myself, which is that a surprisingly percentage of those projects end up being useful in the not too distant future for commercial projects. In ways that always surprise me.
And even without that, the skills I learn tend to end up being as valuable as whatever direct or time-saving value the script/program gives me.
I've recently written my own static-blog generator. On the one hand, I got irritated trying or figured out I would quickly hit limitations with the popular ones. On the other hand, the effort I would have spent searching for and evaluating the hundreds of existing other ones is on par with re-implementing my own.
A customized screensaver that displays random static zooms of my art collection. (Modified from one that would only do animated zooms.)
A Python script that grabs a wireless numpad keyboard (using evdev on Linux) to be used as remote control (volume / next / etc.) instead of keyboard.
A command-line tool "t" to translate a single word using my own match heuristics and a textfile-as-dict I got from somewhere (never updated). Wrote it ~15 years ago, still in regular use.
Tons of others (sleep tracker, custom RSS reader) that I used for years, but eventually stopped using.
Mainly reinventing all wheels for myself, operating systems, code editors, game engines, programming languages. Nothing really hit a state that actually replaces my current tool yet, but definitely fun.
I wrote a web app in Django to automatically transcribe audio interviews, annotate the transcriptions and extract audio fragments. I started building it to help my wife with her MA thesis, as an alternative to expensive social sciences software like nvivo. Unfortunately, she finished her thesis before I finished the app! I later used it to make a few radio documentaries and I was going to try marketing it but it was too much work to get it slick enough. In fact, even I was put off by its lack of slickness and eventually stopped using it.
Yes, I have created many. However, one stands out far above the rest in terms of how much I've used it and how big of an impact it has. That's my cloud-based music player. I have my music collection stored in Wasabi (S3 compatible) and I have client-side python code that I normally run on shuffle-play. As I move across different laptops and whether I'm at home or away, I always have my music handily available for listening. My monthly payment for Wasabi storage is $6 and I'm not tied into any proprietary system.
Text editor, RSS reader, electronic schematic simulator, perfboard designer, optics simulator, browser, git GUI client, music player, expenses tracking app, spreadsheet app (I needed to make simple manual edit in many csv files and waiting for office just took too long, so I made just editor and it launches instantly), numerous one time use chrome extensions, calculator, libv8 based shell, video editor, ad blocker, ...
It usually reaches perfect usability for me very quickly, but to make it usable for others or make it publishable would take months.
I created a no-frills guest list management web app for social get togethers. You rsvp via sms and event hosts can broadcast any updates/reminders as needed. I got a little “dissatisfied” seeing group chats light up with “+1!” when plans were shared. Would be cool to enhance it and make it a business but [excuses here].
I work in accounting & have automated many parts of my job with Python & Javascript.
My Python CLI tool can read data from different sources & do my job. For example, it can read data from excel using Pandas, & then open Chrome, go to a web site, do login, fill forms, submit payments, etc using Pyautogui. In some cases it uses email & cronjobs to start executing automatically.
In another example, it uses Tesseract OCR to convert PDF to text files, & interactively convert them to CSV files that can be imported to any Accounting software.
I made a domain scraping tool that found a nice 3 letter domain, a few graphic editors for game design, html+js+php minifier, file copiers to backup only certain files, and other automation tools.
I'm always excited at the prospect of building new or better tools that help me learn the way I want to learn. It's the best low-stakes way for me to learn - especially if I'm not being challenge by work or am just curious about how a programming language works or other set of tools.
My latest is a language learning application to help practice reading comprehension and vocabulary development. [1]
I needed to hire a Ruby on Rails engineer a few years back, and didn't have much experience with Rails. So took a weekend to scratch an itch and created a web app where I could input a URL to a YouTube video, and the app would then pull the audio from the file and add it to a podcast RSS feed so that I could listen later on my iPhone in Overcast.
It was super useful for a while, and never turned it into anything more. Was handy for just listening to conference talks and other content where the video wasn't very important.
Yeah, I was using it for basically the same purpose as the background player. But wanted on iOS, and then just used as an excuse to play around and get a bit more familiar with Rails. :)
I have a few homegrown tools, the most notable is one I use to record narration for an audiobook-like podcast. I paste my script into the software, then it will go through the script one sentence at a time. I record and re-record it until I am happy with the take, then it moves on to the next sentence. When I'm done, I can download the audio as one merged WAV file.
I occasionally think about sprucing it up to offer for public use, but it's the kind of task that never reaches the top of the to-do list.
I avoid mentioning it by name, I don't want to engage in obnoxious self-promotion. But if you search for my HN username on most podcast platforms it'll be the first result.
Ignoring one-off bash scripts as needed, the standout examples of mine are a simple site for doing a specific type of date math in a bookmarkable fashion [0], as well as a webapp for my D&D 3.5 characters (pre-DNDBeyond days) [1]. As far as I know I am the sole user of both.
I switched from Lightroom to Darktable and with Lightroom it stored the images in folders "year/year-month-day/", so I made a little script that copies the .jpg/.cr2 files from my camera to the right directory based on their metadata. And then in Darktable just re-import this current years directory.
I also created a very hacky script that uses the python paramiko library to ssh to different hosts and spawn a python interpreter which runs a python function remotely for things like grabbing uptimes.
I live in a city in Canada and it gets really cold waiting for the busses during the winter.
For some reason my city doesnt have an app to track buses, so I made my own (with a lot of help). Wrote it in Python, it tracks the real time location of any bus number you enter.
Took a long time, but it works and now I can ping a bus and see how far away it is before leaving the house.
There's usually a handful of busses on a single route, so I sorted them by distance from my current location. It was easily the funnest project I've done
My whole smart home runs on self written software - but only the components that are highly customized, for example the dashboard, the video doorbell (which consists of multiple devices) and presence detection. Everything that can be solved by general purpose software, I don't bother to create my own software for (like your energy consumption report example, grafana does this better then I could ever do). Using mqtt and node-red, it's easy to connect my own software to the 3rd party stuff.
Several, for my work as translator: for example a short autoIt program to create and log translation projects, a short autohotkey program to write different types of smart quotes and n and m dashes in the programs I use to write my translations, a Python program to create and log estimates. Nothing major (all my programs are a few hundred lines of code max.) but they are all programs that I use on a daily basis, in fact they are among the programs I use most frequently.
The one that I use daily is hackerer.news for showing the day's posts not mixed up with popular posts from yesterday. I first made it so I could see all the titles while in the subway and load stories to read when stopped at stations along the commute to the office. Now I work from home but still use it as it saves so much time and visits. I think it gets some regular visits from others but that wasn't my motivation. If you click the date heading it does load yesterday's stories.
> A colleague of mine tracks all of his homes energy use through a custom program which disaggregates the energy consumption per device and outputs a report to a tablet.
This might not be in the "spirt" of this post but your colleague might be interested in looking into Home Assistant. Don't worry, there is plenty of space for custom scripts within HA, but it might be a nice foundation for them to build on as it has energy monitoring stuff built in as well as a way to visualize it all.
One that I use pretty often is `sortedcitations.lua`, which sorts the citations in a LaTeX file according to their appearance in the text. There are lots of fancy tools and bibliography management, BiBTeX, etc, but in the vast majority of cases I just want a single file with the citations in the right order.
I have! I've always found GitHub's default diff to be annoying to track changes. I needed a way to align the left and right editors right next to each other so I could get context. So I wrote an app and published it on the GitHub marketplace: https://github.com/marketplace/difflens. I use it everyday and have other (regular) users too. It's free to try
* A script that emails me every day a list of new articles published by a selection of academic journals. Using an RSS reader for this turned out to be too messy.
* A script that generates Spotify playlists based on my liked songs, optionally according to some criteria. The playlists can be sorted according to specific song features (higher to lower energy, for example).
* A zettelkasten engine, including search, rendering, and backup of entries.
* A system to generate and upload backups of my photos from my cameras’ SD cards.
Thanks! On the fence about whether to use as an excuse to try something small in python for the second time in my life... or just steal the idea and pretty much copy it line by line into something my non-programmer mind will find easier (php). Though maybe it'll be so simple to run and not need future tweaking that it won't even force me into learning by keeping it in python.
Though also, I was hoping for the interesting sources too :P
I pick five tracks at random as a seed to generate the recommendations (https://spotipy.readthedocs.io/en/2.19.0/#spotipy.client.Spo...). If I want I can also filter recommendations according to certain filters (audio features such as danceability, track duration, etc.).
I made a sleep timer for closing tabs. I couldn't find one so I made it. It bothers me that streaming services will keep playing after I fall asleep and wake me up with a blaring action or musical scene. So with this script I can set how tired I am and after I fall sleep, the program will close the current tab and blank the display to keep the light down.
I don't consider it a program nor do I consider myself a programmer. But man, it was so satisfying to have completed it.
- An Android notes app - just the way I wanted - I never implemented sync and it was not really polished but I didn’t feel like using anything else
- An Android app that does the counting and countdown thingie and relaxation time gap between two sets or even repetitions - with voice over of course (I needed when my trainer was no longer available) - I used to set it one and then there was start/pause/finish. I could tweak the presets.
Then I started using iPhone. It was quite sometimes back.
I created a program to use locally for testing emails. It creates intermittent latency and errors on SMTP side and helps you catch code that cannot handle SMTP/network issues (no retry, synchronous code). Now I offer it as a hosted solution and use it myself with every project I develop. If interested project name is Mailsnag and it can be found at https://mailsnag.com/
Clockify polybar integration. Clockify is a time tracker tool. Polybar is a UI bar for window managers like i3 or bspwm. I also have a version that works on wayland and interacts with Waybar but I haven't gotten around to cleaning it up and publishing it.
I click on it when I start working and click when I stop working.
I used lazarus to create an sql editor which can query different databases. It has syntax highlighting, connection coloring, resizable panes, supports multiple result tabs and has filterable/exportable/pivotable result grids. It takes around 30mb of ram, is cross platform and really snappy.
It is missing autocomplete, that is a work in progress.
I just don't want to deal with the burden of answering to issues and tickets, so it remains as my personal toy.
Lots.
- A script and small sqlite DB to download all of a large Youtube channel I wanted to keep. It meant I could just run "get-next-video" whenever I had a spare moment and it would go and grab another one.
- A generator of sheets of math puzzles that looked like the ones my kid was struggling with at school, so he could practice (it worked!).
- Currently working on something to track homebrew fridge fermentation temps.
The first is a background program to monitor my kids time on the PC. As their limit approaches it pops up a window with a timer countdown. When the countdown reaches zero, they're logged off.
The second is for resizing images. I wasn't happy with the way my image editor did it, and I wanted to do a deep dive on some algorithms so I went for it. Gained some great insight while working out all the bugs.
I built a currency trading backtesting and bot monitoring framework [1]. At times I vaguely considered turning it into a product, but for a number of reasons decided not to. However, I am running it successfully, hosted on my own server and am quite proud of what I achieved :)
I have a few different ones, mainly running on a Raspberry Pi 3B (which is likely overkill)
- A monitor for my infant daughter's room temp that communicates with a "smart plug" to thermostatically control a heater
- A second process that creates a dashboard to display temp/humidity
- A webcam for said infant daughter
- An app for logging and displaying health/fitness data
I have pretty garbage short-term memory in addition to (or because of) ADHD. I made a macOS app to let me take screenshots of parts of a screen and keep them around while I work, essentially extending my own short term memory. I call it ScreenHint (it's essentially a reimplementation of a similar app called Snappy that no longer seems to work) and I use it pretty much every day, any time I'm at my computer.
I have created a Node.js program that would scrape comments from a certain blog, look up websites for email address (some commenters had a website attached) and put them into HubSpot. Then I have created a Chrome extension that would extend HubSpot page and show all scraped comments that belong to the profile, in a popup. This was back in my junior years, trying to get leads for my first product attempt. I felt so smart lol
Also, more recently. I created a simple command line program to print a password.
I.e. you enter b003q3gqbba-
and it prints it like:
1: b
2: 0
3: 0
4: 3
5: q
6: 3
7: g
8 q
9: b
10: b
11: a
12: -
What's the reason? The stupid, insecure password masking that some banks use.
I mainly have different cronjob web scrapers that email me results. The latest one is for a local auction site that sells returned items. My scraper does a simple search for items that I’m looking for and then emails me if those items are for sell every day. That way I don’t have to waste time going to the site and looking for it manually, and I’m not tempted by other items that I don’t necessarily need right now.
Lots of small scripts. Probably my biggest thing is a typing program for my son which has videos my son likes as rewards for typing. Just bash scripts and a custom prompt, but it is software someone else uses so I consider it to be worthwhile. It is a form of speech and language therapy.
(I'd release it but the videos are copyrighted - the clips might come under fair use, but I don't know the law well enough to be sure)
Totally! I wrote a HIIT timer app using ionic to track workouts :)
I only released it to the app store so I could get it onto my iPhone/iPad without having to mess around with provisioning profiles every 30 days:
https://apps.apple.com/us/app/biig-hiit/id1598826065
I have written a bunch of applications but the most used application that I have written that I actually use for myself is my bookmarking application. So when I browse the Internet and I find something from the Internet I want to save, I share it with my Telegram bot that will send the link to my application via webhooks. The app will then fetch the website’s contents and save the information to the database.
I use Tutanota as my email provider. They're horrible with spam management, and that's because they encrypt data and can't see what I am sending/receiving.
So I am almost done with a chrome extension that helps me manage those spam emails, it lets me bulk report to Tutanota, add spam rules for the email and domain, and delete.
I'll be open sourcing it and sharing it on HN once done.
Yes, many. The problem I have is that I always feel the urge to "clean them up" and post them as open source with corresponding blog posts and all, which ends up being a time sink (and limits what I do because I have to "pick my battles").
Recently, two of those programs have been web services, which are still public... but I have kept the code to myself and it's pretty liberating in a strange way.
Last week, I wrote an Add-on for GoogleSheets that scrapes a defined list of company job boards for jobs that fit my criteria, adds them to the sheet, and sends me an SMS with Twilio when a new one is added. Runs every hour, and I can be one of the first people to apply for a newly posted job without having to monitor 15 different sites manually. I also use the sheet to track the application status.
Hmm, I have my own Jira client for desktop. I’m sure I’ll get around to publishing it one day, but for now I get to enjoy it myself.
I just cannot deal with enterprise installations of Jira and their forced insanity/slowness. So now I get to define my own fields, categories and icons, query everything locally, and I never have to worry about it again.
Oh, and if I were using atlassian cloud I wouldn’t have lost all my issues :P
I learned C++ specifically to make a tool for creating protein sequence alignments. In my field I often correlate function across proteins from different species. If you know something like, amino acid #136 from protein A is important for its function, you can use alignments to see that amino acid #249 on protein B probably has the same function. I made a tool to quickly make these comparisons.
Last utility I wrote draws a calendar in the terminal, and highlights the current date and also the date of the next full moon. The full moon calculation is not accurate but good enough for me. I run this daily.
For dev-types and general tinker-problemsolver types, that's assumed.
I can't count how many things I've made, most of which I abandoned after I stopped needing them. Sometimes I just make a one line shell script that uses a command line util, and other cases I'll write a bigger "script" (higher level programming language" which often still leverages command line tools.
For sure, I have written tools for photo management (offloading from camera and getting them ranked and ready for a pass with Darktable). I have a financial management system, task management, a system for lecture slides (generating handouts, lectures) and exams (generating keys and blanks and different forms)... I figure half of HN does this! It would be an interesting poll question.
I've written a bunch of stuff that makes it easier for me to connect to cloud resources, pretty much useless for anyone else because it's tailored to my environments.
I've also written a crapload of data processing apps to scrape through or convert various data I've acquired from places.
If I can save 10 minutes of drudgery by spending an hour writing a python or go app, guaranteed I've done it
Sure... my most recent one is an app for the sport of Boxing. It's what I tinker on when I'm tired of coding on business software stuff.
It's getting to be a pretty cool too. It has a "Scorecard" and database for boxers, and I've taken my first (shallow) dive into "Sports Analytics" to predict a winner of an upcoming bout, and it's working pretty good too.
I really made it for myself, but I did set up a website last year (pugilis.com) and there is an older version there that I've made available for free. That version does not have the "MatchUps" feature though.
I'm really not a "marketing" guy but this week I started reaching out to some of the YouTube channels via email that cover boxing to see if any would want to partner with me to promote and sell the version with the analytics.
So far no one has got back to me. I think it's fair to say that boxing fans, as a group, may not be very tech savvy, and maybe even a bit intimidated by the idea of using an "app". And they may think my email is a scam. I put a link to the app in the email and they may be reluctant to click on it. Can't say I blame them if that's the case.
I think my next step is to make a video and put it on YouTube so they can see how it works and confirm it really is an app.
A PWA for splitting bills among friends. When we get a receipt we usually split the cost based on what each of us actually consumed (ex. Bob got 2 beers, Alice 3, etc.). I couldn't find a simple app that could do that, so I wrote my own: https://github.com/emlautarom1/Billy
Sure. A list and inventory manager (actually for my mom). Several programs for generating and managing parts of fictional languages. Tools for creating and managing characters and teams in multiplayer games. A bunch of versions of a couple of programming languages. A wysiwig emacs-like editor. Several artificial life programs. A simple paint program. Probably others I’m forgetting.
I wrote judo[1] because I was frustrated with Ansible. I wanted a very basic tool that could do 80% of the work in 1% of the code. It has one or two bugs, but I've been using it for personal and work stuff since 2016 and I'm not looking back.
A social media client to my and a friend presences: interacting with followers, more with the more important ones, proposing new ones to follow or some to unfollow (and doing that in bulk), and a few other handy shortcuts. It runs serverless crashing maybe once a month for always novel reasons and costs me like 60$ (AWS costs) and a few hours of programming every month.
One of the modules does stuff against their ToS so rather no :) But they updated the API in the meantime so I could get it done properly, then think about putting it in the open...
Yes, a few bigger than small software development utilities. One I use almost every day is jeo.py, a TUI for scoring Jeopardy! I was initially scoring using a Google sheet, but this is easier to use without looking down at the keyboard. https://github.com/bi1yeu/jeopy
When I moved into my current house the VDSL (FTTC) cabinet that serves my road was full, so I could only get DSL.
I wrote a script that checked the OpenReach availability API every few minutes so that when someone ceased their service (because they were moving homes) I would be sent a link to upgrade my service. I think it took about 2 weeks.
I did the same for the second-chance London 2012 tickets.
I have To Do List web app that I built for myself in python/django. It's has a kanban board feel where, as time passes, items move from Future -> Today -> Overdue. If Today or Overdue has too many items, I reschedule them to a future date. So the app acts as a To Do List, Kanban board and a Calendar. It has minimal javascsript so it's fast.
How complex? I wrote a bash script that mounts my encrypted store and opens my work applications. It's not exactly a big program, but it's a procedure that I execute pretty often :D
I had a diary that I'd written in rails and used it for a couple of years. I'd written a fretboard calculator to visualize playing positions on my pedal steel guitar.
Most recently, I built a piece of software to send me digests of RSS feeds at regular intervals, be it daily or weekly. It's an evolution of a little hacky Python script that I had, and I couldn't be happier with it!
I had my own similar script for a while. I stopped using it in favour of Tiny Tiny RSS's functionality, then stopped using that because I didn't like the look of the emails it produced. I'll have to dust off my own script, or maybe take a look at yours!
I hope you like it! Feel free to open an issue of you have problems with it.
It should be fairly easy to change how the emails are generated too, if you're so inclined - just tweak `generateEmail` in `walrss/internal/rss/processor.go`
I have a couple but the first that comes to mind is a tiny little mac app I wrote that "jumps" my mouse between monitors. I use it because I have 2 monitors in vertical orientation, one in horizontal between them, and another smaller monitor above the center monitor. Here is some ascii art of it:
My little app helps to keep my cursor from getting "caught" on the 2 vertical monitors. By default macOS treats the parts of my vertical monitors that go above/below the middle monitor as hard stops/walls so it's annoying if my mouse is too low/high that I have to stop what I'm doing, drag my cursor up/down, then continue moving across the monitors. Likewise, the only way to get to the top monitor is to first go to the center monitor then go up. I hated feeling like my mouse was running into walls constantly so I wrote this app. If my cursor hits any of the old "walls" then my app moves the cursor up/down until it lines up with the bottom/top edge of the center monitor. Also if I'm hitting a wall at the top of the vertical monitors it will jump me over the "gap" to the to top-center monitor.
I looked for (and paid for) a couple of apps out there that claim to do this or something similar but none of them worked for me. I had never really written any Swift code but I was able to cobble together enough code to make it work and in around 200 lines of code I got exactly what I wanted. I wrote this over 2 years ago and I haven't had to touch it since. In fact the first time I rebooted I got confused at why my mouse was getting stuck because I had grown so used to it (added my little "app" to login items and everything has been smooth sailing ever since).
EDIT: Added "!" to the diagram to show all the places my mouse would get "stuck" previously. I left out the ones on the center monitor since they are harder to explain where I'd get stuck going up (the edges since the bottom monitor is higher resolution that the top one).
Absolutely, I just pushed up all the code here https://github.com/joshstrange/mousejump -- I can't make any support promises but it's been working for me really well.
Several over the years, but most were "disposable".
One I made and have used for something like 15 years is a Windows tray app - I click it and the cursor turns to a dropper that let's me select any pixel on screen, then it tells me the RGB, HSL and hex code for the colour of the pixel. I'm colour-blind, so this is frequently useful.
I once wrote a program to scrape the logs from some printers so I could keep track of how much paper and ink was being used. It was just for fun but I showed it to my teammates and we ended up turning it into a leaderboard of who used the least amount of resources. Then they replaced the printers and I didn't feel like redoing it.
A bunch of random things here and there that I needed. The 2 ones that stick out to me:
-A script for downloading and organizing videos from my Youtube Playlists since videos tend to get randomly deleted
-An old Minecraft server plugin which generates custom made structures throughout the world based on .schematic files you provide it and configurable spawning criteria.
Yep. To filter out negativity on Reddit, in YouTube comments, and a couple other places. Needs a lot of work and completely lacks personalization options right now, but haven't had anyone show any interest in it. I don't really market it at all though.
I wrote an expense splitting web app that works with multiple currencies and can export transactions in a format compatible with GNU Cash (that I use) and Excel (that my partner uses). Before that we were using an existing solution (Tricount) but its limitations regarding currencies and export meant that we always made mistakes.
Yes, besides the many scripts I built a visual basic program back in 2000 to make packages of photos and text for my travel blog (before blogging was a thing)
This way I could prepare all the content of my laptop and then upload one zip file in an internet café and have it all published. Internet was still scarce back then. It worked very well.
I have a few, but the ones I get the most use out of is a scraper that checks two very popular campground in CA right at midnight when new reservations open up, and reports back what is available. I have plans to automate the purchasing of the sites if they meet certain criteria, but alas always busy with paid work.
I wrote a Mac utility "app" to display currently playing track notifications using the system notification pop-ups a ways before Spotify or Apple Music had it. People had previously done it with Growl, but I was no longer using that and wanted it to "just work" as part of Mac OS(X).
Calendar appointment system
API Encoder/Decoder
Journaling app
Units of measure converter
Camera downloader and processing
Music player
Automate display/data mining of weather info for 24 cities every 15 minutes
Translator
Loan Calculator
Onscreen menu system for the above
Oh, sure. All the time. Sometimes if you need some solution to a problem you need to invent it yourself.
Back in the day when I had a Windows phone, I used Microsoft’s Zune player to sync it - but I used iTunes for my actual library management. This was a problem because all my playlists and ratings were in iTunes and there was no clear migration path. I’m pretty obsessive about organizing and cataloging my media files so this was something I couldn’t let stand. Unfortunately while iTunes had a decent SDK, Zune had none (at least not a public one).
I basically had to reverse engineer Zune’s APIs to figure out how to synchronize things like playlists and star ratings between the two platforms. It was all a big ugly hack — on the one side using iTunes’ documented but limited COM APIs, and on the other using Zune’s completely undocumented but thankfully also COM-based APIs so I could at least try to infer some functionality behind them via reflection. It was a precarious hack as well. When it worked, it worked well enough, but any time the Zune client software updated, parts of their API would change or break and I’d have to try to figure out how to hack around them again.
All these years later, iTunes still has a COM SDK but it hasn’t been updated since 2004 so it’s stuck only supporting some of the most basic iTunes features for automation.
I can still use it for some CLI tools that I have where I can use keyboard shortcuts to set star ratings on songs without having to manually go in iTunes while using it. That way if I have a playlist going in the background I can just press one of a set of programmable keys to launch this little CLI tool to rate a song on the fly without otherwise interrupting what I’m doing. Sadly the SDK doesn’t support the newer heart ratings, or things like checking/unchecking songs from playlists.
I guess what I’m discovering from writing this post is I seem to spend a lot of time trying to automate all my weird scenarios around media management.
Lately I’ve been working on a project in my spare time to control a BLE-based robotic cat toy. The company that made it stopped supporting it and delisted their applications. This was a very expensive toy that I didn’t want to stop working because of the whims of the company. It was a big challenge - I had to reverse engineer their protocols, reverse engineer their applications, and write something new to replicate the functionality. Just to amp up the difficulty I also decided to build a standalone ESP32-based device that I can use to control the robot without even needing a phone. It’s been a big challenge working with lots of unfamiliar technology but it’s also been a lot of fun learning and experimenting with these new (to me) things.
My most useful ones are honestly just spreadsheets. I made a "family debts" google sheet that we can input expenses into, and split amongst ourselves, and then use to optimally resolve debts between each other. It gets a ton of use, and allows us to just settle up every few months.
Some of the popular restaurants in my town use a booking app called Seven Rooms, which does not have a "notify me" feature like Resy & OpenTable if there are cancellations on a date you're looking for.
Made a bot to check for my desired dates and times and ping me if something opens up.
Oh, certainly. Lots. Most regularly and most personally, I wrote the code editor I used as a daily driver for several years: https://www.github.com/marssaxman/ozette
Yes I created http://lazyday.tv to help me find and track things to watch. Ive been making use of it for several years now and it’s available to the general public for free. No sign ups required. No ads displayed.
I used to maintain a blog/personal site with a collection of Guile scripts.
These days, mostly I write little Emacs Lisp programs to provide nice (meaning Emacs-compatible) interfaces to tasks I have to do at work, like setting up and managing local Docker containers and running SQL queries.
#1 I've created a static site generator that maintains my blog & website
#2 I've created some handy excel macros for my timesheets that saves me tons of time I sent to my clients (like auto skipping weekends, auto-filling hours etc.)
#3 I create indie games that I actually like to play :)
I turned a photo gallery thing into an ecommerce site, tied to Paypal, on a Mac maybe 20 years ago. Lot of PHP mucking-about, with little idea what I was doing. No harm or foul, though, other than I could have picked a different gallery app that already did that.
All the time, and hack other our software to do my own things. I do it a lot on my iPhone, I now work full time on an app that started as a hobby project and got moved forward to be a major focus of the company and I'm still trying out mad things with it.
I created a small program using arduino and IR receiver to control PowerPoint slides using any available remote control.
I had to create a small go program to interface with arduino-cli so that I don’t need Bluetooth or any other hardware, just the serial port
yup, all the time. A simple scripts to make git branches fuzzy searchable, a script to process csv bank statements from my bank and categorize them. todo list, alias management, ELO graphs for Age of Empires II: DE, sublime text plugin to combine csv with textmate snippets, etc. I was submitting a couple just yesterday actually.
Lots and lots. Opensourced everything I could (some were made for employers), under different names. Even maintained them for a few years. Won't name any of them, sorry. But mostly 2D/3D CG-related tools, file conversion utilities. C/++.
I have, just started using it today actually. It's an RSS reader, but one where people can suggest new content to me as well: https://aggregate.stitcher.io/
Lots and I think anybody who is passionate about programming, has enough motivation to get it done. Most of my stuff is to reduce complexities in my daily life and/or automate/simplify monotonous work to be done at regular intervals.
I often write bookmarklets for my own use.
For example a bookmarklet to take me from Amazon/Goodreads to the OpenLibrary.org page for the book. It as easy as grabbing the isbn and then navigating but saves me a decent amount of annoyance.
Also lots. One particularly fun one was a script that scraped fund prices for an old (bad) life insurance policy I had. Dump them to an SQLite db, and then later added plotting graphs which it would telegram to me once a week
Yes I created a program to submit VAT tax returns to the UK tax authority. I had to write it and do a live demo to get the authorization to use the API. It was the first time the interviewer had seen a command line tool.
Several over the years. Most recent one csv reader to work on geojson files. A pomodoro time tracking, I want to make this one a product. Local real estate Data visualizer, stats, charts, also want to make it a product.
I created a kahoot quiz generator. It grabs random questions with 4 answers (one of which is correct) from an open question database and outputs a special kahoot compatible excel sheet ready to be imported into kahoot.
Yep, I created a time tracking tool that syncs with Freshbooks for my contract work. No one else ever used it and I never tried to market it. But it made tracking my hours 100x easier, and I learned go in the process.
I created a phone app once to function as an alarm clock I could set for someone else. Kinda like a hotel "wake up call" except this would call, ring for 10 seconds, hang-up and repeat for like 20 minutes.
Not for me, but I wrote a small program that emails my dad the New York Times crossword every day so that he can print it out. He could just log into the website and print it, but email is so much easier for him.
A real time audio spectrum analyzer for vocal practice. It shows spectrogram and pitch/note of the sound. It also creates challenge notes for practice singing and plays the sound of that note for reference.
The biggest one by far is an entire email user agent. Next is probably a set of tools for my personal website and blog, almost a static site generator. Finally scripts for things like backups, organizing files.
Plenty. Most recent was a volleyball rotation generator so I could hand out customized rotation sheets to every player. When I make a change, I can generate all new sheets by updating names & positions.
A webapp to track my runs, a service which creates backups of my google drive photos to AWS S3, a streaming app to monitor my puppy when we have to leave him at home (with raspberry pi + webcam).
I used to publish all my stuff on GitHub. But my current employer makes me jump through some hoops before I can do that. So I don't publish the stuff that build for myself anymore.
A text editor, data manipulation and display programs, front ends for various things, an interface to play podcasts and search them using podcastindex.org from within Emacs, all sorts.
A few. Working on replacing my Pi Zero W based garage door opener with an esp32 for fun. The Pi had a basic service that accepted HMAC signed Webhooks to open or close the door.
I wrote a quick program in Go to move a certain file from my Downloads folder to my Google Drive folder, when the file is detected. It's to help me backup with Tiddlywiki.
Airbnb won’t open an API for experiences so I created one for myself. Scraping. Once you have four accounts and ten experiences using the UI became impossible to manage.
As a PhD student, I wrote a script that fetched my Uni’s menu each day, parsed the PDF and displayed a Gnome notification of the main course right before lunch time.
The last one was a script that let me carry over my wordle stats when NYT took it over.
I also made an offline copy of wordle to be free of any NYT shenanigans
* track my environment, ranging from actual physical to all host metrics and logs
* write my own music software (effects, instruments)
* write esoteric systems that end up being used for interesting use cases locally
* beer boards, because I like to know what's on tap at home
* database engines, because why not?
it's just a matter of whatever tickles my fancy, from utilities I need, things that differentiate from other sound I hear, to reinventing the wheel to better understand why it's round.
most of what I use is only for me. it's a hobby to tinker. it's mostly workflow tweaks or modules for i3/sway, security relevant things based on netfilter / ebpf ... what all these things have in common is satisfy my curiosity and learn about something new on the way, other times they start out as a tinkering in a new language are a total abomination begging me to be rewritten ...
a 500 line perl script for image tagging and look up script that opens the results in feh. the program can look up images based on set operations.
i would realy like to make the tagging system ai assisted but all of the ML systems i have found are beyond me.
a youtube downloading and playlist system that uses yt-dlp and newsboat rss feeds of my subscriptions.
yes, tons. this was esp more common before the rise of the whole "everybody must have a GitHub portfolio" culture and handheld/spoonfed coding bootcamps & tutorials etc etc
vast majority of my own code has never been seen anywhere. portion only by clients/employers because done for them. very tiny slice in FOSS projects
I wrote a desktop, text-only personal knowledge organizer that I use and rely on every day, primarily for my own use, hoping to make broadly useful someday but...we'll see. AGPL, scala, postgresql; hoping to move to rust/sqlite in future. Would love if others could find benefit from it, but not currently aware of any. http://onemodel.org
i spent many hours as a kid writing programs for my own use on a trs-80 that we owned exactly zero software for. turn it on and start writing code because that's literally all you could do lol
I’d be interested in seeing the program that OP’s colleague has to see energy consumption per device. I want this for electricity, gas, and water. The utilities are starting to get into smart metering, but they’re not up to what I’m looking for yet, at least not my providers.
A command line calculator. While it's on github, is really just made for me because I wanted something to do quick math and convert different units.
A note/todo app. Started it's life as just a text file in a git repo, but now has a web front end, a simple TUI front end, and a little backend so it can add repeating tasks or tasks future days when they come along.
I also have a little python script running to control my exterior Hue lights, turning them on at sunset and such. Just added a thing today that turns on the lights in my office to full brightness when I open Zoom. It's nice, but every time I go down the rabbit hole of home automation, my SO rightly gets annoyed at the silliness of it all.
I wrote a scrabble word generator a few months ago when I was really into playing scrabble online. It's too time consuming to use for a complete game of scrabble, but I use it regularly to help with Wordle:
It is the worst UI for pretty much anything: music, video, podcast, lyrics ...
I selfhost ... i download the spotify exclusive podcasts and host them myself to use the with overcast. They come as OPUS files, but ffmpeg to the rescue.
I pay for premium ... so i want the best experience. Maybe against their api guidelines.
To me this question reads like, "Have you made a personal phone call? I'm curious to know if anyone has called someone else on the phone that they personally know," or "Has anyone else ever spent money on something they wanted?" Clearly whoever wrote it lives on a different planet than I do. A better one, maybe, or maybe worse, but at least very different.
My main user interface is bash, so every time I want to view a PDF file, launch a web browser, list the files in a directory, or compile a program, I write a program to do it in bash and then hit "enter" to execute it. For example:
In this way I estimate I create about 32 new programs a day for only my own personal use. But in many cases I only use each one once. ^R makes it easy to use them again a few times, but in other cases I save them into a shell script to make them easier to distribute to other machines, parameterize, and maintain. The one I most often use is probably a user interface for YouTube via youtube-dl or yt-dlp that consists of a few such shell scripts.
My main editor is Emacs. If I want to do the same thing repeatedly (e.g., delete a line containing the string .LVL) I create a keyboard macro with F3 and F4 (or C-x ( and C-x )) when I do it once, then run it repeatedly with C-x e. I probably write about 4 programs a day in this way.
Emacs has a M-: command to evaluate Lisp expressions, which are programs. Recent programs I have written in this way include (/ 43.2 1.7), (* 9.3 1.2), and (+ 8 3 2.50 3.50 3 7 3.50 3 1.50 4.50 6 5.50 6.50 6 3 2.50 2.50). Probably I write about 1 program a day in this way but I only use each one once. Longer Lisp programs like this can be written in *scratch* and executed with C-j or in .emacs (or .emacs.d/init.el) and executed with C-x C-e. For example, (global-set-key [f5] 'recompile). I use my .emacs file constantly every day but probably only add something to it about once a month. An outdated version is at https://github.com/kragen/kragen-.emacs.d/blob/master/init.e....
Sometimes I write bigger programs for my own personal use too.
A few years ago I wrote https://github.com/kragen/pytebeat for a livecoding performance of bytebeat in a bar. I finished writing it in the train on the way to the bar.
For Dercuano http://canonical.org/~kragen/dercuano I wrote a kind of shitty HTML rendering engine that generates a PDF file, as well as a simple CMS for generating a tree of HTML files from a directory of Markdown.
The other night I wrote a bytecode interpreter with a graphical display in C as a sort of mockup for the operating system of a small computer I recently got the parts for; it's in http://canonical.org/~kragen/sw/erika.git.
I've also written compilers, interpreters, ray tracers, database engines, parser generators, graphics libraries, logic circuit optimizers, 2-D game engines, etc., for my own use.
Some of the recent ones are in http://canonical.org/~kragen/sw/dev3. Over the last 9 years, according to a shell script I just wrote, it has accumulated 170 C programs, 254 Python programs, 60 HTML files (mostly JS with a thin shell of JS), 43 Jupyter notebooks, 28 files in assembly language (though some of these are compiler output), 23 programs in OCaml, 17 programs in Golang, 15 programs in Rust, 14 programs in OpenSCAD, 11 standalone JS files, 9 programs in PostScript, 6 programs in Perl, 9 programs in C++, 7 programs in Scheme, 5 programs in Meta5ix, 5 programs in Java, 5 programs in Lua, 5 programs in Forth, a program in Prolog, and a lot of etc. That's 688 programs in all, according to a program I just wrote in the browser console, which is 69 per year or one every 5.3 days. However, there's probably some double-counting there, or counting of things I started but didn't finish, or things like the copy of D3 I checked in there, and the real number might be more like one every two weeks.
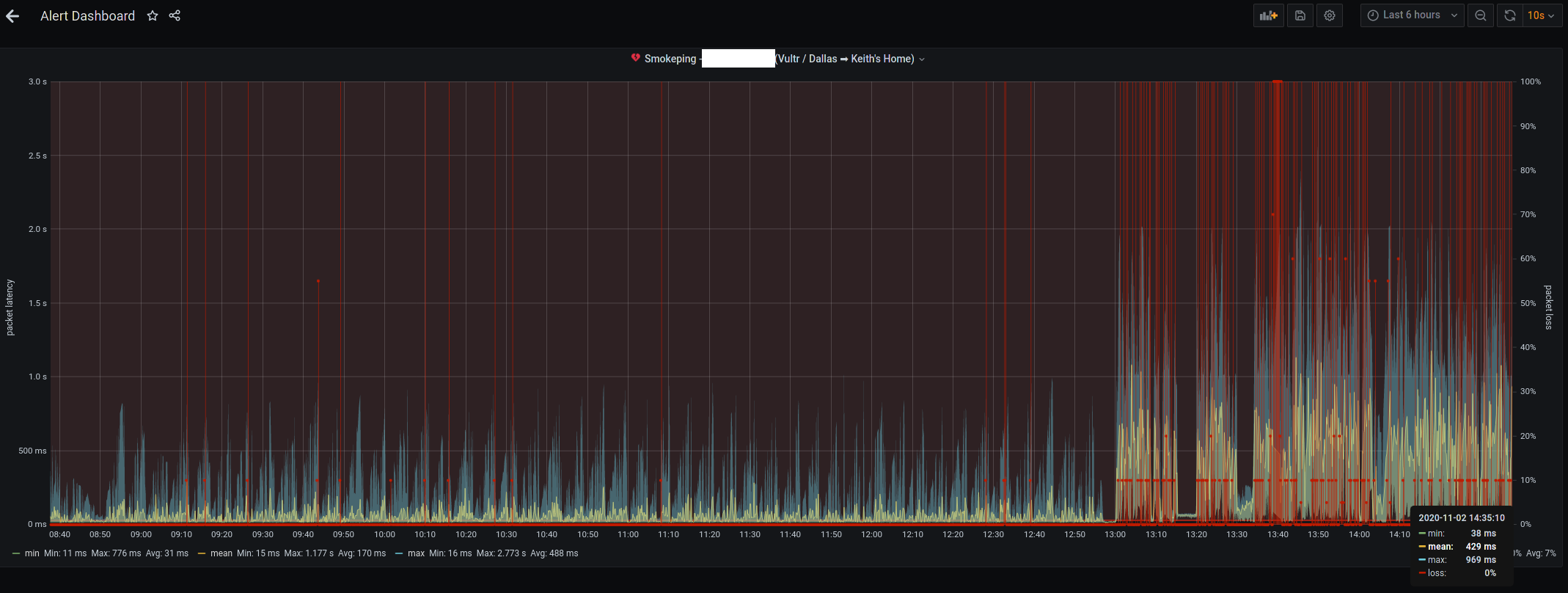{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Off the top of my head, the most used ones are:
* A replacement front-end for "tar" and various compressors
* A script to synchronize my music library to a compressed version for playing in my car
* A secure-but-readable password generator
* A system to batch compress folders full of video files. (For ripped blu-ray discs, mostly.)
* A replacement front-end for "ffmpeg", see above
* A "sanity check" program for my internet connection to see if the problem is me, or Comcast
* A front-end for "rm" that shows a progress bar when deleting thousands of files. (Deletes on ZFS are unusually slow.)
And lots more tiny things.