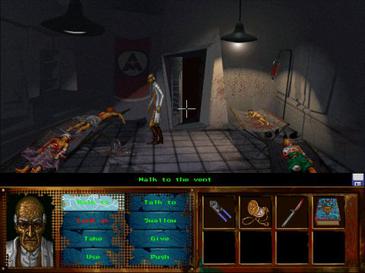
For those who aren't aware: Papers, Please is a video game about paperwork. You play a border agent in a fictional eastern bloc country, checking passports, visas, and work permits. It's surprising and tense and incredibly good. It's currently on sale for $3.99 on Steam, I highly recommend it.
Paperwork, and the inhumanity of being a cog in a machine, with the machine not forcing you to do evil but rather making you very good at self-generating evil out of a desperate desire to survive.
Another game with a similar take on moral choices is This War of Mine. Both are fairly serious works of literature; do not play either with the expectation that you will feel good about yourself or the human condition afterwards.
most games marketed to young adults or teens are a power fantasy - after all, they are what sells well because everyone has power fantasies, and those games fulfill them.
But occasionally, a good game comes out which makes you think about the world, and evoke other kinds of emotions like papers please.
Many good games are not power fantasy. There is huge category of puzzle games, dating simulators, speed based racing games that are power fantasy only if you extend the definition to cover anything. Angry birds, tetris, card solitaires, candy crush, minecraft to name easy most popular examples.
Non power fantasy does not mean only a game that makes point about the world. It may mean also comedic game or Nintendo like feel good whatever.
I'm not trying to alarm you, but I've watched a youtube video of a gamer playing it "unironically". After 30 minutes the guy was enjoying rejecting people and starts getting angry at characters with bad papers, insulting and rejecting them with some kind of sadistic pleasure. Pretty scary.
The Age of Decadence is a great example, if you're on a lookout for such games.
It's a non-linear RPG that lets you play a lone, vulnerable person in a brutal, unforgiving world with a rich setting and highly intricate storyline.
One-on-one fights are hard enough, you-against-many usually ends with your dead body on the ground and a snarky commentary about your yet another fatal mistake.
Could have been more elaborate here. Didnt really want to explore it. Well the story and the choices you must make. The game itself is a fine work of art; but it's more exploitation than a fun adventure game.
I picked up the game because I thought it would be a spiritual successor to the text based game Mind Forever Voyaging. Well it wasnt exactly that.
The game gets dark fast. In fact I don't see it as a game at all, as it isn't fun other than solving puzzles that are at time grizzly.
(Nsfl)
I was pretty shocked at having to operate an organ/eye out of a living and awake prisoner of war in a one of the game's simulations; of a concentration camp.
Another simulation you play as a female that gets violated.
"The game's story is set in a world where an evil computer named AM has destroyed all of humanity except for five people, whom he has been keeping alive and torturing for the past 109 years. Each survivor has a fatal flaw in their character, and in an attempt to crush their spirits, AM has constructed a metaphorical adventure for each that preys upon their weaknesses. To succeed in the game, the player must make choices to prove that humans are better than machines, because they have the ability to redeem themselves. Woven into the fabric of the story are ethical dilemmas dealing with issues such as insanity, rape, paranoia and genocide."
No, but you will find it sad. And I think what's more compelling is you will question the choices you make; is this really what you would do?
I recommend playing it. It can be intense but incredibly powerful; simple choices like "who gets to eat today" really bring it home. Easily the best game of the last few years.
i agree. not only that, there are so many beautiful feelings to be found within the realm of "sadness". and don't let that emotional pain be a barrier to you experiencing meaningful things that'll help you grow.
It's also on iPads (maybe Android tablets as well, don't have one) and is one of the best ports I've ever tried. I might even prefer it on the iPad simply because of being able to multi touch. It is a really great game, I recommend trying it simply for the experience.
Are you referring to the section of the game where you use an x-ray to check for sex that doesn't match the passport? I don't think that's reasonable to classify as extreme, the US government exhibits the same strategies for identification, requiring proof of clinical treatment to get a sex change on license.
If you think the game is about teaching you what you should do, then you played a very different game than me.
There are times when letting people learn why something is bad through experience (even watered down as much as through a video game) is much more effective than just telling them it's bad, for many reasons.
Depiction != Endorsement. Are we going to require all future fictional portrayals of the Salem witch trials to feature token minority characters too because we need to hold people in another reality to the same standard of the ones we are in?
So minorities should only be cast when the subject matter relates specifically to them? I don't think that would leave them with many potential roles. There are so few meaningful roles for minorities as it is. Surely that isn't the right answer.
If you believe that Papers Please is implying that what you do in the game is what you should do in real life then you misinterpreted the creator's intentions to an absurdly extreme degree which I find hard to believe.
Do you believe that MASH teaches you that war is overall positive? Was your takeaway from Requiem for a Dream that injecting heroin is a good idea?
I would call the gameplay mundane, but that's the point. Completing a tedious task with high accuracy and throughput while the complexity and stakes ramp up. I found it to be a very entertaining challenge.
I just played it for the first time after seeing it on HN tonight. It's entertaining in its own way and I'd recommend it, but as I stepped away from my pc it made me feel grateful that I don't work as a customs officer in real life. I suppose that was the intended effect :)
> but as I stepped away from my pc it made me feel grateful that I don't work as a customs officer in real life. I suppose that was the intended effect :)
That and a few others. IIRC, it gets fairly insidious quickly as you try to juggle values at varying levels (protecting your family vs general principle, for example).
One other interesting problem with localization involves the use of printf. Even if you're looking up strings based on IDs in another file (which is a good pattern), sometimes you'll need to move things around based on language. For example, if you're doing right to left languages, you might put the number before, or after the string, and the other way for left to right languages. So like ("%d %s" vs "%s %d").
The way that we got around this was adding another level of indirection, and putting printf format strings also as localized data.
The format strings have to be localized data in any case, because they usually contain literal text, not just placeholders. The real problem here is that you need to change the order of arguments in a printf call - if the string changes from %s%d to %d%s, the order of arguments in the call must change, as well.
If you're on POSIX, you can use positional arguments for that:
Because it's not standard C, VC++ does not support it directly in printf, but it offers _printf_p with such support, and you can always #define printf _printf_p.
> Even if you're looking up strings based on IDs in another file (which is a good pattern) […] putting printf format strings also as localized data.
AFAIK localising "formatting literals" is the more normal method, it avoids redundancies as you don't need two different systems (ids and format strings) and provide more flexibility with respect to e.g. cardinalities. Most ID-based systems bundle formatting support as well, if you're using an ID-based system you basically shouldn't call the language's string formatting functions.
Furthermore translating literal sections individually (without formatting context) will often yield an incorrect result as the entire phrase needs to be shuffled around, or words need to be inflected, or a literal translation suitable for "standalone" expressions does not work for the entire phrase.
More granular is generally worse for translations.
> AFAIK localising "formatting literals" is the more normal method, it avoids redundancies as you don't need two different systems
I never understood why people think this is a good idea. The exact same sequence of letters in an English phrase, which you would like to use instead of IDs, can mean two different things in two different places - and those two different meaning could have different forms in other languages. Denormalizing translation database like that seems semantically incorrect (and strikes me as programmer laziness).
I agree that in general, more granular is worse for translations - there's too much risk your split will pierce the contextual whole that's required for some translations.
I'd expect this to happen when there is a split in the original case as well. E.g. you need to translate the template and the names. They are split in the original already, so they are translated as a split.
The same contextual issue then arises in the original, but apparently the designers thought the trade-of was worth it.
> I never understood why people think this is a good idea.
It makes for a more readable, comprehensible source and searchable source. It's also often possible to dispatch on location additionally to text (PO files store both).
The Unicode CLDR has a whole database of formatted strings for each locale, for more or less the reason you describe. Formatting dates or big numbers (12345 -> 12.3k) is impossible to achieve without a generic formatting language.
Pluralization is another nightmare of its own. Look into how Russian and similar languages pluralize. It has to do with the value of the number modulo 10, similar to English ordinals.
I went to a presentation by a company that dealt with translation, he mentioned this issue and his recommendation was to simply not try to be smart with it and have separate strings where pluralisation is done properly in each one.
That works when there are a small number of possible numerical values. But cldr has a table of plural rules for each of these languages and it's not bad to solve the problem for arbitrary integers.
What about gettext _N? I have used a library with a similar interface, and we didn't even get complaints for Slavic languages with very complex pluralisation rules.
Don't ever use the original string as key in the localization table. That will force you to translate "high" difficulty the same as "high" resolution, for example.
When translating a fixed set of messages, you translate the entire phrase, not individual words. So the keys would be "high difficulty" and "high resolution".
What GP is saying (I think - because your point is so obvious to anyone who has done a few hours of i10n that I didn't think it reasonable interpretation) is that you shouldn't use those phrases as the key in your message table. So don't use 'high_difficulty' as the key to look things up. It makes development easier, because you see the sort-of correct strings in your code or level editor, and usually the keys are in the language of the development team, so it lets you forget about the issue most of the time (as opposed to having to look up the value when you use keys that are not connected to their string value).
I got this wrong several times (of course) when I did my first few i10n projects. First time I used the strings as keys and ran into the problem described above. Time after that, I went the 'pure' way and used GUID's as a key which was a pain in the ass to used and caused the wrong messages to show up in some places a few times. It also made the translators hate me a lot. After that I went what I'd describe the 'pragmatic' way. Every time you encounter a string message, you make up a string identifier that sort of describes the message. So 'High importance!' would be e.g. HIGH_IMPORTANCE. But a multi-sentence message might be 'INTRODUCTION_PARA'. If the id already exists, and there is no obvious alternative, you just call it HIGH_IMPORTANCE_2 - in other words, you don't think about the key too much, you just use quick and dirty keys, you don't change them EVER, and you make sure you have good tools to prevent clashes, even across 'module' boundaries (where 'module' can be 'source files', 'shared libraries' or 'projects that use the same string resources').
You also put formatting strings in the messages, and in a way that makes the order configurable by the translator (e.g. using boost::format and not sprintf). You also provide the translator with a UI that shows them the message key, the 'original' message and the translation in various languages that already exists. And you provide a way for the developer/designer to attach notes to each message, where necessary.
Finally you adapt your messages to be as 'neutral' or easy to translate as possible; how to do this is something you learn with experience. And have to test test test and write special cases where necessary, like where you absolutely need things like 'first' or things where you have weird capitalization rules and stuff like that.
I never liked gettext. First, the is the licence, which rules it out for many projects. Secondly many of the functionalities are overkill, and (while 'pure' from an engineering pov) cause more work than they save (the cases I described above as 'just implement something custom in code'). Third, the tools suck. None of the editors I ever tried were really comfortable to use. They must have gotten the last 10 years or so, which was the last time I looked, but usually they're 'open source user experience' quality' - which is fine for developer tools, but not to be used by non-tech users (which most people who end up doing the translations are, because let's face it, translation is usually an afterthought and a low-respect task).
Minor correction: you mean i18n, not i10n. There's i18n, and l10n, meaning internationalization and localization. Internationalization is about the code abstraction that enables for strings to be swapped out for languages. l10n is actually using the the i18n code to implement a specific language, e.g. French.
iOS still has this problem in French on its keyboard, where "return" (for line return) is translated as "retour"... which literally means "return" but in the context of a keyboard, means backspace (on physical keyboards the backspace key sometimes even has "retour" written on it).
I've seen the same thing with Polish, on Linux. I don't remember which desktop environment it was in. Instead of "wolumin" or such, there was "głośńość".
I understand why he did it, having just done l10n myself for a client, our application is now harder to work with, and harder to just even find things, for example if you search for a phrase you can see on the screen, you get taken to the string file, instead of the string location. It's just an extra step, but it's a little mental drain that you wish you didn't have to deal with. You can't even scan the html anymore very easily as it's filled with all these hard-to-quickly-parse ids instead of human readable text.
Another big problem with using existing strings for ids is that if you notice a typo or tweak the phrasing of a particular string, boom, there goes your placeholder.
Or you can do it the way front-end does and create a 'localizeText(id, default_translation)' function which you will use to print texts. Best of the two worlds.
another reason is different grammar even if it's same in English, while old will be same in English no matter if you write old woman, old man or old child in languages with gender distinction it will be different, same goes for singular vs plural
so while in English you need only one string for singular and plural for different genders, in other languages it need to be written 5 different ways and we still didn't get into grammar cases which also don't exist in English, so while in English you would use 20 times old in other language you need 20 different variations
many companies where it's the default language of products English or Chinese have later big issues to localize content properly, especially considering Chinese being even more primitive language than English. good luck trying to explain all these distinctions to Chinese developers
The keys are for a specific context, so that makes collisions unlikely. You'll notice the example context "turned-over-ezic-docs" has only three strings in it. Of course, if he ever did have a key collision, it would be easy to solve. At worst, he'd have to replace the English strings with random, unique strings and make English a translation just like any other. He decided he'd pay that toll only if he needed to. And he didn't need to.
Awesome article. I'm always impressed by the distance people will go for their passion. Lucas talks about ultimately having to hand draw Cyrillic versions of _each_ of the game's ten fonts. Very cool!
how do you know it's passion when he provided more languages option only after his PAID game became successful? i think there is different word for it in English
Localizing well has a lot of complexity - gender, cardinal, ordinal, etc. rules, and then how to combine them with locale-specific special cases (e.g. in Spanish, a 15-year-old birthday girl is a quinceañera)
I am attempting to solve this with a small library that offers full CLDR coverage and a special expression language.
Haxe really shines at converting compile-time assets into static types. The other related trick is to use json as a config object, and access the fully typed equivalent as a static instance within your code. It's also possible to do this with database queries.
I realize other languages provide support for this, but in my experience with Haxe it's way easier to implement something custom. The macro translation layer for manipulating the AST is flexible and speedy, and the compiler is wired directly into autocompletion requests. There's very little impedance between my fingertips and the desired outcome.
Loosely related to the title: Why not create a complete modular version not only localised, but also tied to individual country's flows and processes? So it could serve as an education material. (mind:blown)
Having just done some l10n for a client, the thing that annoys me is how even the most powerful editors, such as VS, have such awful tools for l10n. .Net's actual i18n support is pretty good overall, but the editor support is bad.
I literally had to build my own. With 2,500 different strings for a total of 10,000 words I wouldn't even consider our application even that big, it must be a nightmare in bigger projects. We haven't even done the sales site yet because the product's being upsold through a partner.
We came up with our own id naming system, then created an xlsx/resx importer/exporter that uploaded to GSheets to allow us to share files with translators. The ids and comments fields allowed us to add extra meta data, to split the strings into logical sections and sheets and order them properly. Be able to add links to the page that section of translations are on so the translator could see the context. This then additionally allowed us to highlight if a translator had missed any lines when we re-imported it, add their own questions/comments, etc. Also, as we were using sendwithus, we used the importer/exporter to allow us to import pot files from them to keep everything in one place.
Then to support those tools, I created a tool to search for phrases used before, find out the ordering from the meta data, quickly copy ids of strings we want to re-use, see missing spreadsheet tabs.
Programmatically, we had to add support for automatically translating enums into strings (think project status for example), add l10n to our audit logs so customers could see their audits in the correct language and we'd see them in English, modify how .Net did l10n of dates because their built in one is really odd with en-GB which is where we are based (shortdate is Jan 01 2025 in en-US but inexplicably 01 January 2025 in en-GB and all sorts of other oddities).
Then we used a modified version of pseudoizer (thanks John Robbins + Scott Hanselman![1]) to allow us to easily see untranslated strings while we went through the whole site without having a finished translation (we used ja-JP instead of Polish to really see the differences in date strings, currency, etc.). We ended up modifying it because it goes a bit mental with adding !!!! for things like tabs.
Probably spent a week on those tools, but boy was it worth it.
I've not tried intellij's l10n support, maybe it's better, but VS's is very lacklustre.
I would recommend against one's own XML format and doubly against CSV/some homegrown delimited format. Instead, consider something like Excel 2003 XML (one of the easier ones), OpenDocument (also pretty easy in many languages), or Office OpenXML (easy in .NET, a bit harder elsewhere) to store your translation data.
Potfiles are another option, but the tooling is pretty clunky and, in games in particular, people don't seem particularly attuned to their use. And they're not great for editing, though they might be for storage--when dealing with tabular stuff, it just makes a lot of sense to use tools that present a tabular interface. It makes life a lot easier.
Blah, how did I forget XLIFF? Unlike a lot of OASIS specs I think it seems pretty reasonable and alright, but I've never actually seen it implemented anywhere (games or general startup-y web stuff). I'm glad you brought it up, though, because it did slip my mind. =)
Until starting my own company earlier this year, I worked in the translation industry.
We had some XLIFF-friendly clients who, on the whole, had been used to translating and localising their data for a long time and were productive and well-organised.
The remainder of our clients weren't; a mixture of spreadsheets, CSVs, home-baked XML/JSON/YAML were most common. We could accommodate these providing the format was documented and we had technically competent translators for that language with the correct industry-specific knowledge.
Finally, some clients insisted on sending us PDFs, marketing materials (hopefully in PSD files but sometimes in PNG or TIFF). They couldn't understand why we had to go to great lengths to find translators who could cope and why sometimes the results weren't pixel-perfect. Of course, supplying the source materials to us to pass on to translators was out of the question.
If it's literally a table of strings, why on earth would anyone use ODF/OOXML? CSV is perfectly fine for editing in any functioning spreadsheet software, works reasonably well in version control (especially since a given commit won't touch multiple columns). In his case, he's using the XML format which Haxe will parse into compile-time-checked references right in his source code; sounds like a great reason to use this standardized(but Haxe-specific) XML format.
yeah I don't see any reason not to use that XML format. CSV can be problematic because it doesn't declare it's own encoding and doesn't play as nice with translation tools as something with named fields, such as XML or JSON.
CSV has no formatting. Who wants to resize columns and set up text wrapping every time you open the file. Could save it as .xlsx and then export to CSV, but that's another step and it's not hard to parse simple spreadsheets in XML. Worth it in my book, because it enables fan translators to contribute easily since everyone has Excel.
It's not about you, though. Or me. It's about what the people working with you are most comfortable with. I can go blurf out JSON or XML or potfiles by hand, whatever. But normal people are going to go "er, no?" and even if you win that argument you've lost social capital on something that didn't really matter.
I really don't like how you're putting words in his mouth. He said nothing to suggest that he felt Excel was inadequate for editing CSVs. That's your opinion. And, it's not exactly streamlined, but it's good enough that Microsoft will suggest using it for that purpose. https://support.office.com/en-us/article/Create-or-edit-csv-...
Can you explain why you oppose CSV? And by the way CSV is a standardized format with its own RFC; it is definitely not home grown. There are mature parsers being able to handle commas and quotes and linebreaks and other special characters in CSVs.
It boils down to this: Excel is the de facto standard for translators and localizers I've worked with, and so tooling that works with that is a smarter bet than well-actuallying them about how trash that standard tool is at my favorite niche case. It's about people, not your code.
Beyond that, hand-editing a CSV file (because eventually you have to do that) with those special characters in it is a huge pain. It remains better than JSON, etc., because being record-based is automatically better than not for this stuff, but it's not a good option. I'm well aware that CSV is theoretically standardized; I have written standard-compliant parsers and writers. (It is awful.) And then, once I had painstakingly written that writer to spec, the next guy's--no, not Excel--trashed my data because CSV has a spec that nobody cares about.
That's adorable! CSV is notoriously loose, has a bajillion edge cases, differs wildly on region, and is not even really a format at all. Basically nobody follows RFC 4180, nor does anyone care about its existence.
The other day I had to fix a bug in our CSV importer; it turns out that when you install Excel, it changes the mimetype of CSV files from 'text/csv' to 'application/vnd-ms.excel' system wide. Wow! These sorts of shenanigans are never ending in the futile endeavour to support CSV.
It seems that you're letting the behavior of a particular application and OS negatively affect your opinion of a technology which works really well on different platforms.
Your translator/localizer, if you have one, probably uses Excel already. I personally prefer to have fewer moving parts in my stack, so I don't really think it makes much sense to make their life harder just to have something else.
If you're not relying on your translators to produce production assets, then you will be converting them from a format they are comfortable with (which tends towards Excel, if not a web app of some flavor) into whatever you're using. Unless you have a particularly rough memory budget, you will almost certainly be saving yourself time and effort by cutting out a step.
If you use a web app of some flavor (AirTable, Google Sheets), conversion shouldn't be a problem though, should it? Or are there good reasons to avoid these options that I'm not thinking of?
It's another step you have to automate in your build pipeline, have to tag and manage outside of source control (making your builds now "code at rev X + assets of difficult-to-isolate revision Y", which makes repeatability a little harder), and so on and so forth.
You can do it, and it has its advantages. But you're also buying complexity.
The second part ("less technical stuff") specifically notes that they used Steam's private branches to beta-test the localisation and that the supported languages are Italian, Japanese, Spanish, French, German, Russian and Brazilian Portuguese.
Sometimes you just have to bite the bullet. For interesting subjects, which always have global reach, the virtual conversations are conducted in English. There is also a place for vernacular -- it is part of people's cultural identity -- but not in a formal knowledge setting. English is a bit like Latin used to be: the language of knowledge, technology, and business. If the subject has global reach, you will miss out on the interesting bits of knowledge, simply because you are trying to do it in vernacular. Doing anything in vernacular, will just lock you up in a small and uninteresting national silo. Nothing of any interest is national. But yes, I use vernacular. I also speak it with my kids, but I don't read it -- unless it is poetry or literature -- and I don't use it in software or in business.
There are dozens of highly-functioning economies in the world that barely use English at all. I just got back from a holiday in France, which has its own fighter jets, nuclear weapons and aircraft carriers, yet only speaks English in jobs that are directly related to foreign communications. A random person you meet on the street will be very unlikely to understand you if you speak English to them.
It's a pipe dream to expect an average French person to enjoy art in its native language, and as a businessperson you will limit you market by doing this.
Granted, the English-speaking world is currently the world leader in technological capability and economic power, but it's quite myopic to assume that this makes everyone else irrelevant.
When most people play games, the goal is to relax. While I will concede that English has largely become the de facto language of trade, business, and technology, and I'm not going to go into hand-wringing because of that fact, demanding that people partake of their leisure in a language that's uncomfortable to them is several steps too far.
You are being downvoted because you are ignorant of massive population of people who consume work of art or other, but who aren't multilangual.
> it is ok to translate games for kids
Big thing that lets my father (factory worker who's 50 years old, no languages other than his father's one) enjoy Playstation 4 is the fact that Sony does insane amount of work to make as much as possible translated to Polish language. The Last of Us as well as Uncharteds which in no way are games aimed for kids received full polonization. WipEout Omega Collection has been polonized as well. Same goes for 3rd parties - Bethesda's games are fully polonized (this includes Fallout's, DOOM and Skyrim), CoD's are polonized, EA's games are polonized (Mass Effect's, NFS), etc. ect.
There are many adult consumers who are more comfortable with media in their native language for one reason or another.
Blizzard even went as far as to declare that every game they'll release will be localized on level that would make it par on native production. They are going so far with it that they are replacing US-specific jokes with local ones.
Well, in their own interest, it may be better to bite the bullet, and learn English.
I ran into my own first book on programming at the end of the eighties, when I was fourteen. It was an old photocopy of Borland Turbo Pascal, in English. There was no translation available in vernacular. So, either I gave up on programming, or else I just had to get used to reading these things in English. Later on, programming became my full-time profession. If I hadn't done the effort of doing what it takes, and figure out English, today I would probably be queuing for unemployment benefits or another social handout. My kids would now be begging in the streets, instead of happily enjoying their costly private tutor and cosy private school. The kids obviously understand vernacular, but the classes are firmly in English, if only, because the other parents also know what time it is. The false beliefs and pagan gods of vernacularity make it so that the rich are getting richer, while from the poor, even the little they have, will be taken away from them.
I don't get why you're putting English on such a high pedestal. It's just another language, and a very annoying one for those taking it up as a second language due to its lack of internal consistency. If you care so much about learning some world language, I suggest you learn and start teaching your kids Chinese since that's the country on pace to surpass the US in economy. [0]
People playing these games aren't doing it to gain a marketable fluency to allow them to get a great job and prevent their family from begging (as your alternate future would supposedly have entailed). They're doing it to wind down after the end of a day, to experience something entertaining. Being forced to do it in another language is not anyone's definition of fun (instead it's alienating) and that's why despite the original game existing in English, the author mentions fan translations popping up. Btw, knowing just English will also lock you into a silo—that of the anglosphere and despite your veneration for it, it's not the end all be all of culture, nor do its tendrils reach everywhere. (for example, there's a wealth of Japanese literature that hasn't even been touched by American translators; same for so many interesting cultures in other countries) localization is a gift of culture to those who speak other languages—it's the same thing that allows Americans to enjoy French poetry, German philosophy, Korean comics, etc... Don't be so hasty to put down the whole world just to feel good about your own choices and shame those who aren't so capable or willing to jump on the Anglotrain.
I can only emphasize that vernacular indeed has its place, if only to build local identity and belongingness. So, I am not advocating to abolish it. As I said, I speak vernacular with my own children, and they speak it with the kids of the neighbours.
However, if you do a serious subject, which is always global, but you do it in vernacular, you are missing out on the virtual global conversations that really matter. It will inevitably force your own contributions to the field to become sub-standard.
France recently decreed that they will prosecute people who post "terrorist" opinions on the internet in French. Of course, France will surely expand their action radius and seek to police any kind of subject, in order to control the "narrative", and make sure that it is favourable to what the powers that be, want you to believe; in line with what they have been doing for ages with newspapers and television.
The UK also want to do that but they face the enormous obstacle of English-language opinions posted from the USA, which are protected by substantial first-amendment free speech provisions. According to Brandenburg versus Ohio, even advocating the violent overthrow of the state, is firmly protected speech. Don't ever say a thing like that in vernacular, because the local-language government may seek to arrest you. Hence, you can expect a much freer discussion in English than in French, since it is unencumbered by national-state regulations that curtail possibly unpopular or anti-government speech. I can pretty much say whatever I want in English. Don't try that in Polish, German, French, Chinese or any other local vernacular.
> The UK also want to do that but they face the enormous obstacle of English-language opinions posted from the USA, which are protected by substantial first-amendment free speech provisions.
That's no obstacle. US laws don't apply to the UK, and the UK already has some heavy-handed internet restrictions that couldn't fly in the US. For example, in the UK, there is a list of child pornography sites that all ISPs are required to block. The internet does make jurisdiction a thorny question, but there are sometimes ways around that (note the old rules on British libel law, which pretty much held that you only had to justify some harm in England/Wales to sue for libel there--e.g., Donald Trump could have sued the New York Times for libel in the UK instead of the US. The UK did tighten up the residency requirements after the US passed a law basically saying "we're not going to cooperate in enforcement of UK libel law").
It's not a matter of English versus non-English. It's a matter of the ability of governments to enforce local legislation.
If you're in the US the US government can't inhibit your freedom of speech - and this includes the speech you make in French.
And if you're in the US and you deny the holocaust it doesn't matter what language you use to do so, when you travel to a country where it's illegal to deny the holocaust you're going to find it tricky. (For varying degrees of tricky including "nothing at all happens; noone knows or cares".)
I respectfully disagree that vernacular makes contributions somehow substandard. It's still language and still affords a full range of expressibility. You're only saying that because in your mind you connote English with "professional" and whatever other niceties while vernacular is vulgar, uneducated, etc... But vernaculars have rich histories in many countries and by virtue of being used by the populace, have deep utility. Yes, they're not international, but English has only gained the status of lingua franca by virtue of its expanse; it could very well have been Chinese. They're nothing inherent to English that makes it superior and if we're solely basing our justifications on business use, like I said Chinese would be a better choice if you're looking towards the future. By the way, I highly recommend trying to learn about other languages, some of them have really beautiful systems, both verbal and written and some language features are really nice like phonetic alphabets.
Regarding France, I think you're conflating language with law. The only thing allowing France to police but the UK not to is the law, not the language itself. You think these countries aren't already capable of getting translators to look at comments reported to them? The language isn't protecting anyone, it's being in another country that has freer speech laws. Better advice would be to move to the US. (but in actuality isn't better advice because our government isn't really any better what with all the surveillance going on and our own terrorism hysteria)
There's a concept in linguistics called the Sapir–Whorf hypothesis [0] that I think you subscribe to—that language determines thought. It's failed to gain consensus by linguists but still isn't a closed matter. I think if we consider how people all over the world use language, we can find that they're just the same as us. The only thing preventing us from understanding them is our own implicit biases, our prejudices, our looking down on them. This sort of evangelizing of English isn't really that far off from the spread of Christianity through imperialism, though America's own "Manifest Destiny". We should think twice before imposing our will on others because we think it's by default better. At the end of the day unless you're working in an international market or planning to live elsewhere, you don't really need to know English specifically. I think everyone should learn another language, but instead focus on what languages interest you and which one you actually need, not just whichever is the top dog or has a sense of superiority attached to it. (similar to how white skin is now considered beautiful in a lot of countries, to the point where people are getting their skin bleached)
I am a native English speaker. What you say would benefit me. Having everyone else do everything in English would be great, for me. So I neither downvoted you nor contested what you were saying because I "didn't want to hear it"; I did because your post was exclusionary and wrong.
Let people enjoy things. It is ok to enjoy things, really. Also, many people who speak well English in work, still prefer translated books and games and what not.
You got downvoted not because of truth, but because you are all sanctimonious about foreign languages while we speak about game.
I see. I just looked at the HTML excerpts, so, I thought it was about something generic. I am ok with translated games. I am not ok with translated math, though. It's like the localization of the glibc library. It inflates the size of the binary, while nobody that I know, would want to see vernacular in the commandline terminal. I would think of it as a bug. Time to move to musl or dietlibc!
Sometimes I get i18n fatigue too. I think the world would be a better place if everyone's languages fit in ASCII.
That said, the cat's kinda out of the bag. UTF-8 is at least well-done, and the algorithms are widely available. I study Japanese and have started studying Russian and Chinese; I think maybe the best way to convince people to learn English is to walk the walk. Who knows, maybe everything will go very wrong again before we get a chance to standardize.
I'm also working on an engineered language with a test suite/corpus maintained alongside the language. Maybe in the ashes of the old new world there'll be room for something like this.
To write it properly, we need left- and right-facing single and double quotes, diareses and accents for words like naïve, façade and café, en- and em-dashes and the ellipsis.
Longer documents will require symbols like † and ‡, bullets and §. The currency symbols £, €, ¢ and ₹ are used by countries where English is an official language.
I can't even use symbols like that anyhow (I deal in USD, CAD, and NTD). I end up using ISO 4217 codes everywhere. You missed ¥ as well, for which I would use JPY or CNY.
Somedays, I dream of a world where the ancient chinese were exposed to alphabaeic scripts and decided that was a good idea, instead of sticking with characters.
Though honestly, I kinda like ideographic languages. If the symbols could be enumerated in a byte and leave space for delimiters and punctuation, then I'd be down to be globally colonized by an ideographic language. Really the only difficult ones (for computers) are abugidas, abjads, and whatever thai is written in (and I suppose it is a bit of a pain to compose hangul, and still more jamo than would fit in an ASCII-sized encoding).
Thai is an abuguida, descended from Brahmi just like most of the rest of the South and South-East Asian scripts. It's probably the one with the most additional stuff to consider, but fundamentally it's the same kind of script.
{kind=link}