I really wanted (and still want) JPEG-XL to succeed.
Not sure how feasible this is, but one thing that could of helped with .jxl is allowing it to be read by a jpeg decoder. Let me explain. JPEG-XL has a feature that allows you to pull out a fully compliant jpeg, if you could somehow send the entire .jxl payload, and the browser's jpeg decoder just decoded the jpeg part, I feel adoption would be significantly easier, because then there is very minimal risk to just serving JPEG-XL with or without browser support.
Edit: Changing jpeg decoders around the world is not the approach I'm suggesting, but rather a carefully done "byte hack". Put the JPEG at the head of the binary blob, and stop decoding when the JPEG ends. If JPEG decoders only stop at the end of the byte stream, then another approach would be required.
Presumably, JPEG-XL decoders would produce higher quality decodes out of the same file while being backwards compatible with browsers that only have support for standard JPEGs
If it's backwards-compatible with standard JPEG decompressors, then you've just made a better JPEG encoder. And that's great, and people are still doing that all the time, but we don't need a whole new ISO spec to do it. All of the JPEG-XL enhancements are new additions to the format that aren't backwards-compatible.
I’d make the case it is the opposite. One off-brand browser can hold up the industry’s migration for years.
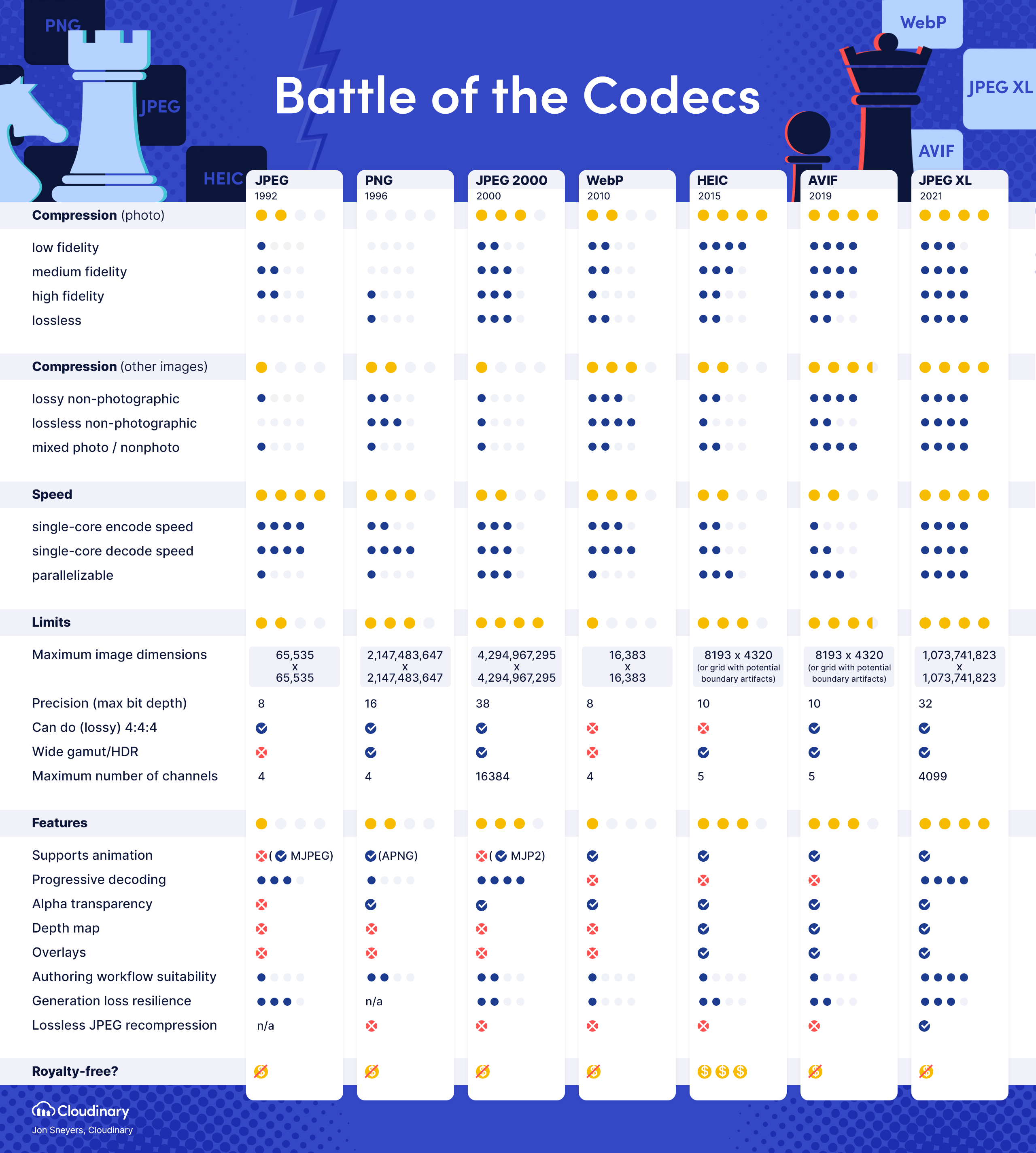
The cost model of images is such that you only get the full benefits of a new compression system if it is so widely used you can abandon old formats. That’s because the cost of images includes storage, transfer, plus handling and processing costs. If you have to maintain a large number of different formats, say JPEG, WEBP, AVIF,and JPEG-XL it’s just awful.
I can’t really use a new format until Safari supports it on mobile and mac at the very least. My take up of WEBP was considerably delayed because Apple was slow to get it in Safari on older Intel macs (one of which i have.)
Votes and comments aren’t a measure of popularity or importance. They’re super easily skewed by specific communities deciding to hammer the reports or similar - often about things they don’t have technical understanding of.
Other examples would be when Libc++ announced adding bounds checking by default and a huge number of people (from HN and similar) came in to provide votes/+1s or comments with little actual technical feedback
"Google's deprecation of the JPEG-XL image format in February in favor of its own patented AVIF format might not end the web in the grand scheme of things, but it does highlight, once again, the disturbing amount of control it has over the platform generally."
The specification of AVIF is also publicly available, while you would have to pay a little under $500 to purchase all five of the ISO/IEC 18181 specifications for JPEG-XL. Not a monumental cost, but something prohibitive for a hobbyist:
The C++ committee makes draft versions of the standard available for free[0], I've heard that often the last draft before a new standard version is published is almost identical to the published version. It would be awesome if someone involved with JPEG-XL could arrange for the same. Edit: I found https://arxiv.org/abs/1908.03565 but it hasn't been updated since 2019.
Patented and royalty-free are not distict, it depends on whether the owners of the patent have agreed to others using it royalty-free, which is the case here (for both AVIF and JPEG-XL, and both have Google owned patents I think) .
So they are technically correct but a little misleading.
Google did not create JPEG-XL. They answered a call by the independent JPEG standards org, as did others. The majority of the spec and ideas came from elsewhere, as did the reference code.
Next you'll tell us Microsoft made C++ because they have an employee on the standards board...
This is kind of an awkward issue for FSF, since the relevant parts of chrome are free software. You can fork chrome and keep the jpeg-xl implementation in and surf the web.
But that doesn't matter, because the source being free isn't the issue, it's the default in a complex ecosystem of websites responding to browsers supporting standards, which they judge by uptake of the pre-standardized versions, etc etc etc.
{kind=link}
Not sure how feasible this is, but one thing that could of helped with .jxl is allowing it to be read by a jpeg decoder. Let me explain. JPEG-XL has a feature that allows you to pull out a fully compliant jpeg, if you could somehow send the entire .jxl payload, and the browser's jpeg decoder just decoded the jpeg part, I feel adoption would be significantly easier, because then there is very minimal risk to just serving JPEG-XL with or without browser support.
Edit: Changing jpeg decoders around the world is not the approach I'm suggesting, but rather a carefully done "byte hack". Put the JPEG at the head of the binary blob, and stop decoding when the JPEG ends. If JPEG decoders only stop at the end of the byte stream, then another approach would be required.