The scariest thing to me about AWS is that I might accidentally bankrupt myself while I learn to use it. I've seen horror stories on HN before. Articles titled "How I spent $32k with AWS, a for loop, and a simple typo" or something like that.
Normally when I learn something new, I learn by tinkering and breaking stuff. I don't feel comfortable doing that with AWS. I'm hoping people will tell me I'm way off base because this fear has stopped me from getting the ball rolling.
I run a million-dollar business on it for $4500/m, give or take. It's not Webfaction (who I love and highly recommend) or Linode. It's virtualized data-center territory that can support some massive stacks.
They give you enough rope to hang yourself. I'm ok with that, because it works brilliantly when you have the time to put in to it. (They also almost always help out or completely forgive someone that accidentally ran up a massive bill in a short period of time.)
Without AWS, my company wouldn't exist - I could never have initially afforded dedicated hosting or collocation. AWS changed the game. You can argue they're not the cheapest or even the best anymore, but it works this way because of Amazon.
You could have afforded VPS hosting in the beginning (starts from $20 per month for decent specs), and immediately switched to dedicated hosting once you outgrew the VPS (from $100 per month). AWS was never the cheapest for any given level of performance; you've always paid a huge premium for rarely needed flexibility.
I would argue the "rarely needed flexibility" - our traffic is very spiky, and we scale from 3 to 11 or even 13 front-end instances between our lowest and peak usage. If I had to maintain all that hardware capacity for 10% of the day, it would be more costly.
Then there are the ancillary benefits - I can lose a server and another is in its place, attached properly to the stack within 60 seconds. I can take advantage of compute power when I need. I don't have to run nginx or haproxy for load balancing (and I don't have to manage the load balancer servers) and spinning up an identical stack in Europe or Asia is a single command line statement away.
Also I'm not a server admin by trade.
So I realize there are scenarios where bare metal could be cheaper, but the opportunity and admin costs need to be factored as well.
Traffic that spiky is extremely unusual. But you don't need to maintain all that hardware capacity for 10% of the day.
There are a number of colo providers that also provide managed hosting and cloud services (even if you for some reason couldn't deal with the latency of simply tieing EC2 instances into a colocated or managed hosting stack via a tunnel).
In fact, combine, and you can cut the hosting costs even more than with colo services alone, since you don't need to plan for a low duty cycle for the hardware - you can run things on 90%+ load (or wherever your sweet spot turns out to be) under normal circumstances and fire up cloud instances for the spikes.
That method handles the loss of servers etc. as well just fine, again further cutting the cost of a colo/managed hosting setup because you can plan for less redundancy.
Personally I've yet to work on any setup where the admin costs of an AWS setup has been nearly enough lower than colo or managed hosting to eat much into the premium you're paying. You have 90% of the sys-admin hassles anyway, and you're left with far less possibility of tuning your setup to what works best with your setup.
Most of the setups I've worked on come out somewhere between 1/3 to 1/2 of the cost of running the same setup purely on AWS. Sometimes the gap is smaller if you have really spiky traffic or have lots of background processing or one off jobs where you can e.g. use spot instances extensively.
I do understand people wanting to pay to not have to think about these things, though. But you're almost certainly paying a steep premium for it, even with your traffic spikes.
The idea of straddling two separate data centers seems far more complex, cost-wise, and time-wise, than simply going with AWS and using their flavor of elasticity. Given that his hosting costs are half a percent of his yearly revenue, "premium" really seems like the wrong word here.
It may seem more complex, but it really isn't, and it typically ends up so much cheaper than EC2 it's not even funny.
And you don't need to straddle data centres as most data centre operators these days have their own cloud offerings - often cheaper than EC2.
I don't know his margins, so maybe it isn't worth it for him specifically, but I know plenty of businesses with small enough margins that the opportunity to halve a half-a-percent-of-revenue cost like that could easily add 10% to profits.
I wasn't referring specifically to the physical aspect with something like colocation, although that's another potential facet of complexity. The complexity I was referring to is literally having two distinct environments interoperate seamlessly.
You now have one environment trying to talk to a database in another location, for example. So, some requests are artificially slower than others. You could mitigate that with caching, and probably already do, but now your cache is fragmented across two, or more, environments. On and on and on and on.
Configuration, security, duplication of resources that can't be easily shared. These aren't unsolvable problems, but they're relatively more complex than sticking everything in a single environment.
And yeah, the money aspect could easily be worked in either of our favor. It really depends on the specific situation.
If you want to play with VPS servers, use DO. If you want to virtualize a data-center or series of globally-connected data centers with racks of servers, use AWS.
So maybe AWS isn't the right solution for you. You say in another comment that warnings about billing overages aren't enough. AWS can't hold your hand and provide Netflix-capable services at the same time.
Amazon chose the latter. I would recommend you not choose AWS until you have the time to dedicate to it.
How is being able to set up a $ limit "holding my hand"? You guys are defending something that is indefensible.
I don't want to "play" with VPS servers, I want to work knowing that I won't go bankrupt just because I'm using at the same time a service that won't let me set up a limit, and a pull payment system (ie. credit cards, as opposed to push systems like Bitcoin).
I imagine that they decided not to have $ limit as implementing that would be once you hit the $ limit, they will take your whole stack down completely. This includes anything you've had setup on AWS, which could be hundreds of instances of any of their services... which may or may not be feasible to do instantaneously or safely (without you losing data or breaking something.) Imagine pulling systems down in the wrong order or while writes or reads are being done... you now have no guarantee that your data will be in a good state.
It's always best to leave termination of your client's systems up to the client than to pull the plug out from under them... at least I'd like to think that's how they would have reasoned it internally.
You can have a $ limit. Use a CloudWatch alarm that shuts down your instances if the billing metric exceeds the growth rate you specify for the period you specify.
Like it or not this is a problem many of us have, and are avoiding AWS for that sole reason. You can keep blaming the victim, or you can accept not being able to set up a limit is a usability problem.
It's like saying "this website is stupid, it's storing passwords in plaintext", and you answering "hurr, it's the user's responsibility to create and manage cryptographically secure passwords".
You're not a victim! Youre inability to control your costs, given the tools, alarms and general common sense doesn't entitle you to some magic off button! Learn to use the tools appropriately and you won't incur unexpected costs.
And as an analogy, Aws is more like C; if you are willing to put the time in to learn, you can do some amazing things that are impossible with other providers. But you must take responsibility for them.
How is a simple configurable limite a "magic button"? What extreme technical difficulties do you see in implementing it, that warranted you calling it "magic"?
Because it would tear down the entire stack? If you're a real business, depending on servers to be up and data to stick around, then it makes absolutely no sense to have machines shut off and volumes deleted if you hit some arbitrary marker. There's nothing you get for free in AWS (besides the Free tier, and not many people are running their entire, highly profitable business on that) and the only solution to "not spend more than $X per month" is to literally shut down and delete things.
I'd love to hear use cases where legitimate businesses, who make money off of the products or services they offer, can literally afford to have their business just stop working. It sounds totally contrived.
A CloudWatch alarm on a billing metric could also be used to send you SMS, email, hell even call you if you want to wire a webhook up to a quick and dirty twilio app (via SNS)
In fact, we use an SNS->Slack gateway running on a free Heroku dyno to get out alerts in a Slack channel (which is pushed to phones/etc), along with other CloudWatch alarms related to performance.
Honestly, this issue of "I don't have any visibility into what I'm spending" is a waste of energy. You do, and you can have AWS bug you as intensely as you want with updates as frequent and as urgent as you need
It's not "playing": reading is fundamental. Their billing rules are clear. It could be argued that their vocabulary for describing the billing rules takes a bit of figuring out. I have a client that didn't understand either the rules or my instructions and did something silly and ran up a $5000 bill, when he was thinking it would be $100~$200. We called Amazon and they cancelled the bill.
Amazon is very easy to work with, if you simply tell them that you are an idiot and fucked up. You're not the only one.
Can you use a pre-paid credit card with Amazon? (Not that that would absolve you of owing the balance - but they might halt your account for lack of payment and prevent further charges from accruing).
AWS charges are monthly so it won't help much (also they don't immediately pull the plug, they send you the email warning first). One just needs to setup the alarms and pay attention when deploying a new code. It sounds far more scary than it really is.
you could protect yourself by setting up a limited liability company (cost in the uk is about £14), then your assets aren't at risk if something goes very very wrong...
Amazon probably should do a credit check before offering thousands of pounds in credit...
(I am not a lawyer and this should not be taken as legal advice)
I addressed that in other comment: I don't want to have to rely on that. For starters, there is no real data about that, just anecdotes. How do I know they will reimburse non-US customers too? Many companies have that policy: They protect US customers because they can sue them, but people from other countries can only complain on the internet.
You are creating one of those arguments that really add no value. Really, if your app is succeeding you might want it to shut it down? No you are just creating another strawman argument because you see a service not offering one feature you MIGHT want. Seriously, get over yourself.
And AWS is the only service that supports both, and any finegrained solution in between, by triggering programmatically actionable alarms.
You just have to set it up, and if you cannot be bothered, AWS isn't the service for you. If you don't want to do your own cooking, fine, but don't whine about the grocery store not providing you with your own personal chef.
All he asks for is a reasonable feature that can be enabled or disabled as the customer wants. You may not need the feature, he does.
This is hacker news, ie for people who like tech, like to ticker with it and play with it. What is so bloody wrong with wanting a safety button so that you don't ruin yourself that you have to throw out insults?
Yeah, Amazon's key model is a pretty big weak point, both Google Cloud and Azure handle it better. It would be safer to use different sets of keys, like one to create new machines, and app-specific keys that can update only, but that's more work and more headache to manage. Google Cloud just makes me SSH tunnel, which I like.
A friend amasses $200 bill overnight due to bad looping when experimenting with Lambda. This is all too common of a story now. Amazon should do something other than goodwill refund.
This isn't true at all - the main issue that most of those articles have faced is either:
* Committing root credentials to a public git account (equivalent to your root account on every machine + ability to purchase new servers…)
* Spinning up instances during free period, then forgetting and getting billed the $10/month on them a year later
* Not reading the costs, and trying to replicate what you might normally purchase in AWS and being surprised at the cost, rather than buying 101% of capacity required.
I'm using it to host a mid sized website with an intranet type app with servers spanned across multiple data centres, built in redundancy etc for around $100/month after reserved instance one off payments. It's crazy cheap and in my view, incredibly powerful even for smaller businesses.
Given the size of reserved instance pre-payments it seems a bit disingenuous to claim you're paying around $100/month. Reserved instances are definitely the way to go if you have a steady state load that warrants them, but you do have to look at that pre-payment as part of your monthly costs to get a proper view of what's being paid.
This article appears to include a lot of very good advice(speaking as an AWS solutions architect). I might suggest a emphasising a few things such as not having keys on login accounts(they negate multi-factor auth if leaked), and to ALWAYS pick or create a new IAM role if you aren't sure an existing one fits for the EC2 instances.. But perhaps this sort of advice is not appropriate for the article.
Much respect for the amount of work that went into this. I'll try to get through it all here at some point :)
Apologies in advance for the table of contents going way off the screen. This is the biggest post published so far. We'll be doing some UX work on the table of contents widget in the next week.
While you're at it, how about a reasonable print stylesheet? I had to do a lot of surgery on the node.js tips article, but still gave up because I could only get a max of 19 lines of the code snippets to print
We've scheduled a lot of UX design polish on our posts schedule in the next 2 weeks along with a big announcement first week of feb for you to watch out for.
Out of curiousity, why go with AWS when Linode, Digitalocean, etc appear to be so much more cost effective? Is the simplicity of spinning up AWS instances really great enough to counterbalance what appears to be a significantly greater cost? Is it the flexibility of different AWS services?
Article author here. So, you're right that while AWS does continue to lower prices, they're still not the cheapest game in town. Frankly, they're not even necessarily the most performant game in town.
What they are really competing on is breadth and depth of service. The article goes into a lot of those services, but, as one example, if you launch an instance in EC2 you can allow it to access secured buckets in S3 without any need to store keys/passwords on the instance itself thanks to IAM roles.
Another example is services like AWS Lambda, which is a hosted way to run a function without any need to manage servers.
The list goes on and on...direct VPN connectivity, Hosted Active Directory, CloudHSM. While I'm biased, my perception is that AWS is pretty far ahead of the pack.
Thanks for all the replies. I am just researching all of this for my own startup and it is important to understand all the tradeoffs. And it is clear from your article that AWS has a very deep feature set. Its a good article!
Actually, technically, StackExchange is not profitable yet: (http://www.joelonsoftware.com/items/2015/01/20.html). However, "We could just slow down our insane hiring pace and get profitable right now, but it would mean foregoing some of the investments that let us help more developers."
I think that's spot on, it is all of the bells and whistles along with a fairly predictable management cost, even if you are new to AWS, that make it a safe choice for a big swath of the market.
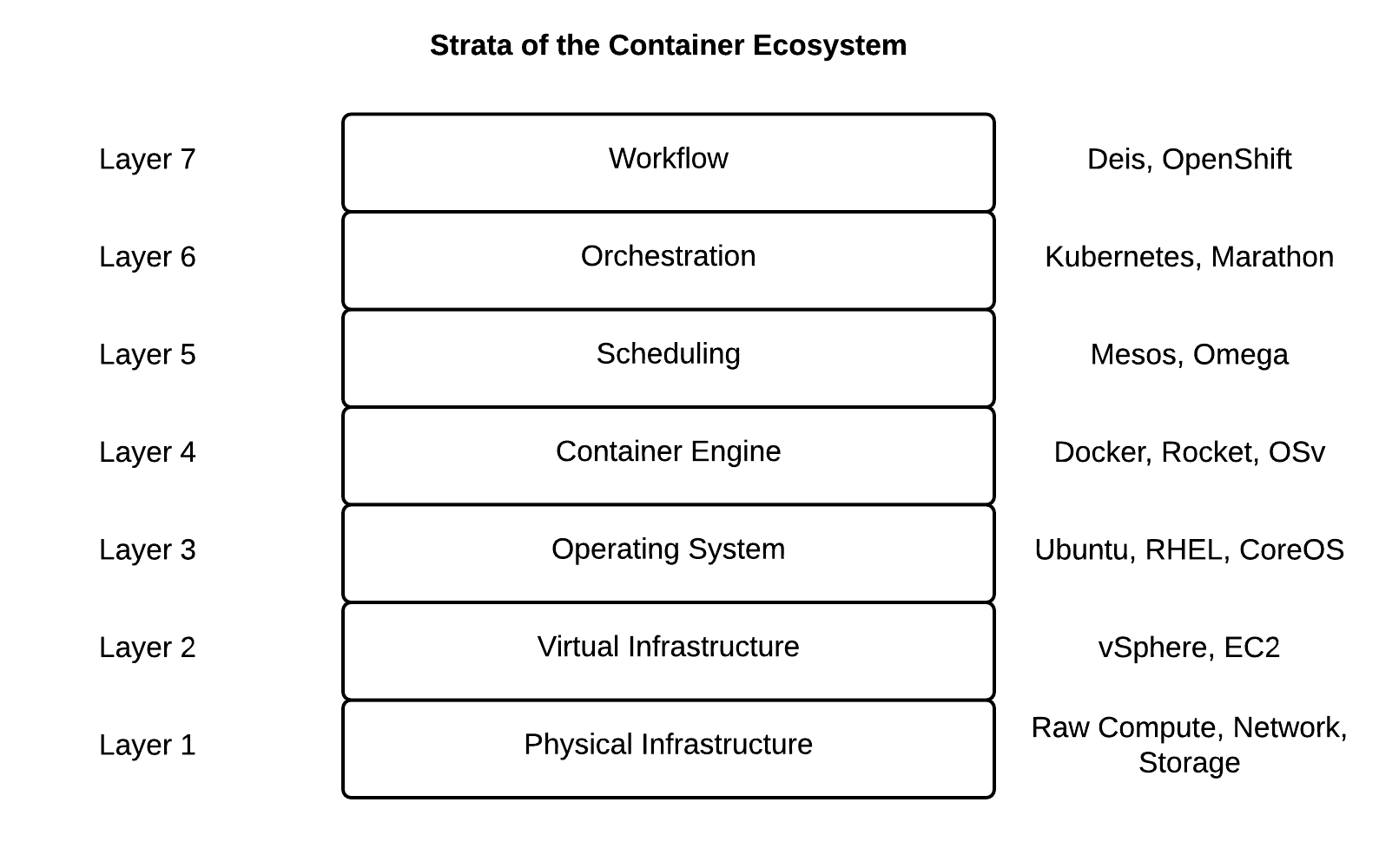
Kudos to you for touching on containerization, I would just like to add that the many emerging platforms and tools (https://pbs.twimg.com/media/B33GFtNCUAE-vEX.png:large) are rapidly starting to provide an alternative to AWS that was not there before in their ability to realize more competitively priced hosting alternatives without sacrificing on administrative overhead.
For 99% of startups the cost of web hosting is negligible next to the cost of labor. Even the tiniest gain in productivity will overshadow hosting savings.
Not valuing your time is easily among the biggest mistake you could make.
That is very true, time is quite valuable. It appears that for my use case AWS would be at least 5x as expensive though. I won't know for sure until I actually try running some benchmarks. Have you had experience showing AWS to be significantly faster to deploy and administer than Linode, DigitalOcean, etc?
IME, AWS is slower to set up initially. Since you are starting out with it, I'd say it will take longer to do things "the AWS way". This article should help quite a bit with that part.
The real trick with AWS, IMO, is figuring out what you want to do yourself vs what you want to have hosted. For example, they offer a hosted cache such as memcached or Redis. For my app, I run Redis myself as it required roughly 15 minutes of work total to set up and maintain in 2014. OTOH, that's not nearly the case with Postgres. I spent a day and a half tuning the version I host, switching to RDS, then switching back because RDS was too slow (even though by the specs, it was using a more powerful VM than the EC2 box I was running my instance on).
Basically, once you grok AWS, things become more productive AND you don't need to spend time on doing things like setting up VLAN's, transferring data between boxes, etc. You can do cool things like detach a virtual disk from one VM and attach it to another, rather than pushing 100 GB's of data over a network. This, AFAIK, is not something that Linode or Digital Ocean can do.
Having said that, DO is great for lots of things. It's a good place to experiment and to run lots of really small things. For me, that's side projects or things that I am trying out before thinking about moving them to the "big iron".
> Basically, once you grok AWS, things become more productive
> OTOH, that's not nearly the case with Postgres. I spent a day and a half tuning the version I host, switching to RDS, then switching back because RDS was too slow
These two statements are contradictory.
You would have been better off just renting a dedicated host for your DB and doing the tuning yourself (either in person or getting someone to do it) - because the AWS offering is slower than your own instance, and database is a service thats often ripe for easy optimisation by using a dedicated host/cluster of hosts vs virtualised host(s).
Of course dedicated hardware is faster. It is also very inflexible. You cannot clone your DB box to 10 more instances wishing minutes. You cannot detach and reattach volumes withing minutes. You cannot resize the box to 2x size withing minutes. You cannot move it to a different VLAN within minutes. AWS is not the speediest, but it certainly is flexible.
According to your comments though, you'd have been just as well served with a regular VPS at a regular VPS host - you wouldn't have wasted time to found out RDS is slow, and you wouldn't have issues with slower than usual disk IO on EBS.
My point about physical was just another common optimisation for performance critical DB servers, you could probably get close to bare metal speed with the flexibility of virtualised by using a "single VM on hardware" model that some providers offer now.
Thanks for the perspective. Right now I am still just in the experimental phase of building things and even an early beta is 6 months out for my project. Like you said there definitely are a bunch of useful tools on AWS. This article definitely convinced me to actually spin up an AWS instance and see how well it works before just going with Linode or DigitalOcean.
I don't think doing it the AWS way is always necessary from the start. You can do a lot of simpler stuff with ElasticBeanstalk or OpsWorks and you'll still be in a better position to scale than working straight on a VPS.
The advantage of AWS is the scale at which it can operate and the rich ecosystem of services (S3, ELB, CloudFormation, RDS, etc) that you can use as building blocks for your app. DigitalOcean, Linode are more like VPS providers and are only suitable for a subset of the use cases AWS covers (or Azure or Google Compute Platform)
If you are/have skilled sysadmin staff, there is very little if anything AWS offers that you can't run on your own rented/owned phsyical/virtual servers.
I'm not suggesting that's ideal for all companies, but this idea that somehow it's impossible to run a load balancer or store files without using AWS/Azure/Google 'clouds' is a bit ridiculous.
I've spec'ed out S3 alternatives for clients, and pretty much no matter what criteria they have for redundancy, managed hosting solutions or co-location comes out much cheaper than S3. E.g. typically half or less of the S3 costs for triply redundant servers, on RAID arrays, in separate data-centres with replication (e.g. using OpenStack Swift, or Gluster / Ceph + an API layer for example)
For larger setups you can do it at 1/3 or less of the cost if you're prepared to go the colo route (rather than managed servers) and leasing your own hardware.
If your average bandwidth usage per object is high you can trivially cut costs far beyond that, as the EC2/S3 bandwidth costs are atrocious.
The exception would be if you can't avoid huge amount of object accesses from within EC2 even if you move the storage out of S3.
For the vast majority of people, S3 means cheap, mass storage.
For the majority of those people, a simple SFTP/rsync/NFS/whatever endpoint (potentially with replication to provide redundancy) would more than fit the bill, and would actually be simpler to use than the S3 API.
I store about a terabyte on S3. It costs us $25 a month. If I spend more than a few minutes a month administering an alternative setup, I've lost money compared to just paying S3.
That entirely depends on how you use the data. If you store files that are accessed over the general internet, and each file is downloaded just once in the month, you've just quadrupled your monthly cost, thanks to AWS' high data transfer fees.
Are there any resources out there that teach developers weak on scaling/architecture how to manage this themselves? What architectures are the "best practices" of today? What tools are proven? Any books/articles/papers to recommend?
Good point, it becomes clear that if you are operating at the scale of a large company the large scale and rich ecosystem are important. It was just a bit surprising to me that for smaller scale instances AWS is so much more expensive. It would seem they should be cheaper due to economies of scale.
AWS is definitely aware that their costs can be prohibitive for brand new startups. Check out AWS Activate[1]. If you can demonstrate that you're a legit startup, there's a decent chance you can get free AWS credits, not to mention free support.
Getting the business level support is absolutely necessary if you don't have someone with AWS experience and are doing anything substantially complicated. The free-ish support is, on the whole, pretty abysmal. The availability of solution architect time is not always useful. You ask 3 people and get 3 different answers. I've given some thought to doing consulting around this for equity but haven't figured what that would have to look like. There's a lot of wrong turns one can go down pretty easily. Bottomline, Activate is helpful but not sufficient.
Consider that whenever you are paying for AWS you are also paying for whatever proportional part of the AWS infrastructure is sitting idle at any one time - Amazon still need to cover those costs - it just get amortised over the paid resource usage.
Really? I know reserved instances lower the price but they still have shown themselves less performant for the dollar in the benchmarks I have seen. Are there any good articles you could recommend with benchmarks showing AWS to be more cost effective?
My experience is similar. EC2 performance is mediocre in general and quite poor compared to dedicated bare metal. Disk I/O is abysmal (yes, even on "SSD" EBS).
Any citations? There are lots of people using EC2 at appropriate instances sizes to do compute intensive loads. Provisioned IOPS and, again, appropriate instance types are necessary to get high performance disk I/O.
My "citation" is my own experience managing infrastructure for several AWS-backed startups. I think public cloud services have a role and make sense in certain cases (particularly for very early stage companies), but I'm realistic about their performance characteristics and tradeoffs. The biggest danger is in overuse of proprietary AWS services, which makes it much more difficult to migrate off when the business outgrows the public cloud.
EBS is not intended for high-perf applications. This is well-known and well-understood. As far as CPU perf being poor compared to bare metal--you might be the one person out there who actually needs it, but I'm betting not.
I use AWS, and will continue to use AWS, because it means less screwing around with stupid things and more time making important things work.
CPU-bound workloads are not particularly rare. Also, EBS is your only storage option for any data you might care about. 90% of the reason RDS exists is because I/O is so bad on normal EC2 instances.
You can run a database just fine using provisioned IOPS EBS especially in a RAID 10 configuration. I'd like to see some data to the contrary as I've actually done it.
There's some disadvantages to using RAID 0 with EBS volumes in a performance dependent situation.
Since you're writing to multiple EBS volumes for the RAID 1 portion of the RAID 10, you're going to require more EC2 to EBS bandwidth.
EBS volumes are replicated across multiple servers, so you don't necessarily need the reliability, especially if you're replicating the data elsewhere.
YMMV, of course, and everyone has different priorities and different levels of what constitutes acceptable risk, but RAID 0 with EBS isn't quite the data death wish it is with physical hardware.
> EBS is your only storage option for any data you might care about.
No, it's not. It is if you want data-at-rest storage, but I don't care about that when I have multi-master MySQL and Postgres running on instance stores. Or when I have replicative NoSQL databases (Riak is more than happy running forever in instance stores and duping across AZs).
I only have a general comment about this, but that kind of performance is almost not worth thinking about in most cases. Just like NBA players need to be "tall enough", your cloud needs to be "fast enough", and AWS is just that.
Having said that, nothing beats getting real hardware in terms of performance/$. I used to work for a company that exclusively worked on SoftLayer's hardware servers. These were $500+/month each, but they were fast. The point is that if you can devote a dual octocore machine to what you are doing, and are willing to pass up on the SAN, flexible networking, etc. then you get a very fast box. If what you are doing requires lots of very fast hardware, then yea AWS or anything like it is not really for you. But if you are like most people, your AWS bill is not going to break the bank and you can just spend one less billable hour figuring out why the server is slow, and just double its size.
Compared to provisioned IOPS SSD, it's about the same. Compared to regular "burstable" SSD it's much much better. The gp2 EBS SSD is not actually meant to be used for data storage, something which AWS hasn't done a good job of making clear.
2 years ago I would've gone with a vanilla 3 tier app in AWS with cloud formation... Now I'd pick DO with a CoreOS cluster running Docker containers for each service... or maybe Atlas by Hashicorp [1]... No vendor lock-in, still flexible and fun to build... =)
I'm a real newbie in terms of web server deployment, but for my first web app I went with an EC2 VPS because I had no idea what sort of traffic to expect and how I would handle spikes. Despite having a pretty decent VPS from Inception hosting (whom I recommend, no affiliation), I wouldn't know what to do to scale up.
EC2 seems to handle all that nicely by letting you just upgrade instance types as you need them, and providing burst performance for spikes in traffic. It seems like a pretty fire-and-forget solution and I've not paid them any money yet (10 days, 30,000 hits)... So far I'm happy but really I've no idea what I'm doing.
It can also totally depend on what you need, instance-wise. I have a workload that includes a lot of processing and high-memory requirements.
A 60GB r3.2xlarge spot instance on AWS will cost you about $50/month while on DO you'll be paying $640/month for a 64GB machine.
Granted, the DO machine will be way more performant, and you have to have a workload that suits spot instances.
Every time I look at things like DO to see if I'm missing out I price up my current AWS setup and they're always astronomical (for my use case).
Then there's all the other control around AWS; it's so much more advanced than all the other services. Nobody else really comes close to the flexibility they give you.
For a lot of (probably even most) web apps that probably doesn't matter. Have a look at your use case and decide if AWS is worth it.
You're comparing apples with watermelons. The only thing vaguely similar is the memory, and it's only cheap because you get it randomly as the market fluctuates.
In every other regard - disk space, CPU cores, data transfer, availability - the AWS spot instance option is MUCH worse than a regular VPS like from DO, or even a dedicated physical host.
Ignoring the CPU core difference, a regular (i.e. so you can use it all the time) instance with extra EBS storage and data transfer to match the DO instance you mentioned, would be $1500/month.
Places like Rimuhosting will rent you a pre-used dedicated server with 128GB RAM, 2TB HDD + 200GB SSD Dual Xeon (12 cores, 24 HT) physical server (which you can then run a single Xen VM on, for better portability) for $400 a month. Yes it's more than your $50 a month, but its completely yours, for as long as you want it.
To truly take advantage of a spot instance and NOT have it impact your business, your workload needs to be very tolerant of interruptions and variable processing time per day. For the vast majority of people using EC2 (web/app servers running 24x7) it's not a realistic option.
Agreed. But that was also my point - it depends on your application.
Aside from that though, spot instances aren't that volatile. I have some that have been running for months. Obviously they're not always at the low low price they can be, but if you average it out, they're not much higher than that.
In total honesty, I don't use those machines I mentioned. I use ones with 32gb ram and much better CPU performance. I need that ram for what I'm doing and any other provider I've found comes in a lot more expensive to satisfy that requirement. The CPU I get is good enough for what I'm doing.
But again, I don't know anyone other than Amazon that has an infrastructure that flexible at that price.
To me AWS still suffers from the same problem that most others do - their pricing is based around fixed allocations of everything (i.e. CPU, RAM, local disk space) - what if you want lots of RAM but don't need lots of disk space? Or Vice versa.
Oh for the.... Could whoever down-voted this please have the decency to chime in with a reason?
If there's anything incorrect with what I've said, please point it out. I'd love to know about other providers that would give me more bang for my buck.
Is it the assertion that spot instances are a viable option for some use-cases? Is it the fact that I compared something to DO?
These guides are really hard to read (at least for me) because there isnt really a point (until the end) where I can stop and go try out some of what I've learned. Perhaps, if it were formatted in the way of "steps to setup a scalable web app on AWS" it would be more palatable.
In either case—assuming you run a VPC—you usually configure one or more NAT instances to allow EC2 instances to communicate with the internet (http://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_NA...). I suppose a bastion could do double-duty as a NAT, but in most cases you want one per availability zone to add isolation and redundancy.
Doesn't this -somewhat- mitigate the advantage of having zero-surface area?
I'm using a Bastion setup, so don't get me wrong, just want to understand how strong the pros are for the VPN route.
On your last note. I just run one Bastion as a general rule. They're quick enough to spin up another instance (in a different AZ if necessary). Generally our services won't die if the Bastion or NAT is down.
We (Appuri) use VPCs exclusively. There are pros and cons. I'll try to list the top:
Pros:
- Logical isolation. You can put instances (and RDS, Redshift) etc. inside logical subnets that are not addressable from the outside world.
- VPNs. If you really want extra security, you can wire up VPN so one of your VPC subnets shows up on your corporate subnet.
Cons:
- A complete pain to manage with SSH-based tools. Most deployment tools (Ansible, for example) and even lower-level tools like fleetctl don't play well (if at all) with jump boxes. Example - Ansible Tower requires instances that are publicly addressable OR placing a Tower instance inside a VPC (which means we can't use it to manage multiple VPCs)
- We have had to write our own workarounds for the above con.
- Complexity. There are more concepts to learn about.
- Lack of portability. I don't know if all cloud providers (Azure, DO etc.) even support VPCs the same way AWS does. This makes our infrastructure less portable than I'd like
I think you'll find you can solve this via ssh config. Specifically using ProxyCommand -- in the case of Ansible anyway. You can then ssh reference an internal address.
I was asking less about VPCs in general, more the use of the VPN->VPC or Bastion approach to bridge into that network.
We use fleet within a VPC and our approach is to just have a single "ops" box in the public subnet and then use $ETCD_ENDPOINT (or whatever the environment variable is) so that etcdctl/fleetctl can connect to one of the boxes in the etcd cluster.
We disable password login on the ops box and set up 2FA on SSH connections. We haven't taken the step of whitelisting IPs but it's probably something we should do.
I just finished moving our last EC2-Classic service into VPC. It's been less of a headache than I anticipated.
If you need a VPN, you'll know it. My advice if you don't need a VPN now is to leave a few smallish subnets in your VPC for NAT'ing if you need to setup a VPN in the future. Then, just white-list the IP's that have access to your bounce boxes. Create a Temp security group and add your home/hotel IP on demand, blow all the rules away regularly. You have essentially have a multi-factor protected white-list for your bounce boxes at this point.
The logic here being you'll only need certain things on the VPN, and you can put them or give access to them through the small subnets. You can simply use NAT to translate a /28, /29, or whatever to an available block in your corp network. This won't work for everyone, but I think for a lot of cases you don't need full access to the VPC via VPN and you'll know pretty early on if this will work for you or not.
Great to see article putting it all together. Also going to be great to send this to people who think that using AWS cloud means that you can skip hiring people with skills in systems administration.
I knew I'd see a bunch of people stating that AWS is expensive and you should use a dedicated server or a VPS. But there are many applications built by people like me who are lone developers or small teams of developers who either don't have the admin skills or simply don't want to admin their own servers and the fact that AWS handles quite a lot of this for you is sometimes worth the the added cost.
{kind=link}
Normally when I learn something new, I learn by tinkering and breaking stuff. I don't feel comfortable doing that with AWS. I'm hoping people will tell me I'm way off base because this fear has stopped me from getting the ball rolling.