I'm a technical writer and good diagrams are extremely valuable. I'm very skeptical of "diagrams as code" because it seems like the goal is to minimize effort, not to produce a useful diagram.
Good diagrams, including architecture diagrams, require careful consideration: What does the reader need to get from this diagram? What should I include and what should I leave out? How do I organize items so that readers can understand the diagram quickly?
Maybe diagrams made in, say, Visio, draw.io, or Inkscape are fine when you're the sole author of them, and you create typographic quality documentation, a business presentation, or otherwise need eyecandy.
In my practice across a few companies, diagrams made in code-oriented tools like Graphwiz, PlantUML, or Mermaid were vastly more useful for documenting real, evolving engineering projects.
* You can store them along with other documentation texts. Their source is always obvious.
* Version control! You can diff them and make sensible pull requests when updating some small aspect of a larger diagram, along with text, and possibly as a part of a code change. You can review, discuss, and approve the changes using tools familiar to every engineer.
* The amount of visual tweaking the language allows (graphwiz, quite some; mermaid, minimal) prevents bouts of bikeshedding and keeps the diagrams focused on their essential parts.
* Since the language is open, and no special tools are needed (except a text editor and a renderer on a web page), the diagrams are now everyone's concern and purview, as opposed to the person who happens to be good at graphics.
* The formats are not locked up; you don't need an authoring license, a subscription, a particular OS to run the editor, etc. You own your diagrams.
* Sometimes you can generate these diagrams from other data you have, pretty easily, and with consistent results.
These considerations appear to overweigh whatever visual imperfection issues these tools have.
I very much agree and the only thing that I'm missing is tools that generate a somewhat stable output. What I want is tools that take their last output into consideration and generate new diagrams that are both correct and as similar as possible to the last output they produced. They should do what a human does out of necessity when updating a diagram manually - make it represent the current state correctly with minimal effort.
Of course that means the diagrams will not be optimal in any case. For example, there could be better arrangements of boxes or less crossings of lines. I sill think stable diagrams are important for our limited brain and one important reason why people shy away from automatic diagram generation is the mental chaos a complete rearrangement of elements brings with it.
One example of a software that got this right is Taskjuggler, the obvious counterexample is Graphviz.
> What I want is tools that take their last output into consideration and generate new diagrams that are both correct and as similar as possible to the last output they produced.
Something I've been struggling with as well. Now it sounds like a task for ChatGPT and dot, need to try that today.
If you're not too fussy about results it might not be "that hard" to load a previous layout into dot, and optionally mark the nodes and edges that are allowed to be moved (or preferred not to be moved), and run the algorithms on that. It "just" needs someone to work on it, or pay for developers to do it. We wrote a paper about this in the mid 90s and Gordon Woodhull even got a successor of that to work, see dynagaph.org
The graph drawing community extensively studied algorithms that update and "preserve the user's mental map" of various types of layouts. It's all heuristics anyway; sometimes they produce locally optimal layouts, but it's not as if extant layout systems are producing mathematically optimal layouts in general.
I find the code-based drawing tools to be a little finicky for my taste, and the compilation pipelines turn into a real pain if you want to, say, embed a .png in a markdown file and just have it display in your Git web interface of choice (obviously GitHub's Mermaid support helps if you're in that environment).
My preferred workflow is to use draw.io's PNG support. They embed the draw.io data into the PNG's chunks, so a regular image viewer opens it fine but you can directly edit the file in draw.io. If you have Git set up to diff images, that also "just works" when reviewing the history. Plus, there's an excellent draw.io plugin for VS Code that embeds the editor right into VS Code and will transparently open and save "foo.drawio.png".
Minimizing effort is IMHO almost always a worthy goal. All else being equal, less friction in making or maintaining a diagram means diagrams are more likely to be made and maintained, or that more thought can go into a fixed amount of diagrams. People who don't care about diagrams being useful when making a diagram is easy won't suddenly start caring when it's hard.
Also, not all diagrams are there to communicate a carefully considered point. One other value of "diagrams as code" is the ease with which you can turn the output of some program into a diagram, providing another useful way to think about the problem you're solving. For example, when debugging or verifying correctness of code I've been writing, I find it occasionally useful to add a bunch of print statements sculpted so that I can paste the output log into PlantUML and immediately get a nice, visual representation of the thing I care about. Such diagrams are throwaway, generated on the fly, but can be of great help.
That is a very valid point. A bit of a counter argument at the bottom:
There is a model and auto diagrams which represent the current state. Good for analysis (automatic or not etc). Can go very detailed. Model as Code, in a database, xmi files, auto analyzed from code. Whatever.
However, there is a difference in the architecture depending on the moment and the perspective. Before coding, you actually communicate the architectural solution. Here presentation matters a lot. A pure model and auto diagraming sucks. Same when you go to a manager. They do not give a shit about the correctness. If they do not find themselves within 2 seconds in your diagram, the diagram is lost.
So unfortunately, both angles have very important uses.
Random example I did the other day: I wrote a small Dependency Injection library for a project in Common Lisp. Because it handled wiring up both big and small systems, and was designed to be composable, it wasn't easy to see the entire graph of all the components from code. It wasn't impossible - I designed it to be declarative and locally readable - it was just tedious.
My solution for this was to write a helper function that, when called, would walk the entire graph of those components, and print it in PlantUML form. More specifically, the code walked the pointer graph and made a mirror of it, in the form of lists of vertices and edges - then, it would loop over vertices to print a "class Foo as Bar <<Baz>>" kind of line for each of them, and then loop over edges, printing lines like "Foo <-- Quux" or "Foo +.. Quux". The result, also bracketed by @startuml and @enduml lines, could be copy-pasted or streamed directly into a file, which I then fed straight to PlantUML, resulting in a very nice DAG of actual relationships between all concrete instances of components in the running program.
Simple. You just make the program print out all the data that will allow you to construct a visualization you want. How to best do it depends on your particular problem and preference.
So, on one side of the map, you have your program, which you can modify to make it print stuff. On the opposite side, you have PlantUML (or GraphViz, or ggplot for plotting charts, etc.). How you connect them to produce the visualization you need is up to you.
For simpler problems, you can do it the way I described in the part you quoted - print diagnostics about an object in a format that's valid PlantUML syntax. For example, as you walk a DAG of objects, do:
You can then literally copy and paste that part of stdout into a file, perhaps decorate it with @startuml and @enduml (or just script it away too), and you'll get your diagram.
For more complex problems, you'll want to print what you can where you can, and have auxiliary script to sort and group that output properly, and then write out a PlantUML diagram.
In the middle sits a technique I found particularly useful. PlantUML itself is a programming language (and probably a Turing-complete one). It has variables. It has functions. It has preprocessor macros. You can prepare yourself a small DSL in PlantUML, so that you can meet your program in the middle - whether it's because you want to keep your output more readable, or because it would be too invasive to modify a program to print things the way PlantUML wants them.
Don't know what else to say here. The idea itself is not something particularly brilliant, or difficult.
The shortest one is for a single communication. Think "created in a meeting, used in a meeting". These need to have zero friction to make, their maintenance life is measured in hours, and quality doesn't really matter. You'll do best to use a whiteboard or paper. Take a photo with a camera if you regret thinking it's of no use in 24 hours, and convert to one of the other formats.
The second one is for a planning stage. You might argue different design decisions and their merits. You need to be able to point to a few different solutions to keep the dialog going. These likely need to be pre-made (can't make them IN the meeting as that's too time consuming) but they should be easy to adjust during a series of meetings. Here is where you may want to use some simple drafting tool or Visio or similar. This type of diagram also works well for a presentation where you want to show a group of people a design/architecture - but you can then throw away or archive the presentation. The key is that these diagrams aren't live documents. They have a lifespan limited by some specific event such as a meeting, a presentation. You may be tempted to keep them, but it will be a historic artifact. A recording of the presentation is more useful than the diagram itself. The key thing to remember is that they are useless for describing an evolving system as no one has ever successfully maintained/updated a set of Visio drawings over time to accurately reflect the system they described.
The third one is when you want to achieve that impossible goal of having a living document. The only way to have a living document for software is as code/text, since the only source of truth is version control. Either it needs to be constantly modified, or (ideally) it has to be constantly auto generated. The quality of a generated document is going to be nowhere near a hand-drawn visio thing, but on the other hand it will describe the system, unlike the visio document which was last updated six years ago.
Most of the architecture diagrams that I review and sometimes write are of the second kind. Once you have planned and set for execution, the architecture rarely changes. If it did, then there was something fundamentally wrong with the first architecture and as s result this diagram will be modified in a review or a rewrite or whatever.
A live architecture document derived from code, even on a batch basis if not in real time, will be a really cool endeavour. If you can somehow look at a repo and generate a diagram describing all the different subsystems and their interactions, boy imagine that !
A simple traceability might be just through imports starting with the main program. Start with the main functions and trace them through. May be using a tool like sourcegraph.
Between the high level architecture diagrams which don't change much and the code itself, it feels like we are missing a strategy or tool for visualising mid-level code structure which is in between these two ends of the spectrum.
At work we have a bunch of Python services which do REST API and CRUD for the most part. There we have a simple plain python dependency injection set up which puts together the different components/classes of service and makes sure that each is provided with the references its dependencies. This is defined in one python file. I experimented with parsing this file and graphing the relations between the components, and the result was pretty good (given my low effort). It did a good job of exposing the relations between most of the important classes and where things had gotten messy.
It is extremely hard to keep documentation up to date without a full time technical writer (GitHub had none). Rendering a diagram usually means unique steps to get there and once the maintainer is gone, so are the updates (a great example was how their loadbalancer diagram was 5 years out of date when I got there). I went about talking loudly about the importance of a diagram which resulted in folks saying “they are not visual they can only understand the code in their head”, senior and staff engineers said this. I immediately realized I had to solve this. I made a few actions that would render mermaidjs files (which was later automagically rendered without requiring actions) much like a DIAGRAM.md file. Rave reviews from everyone who came across it “wow now I understand how this platform works” “it’s so easy to make an update to the diagram during architecture planning”.
Unfortunately my team was dismissed while I was in the middle of this project, so I never saw how it ended. To answer your questions, I advocated to break the architecture into chunks. You can get the big picture by following each diagram, or include other diagrams into one large one but to focus the output to specific readership (usually part of the documentation that defined the components)
This is true, but for me it's in tension with my desires to a) minimize duplication, b) keep code in sync with docs, and c) keep cost of change low.
In service of that, I think the article's correct when it says, "we should be using code to generate architecture diagrams". Anything else produces expressive duplication between the system and the diagrams, which either increases the cost of change or guarantees documentation drift over time.
Diagrams are valuable and useful. But some of us simply can't create them using "graphical" tools. I literally can't even make a drawing for something as simple as a dog house with any on-screen tool (mouse, select, point, click, drag etc) - I've tried so many times. I just can't do it.
But I can write relationships, connections and the like using text, and then have a tool draw them for me. When I do that, I "see" something in my mind which is an overview of the architecture, the structure, whatever, just not in something which looks like an actual drawing would. And I can use that to write the "code".
I know it's hard for those who can do such things using everything from xfig to CAD tools, to imagine that it's difficult, or basically impossible, for some others to do the same. And it's not about training, my mind just doesn't work that way. At work we've been using graphical tools for architecture etc. in various forms on and off during the decades I've worked there, and I've used them during those same decades - it doesn't work. I never manage to do that. I waste months. Instead I have sometimes quickly written code to take descriptive input and used that to create output - e.g. FrameMaker output, or some *TeX output, or Graphviz, and saved tons of time (and for a much better result). And the "code" can be version controlled and diffed and the like, exactly as some other comments say, and what the article mentioned.
I'll take a deeper look at what the article says about this.
The problem is the physical place the boxes are arranged matters. It is easy to draw a box and all the relations, it is hard to make the drawing useful.
I once did an automatic creation (dot) of my system - my monitor turned entirely black. I was finally able to see things when I zoomed in to the level that there were 10 boxes on my screen - but the boxes were not related to each other in any meaningful way as the system doesn't have any way to capture box a and c are part of the same subsystem, while box b is part of a different one.
I stopped doing code blue prints. They are either documentation only or you should look at code. There is however a area (think systems in a network) where typical IT Management / Cloud Management / etc fails. Here documenting a blueprint model helps with analysis (e.g. checking against reality)
I'd love to have a middle ground; I'd like to provide a diagram generator with a layout template and layouting hints, then have a tool generate a diagram conforming to that layout. I feel like that would be the best of both worlds. I could emphasize boundaries and structures visually, but I wouldn't have to keep everything updated by hand (as long as things don't drift too far).
I’m a big fan of diagrams as code but only when I’m doing them usually.
Mainly because I usually start out with an idea of what I want then try to recreate it. Usually that means I’ve had to read the entirety of the tool’s documentation end to end, and often I’m still bummed because the tool can’t recreate what I see in my head. But whatever, I’ll compromise.
But a lot of people go the other way. They make the diagram out of what they know how to use, and so generally their diagrams-as-code diagrams lack the detail you’d find if they had created it with a WYSIWYG tool.
But I hate WYSIWYG tools. Editing and versioning them is challenging.
I like WYSIWYG tools for a static system. However since I'm documenting a dynamic system that is changing all the time the tool needs to reflect the actual state of the system as it is now, not how is was 2 weeks ago.
20+ years ago I worked with a UML code generation system, so our diagrams reflected reality: you couldn't change the code layout except by using the WSIWYG tool. As such we always had correct up to date diagrams. It was great, every Monday the first thing I did was print the current diagram out and pasted it to my wall, then the rest of the week I'd refer to that all the time, but by Friday there were noticeable differences. Unfortunately such tools never caught on - in part because they have other limitations - but the diagrams were something I still miss.
I think that diagrams as code become useful when all the stakeholders (engineers, coders, devops etc) are involved in building it together. It'll eliminate spaghetti code and ultimately hold information on important key decisions made by different builders. It'll be a type of dev tool that helps churn out diagrams (code visualization, code maps) where different levels of builders understand it and it holds all the information on the whys of the software.
> I'm very skeptical of "diagrams as code" because it seems like the goal is to minimize effort, not to produce a useful diagram.
It is, and this is a valid goal. The ideal you're chasing doesn't happen in most projects: minimising efforts means those projects are much more likely to have an up-to-date diagram of some description.
I suppose it's not the same as "architecture" but since we set up our data pipelines in Dagster and the diagrams became something that the code generates it is MUCH easier to onboard people and explain how everything relates. We had manually maintained ERD's before but they were never as good or up to date.
I've often found that diagrams as code is fine for simple things, but once the complexities start adding up, it becomes as much work maintaining the diagrams as it is to main the actual codebase. I honestly think there is little difference in effort required to maintain a diagram in something like draw.io over PlanetUML or ilograph. Time is just spent in different places
Automatically laying out diagrams in a away that makes contextual sense is one of those problems that seems easy, but is actually really hard. If it was easy, everyone would have used dot files and graphviz to generate their diagrams since the 90s
Disclosure: I'm the CTO at hava.io, where we automate cloud environment diagrams, so I'm biased towards automation
This is a problem with the languages, not a fundamental flaw. Well designed GUI can beat poorly designed language, but manipulating text has a much higher ceiling than drag and drop, in terms of speed and comfort/familiarity. Every programmer has their own ecosystem for manipulating text. I can grep, version control, diff, jump with Vim key bindings, search & replace, etc.
The layout engines are very hard. We've been making one [0] for over 2 years now. At first it seemed dubious whether it was possible to beat aesthetics of Graphviz, but we've been designing it to emulate how diagrams might look on a whiteboard drawn by humans. That's a very different heuristic than the theoretical hierarchical cross-minimizations that previous algorithms strive for, and it's yielded good results for a subset of diagrams. With further spot-assist of AI, this will only get better.
[0] not linked to not detract with self-promotion. you can find in my profile if you want
Thank you for mentioning the aesthetics in graphviz. It's not in any sense optimal; we chose a collection of heuristics meant to get somewhere close to diagrams made by hand (with tools). Some areas can clearly be improved. Even the initial ranking and cycle breaking is not always quite right. Possibly some of the middle stages need to be more aware of groups of nodes. How to draw sets of natural looking curves around obstacles in diagrams still seems to be an open problem, do we even know what to optimize? It's natural to ask if machine learning algorithms will get there first.
I think you might've misunderstood. The text generates a visual diagram. Like HTML generates a website. You're not showing customers the text, you show them the diagram. You don't show customers HTML, you show them the site.
Really? A good example would be a chess board individual moves are easy to read in code (chess notation) a whole board state in the mid game not so much…
Depending on your chess engine (e.g. a physical board) a player could reasonably move many times without stopping to update the diagram. Maybe I forgot. Maybe I was in a hurry due to schedule problems. Maybe the diagram editor was offline for maintenance but the chess engine was still open so we kept on playing.
This might soon prove to be A Problem for folks who reasonably yet erroneously expected that each responsible player would of course update the diagram immediately after each move.
A chess game is over in at most about 60 moves. Sure the game might last for several hundred moves, but by move 60 only a few pieces are left and it is obvious [to experts] what is going to happen. Even in unlimited time controls, the actual time spent one all moves (as opposed to sleeping or doing some non-game activity while waiting for your opponent to move) isn't very long.
By contrast code lives for many decades. While it isn't all modified every day, it is changed often enough.
The industry spent a non-trivial time trying to maintain diagramming back in the waterfall days under UML and we really struggled to find a decisive solution.
As other posters have mentioned there are serious issues with having auto-generated and authoritative architecture diagrams. The biggest problems include maintenance burden (did you upgrade the diagrams?) and automating layout.
Personally I find the least ugly solution is to just draw some low-effort arrows and boxes when you need them and (for the most part) discard the diagram once you're done.
Yes! I use https://excalidraw.com/ for this. Its free and open source, is super easy to use, runs locally, looks nice without folks getting the impression it's a source of truth
I'm partial to yEd! as it is built on a graph model and has good automated layout options. Unfortunately not open source, but free to use for most applications.
100% agreed. 90% of computer science/engineering related topics can be explained using annotated boxes and arrows. The thing is you have to have someone to explain them in english cause theyre as good as meaningless without context
With the nasty detail, that this is the issue that you now need on 2-3 levels someone having a good/perfect understanding of design. And having that after 5 years of maintenance is a challenge. Yes, there are also other problems then but just draw ad-hoc on demand (as much as I love it) is very dangerous.
I think simpler, manual solutions are underexplored.
The prevailing assumption is that you either do the layouting by hand (see: almost all diagramming tools with a GUI), let the computer do it for you as a starting point for manual layouting (see: aforementioned GUI tools that have "auto-layout" feature), or you don't do it at all, and let the algorithms handle it (Graphviz, PlantUML and other text-to-diagram tools). What I haven't seen anyone try is allowing manual hints and overrides in otherwise auto-layouted text-to-diagram context.
I'm pretty sure I discussed one proposal more thoroughly on HN, but I can't seem to find any of my comments on it other than this: https://news.ycombinator.com/item?id=19406739. To save you a click, here's the relevant bit:
grid
Comp1 Comp2 Comp3
Comp4
Comp5 Comp6
endgrid
Imagine being able to write something like this in PlantUML, as a part of your normal diagram code. This is to be read as 2D arrangement, and would tell the layout engine how to place those particular elements relative to each other. The layout engine is then free to do whatever it normally does, but it must preserve the arrangement and alignment specified above.
Such a feature would solve more than half of the problems I have with automatic layouts. Additionally, pinning major elements like these would stabilize the diagram, avoiding the all too common situation when a slight modification to the current diagram (e.g adding or removing a single connection or node) flips the entire picture around.
I can think of other layouting hints, with varying levels of precision. They all stem from how I'd think about the diagram if I was doing it by hand (or in a GUI diagramming tool). These things go left-to-right in order; those things go to upper right corner, etc.
I didn't imply an ASCII mockup by my example. That grid is a way to declare, in form of self-depicting text, where the major components of the diagram go relative to each other. Imagine that every one of the components is a group, and each group contains half a dozen nodes, just as many arrows, and some may even have their own hierarchy.
The point is to pin major high-level parts of a complex diagram, so that as you continue to add, remove or modify the details, the rendered diagram doesn't look completely different every time you change something. This addresses my major issue with PlantUML, in that with any nontrivial diagram, even the tiniest change - such as adding or removing a link, or reordering neighboring nodes, can cause the diagram itself to completely flip, or spaghettify itself.
Note in particular that there is more than one view. If I'm looking at a subsystem I want the subsystems it depends on close. However in a larger view some of the subsystems it depends on will be spread far apart.
I agree very strongly with this, but I build tools in this space, so I'm obviously biased.
IMO, Architecture Diagrams should be code, but there's additional value in describing those diagrams in a way that lets us use metadata to interact with the systems they're describing.
ie: OpenAPI describes an API, and lets me interact with it - it's limited in that it doesn't descirbe how two independent APIs (eg., Microservices) are related. I also believe that OpenAPI has a very poor signal-to-noise ratio, meaning it's hard to read & grok.
I'm one of the creators of Taxi (https://taxilang.org), which provides a language for modelling systems and data.
We also build Voyager (https://voyager.vyne.co) which visualises those models into pretty diagrams.
We also build Vyne (https://vyne.co), which lets you use those some models to run queries against those systems, and handles all the integration for you.
If you're interested in anything in this space, hit me up.
I once made the mistake of doing a set of rather detailed integration diagrams for an airline I was consulting at.
This diagram, which was intended to be a rough snapshot of how the systems interacted, instead became the single point of reference for how everything in the company worked. It was used to justify investment, knock back projects, one PM even tried to use it to dragoon AD into a PCI Compliance project due to a couple of lines on the aforementioned diagram (like this system has cards, line goes to Exchange as it alerts via email and AD is connected to Exchange. AD is now on the PCI hook).
It was the first thing I did there, leaving 4 years later. They were still in wide use 3 years after I left and hadn't being updated since they were drawn, not to mention they were flat out wrong in a number of significant ways to start with (either simplified for $REASONS or just didn't find out the real story until a year or 2 later).
These diagrams are probably the most impactful thing I've ever done in my career given how long they remained in daily use and the effort to draw them (which was probably a week or two? Took a long time to get the data but the drawing bit was pretty quick).
Would code have made them more accurate or likely to be updated? I doubt it.
Would it have made them more useful? I don't think so, the key to them being well understood and useful was mostly in the layout, something that is difficult to control in any generated diagram.
I did actually have a go at using structurizr when I was there but it was too much work when compared to knocking out a quick draw.io.
Personally these days I make great use of PlantUML / WebSequence diagrams and am very interested in the C4 / mermaid stuff, but I would likely take the approach of the Engineering Manager - please produce diagrams and make them:
1 - accurate and
2 - useful for whatever story you are trying to tell.
Do it in code if you can make it work, but as someone in the thread said - this is an old problem and if it was easy it would have being solved in the 90s.
That said I've always thought a dependency system would be a good way to express the relationships between systems - you could almost model systems using something like maven poms - but again, it's always too hard to get the scope and resulting view right.
Half joking but I wonder if it were drawn in the sketch style (hand drawn look) and comic sans, people would have seen it as a draft rather than a reference paper.
It wasn't a draft, it was reviewed, approved agreed upon etc, but the initial reason to do it was supporting a review of how things were integrated. Basically because it was useful and there wasn't anything else like it, they turned into the "how everything works" view.
I agree. The take-away from your story: Complex diagrams should be layouted carefully by hand, code for diagrams is good for very simply diagrams or structured with litte structure of few levels (e.g. max 3 node diagrams; or 2 levels; or four layout quadrants).
The C4 model (https://c4model.com/) is great for architecture diagrams. You can use different tools to generate them. Here are the ones I've been using:
It's okay, for software architecture. Really you should just have lots of different types of diagrams until you have enough to understand the system. There's no single type or form that will suffice.
Can definitely recommend at least trying structurizr. I'd recommend starting with structurizr-lite, which runs locally on docker and version controlling your work as you go.
Just starting to use it myself to document an existing system that few people understand and there is not a lot of existing reliable knowledge of. Doing this sort of task has so many benefits long term but can be painful in terms of getting started.
The combination of C4 approach, structurizr for diagrams, embedded markdown for detailed notes and version control is feeling like a great combination.
Having it version controlled helps a lot with collaboration and communication. I'm using PRs in order to get insights and corrections from others without the need for constant meetings/discussions.
This is perhaps a tangent, but I've used https://asciiflow.com/#/ a few times now to insert diagrams into my source code as comments. I understand people might have negative opinions on the efficacy of comments that this would only exacerbate, but nevertheless I've appreciated what AsciiFlow gave me.
I’ve been using MonoDraw https://monodraw.helftone.com/ for this exact sort of stuff for years, was one of the main reasons I bought the program actually. A good diagram in a block comment right above or below done complicated code is a ready powerful way to make sure you’re going to be able to maintain that code in the future.
I find flowchart style diagrams for finite state machines and UML(ish) sequence diagrams for RPC code are both extremely handy places to add a diagram.
What is great is that this becomes code. The next person modifying this workflow will be blamed for not updating the diagram. Now you always have up to date architecture (until someone removes the comments lol)
I am a solution architect who uses Lucidchart as well as automated arch docs like dependency cruiser and plantuml.
They both have value, and I will never give up custom diagramming.
It comes down to expression.
Not everything in a diagram is purely informational, sometimes you need to represent concepts and relationships in ways that are very frustrating to encode in code
Yes this is something the article doesn't really address. Architecture diagrams are often not produced for technical people, or need to contextualise one domain for another.
Solution architecture is in one sense an art of communication; explaining systems and components for different audiences and contexts as clearly and efficiently as possible.
I find an automated display is fairly close to what you have through CMDB visualisation, just for engineers instead. They can be quite useful, but only for particular audiences.
This is exactly it. There isn't one authoritative way to project any process into a series of lines that is easily readable and conveys all ideas or dimensions. If there were, we wouldn't need the code in the first place. You'd just "draw the lines".
As for Haskell... while I think architecture diagrams should be written in code, they shouldn't be written in a programming language. Programming languages are for writing, well, programs. Programs execute, accept input, have state, and all manner of other things that just don't apply to diagrams. Diagramming in a programming language is just weird.
I didn't mention it, but I do write architecture diagrams which have input.
data Version = Current | Future
generate :: Version -> Diagram
Implementation uses a few if/else expressions. Really simple.
The final points of the post was that we should be able to generate architecture diagrams from other code. Parsing a service descriptor, generating them from tests, etc. You DO need a programming language.
I understand the goal of making the visualizations dynamic, but even the author isn’t directly tying the code that produced the visualization to the code it represents. There’s a reason:
Communication of an architecture is partly an artistic exercise. The job is to communicate the meaningful parts for the audience and context, and simplify or gloss over entirely the unnecessary details.
Sure you could invest in code generation for said art, but it’s still distinct from the code it represents. Whether you should make that investment in optimization is uniquely a value prop of how important it is that THAT piece of art is always up-to-date + how hard it is to manually update the visualizations in a non-code manner.
No one likes to maintain diagrams.
We should turn this around somehow: the code should "be" architecture diagrams.
i.e. existing code should be analyzed to deduct the desired architecture diagram.
It's not like the dependencies aren't there. They just aren't made obvious.
Which maybe they should!
As an example: when I see an instance of a http-server being created with a port number and routes registered, I already know at least two boxes of my diagram :)
If I analyze package/namespaces dependencies, I have a bunch more boxes.
If I analyze this across repos with slight hints (i.e. repo A is front-end, talking to repo B, backend), I have many more boxes errr out of the box.
One could argue that if we can't deduct our architecture from looking at the code and configuration, something is smelling badly.
I'd push this idea further: this shouldn't be just architecture deduction to make diagramming be derived from code. This should be concept deduction to make programming itself work on higher conceptual level (which may involve automatically creating diagrams on the fly, too).
For example, imagine I have a bunch of classes that I know implement a state machine. I should be able to annotate them as such in code, and gain the ability to do things like:
- Render a state machine diagram from them
- View them in a UI (could be graphical, could be just a different textual representation) dedicated for state machines - one that emphasizes states, transitions, and associated conditions and side effects, while diminishing or hiding all other aspects.
- Edit them in that same UI. In there, "add state" or "rename state" or "add transition (with conditions)" are the atomic editing actions, matching the way I'm currently thinking about these classes.
Elsewhere, I may have another state machine, where states are just functions tail-calling each other, or actors sending each other blocking messages (both are a common pattern in Erlang). I should be able to use the same annotations on such code too, and get the same capabilities described above.
Furthermore, some of the classes in the class-based state machine example may be parts of other, lower or higher-level concepts. Or I might encounter pieces of the state machine while working on a cross-cutting concern like error propagation. I should be able to interact with those pieces through UIs dedicated to other concepts or concerns I'm focusing on.
Trying to force the base, raw plaintext form of the code to represent all relevant concepts, all the time, in an explicit and readable way, is a fool's errand (and a source of endless, unresolvable debates about "clean code" and software architecture). Instead, I believe programming languages should be optimized to allow us to write code using a bag of higher-level tools, each dedicated to a concept that's closer to how we think about our programs. We should rarely, if ever, touch the raw source form - and we definitely shouldn't expect the raw form to clearly represent every possible role it plays in the whole program.
There are tools that can analyze the code automatically. They are worthless because they have no way to capture what grouping is important. There are groups of boxes in my system that need to be together because they are a subsystem. Note that when I ask a different question I will want a different grouping of boxes.
Sort of related but an interesting idea is take it one step further with the Feature Oriented Active Modeler (FOAM) [1,2] paradigm and use code to model your whole system, which generates diagrams model, and runnable code in whatever language needed. The project is still young and it may not be practical today with the available tooling but it seems like a cool idea and project. It is influenced by the unix principle of “coding the perimeter not the area” which is essentially factoring your dev tasks into building NxM capabilities, but instead of building NxM things individually build N+M tools that can be composed into NxM capabilities [2].
So with FOAM the idea is if we want to maintain a model of our software, and build it as well, what if we can use one composable tool to generate both, rather than model everything and code it separately.
I agree with this in principle and use mermaid quite a bit. I like that code can be versioned clearly to track changes and this lowers confusion over when the diagram changed, who changed it, who approved it, and what changed.
However, I have a hard time with “ugly layouts” that really do distract any attempt to describe the architecture. This comes up a lot with flow charts and sequence diagrams where non-dev stakeholders want to read and understand. Frequently we end up redoing them in draw.io or something that allows a manual layout that looks better.
This is a minor nit, but is a big barrier to architecture as code as once the diagrams get manual, they get out of sync.
I use TLA+. Almost every system has some sort of safety property that needs to be guaranteed (bad things must never happen). A good many have liveness properties (something must eventually happen). Diagrams are well and good for documentation but tell you nothing about the specifications of the system.
I tried UML once but found it lacking.
When I’m writing documentation I like to use diagrams. Mermaid has served me well. It’s integrated into GitHub these days which is convenient. I’ve also used ditaa and graphviz to good effect. With org-mode and org-babel it’s quite easy to build executable documentation: take the query from a database to build a rough ER diagram with graphviz, a shell command on a jump box to get the data-plane hosts to build into a network diagram, etc.
Another interesting tool: https://github.com/moosetechnology/Moose I haven’t spent that much time with it but I learned enough to generate a dependency graph for a NodeJS project that was useful for planning refactoring work.
Update: Alloy is another nice modelling system. It has a built in visualization system as well. And the newest release, Alloy 6, has features to make liveness checking a whole lot easier and more powerful. The book, Software Abstractions, is also indispensable for general program design advice.
The more I think about it the more it seems like the code itself should be the diagram. Not the code you write FOR the diagram, but the code for the feature, product, team you work on.
Feature2: Diagram {
// list feature 2 dependencies
}
Then some compilation system should be able to build a not so noisy diagram from this. Key being not so noisy (I don’t care about the 100 million sub classes here).
C4 came up with icepanel earlier. I will give one take - C4 is a nice abstraction that is very useful for architects, who spend a bulk of their day presenting things at different levels of the company.
When it comes to the engineers deploying and checking things into git, it is quite a bit of cognitive overhead. Imagine taking a C4 training and then referencing that knowledge every 4-6 months when you actually need to model something new, and having to choose layers to model at. Engineers are the ones expected to maintain system documentation, and usually they know exactly what the network and sequence diagrams for a system should look like. Anything standing in their way of that goal gets replaced with draw.io or even ASCII art editors. In my anecdotal experience building these systems - engineers want a dead simple graph editor that is canonical enough for their company (think shared templates); or they just haven’t fumbled enough with UML-metalanguages like this one enough to realize what they want.
That said, checking in models and having them be in a diffable format is helpful to them as well. There is no reason a visual editor can’t do this.
Man, I just was browsing around on Mastodon a couple weeks ago and found an architect that said he was using a tool for this sort of thing, and it was one I never heard of before and it looked like it was good. And now I can't find it again. All I remember is that it was text files that had a certain file extension of more than three letters.
At any rate, architecture diagrams are drawn in a lot of different contexts. I find myself reaching for these tools:
If I'm screen-sharing and want to draw something really quickly in a collaborative sense with others, I use Flying Logic. You can basically draw this as fast as you talk to each other. You could substitute that for any other drawing app that will automatically lay out as you draw. It basically runs a Sugiyama-type layered algorithm in a loop, and it supports groups and nesting. Sometimes I'll export these drawings into wikis, but it's more for a general sense - it's really just labeled boxes and arrows.
If I want to quickly put together something more detailed that will again be used only for reference, and not as a living document, I'll sketch something up in Excalidraw (free version) and export it. It still find it a little too fiddly for drawing live with an audience, but it has more flexibility than Flying Logic since you can also write text outside of the boxes and arrows.
But for stuff that needs to be more official and/or be edited, I'm all-in on the diagrams-as-text thing. I just haven't find the right tool yet. I feel like mermaid and plantuml are a venn diagram and haven't really committed to either. There's also that crazy python one that has all the AWS-branded diagram elements but it's too finicky to pull up quickly.
I have been using Excalidraw for both use cases 1 and 2 with (subjectively) great results. A few points to use it for live sketching:
* Having a consistent whiteboard orientation. In my area of work I deal with data pipelines. Sources are always on the left, consumers - always to the right
* Only one or two types shapes should be used - to me, rectangle covers pretty much anything. A blackbox system? It's a square. Some logical domain? Rectangle. A specific interface? Maybe use a diamond or a circle. Excalidraw uses numbers for shortcuts, so those are always at the fingertips.
* Colors should be kept to a minimum. 3-4 is plenty. Select a shape, "s" for the line color/"g" for fill color.
* At the end of the day all systems exist to help humans. A human figure(stick one, from Excalidraw most downloaded libraries) should pretty much always be on the diagram.
Architecture is, literally, the blueprint that was used to build the building. But the blueprint is not the building. The building deviates from the blueprint, either by accident or by necessity.
Likewise, code is just the blueprint of the system. It is not the system. The system operates in its own unique fashion, and is often changing, even when the code isn't.
Therefore, things like Distributed Tracing and other Observability/Telemetry techniques can tell you a great deal more about what the system actually looks like as it exists in the world, not just on paper. This real world look at the system will help you reason about how it actually works.
But architectural diagrams are still necessary to plan work you haven't done yet. I really love the idea of asking everyone to draw their own diagram, because all those perspectives are valid, and you'll always find things that other people forgot about. Doesn't matter whether you make this drawing out of code or on a napkin. Do whatever best captures the work needed and gets you to the building phase with everything you need.
In actual building construction they have as-built plans, which are the blueprints made after the fact which should correspond to how the building was actually built.
I think it would be a good engineering practice to have the same in SW.
One reason I prefer diagrams as "code" (by which I mean Mermaid or similar) is that they can be checked into version control, and changes can be reviewed over time. Unfortunately the diffs become less meaningful after significant changes.
Hmm.... outputting an image to highlight changes might be fun to hack together. One day :)
architecture diagrams change very infrequently, and are most useful in a given context (ie tailored to a particular viewer or team). writing actual code to describe them feels like a solution in search of a problem.
Agree, but I get the temptation if you want to be able to rapidly evolve your architecture early on to discover what works best.
Removing that extra bit of documentation related friction and maintenance that keeps an ill suited architecture around longer than it should or drifting from reality would be nice. I have a hard time seeing how the complexity or quirks of a diagramming tool that could also stay tailored to certain views wouldn’t become more of maintenance headache than being disciplined about manual diagrams.
Atlassian Marketplace's architecture diagrams change constantly. Altassian replaces a core system, we have to integrate with a new one, we rewrite or replace a system.
Did you read the part about generating diagrams from different things, e.g. service descriptors, service proxies, tests?
Something I love about diagramming with a markup language is that you get to wipe your hands clean of tedious alignment and visual perfection. If you give me the ability to align and resize and do all kinds of cosmetic stuff to my diagrams, I will.
I have no use for architecture diagrams. Every diagram I've seen, ever, had the problem that it lacked sufficient detail to be of any use other than saying to non technical people "we have stuff, here's a pretty slide for you to prove that". That's literally the only reason I get asked to produce diagrams.
A diagram with sufficient detail to be actually of use to people like me would not fit on a slide. And it wouldn't be that useful. Because you'd have to study it to understand how it all fits together. You might as well inspect the real code base and learn way more in about the same time frame. In fact, that's what I do. In the rare case that there are diagrams at all they are extremely unlikely to be of any use whatsoever.
And if you are thinking I know nothing about the subject and must obviously be an idiot. I actually did my Ph. D. 20 years ago in this field. I read a lot of books, articles, etc. on this topic. I deeply immersed myself in this stuff.
So, my well informed opinion is that software architecture drawings serve no purpose whatsoever. Complete waste of time. Nice talking point on a whiteboard during a meeting. Wipe the board when the meeting ends.
Big OSS projects don't have diagrams. Even OSS projects that implement architecture drawing tools. I find that highly ironic. Tool makers that create UML drawing tools don't eat their own dog food. That should tell you all you need to know about such tools.
Ridiculous. Diagrams are extremely useful for communicating the essential information efficiently. Not everyone needs to spend time going through every line of source code to understand design concepts. I’m really struggling to see how this could possibly be argued otherwise.
As someone who are involved half a dozen projects, high level architecture diagrams are extremely useful. This is especially true when meeting with stakeholders in other teams and explaining what we need to do to accommodate their requests, and also when onboarding new resources. The way I use diagrams, they should not be code as that is just added complexity without any benefit
I don't know where you get this from, but in my experience, high-level architecture diagrams are excellent at ramping up someone new on a team. They help immensely in giving them a map to what the code represents, and they are likely to refer back to the diagram often when crossing module boundaries.
The whole value of diagrams is that they don't have as much detail as the code. They can thus focus on the intent and on the bigger picture of how things are organized, instead of getting trapped in the weeds of machine details.
OSS projects are also not exactly famous for their well-considered documentation and on-boarding tools. It would be like concluding QA is useless because big OSS projects usually lack QA engineers and test plans.
I have a couple of decades of experience with real life projects. None of which featured diagrams in the last 20 or so. From extensive interactions with colleagues and friends I know for a fact that this is the case across the board. I have no counter examples. Maybe I live in a weird bubble where people just don't do these things. You know, companies like Nokia, Here Maps, and a few others. Most of the startups in Berlin, or any of the various companies I've visited in the US over my career. Just not a thing anymore.
It was once of course, and unlike most people in this thread I actually did some case studies at companies that proudly showed me their work in the form of lengthy architecture design documents featuring lots of high level and perfectly useless diagrams. That's the reason people don't do this anymore. It's a lot of effort and you don't get a whole lot in return. Doing case studies like this is hard and thankless work BTW.
I spend way too much time looking at architecture documents and then learned more about the documented systems by actually talking to the persons that wrote those documents in about 30 minutes. These documents were basically stating the bleedingly obvious and omitting everything else. Anything actually complex or complicated was left out because it would quickly become unwieldy. A person can tell me that there is a database and it has 20 tables. Or they can quickly tell me what their domain is about and I can infer that they probably have database with things called users, addresses, etc. You don't need a diagram for that. And things like model classes are usually pretty straightforward to read. And unlike the diagram they are actually complete, not out of date, and not overly simplified.
Diagram tools are still sold of course. But it's a niche market. The exclusive customers for these tools tend to be mid to large sized companies where this is a necessary evil to keep their customers or managers happy. It's a form of ass coverage. A chore where somebody has to sit down and do that. No OSS project I know of, small or large, includes diagrams in their documentation. Not a thing. Never has been. And yes, I did some case studies of those as well back in the day. Much easier than corporate case studies. If you don't believe me, try finding some diagrams on Github. I'm sure you might find some but I doubt you'll be very impressed.
I've seen plenty of engineers ask for diagrams but always in this form "someone (not me, obviously) should do a diagram to make my life easier". It's write only documentation. Outdated almost immediately, and typically rarely looked at. Skip it if you can, minimize your time spent on it if you can't. You have better things to do. Software architect is no longer job title that is common or fasionable.
Empirical research in the software world is like architecture diagrams. Lots of people asking for it, not a whole lot of people doing empirical research. And lots of people confusing marketing material with proper research (e.g. most articles published on Agile methodology). And even fewer researchers that even do a half decent job when they do it. It's hard and typically not covered in computer science degrees. So there are a lot of not so skilled, amateur empirical researchers doing a not so great job of doing empirical research. And of course companies don't actually like their dirty laundry being published.
I know this because I was such an amateur researcher and I read a lot of papers back in the day. Like thousands. Part of the job. Most of those papers were entirely unremarkable. The better ones exceedingly dull reading material with inevitably very unremarkable/predictable conclusions backed up by really impressive research methodology, statistics, etc.
The reason I left academia was that I realized that I was not a great empirical researcher, was probably never going to become one, and did not know a whole lot about software engineering and architecture either because I had never worked outside of a university. That's 2 decades ago.
Cool anecdote. Mine is that they have been useful in nearly every systems design I’ve been a part of early on. You don’t think visually/spatially, some people do.
Putting boxes with lines clearly groups responsibilities and defines which pieces are related.
It’s the same reason org charts exist. It doesn’t tell you how a company functions but it very quickly tells you who answers to who.
Some diagrams work better as posters or even whole walls, so that it's easier for a human to move across the project and see everything on one huge map that works at an intuitive zoom level.
I like the idea of "Contract-driven development", which should in principle help with this kind of thing. Services expose an API schema (say, OpenAPI), and other services can register usages of that contract.
This framework is usually intended to capture low-level collaboration between teams; if you need to make breaking changes to an API, you can see who's depending on it. But you can also in principle build a graph of interactions based on who is consuming contracts.
Another direction you can take this is to analyze traces from your production system, to determine who _actually_ calls who, instead of who claims to call who. I've not seen tools that offer this, though I know many of the big guys are doing this kind of analysis.
As far as the article goes -- I think all docs should be written in Markdown and checked in along-side the service/code that's being documented.
I've done diagrams in MermaidJS, but you can use fancier code tools and a Make script if you prefer. You can use something like Gitlab Pages to render your docs really easily. It's hard work maintaining the discipline to keep docs up to date, but at least keeping the docs next to your code you make it _possible_ to have a chain of PRs updating the documents at the same time, and a given release tag showing the docs changes associated with that release's code changes.
It should be possible to change architecture from changing a text file. Which is also a diagram.
I am designing a state machine formulation for complicated systems and a multiplexing format for messaging. In theory the state machine formulation can be rendered to a diagram.
This state machine is similar to Prolog and BNF parser format. It defines a progression of states for async/await. I think the format would be useful for microservices and multithreaded software.
> Ideally, we’d have dozens of architecture diagrams - from various views, from various proposals, from various teams. We don’t see this very much and I think part of the problem is that architecture diagrams can be costly.
I dont think cost is part of the problem at all. I just dont think people want 24 different diagrams depicting the same thing. That seems insane - I cant believe the author doesnt see a problem with this.
1. Oh god yes. Anything to stop management by powerpoint.
2. But a piece of code written seperate and distinct from the actual code is just as disassociated from the real world.
3. So build the diagram from the actual code (parse the code in the repos, monitor real time network calls, put the data in the config files. whatever)
4. please for the love of god stop using low code solutions - they just make another huge hurdle to being able to introspect.
the author seems to miss the _reason_ for the discrepancies in diagrams, its not the tool, persay, its the lack of knowledge. In a big system its not really that plausible to know the whole system.
The author _almost_ grasps this, but instead of thinking why teams might not know the "truth" of a system, they dive straight into code. sure great, having UML is great, but I can guarantee that nobody apart from the author is going to update it, because the barrier to entry is a fucktonne higher than using some web based visio clone.
If you want an accurate diagram, that self updates, then you need a tool that pulls the relationships out and generates it. However this will be messy, difficult to understand and possibly fragile. Worse still, unless you are lucky, it will be a custom tool.
However, given that most people recognise that you need to monitor your service in depth, its not actually that hard to generate a dependency map from your monitoring system, if you've set it up properly.
There's an important distinction between 2 categories in architecture diagrams:
1. Free-form. You have an image of what it should look like. It's precise. An algorithm won't be able to get it right.
2. Structured. You just want to represent the relationships in a clean way, and there's a hundred ways to do that acceptably.
Code/text can never replace the former, and free-form ones are always going to have its place. It's too black & white to say all diagrams should be code or not code.
I'm one the authors of a new text-to-diagram tool, and I wouldn't recommend it for all use cases. Example here of free-form vs structured: https://d2lang.com/tour/future#layouts
I had been super excited by the work on d2 (and Tala), the new language for diagrams with automated layout. I'm happy to pay a reasonable price... but their prices are currently five times higher than the cost of a Visio subscription...
A pity, in my month long trial period I used it extensively, and loved it. Crawling back to Plant UML has been all the more painful for it.
I use (and like) D2, although it’s early days and still has a few rough edges. Prefer the syntax versus Mermaid.
It’s open source, though, isn’t it? You can just install locally with brew or whatever, plus the vscode extension and you’re off to the races. You don’t then get the fancy proprietary GUI, though - that’s what you’re referring to?
Thanks! TIL. Will check it out. Dagre seems to have been okay for me, perhaps I don’t know what I’m missing.
UPDATE: Just tried out TALA. I'm in the same boat, interested only in the CLI. It definitely makes everything I've thrown at it look nicer. Would you be willing to expand a little on what you like about it versus Dagre, having had some experience with it?
I totally agree the distinction exists, just wanted to say https://flowchart.fun/ is nice because you can run layout algorithms and then tweak to your liking w/in the same editor
I've been looking at this recently - involved in domain driven design.
Finding the right balance is important. The diagram needs to be easy to make right, and ok to throw away.
The diagram has to actually reflect the code. Making the code top down should make the same diagram if you backwards engineered it.
I can see how keeping the diagram in the repo is good practice because the further documentation is from code - the less realistic it is.
I could really see a DIAGRAM.md - where your IDE would convert markdown into a UML diagram(ish). And plop that inside the top level of a software component.
> Architecture is the relationships between systems
I find that somewhat limited. A part of architecture “can be” the relationship between systems. As with anything expressing relationships, representing them using diagrams is helpful. Given the textual nature of our tools, storage and change systems, I like the idea that a diagram is based on code. However, it’s no panacea, as future maintainers still need to understand and learn the syntax and rules of that diagramming code. Can code and diagram changes be automated? I suggest no.
I prefer to think that software architecture is the set of decisions made about how to implement the functional and non-functional requirements of a project.
A tool as Archimate already provided options to represent different views on an architecture depending on your role. Archimate is maybe a bit dated and closely related to the TOGAF Enterprise Architecture framework, but it can be powerful.
Disagree 50%. Before you write any code (Corp World) you need a few diagrams detailing what and how you're going to build a thing. These lead to discussions and are refined/evolve into something you can start coding up.
There's a company that does this already! The visualization of code and diagrams helps different times of learners I think. Which also is beneficial for knowledge transfer since everyone learns different, some better from pictures vs some better from drilling down deeper. I also think you systems thinkers having a good architecture diagrams that can be visualized in different ways can lead to insights that otherwise are hidden. https://www.codesee.io/
I was going to mention that code visualization is increasingly becoming an important topic to new and expert engineers and coders. And I did come across CodeSee.io that looks to be leading the charge for that. Excited to see the developments in code visualization and the visuals themselves.
Coming from Atlassian Confluence, "very fiddly and even buggy" made me laugh. It's really hard to maintain a diagram in that suite.
Personally I prefer excalidraw, though the embedded scene can easily be not exported or stripped, or people just don't realise you can continue to edit it if you import the PNG.
Furthermore most documentation systems (ahem confluence) don't have a sane coding API to keep the file upto date.
I've never seen people get value out of these diagrams, except when someone creates a one-off diagram to explain a particular detail when whiteboarding.
There are tools like this to generate diagrams of the relationships between database tables. They all seem to come with a way to filter down the number of tables displayed. A full diagram of complex databases actually appears harder to understand than a text version.
Architecture documentation is not just consumed by programmers/coders. I can't imagine showing Haskell (or something similar) to non-technical leadership or during an M&A process.
Know your audience. Frankly I would loath trying to decipher code when getting a high-level view of the architecture of a system during onboarding.
Architecture-as-Code is source code. It can be compiled/rendered to other forms, like diagrams. (Ideally I'd like sonething like CSS to control styling the diagrams in so that you could adjust rendering, even selectively hiding pieces that aren’t interesting to a particular audience, without touching the logical description.)
In a perfect world, the architecture description would also be part of the “working” source code, interacting with more normal program code (and/or IAC) specifying the concrete components, and playing a concrete role in building and deploying systems, so that the work that goes into architecture specs isn’t duplicated and the arcuitecture description doesn’t get out of sync with reality.
I don't often show architecture diagrams to non technical people BUT I also definitely don't show most technical people this Haskell code. I also don't show them the PlantUML.
TFA isn't advocating consuming architecture diagrams as code, but creating them with code. Render them and you get back the same images as you had before.
he suggested generating plantuml diagrams from it, so you would use the image for onboarding. you'd only see the code if you were going to update the architecture
Oh are you intimately familiar with Atlassian's systems?
Marketplace is Atlassian Marketplace, a real website, REST API and bunch of frontend components. If it's not part of an architecture, what is it?
I did simplify Commerce, the system is Atlassian Commerce Cloud Platform. I apologise that I simplified the name for an example, which has confused you.
Has anyone tried to build complete company architecture in C4Model? We have an ambitious idea of documenting our current state of architecture using C4 and also have a process around it to keep it updated. Just wondering if any organization has tried this at company level and succeeded?
I know a number of organisations who have done/are doing this, and my key piece of advice is to look at modelling rather than diagramming. Note that I'm not necessarily suggesting a traditional UI-driven modelling tool here. My open source Structurizr DSL is a "models as code" tool that allows you to define a model+views, and have them rendered using a number of tools (e.g. Structurizr, PlantUML, Mermaid, D2, etc). I have some conference talks on YouTube that provide an overview if you want to learn more; e.g. https://www.youtube.com/watch?v=0-gVFWONnQw
If something can be done(created) with code it will end up done with code for the sake of dynamism, maintainability and ease of modification. WYSIWYG tools are great and powerful but they are to save the day not to endure. So IMHO in the end it will be always YES CODE.
FYI, tracing supports arbitrary spans at whatever level of granularity you want. However, out of the box auto-tracing is not going to do this, it depends on the language but usually the spans are at the RPC layer of abstraction, so any fine grained spans would be fully custom code.
We did this a while back for some critical functions in our rails monolith where we wanted to confirm that an expensive bit of code was behaving as expected. It’s not bad when the service is already set up with tracing libraries and the rest of the plumbing.
Why are we trying to hijack the word architect? If you tell someone youre an architect and then show them systems-architect diagrams im sure you are going to get some weird looks
yes, except i think for a vast vast majority of people the word architecture does not bring up thoughts of IT. the title of this post doesn't do a good job of that. whats wrong with 'IT systems diagrams should be code'
Another reason these diagrams should be expressed in some sort of code is LLM currently are not well versed in architecture because its missing from the training set.
if you take plantuml as an starting point (textual encoding of the various UML diagrams) you quickly realise that "architecture" is simply not a sufficiently well defined set of concepts to turn into "code".
it is rather a compilation of loosely connected heuristics that describe different aspects of architecture but not "the" architecture.
it might be possible, though, to achieve something interesting for a subset
KeenWrite[0], the FOSS Markdown editor I’ve been working on, includes the ability to render plain text diagrams via Kroki[1]†. See the screenshots[2] for examples. Here’s a sample Markdown document that was typeset[3] using ConTeXt[4] (and an early version of the Solare[5] theme).
One reason I developed KeenWrite was to use variables inside of plain text diagrams. In the genealogy diagram, when any character name (that’s within the diagram) is updated, the diagram regenerates automatically. (The variables are defined in an external YAML file, allowing for integration with build pipelines.)
Version 3.x containerizes the typesetting system, which greatly simplifies the installation instructions that allow typesetting Markdown into PDF files. It also opens the door to moving Kroki into the container so that diagram descriptions aren’t pushed over the Internet to be rendered.
Note that Mermaid diagrams generate non-conforming SVG[6], so they don’t render outside of web browsers. There is work being done to address[7] this problem.
> Maybe we should write architecture diagrams using code instead. With code, we can update architecture diagrams within a pull request, version them and quickly modify many of them at once.
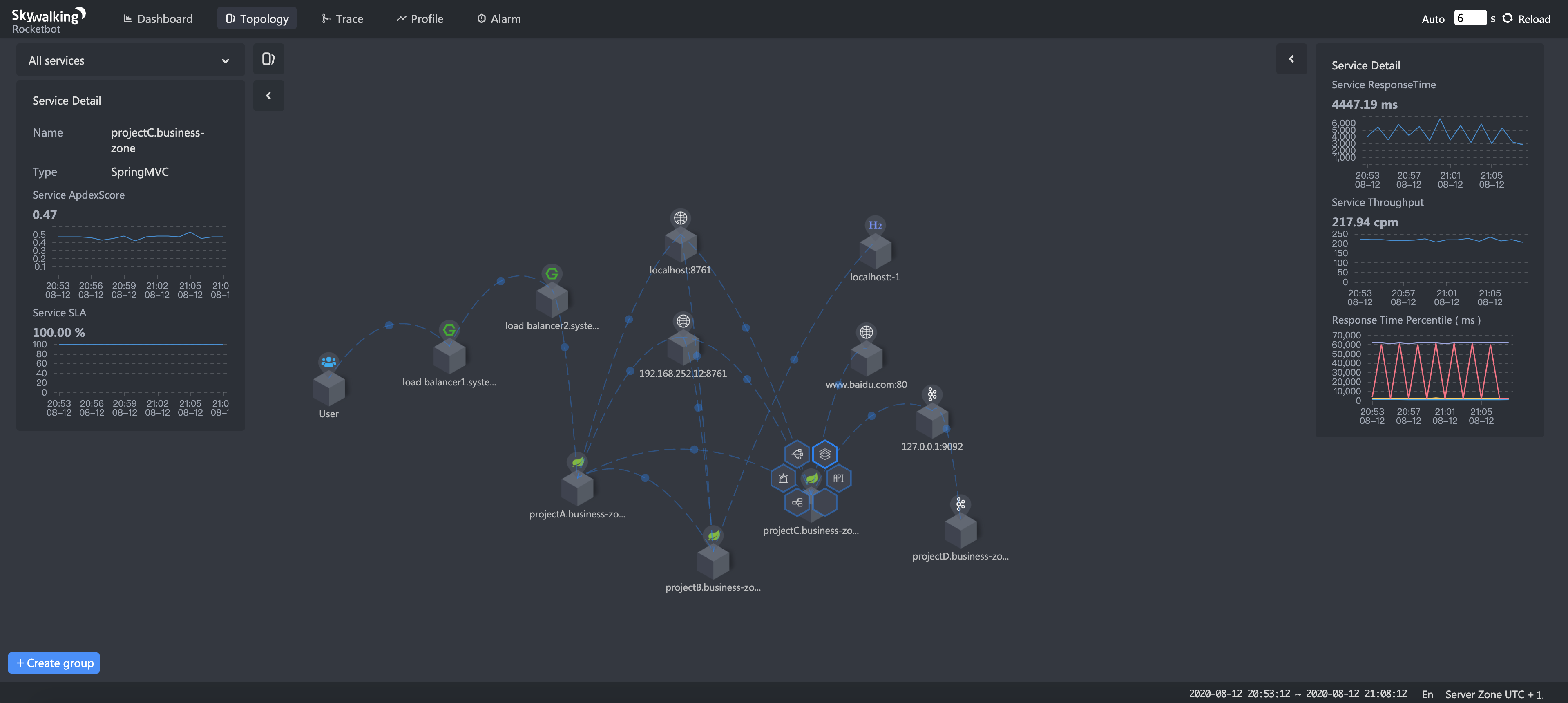
For some level of granularity, you can do even better - generate the architecture diagrams from what you actually have up and running, as long as your deployment units coincide with the components. I know that Apache Skywalking isn't the most popular APM solution out there, but they have something very much like that: https://skywalking.apache.org/blog/2020-08-11-observability-...
Better yet, these sorts of "live" diagrams also allow you to display statuses of all of the connections between the components, open related data, tracing information or even related logs, if you need to look at why a particular endpoint doesn't work as it should. It automatically updates based on how things are related and so you don't have the inevitable difference between how things are and how they should be, just because someone would have forgotten to manually change some diagram somewhere.
Of course, there are downsides to this - it won't be as pretty/presentable as something that someone could create in a design tool and there's not much "customization" to speak of, that'd let you focus on the different perspectives (as exemplified in the article). However, as long as you're actually in control of your services (e.g. can instrument them), tools and approaches like this seem like sane options regardless.
I'll go on a bit of a tangent here, but I'll say that diagrams are really powerful, yet people usually under-utilize them and see them as just documentation or something to tick a box. I'll use databases as an example for this, say, using tools like DbVisualizer to explore database schemas: https://www.dbvis.com/features/database-management/#explore-... While it is great, sadly, that's as far as things usually go.
- generate a diagram from your dev database, change it as needed
- visually validate that it looks okay (way easier to do than looking at a bunch of scripts, many are visual creatures)
- if okay, generate the SQL scripts (which you can also look over), and/or test them out against your instance
- if you have an automated DB migration tool, put the scripts in it
Of course, it isn't perfect and won't help you in complex cases, but for trivial stuff it's still excellent without pigeonholing you into something specific (it's still SQL at the end of the day). I think that visualizations are good in most cases, whether it's an ER diagram, an architecture diagram, or something like a DAG for your CI pipelines: https://docs.gitlab.com/ee/ci/directed_acyclic_graph/
So why couldn't we plan out our architectures in a similar way? Where's my AWS/GCP/Azure Studio 2030, where I can draw a bunch of boxes and click either "Generate infrastructure as code package" or "Deploy to AWS/GCP/Azure live", or open already generated/running deployments in the tool to edit them?
I'd suggest evaluating tools on an as-needed basis, instead of wholesale rejection. And I'd 100% agree that the article could've benefited from a "Why Haskell, specifically" section. But really, few things are unequivocally useless. (Or good, for that matter)
(I'd also suggest that you meant 'recoiled', not 'rebuked')
The article has nothing to do with Haskell, other than it's what I use. Why should I have to justify that when I want to talk about architecture diagrams?
Would the same expectation be in place of my examples were in JavaScript? I doubt it.
It's your article, you don't have to justify anything.
That said, it still would've been nice to hear if Haskell has bought you anything that other languages don't do.
Would I have asked the same question for a JS article? Maybe I wouldn't have asked - I'm a bit more familiar with JS than I'm with Haskell - but a "and here's why I picked those tools" section would still have been interesting. I like hearing how people think about solving problems.
The fate of writing in public: people will always ask for more info on the parts that they're interested in.
{kind=link}
Good diagrams, including architecture diagrams, require careful consideration: What does the reader need to get from this diagram? What should I include and what should I leave out? How do I organize items so that readers can understand the diagram quickly?