If that's really true, a 16 core AMD having a higher performance than a 18 core intel processor at twice the price, that's a fabulous news for all consumers. Hopefully that will stop both intel from setting absurd price for mid end processor and generally push the industry forward.
If anything the 3D chiplet tech will make their chips even more expensive/lower yield/more likely to overheat.
HBM memory for instance is still quite expensive, and even 3D NAND was more expensive initially. Now it's harder to tell because the whole market crashed and they reached a limit for density anyway.
I agree with you, I don't see how Intel will cool a 3D chip unless the bottom package is extremely simple. Even then, it looks like that design would be more expensive than the multilayer mini-board + ball grid array AMD explained in their presentation.
In both this case and their delays in getting to 10nm due to wanting larger dies, it really feels like Intel's management is letting better be the enemy of good whereas AMD is making smarter choices about where to compromise.
By the time Intel releases their awesome 10nm 3D chiplet stack, AMD will likely have moved onto 5nm compute chiplets with a 7nm IO chiplet. It's not clear to me how Intel will catch up in the next 5 years or so.
Uh - Intel is releasing Foveros this year. Assume its going to be in a surface type of device. Little big core for x86. AMD will not be on 5nm. You seem confused about the status of the industry..
Point being you were wrong in the statements you have been making. 5nm will not be out by the time Foveros is introduced. I did not state Foveros is a competitor to a 128 thread epyc processor..
Wanna guess how much first ever 60 MHz Pentium chip cost in 1993? How about first 90 MHz Pentium in 1994? First Pentium II in 1997? Price of fastest Athlon K7 in August 1999? All more than $750 despite 20 years of inflation.
I think it's aimed at people who do specialised tasks such as video editing without the extra expense of moving to HEDT hardware.
Plus, these chips with two CCXs also has double the PCIe lanes 40! So a number of NVMe drives, GPUs, 10GbE etc... can run together without fighting over lanes (and that's without double bandwidth of PCIe 4.0).
It does still feel weired calling 16 core/ 32 thread CPU with 72MB of cache 'consumer'.
There is a little confusion whether it is 40 lanes or feels like 40 lanes. PCIe is a serial interface so they only need an additional wire per lane, per direction. So it is feasible as CPUs generally have spare pins.
As DDR5 is coming out next year, that will mean a new socket, limiting the upgrade path for the CPU, RAM & Motherboard. Although, 16 cores ~4.5ghz shouldn't be a problem for the near future (maybe 5 years even). Same goes with the PCIe bandwidth.
Edit: Just done some checking, I appears the 3950X has 24 PCIe lanes (16+4+4), but they are twice as fast, so not far behind the current 2nd generation ThreadRipper!
There is no confusion. It has x16 lanes for graphics/slots, x4 dedicated lanes for NVMe storage, and x4 lanes for the chipset.
The chipset multiplexes up to x16 lanes of "stuff" onto the x4 chipset lanes from the CPU.
All of this is physically determined by the pinout of the socket and none of this can change unless AMD moves to a new socket. What did change is the speed of the lanes - x4 lanes on 4.0 is twice as fast as x4 lanes on 3.0.
AMD, like Intel, likes to pretend that chipset lanes "count" as full CPU lanes, arriving at a total of 36 effective lanes. But that's nothing new either.
That's correct, however, considering that Zen 2 supports PCI-E 4.0, that's double the bandwidth of the previous generation, it means that those multiplexed 4x can theoretically now support double the bandwidth of the previous generation 4x and it's not like the "stuff" that does get multiplexed over that 4x (USB, SATA, some 1x cards like sound, wifi and ethernet) also suddenly needs twice the bandwidth meaning that in practice, that 4x works as an 8x in Zen 2 motherboards. Great deal I say :)
It's a halo product for their am4 platform. I've heard people recommend midrange Intel cpus over equivalent Amd parts because you could upgrade to a top-of-the-line cpu later on that platform, but you couldn't go higher on Ryzen.
Does anyone honestly upgrade CPUs? I’ve built machines with upgradability in mind for decades but I can’t say I’ve ever actually done it. Every time I want to upgrade, inevitably enough time has passed that there’s a new socket out and I have to replace the motherboard anyway.
Looks like I was for some reason confusing pcie 4 compatibility (which will not be supported even on top end mobos) with cpu compatibility. Can't edit the post though.
I've only done it once before with an early Pentium, I believe from 133 to 300 MHz? I plan to do it again with my Ryzen 7 1900 as soon as the 3000-series hits the market.
I'm probably going to buy it; I do 3D animation/simulation stuff that gets huge benefits from parallelism, and it sounds like the Ryzen 9 beats everything other than the top-line Threadripper 2990WX (which has 32 cores but only 3GHz base clock with 4.2 boost). The Threadripper isn't a clear winner (the base and boost clocks are quite a bit lower), and they're super pricey ($1.7k). $750 for 16 cores at 3.3/4.3GHz is incredible.
Gamer and programmer here! From the perspective of a gamer with a "large but not infinite budget" in the past say ~8 years. I play counterstrike where any fps stutter is unexceptable. I also enjoy prettier games like BF5, etc. My current system is an i7 8700k, 32GB ram (just because), and a 1080ti.
Intel has always been the go-to. The #1 Priority is thread performance, first and foremost. Second is at least 4 cores. Most modern games can utilize at least 4, but it's also important to give the OS and other programs like discord plenty of cores.
While the Ryzen Gen 1 and Gen 2 have been amazing values, for gaming performance Intel has still ben king. When you compare AMD to Intel FPS to FPS Intel nearly ALWAYS wins.
CSGO is especially thread performance reliant, but this goes for most games. It's worth noting too that while games can use multiple cores, I don't believe most engines scale to 8+ cores very well.
Historically the only reason Intel has won on absolute top performance gaming FPS is because their raw single-threaded performance has beaten AMD due to most games still being bad / ineffective with multiple threads. For the first time in many processor generations this may actually not be true because of Intel’s stumble in their 10 nm transition.
That changed slightly with Ryzen: AMD closed the gap on single-threaded IPC (close enough, anyway) but the new issue with Zen 1 and Zen+ was memory/cache/inter-CCX latencies. Zen+ solved most of the memory latency issues but hadn't fixed cache/CCX latencies much.
Supposedly Zen 2 solved most of that. (And some game benchmarks like CSGO suggest they really did) We'll see how it actually pans out since there's still the issue of inter-CCX latency (and now even cross-chiplet latency).
It doesn't solve all of it however. If your program has more than "$number_of_cores / 2" threads, you'll cross the CCX boundary at some point(s). On Zen 2, that instead changes to "$number_of_cores / 4" (CCX boundary) or "$number_of_cores / 2" (chiplet boundary).
Inter-CCX communication requires hopping over the Infinity Fabric bus, which (in case of Zen 1, no newer benchmarks) increases thread latency from ~45us to ~131us. I'm sure it was reduced in Zen+ and is probably closer to 100us by now. However, I'm not sure if inter-chiplet communication will be the same (e.g.: has its own IF bus) or worse (IO chip overhead).
Hopefully someone runs the same inter-thread communication benchmarks on Zen 2.
Recovering CSGO player here. I got a beefy box (TR1950X, dual 1070i’s, NVME, etc) for ML and crypto mining, and gaming inevitably followed. That plus low ping internet immediately boosted my ELO rankings and I started having more fun. Life in general became less fun since my sleep was suffering. That and the toxic CSGO community has kept me away, but I still relish the palpable advantage I enjoyed with better gear.
The trick is to play random matches and gradually add people you enjoy playing with. We started doing this a year ago, and now we have a small discord server with a few dozen people who are all fun to play with. It's best to recognize things are frustrating by not verbalize it 24/7 as it lowers the teams moral.
as another CSGO player, I am seriously considering one of the high end ryzen 3000 cpus. if the performance is as advertised, it looks like amd will be the single thread king for at least 6 months.
Before you pull the trigger wait to see what the latency between the chiplets/memory does to framerates. We'll know once benchmarks are out, but remember not just to look at average framerate but minimums too, you can have high framerate with terrible stuttering.
I doubt gamers will be a big market for that chip. You don't get a whole lot of increased capability / FPS with a high end chip compared to a mid range chip when the GPU is generally the limiter. But I do think they are going to sell a ton of 3600-3800 chips.
Came to say the same... the 3600 (non-X) is extremely competitive in gaming, and is pretty likely to have some good overclocking headroom with a good water cooler. Personally, I'm very much looking forward to the 3950X and will probably be my choice (even though waiting yet another 2 months to upgrade) unless something significant/soon happens in the next ThreadRipper, the 3950X is likely to be a very sweet spot carrying it for 5 years and more.
I've said in other comments my 4790K is getting a bit old at this point, not slow for most stuff, but definitely hungry for more cores for a lot of tasks, and looking to break past 32gb of ram. I'd also been considering Epyc or even Xeon, as older/used Xeons can be very well priced. Guess I'm waiting until September.
> I've said in other comments my 4790K is getting a bit old at this point, not slow for most stuff, but definitely hungry for more cores for a lot of tasks, and looking to break past 32gb of ram. I'd also been considering Epyc or even Xeon, as older/used Xeons can be very well priced.
I’m in nearly the exact some boat. I’d like to have ECC ram the second time around for my home server, which the Zen chips reportedly support though I don’t see people using. I’d also like better power usage. I think I’m going to wait one more year.
Just got a used Dell, dual 8-core CPUs and 128GB ECC ... main purpose is for a NAS and it'll sit in the garage because of the noise. I may look into what CPU upgrades are available and maybe throw some heavier workloads at it.
For now, planning on just playing around with it. I haven't decided if I'll be running Windows or Linux as the base OS yet.
It's a standard 2U enclosure... haven't tested the power usage, but it's a relatively current Intel CPU (E5000 series iirc), so should idle reasonably well.
Well, at first gamers said dual-core chips are useless. Then that quad-core chips are useless. Now they're testing waters with octa-core chips.
Game developers have always made a good use of the available resources. They'll use the extra power available. The newest techniques they have, like work stealing queues, can scale to a large number of cores.
So games and gamers will use the extra cores. It's much less of a jump from 4 cores to 16 than from 1 to 2.
In (recent) games made with Unity, a lot of workloads like scheduling the GPU and such are offloaded to separate threads with (almost) no developer intervention. Future games will extensively utilize the job system which provides safe and efficient multithreading. Not sure how Unreal and the remaining leading engines stand, but things seem to be looking very good for high core count CPU owners.
gamers will probably not be a big market for that chip, but it might be appealing for gamers with a large budget. unless intel has something big hidden up their sleeves (doubtful when they don't even plan to release their next mobile line until holiday 2019), that 16-core chip will likely have the best single-threaded performance on the market. plus it has to be a highly binned part to have the same TDP as the 12-core model even with a slightly higher boost clock. I for one am very interested to see overclocking results.
Just look at the cost of gaming GPUs (including the costs of watercooling?). Not to mention the fact that CPU can have a slower upgrade cycle than GPU (since a CPU upgrade will usually mean upgrading the motherboard, possibly the RAM, who knows what else while you're there), so getting a top GPU is not at all cheap in the long run.
No it's not worth it IMO, but some people spend crazy amounts chasing a few extra fps.
More recently, the 9900k's MSRP was $500 but it was sold for $600 at launch due to scarcity. People wondered who would even buy that given its price but gamers (myself included) happily did and it sold out for months.
Yeah but if you want the best consumer chip in the market, you're probably a consumer with special needs e.g. someone that encodes/renders videos; engineer/scientist who needs tons of computation/simulation/visualization; gamer who plays CPU-intensive games like factorio/dwarffortress/rimworld etc... so in that niche $750 is still a very much consumer product. The end computer setup will cost around $2k, $3k which is a pretty normal price for these kind of niche consumer computer.
What really matters (for people that do the CAPEX and OPEX math on their assets; not gamers) is the performance/power ratio. Without this I don't see AMD eating much of Intel's lunch (35B vs 208B market cap).
The Zen 2 16 core chip is 105 watt TDP. The chips its wiping the floor with are 165 TDP. TDP doesn't necessarily correlate with real world usage, but benchmarks show that AMD is much better at their chips running closer to TDP than Intel chips are, so the gap is probably actually wider. The strength of Intel chips is being able to pump a lot of power through them to hit higher clock rates.
It sounds like you're saying performance/power is a benefit for Intel, possibly based upon the history of AMD chips, but that line of thought has been wrong since the Ryzen architecture.
> benchmarks show that AMD is much better at their chips running closer to TDP than Intel chips are, so the gap is probably actually wider
AMD gives their TDP with enabled turbo (similar to real usage), Intel gives TDP at rest / no turbo enabled.
There is still some variance from both between given and real TDP, but the core of the difference is well assumed, and dates back to almost a dozen CPU generations back when Intel already had to guzzle power like crazy to superclock their chips in the vague hope that they could compete with AMD's products of the time (and then they never reverted it once they took the lead back with the core architecture)
It's kind of similar to the whole "Intel wants comparison dont with SMT off", due to the last 15 years being theirs, the whole thing is biased toward Intel, ... yet they still massively lose those comparison.
This is accurate, several "95W" TDP intel chips will happily guzzle upwards of 200W+ for sustained periods (providing they don't down clock due to heating)
No this is absolutely not accurate. This only happens due to motherboard defaults running all cores at turbo speeds simultaneously as well as automatic overclocking behaviors on by default.
The reasoning doesn't matter, what matters is what the average consumer sees. If most consumer motherboards do it "wrong", Intel should use those numbers instead of the less common, but "correct" case.
And almost every benchmark will run on one of those motherboards, or do you have a list of curated benchmarks where they were done with TDP limitations per spec?
This is wrong, intel gives their TDP with CORRECT turbo enabled. The problem is that nearly every popular motherboard out there enables turbo on all cores simultaneously ("enhanced multicore" for example on ASUS boards) which blows the TDP out of the spec massively.
As a Small Form Factor enthusiast, I can attest to this with utmost confidence. The chips will run at their expected TDP when configured as specified by the factory, that's just not the default on almost any enthusiast board from known companies. In the case of ASUS it can actually be a bit of a battle to get things to run as intel specifies, both with MCE and automatic overclocking behaviors.
> The problem is that nearly every popular motherboard out there enables turbo on all cores simultaneously ("enhanced multicore" for example on ASUS boards) which blows the TDP out of the spec massively.
If that's the case, then also the performance is "massively blown out", since essentially all the benchmarks around are based on popular motherboards.
Anantech did a test some time ago with a real, fixed, 95 W TDP[¹], and it ain't pretty.
It's definitely good for Intel that "every popular motherboard" is, uh, guilty of going out of spec, otherwise, the popular opinion of Intel chips would be significantly lower.
Regardless, I'm also not really convinced that this can be considered "cheating" by the motherboards. According to the official Intel page [²]:
> The processor must be working in the power, temperature, and specification limits of the thermal design power (TDP)
so ultimately, it's the CPU that sets the performance/consumption ceiling.
And you can do the same on quite a few AMD boards with "Precision Boost Overdrive", which gives you a 300W TDP on 1950x if your cooling can handle it.
Or you can ignore turbo and flat overclock the thing, which depending on workload will produce better results.
I think even on 1st gen Zen processor intel had performance/watt advantage though the gap was lower. It's Zen 2 that has completely obliterated intel in performance/watt. Which is almost a bigger shock than the AMD taking the performance crown. Taking both the performance and efficiency crown in a single generation specially when it's not even a full new generation is beyond impressive. Of course it was only feasible with the foundation build up by Zen 1 but it's still very encouraging after the major stagnation that was there in desktop processor for a long while.
It's going to depend heavily on which specific CPU you're talking about and which specific workload, but at least on Handbrake the Ryzen 2700 was the performance/watt king per legitreviews: https://legitreviews.com/wp-content/uploads/2018/05/performa...
Maybe Intel took that back with their lower clocked 8c/16t chips, dunno, this isn't something that comes up all that much in consumer reviews. But there's at least not a significant gap in either direction, it's pretty much a wash.
The dual EPYC 7601 used 100w less than the Xeon competition in povray while also being the fastest system by a substantial margin at povray, too. Which would put performance, power, and performance/watt all firmly in the EPYC 7601's domain on that one test. And Intel took it back on MySQL. So 50/50 split.
There are a lot of factors to unpack here, but the 8700K has 2 less cores than the 2700X, which is the reason the 8700K is coming out behind. The direct comparison here is the 9900K, but the 9900K ships with significantly higher stock clocks (4.7 GHz all-core), which also reduces its perf/watt.
When limited to its "official" 95W TDP, the 9900K does about 4.3 GHz and has a higher perf/watt than Ryzen (both higher performance and lower power consumption).
So basically you are in a situation where the Ryzen pulls less at stock, has slightly higher efficiency at stock, but has a much lower clock ceiling. While the 9900K ships with much higher clocks and worse efficiency, but has a much lower power floor if you pull the clocks back to 2700X levels.
Of note, the 2700X is actually pulling ~130W under AVX loads (33W more than the 95W-limited 9900K).
The Stilt noted that the default power limit AMD ships is 141.75W and the 2700X will run it for an unlimited amount of time (whereas Intel at least claims PL2 obeys a time limit, although in practice all mobo companies violate the spec and boost for an unlimited amount of time as well). So really "TDP" is a joke all around these days. Nobody really respects TDP limits when boosting, and it doesn't directly correspond to base clocks either (both 9900K and 2700X can run above baseclocks at rated TDP). It is just sort of a marketing number.
Epyc is a different matter and once again more cores translates into better efficiency than fewer, higher-clocked cores. But the gotcha there is that Infinity Fabric is not free either, the infinity fabric alone is pulling more than 100W on Epyc chips (literally half of the total power!).
Similarly, the 2700X spends 25W on its Infinity Fabric, while an 8700K is only spending 8W. So, Infinity Fabric pulls roughly 3x as much power as Intel is spending on its Ringbus. This really hits the consumer chips a lot harder, mesh on the Skylake-X and Skylake-SP is closer to Infinity Fabric power levels (but still lower).
Plus, GF 14nm wasn't as good a node as Intel 14nm. So Ryzen is starting from a worse node.
Moneyshot, core for core, power efficiency on first-gen Ryzen and Epyc was inferior, but of course Epyc lets you have more cores than Xeon. Ryzen consumer platform's efficiency was strictly worse than Intel though.
And that goes double for laptop chips, which are the one area that Intel still dominates. Raven Ridge and Picasso are terrible for efficiency compared to Intel's mobile lineup. And AMD mobile won't be moving to 7nm until next year.
Because of that whole "nobody obeys TDP and it doesn't correspond to base clocks or any other performance level", we'll just have to wait for reviews and see what Zen2 and Epyc are actually like. I am really interested in the Infinity Fabric power consumption, that's potentially going to be the limitation as we move onto 7nm and core power goes down, while AMD scales chiplet count up further.
I somehow completely missed this coverage of Infinity Fabric power usage. I wonder if IF power usage percentage remains the same in this generation or it has been reduced. If not improvement of IF power usage would remain a viable opportunity to make these chips even more power efficient. It seems that given IF power usage it's clear that I was even more uninformed about the power usage of first gen Zen cores.
This is good to know. Are there any reputable benchmarks that show those advantages? Something like FLOPS/watt on some LAPACK or Tensorflow test, or amount of joules to compile the Linux kernel, or anything of this sort?
> It's Zen 2 that has completely obliterated intel in performance/watt. Which is almost a bigger shock than the AMD taking the performance crown.
Why is this shocking? Zen 2 is 7nm and Intel's latest is at 14nm. It would be a far bigger shock if they didn't beat Intel in performance/watt. Zen 2 vs whatever Intel releases on 10nm in the next ~6-18 months is a much more interesting comparison.
AMD wasn't really a consideration but for budget until they launched the Athlon in the late 90s. The success of Athlon was as much about Intel's fumble with Netburst as it was with Athlon being a solid competitor.
It took Intel almost a decade to roll out Core and in that time AMD failed to capture the market despite making tremendous gains and legitimizing itself.
Ultimately AMD fumbled with the Bulldozer/Excavator lines of CPUs and lost almost everything they had gained.
The reasons AMD couldn't capture the market are complex but the short answer is that Intel influences every aspect of a computer from software, to compilers, to peripherals, to firmware.
> It took Intel almost a decade to roll out Core and in that time AMD failed to capture the market despite making tremendous gains and legitimizing itself.
And by AMD failed you mean Intel used illegal means to stop them from it, right ?
The US, Japanese and Korean fair trade comission equivalent all either blamed Intel or fined them. The EU was still too young in that area to be in time but in 2009 they gave one of their biggest fine ever at 1.45 billions € to Intel for what they did, along with an approriate "oh and if you do it again we won't be late, and won't be so nice".
Calling it "AMD failed to capture the market" is technically true, but that's one funny point of view.
> Ultimately AMD fumbled with the Bulldozer/Excavator lines of CPUs
I've heard this baseless assertion before but so far I've never heard any semblance of support. Why do you believe that AMD "fumbled" with their Bulldozer line?
Not Ryzen related, but seems you're pretty up to speed with AMD products. Does that include Radeon as well? I have a MBP and I am considering a Radeon VII for my external GPU (currently GTX 1080 but only usable in Windows. Thanks Mojave). My main concern though is thermals and noise. Does it perform on par with Nvidia there or little bit worse or considerably so? Power draw I'm not that concerned with.
thanks for that. That's a huge bummer. Really wish Apple wouldn't force the Metal issue with Nvidia. Yeah, it'd be nice and all, but as a user, I'm fine with the various scripts I have to run after macOS updates to get the card running again but they just nixed that outright. Oh well, hopefully AMD can solve the fan problems or Nvidia and Apple can work something out, either or.
The Radeon 5700 and 5700 XT are supposed to be competitive with the RTX 2060 and RTX 2070 at slightly lower prices. Only reference cards right now, but things might be looking up once OEMs have a chance to put better coolers on instead of AMD's reference blower.
I'm planning to hold out for next gen when they get ray tracing hardware to be a bit more future proof (my GTX 970's not dead yet), but since I'm thinking of trading my Wintendo out for a Mac + eGPU setup it's nice to see that AMD could actually be a good GPU option now.
Those were just announced this week, so keep an eye out for 3rd party benchmarks soon.
Will probably pull the trigger on a Radeon VII myself, only because of the better Linux drivers, and possibility of hackintosh usage. At least for my current system, I did a mid-cycle upgrade for the GPU (GTX 1080) and added NVME a couple years ago. Still running 4790K on 32gb ram, and does great for most stuff, but not so much for encoding or dev work (couple dbs and services in background).
Sadly they both appear to have a total board power 50W higher than NVIDIA's comparable model(s), so NVIDIA might still win out on power. But we'll have to wait for third-party benchmarks to confirm that.
I would wait the month or so for Navi cards to show up and see how they do on thermals and if the application performance is to your liking; Navi is intended for midrange cards(says the PR) but getting similar performance to your 1080 is possible.
AMD's recent releases have a reputation of releasing at "hot/high-power" stock and then doing much better when undervolted. Navi will get the die shrink, so the results for both power and thermals are likely to be even better, but benchmarking needs to be done before we have a full picture of what's changed.
It looks like the latest AMD cards are a bit more power hungry than NVidia counterparts. On performance, the Radeon VII seems to be closely aligned to the RTX 2080 (not TI). The RX 5700 XT is around the RTX 2070, and the RX 5700 is above the RTX 2060. Depending on your workload, and if it can leverage the AMD targets, it could be good to great. If you don't actually care about RTX features (and the slow framerates that comes with it), then you're better off with AMD for the price difference, even considering the extra power needs.
I guess you are not aware that at this point everything suggest that the upcoming AMD 7nm processors are significantly more efficient that similar performance intel processor.
The Ryzen processor is 105w vs. the significantly slower intel processor is 165w. Additionally also AMD's TDP numbers are much more accurate in terms of real peak usage than intel. So almost certainly Zen 2 processor will have a much better performance/power ratio than corresponding intel one moving forward. That was definitely not the case for AMD in their last generation.
In that case, Intel should be in big trouble, because the advertised TDP seems to be less than half the power required to reach the chips' advertised performance:
> In this case, for the new 9th Generation Core processors, Intel has set the PL2 value to 210W. This is essentially the power required to hit the peak turbo on all cores, such as 4.7 GHz on the eight-core Core i9-9900K. So users can completely forget the 95W TDP when it comes to cooling.
The Core i9-9980XE pulls from 199W->245W depending on the workload and AVX instructions being used under stock settings. The Ryzen is listed as a 105W part, although when overclocked, I'm sure it will pull more than that.
> AMD chip at 105w (and AMD give real tdp), while the Intel chip is at 185w (and Intel give tdp in non turbo mode).
Both AMD & Intel list TDP for all cores used at base clock frequencies. The major difference is Intel heavily leverages what they call all-core boost to never actually run at their base clock, allowing them to list rather ridiculously low base clock frequencies. For example the i9-9900K's base frequency is listed at 3.6ghz, but the all-core turbo frequency is a whopping 4.7ghz. That difference is how you end up with a CPU that expects a whopping 210W of sustained power delivery (the 9900K's PL2 spec) even though its TDP is only 95W.
AMD doesn't (didn't?) have an all-core boost concept, so their base clocks are just higher, making their TDP number closer to real-world. But still technically base-clock numbers and not boost numbers, and so you will still see power draw in excess of TDP.
Surprisingly no one noticed or reported that the memory is heavily overclocked by +29% in this specific benchmark. Here is the direct link to the detailed results: http://browser.geekbench.com/v4/cpu/13495867
Officially Ryzen 9 3950X supports up to DDR4-3200 (1600 MHz) according to the published specs https://www.amd.com/en/products/cpu/amd-ryzen-9-3950x however in this benchmark the memory was overclocked to 2063 MHz:
Memory: 32768 MB DDR4 SDRAM 2063MHz
Memory overclocking heavily impacts Geekbench multi-core scores. For example the old Threadripper 2950X sees a score boosted by +18% (39580 vs 46908) with a +9% overclock (1466 vs 1600 MHz): http://browser.geekbench.com/v4/cpu/compare/13400527?baselin... Although to be honest comparing random Geekbench scores in their database is not exact science because too few system details are reported (for example we don't know if the user systems are running dual or quad-channel DDR4) and we don't know what other hardware mods users make.
While AMD claim it can be overclocked to 4200 or 5133, it doesn't invalidate my claim that officially it is spec'd for DDR4-3200 according to the product page: https://www.amd.com/en/products/cpu/amd-ryzen-9-3950x
Note I am not playing down the 3950X's performance. It is overall a processor superior to Intel's counterparts in most aspects.
Every ddr4 module beyond that is officially a 3200 module with overclock option.
That's why you need to enable Extreme Memory Profile in your bios to use speeds beyond 3200.
Geekbench doesn't compare stock rigs, it compares benchmark results - commonly used by overclockers, even those who go to extremes like liquid nitrogen. The benchmark results this is being compared to are also heavily overclocked and tuned systems.
Cite for that? All I see are numbers with an Intel CPU model next to them. I don't see anything reporting the hardware configuration except for the one AMD system, which as noted is very significantly tweaked.
The model name with a number next to it is some sort of average (they don't say but I think it's geometric mean?) computed from all scores submitted from that particular model. It's not terribly useful because you have no idea how many of them are overclocked, by how much, the memory configs, etc. without reading through every entry and a lot of them are missing info anyway.
This 3950X result is definitely not faster than the top overclocked 9980XE, but it is faster than something like 3/4 of them. Given the base clocks of each I would expect the stock 3950X will end up at least slightly faster than the stock 9980XE though.
What could be a cite for this. PC builders worldwide like to build their computers and then benchmark them on geekbench. Naturally the top most benches will be the heavily tuned ones.
But those independent tests are inevitable and probably right at or right after launch. Does AMD stand to gain anything by falsifying test results that are (relatively) easy to fact check independently?
I mean, no one should lose their minds over it right now or anything, but it seems impressive. I certainly don't see an upside to giving bogus stats right now.
Which is hilariously wrong. And if you think that's some quirk of Epyc, well, same CPU gets 65k when run under Linux: https://browser.geekbench.com/v4/cpu/10782563 So clearly there's a software issue in play. Maybe this is related to the new Windows scheduler change. Maybe geekbench just has some pathologically bad behavior. Who knows.
So yes we should wait for release & independent testing before getting too excited, even if that's just so we get numbers from something other than geekbench.
Geekbench exposes some strange behaviour around the memory allocator under Windows. On systems with more than 8 cores Geekbench spends a significant chunk of time in the memory allocator due to contention. This issue (at least to this degree) isn't present on Linux, so that's why Epyc scores are much higher on Linux than Windows.
The memory path for current/prior Threadripper is a pretty well known issue, and likely the cause of the disparity. It may or may not have been an issue in other types of workloads. The new memory path is more consistent, slightly slower than best case for prior gen, but huge leap forward for Zen 2 considering the better handling for higher clocks on RAM.
I find myself drawn to these new chips and news, but you're absolutely right - we need to be skeptical here. But I really want to believe. Either way, I wont be ordering until I see a lot of real 3rd party benchmarks.
The old Threadripper 2950X can get up to 46908 with a little bit of memory overclocking, here it is with DDR4 at 1600 Mhz, a modest +9% over stock at 1466 Mhz: http://browser.geekbench.com/v4/cpu/13400527
This Ryzen 9 3950X scores so high because the memory is heavily overclocked by +29%, see my other post in this thread.
This might be an unfair comparison — the AMD numbers are from a single benchmark, and the article is comparing this against the aggregated scores of the i9-9980XE. A few i9-9980XE multi-core scores on Geekbench reach higher than 60k as well, with the highest being 77554 multi-core.
The Ryzens have an absurdly long branch prediction history that make them much better at repetitive tasks than random real-world workflows. I wonder how much this is effectively "gaming" the Geekbench suite.
That's not the impression I got from that thread. They seem to agree that this is bad for benchmarking, but remain undecided on whether that's good or bad for real-world processing.
It depends on the work. So as always benchmark suites are to be taken with a grain of salt. More specific benchmarks, such as compiling a standard set of real software packages, can give a clearer picture of performance for those more specific use cases.
Until we see more specific data on how these chips perform for certain tasks, this is just FUD.
Yes, that's why I qualified my "real-world tasks" with "random". What is clear is that:
* Ryzen has a longer branch prediction history than Intel's processors.
* This will give it an advantage on repetitive executions.
* It's a challenge to robustly measure tasks since using repeated executions to gain confidence intervals can interfere with the measurement itself.
What's not clear is to what extent real-world tasks are repetitive enough to benefit or random enough to be negatively impacted. It's likely a mix of both.
By no means am I attempting to spread FUD — I find it quite interesting and wanted to spark a bit of discussion on it.
Pardon. I didn't mean to imply you were intentionally doing that. Just trying to make sure there's skepticism of benchmarks as well as skepticism that the boost from branch prediction is dishonest.
> More specific benchmarks, such as compiling a standard set of real software packages, can give a clearer picture of performance for those more specific use cases.
Is there a good place to go for this? I've tried to find software development focused benchmarks before, but I've come up mostly empty.
Bravo, everyone on the PC side has great options now, but I feel for Mac "Professionals". Sad they just got straddled with the horrendous over priced and under performing Xeon platform. It boggles my mind why Apple would release a $6k model that will get trounced by these chips for a fraction of the price. I know the expand-ability is what you are buying into, but I imagine 90% of Mac Pro customers could care less about terrabytes of memory or a video solution that improves current vram limits. Add to all of that the gimped performance you are going to get on the Intel parts with the latest security patches.
Apple must have had an interest in going with AMD - the fact that they didn't makes me think that getting macOS ready as a productive, reliable OS on AMD CPUs isn't as trivial as we might assume. Also, is Thunderbolt even an option with AMD?
Given that it's AMD, shouldn't that be "it's fabless"?
I've got a mix of Intel and AMD, and have had no loyalty back to when I replaced my Pentium 75 with a pre-unlocked AMD Duron from OcUK.
I'm so glad to see AMD not only raise its game exponentially, but also force Intel to compete. It's good for everyone.
My next purchase will probably be a Ryzen 5 2600, because the price drop ahead of the 3xxx has made them ridiculous value for money.
Definitely a good time to be a PC gamer.
Slightly frustrating that the integrated graphics 3x00G chips are basically Ryzen 2xxx chips though. I hope the g-range gets a refresh with proper Zen 2-based chips shortly.
WRT "who next", did you see the Chinese AMD custom Ryzen+Vega APU console last year, the Subor Z-Plus, with 8GB GDDR5 as shared system and graphics memory?
Totally agreed on the 3xxx(G|H) parts not being Zen 2, and really misleading on that front. Though they're mostly underclocked with lots of room for boost, so competitive to Intel's. Also the onboard vega gfx almost doesn't suck by comparison.
The current rumor is Apple is going to ARM in 2020 for their computers. There is uncertainty if that will include MacBook Pros or Mac Pros initially or if it will just be their Air and maybe the MacBooks to start with. That's not to say they won't take their higher-end computers to AMD but I would bet if they are moving to ARM at all they are going to push for everything to be on ARM eventually and it's probably not worth the effort to switch from Intel to AMD in the interim.
As long as they're coming out with new hardware configurations anyway, why should switching to AMD require substantial effort?
There are modified Darwin kernels that allow Hackintosh to work on AMD processors. These kernels have some stability issues, but if hobbyist outsiders can get most of the way, I don't forsee it being a big hurdle for actual Apple engineers.
Because strategically, the move to ARM makes more sense for them to focus on even if sticking with Intel is a bit more painful in the short term. They already have a large team working on ARM processors and an architecture license for the platform. With x86, they are basically just resellers. So adding AMD's flavor of x86 to their lineup would likely be seen as a distraction for them without providing a long-term benefit.
Primarily, compatibility with legacy apps, and compatibility with other OS's (eg Bootcamp/Parallels).
I also have major concerns about raw performance at the high end, and I suspect ARM would come with even more software lockdown, although there's no reason that has to be the case.
I was watching highlights of WWDC and they mentioned that they're adding support to XCode to migrate iPad apps to the desktop.
I subscribe to the theory that the Air will move to ARM at some point. Adding this feature to XCode sounds like the sort of thing you would do to prepare the way for an architecture shift. Especially if you were still on the fence about that shift. Let's just get a feel of how viable this space is before committing to anything.
Except the change to XCode is a direct conflict of interest with moving MacBooks to ARM platform. If they are moving to ARM soon, there is no point in adding a brand new feature to the IDE that helps convert ARM apps to x86 apps. The reason Apple is doing so is due to the new Ipad OS that resembles desktop interface.
At the very least, half of the cache is disabled. They cherry-picked a feature from the Pentium III lineup that they wanted to keep while lowering the cache to Celeron levels. It's a deliberate modification to reduce cost while maintaining desired performance.
It's not detectably customized beyond that but it's not like it's a SKU you can buy off the shelf, either.
I could understand Apple not wanting to jump all over Ryzen 1000 from day one, but not even Zen2 2-based Ryzen 3000? Even after the whole 5G spat it had with Intel?
The thought would be that they don't want to do any architecture shifts before they bring it all over to their own ARM chips. And AMD still doesn't really deal with laptop processors.
Firstly it might be more complicated than that, they may have a contract in place with intel where they need to stick with them for X amount of years in return for cheaper stock or better deals elsewhere (Apple and intel work together on other things). That’s hypothetical, but it’s certainly not as simple as “they should just switch”.
Secondly Apple might be waiting for their own chips to reach a point where they can be used in their laptops/desktops and jump on to that. It would be overkill to use ryzen as an interim.
Some x470 boards support it to via an addin card and thunderbolt header. To get displayport passed through you need to run a cable from your graphics card output to the addin card input. It's not very tidy and doesn't work 100%.
I'm hoping someone eventually just does the needful and sticks a thunderbolt chipset on a PCIE4 graphics card and makes it work somehow.
That’s a lot of performance for 749 USD. Building a new workstation / gaming rig in about 18 months time so I will be spoiled for choice by then especially given the used market as these will be old hat by then.
It looks like single core performance is still worse than i9 9900K. I wonder how this could look like when overclocked?
Sadly my workflow prioritises fast core over multiple cores - audio production. This workflow cannot be made parallel as one plugin depends on the output of another. If plugins can't keep up with filling the buffer you get stuttering.
Single core limits you how much processing you can have on a single audio track and multiple cores how many tracks of that processing you can get.
It looks like I wouldn't be able to run my chain in realtime on this new AMD even if it had 100 cores.
The numbers provided by AMD are supposedly benched before 1903 Windows scheduler updates (for CCX aware process threading, much faster clock ramping, etc) and without the latest Intel security mitigations, so it's possible that real world numbers might be even better: https://www.anandtech.com/show/14525/amd-zen-2-microarchitec...
Besides the massive L3 cache, Zen 2 now supports very fast RAM overclocking on part w/ Intel platforms (DDR4 3600 OOTB, air-cooled 4200+, and 5K+ on highend motherboards - a huge improvement considering how finicky Zen, and even Zen+ was) and also a huge FPU bump (including single-cycle AVX2) but I think for full details, again we'll be waiting either for July or later for AMD's Hot Chips presentation.
Every workload will be different, but considering AMD's node, efficiency, and security advantages, I wouldn't take it for granted anymore that Intel will have a lead even for single-core perf (especially once thermals come into play).
The source mentions that this benchmark was of an early sample unit -- with a base clock of 3.9GHz and a boost clock of 4.29GHz. The final production unit is specified at base 3.5GHz and boost of 4.7GHz. I'd expect if it can sustain that boost clock with any longevity that it might come notably closer to the i9-9900k in performance.
Why would it not be possible to use multiple cores? Even though the plugins depend on the output of the previous one, they could sit on different cores, passing their output on from core to core. Even though that would not be parallel, being distributed, it could be faster (in some cases it might not).
> Why would it not be possible to use multiple cores?
Because the software doesn't do it (much; I've been told some applications do time-delayed mixing for stuff like delay) and the software is entrenched.
I wince every time I see someone say something can't be made parallel, but this actually not the way to do it. You would want a chunk of samples to be dealt with on the same CPU as it goes through plugin transformations. This would give data locality.
Then other CPUs would be free to start the next chunk of samples. The amount of parallelism is going to depend on the buffer size and number of samples each plugin needs to operate.
I don't think you can make a blanket statement here; it's going to really depend on the implementation details.
For example, if each plugin includes any kind of LUT, you don't have data locality either way, and you're much better off passing data between the plugins. If the plugins are complex, you'll be flushing your instruction cache, which will have to be refilled via random access as opposed to the linear reading of an audio segment.
Further, 192khz 24bit audio is only 0.5 megabytes per second. Skylake lists sustained L3 bandwidth as 18 bytes/cycle. This is enough to transfer 100k such audio streams simultaneously. It's very unlikely this is a bottleneck.
There are a lot of assumptions and some misunderstanding here. The data locality is about latency first and foremost. DDR3 at it slowest actually has 30GB /s of bandwidth and DDR4 can get past 70. Memory bandwidth is rarely the issue.
Also instructions shouldn't be huge, but more importantly they don't change. If the audio buffer stays on the same CPU, it doesn't change either.
Don't forget that writing takes time too. Writing can be a big bottleneck. Keep the data local to the same CPU and it doesn't have to go out to main memory yet.
Other things you are saying about 'flushing' the instruction cache, L3 bandwidth numbers and theoretical LUT that make a difference in one scenario and not the other without measuring (even though the whole scenario is made up) just seem like stabs in the dark to argue about vague what-ifs.
Skylake-X L3 latency is ~20ns. So if you build an SPSC queue between them, how many plugins are we chaining up linearly that this becomes an issue, or even a factor? 1000 might get us to 1ms?
OK, so we're left with a single core running a thousand plugins, and instruction cache pressure is a 'stab in the dark to argue about vague what-ifs'?
You take an absolutist view on what is so obviously a complicated trade off and talk down to me to boot. Maybe I know about high performance code, maybe I don't, maybe you do, maybe you don't. But I do know enough about talking to people on the internet to know to nip this conversation in the bud.
> Skylake-X L3 latency is ~20ns. So if you build an SPSC queue between them
The latency is mostly about initial cache misses. There is no reason to take the time to write out a buffer of samples to memory, only to have another CPU access them with a cache miss. One of many things things you are missing here is prefetching. Instructions will be heavily prefetched as will samples when accessesed in any sort of linear fashion.
Also you can't explicit use caches or send data between them, that is going to be up to the CPU, and it will use the whole cache heirarchy.
> You take an absolutist view
Everything dealing with performance needs to be measured, but I have a good idea of how things work so I know what to prioritize and try first. Architecture is really the key to these things and in my replies I've illustrated why.
> Maybe I know about high performance code, maybe I don't
It sounds like you have read enough, but haven't necessarily gone through lots of optimizations and recitified what you know with the results of profiling. Understanding modern CPUs is good for understanding why results happen, but less so for estimating exactly what the results will be when going in blind.
If you were as good as you claim, you would have directly answered my argument instead of hitting a strawman for five paragraphs.
Your experience led to overconfidence and you identified a ridiculous bottleneck for the problem domain. This is complicated and FPU heavy code running on few pieces of tiny data. And yes, riddled with LUTs. The latency cost you're worried about is in the noise.
Instead of doing some back of the envelope calculations and realizing your mistake, you double down, handwave and smugly attack me.
Your conclusions are bullshit, as is your evaluation of my experience. For anyone else that happens to be reading, I suggest taking a look through the source of a few plugins and judging for yourself.
There is no need to be upset, there is no real finality here, everything has to be measured.
That being said the LUTs would follow the same pattern as execution - all threads would use them and if they are a part of the executable they don't change. This combined with prefetching and out of order instructions means that their latency is likely to be hidden by the cache.
New data coming through however would be transformed, creating more new data. While the instructions and LUTs aren't changing the new data being created on each transformation can either be kept locally so it doesn't incur the same write back penalties and cache misses by
due to allocating new memory, writing to it and eventually getting it to another CPU.
If the same CPU is working on the same memory buffer there is no need to try to allocate them for every filter or manage lifetimes and ownership of various buffers.
If you took time to read the code linked, you'd notice two things:
1) It's very common for the processing of samples to not be independent, but have iterative state; for example delay effects, amplifiers, noise gates...
2) The work done per sample is substantial with nested loops, trig functions and hard to vectorize patterns
So not only does your technique break the model of the problem domain, the L3 latency you're so worried about when retrieving a block of samples is comparable to a single call to sin, which in some cases we're doing multiple times per sample.
Now you conflate passing data between threads with memory allocation, as though SPSC ring buffers aren't a trivial building block. This is after lecturing me on my many "misunderstandings"... if you're willing to assume I'm advocating malloc in the critical path (!?), no wonder you're finding so many.
I'm not upset, I'm just being blunt. Ditch the cockiness, or at least reserve it for when your arguments are bulletproof.
I'm not sure where this is coming from. If one cpu is generating new data and another CPU is picking it up, it's wasting locality. If lots of new data is generated it might get to other CPUs though shared cache or memory, but either way it isn't necessary.
Data accessed linearly is prefetched and latency is eventually hidden. This, combined with the fact that instructions aren't changing and are usually tiny in comparison, is why instruction locality is not the primary problem to solve.
The difference it makes it up to measurement, but trying to pin one filter per core is a simplistic and naive answer. It implies that concurrency is dependent on how many different transformations exist, when the reality is that the number of cores.that can be utilized will come down to the number of groups of data that can be dealt with without dependencies.
> SPSC ring buffers
That's a form of memory allocation. When you fabricate something to argue against, that's called a straw man fallacy.
Are you claiming the act of writing bytes to a ring buffer as being memory allocation? In that case I misunderstood what you were saying and it was indeed a straw man.
In any case, we're clearly not going to find common ground here.
These cannot run at the same time as the output of one feeds into another one. Data travelling from one core to another could mean additional performance loss. Some plugins use multiple cores if whatever they calculate can be parallelised, but still the quicker it can be done the more plugins you can run in your chain.
This is silly. A bottleneck for audio processing is a particular product's flaw, not an intrinsic challenge of audio. A modern machine capable of doing interactive, high-resolution graphics rendering or high-definition movie rendering can do a stupendous amount of audio processing without even trying.
The data rates for real-time audio are so much smaller than modern memory system capabilities that we can almost ignore them. A 192 kHz, 24-bit, 6-channel audio program is less than 3 MB/s, thousands of times slower than a modern workstation CPU and memory system can muster.
The stack of audio filters you describe are a natural fit for pipelined software architectures, and such architectures are trivially mapped to pipelined parallel processing models. Whatever buffer granularity one might make in a single-threaded, synchronous audio API to relay data through a sequence of filter functions can be distributed into an asynchronous pipeline, with workers on separate cores looping over a stream of input sample buffers. It just takes an SMP-style queue abstraction to handle the buffer relay between the workers, while each can invoke a typical synchronous function. Also, because these sorts of filters usually have a very consistent cost regardless of the input signal, they could be benchmarked on a given machine to plan an efficient allocation of pipeline stages to CPU cores (or to predict that the pipeline is too expensive for the given machine).
Finally, audio was a domain motivating DSPs and SIMD processing long before graphics. An awful lot of audio effects ought to be easily written for a high performance SIMD processing platform, just like custom shaders in a modern video game are mapped to GPUs by the graphics driver.
I don't think you're wrong in a technical sense, but the human factors in a contemporary DAW environment are imposing a huge penalty on what's possible.
The biggest issue is that we're using plugins written by third parties to a few common standards. Even when the plugins themselves are not trying to make use of a multicore environment, you still get compatibility bugs and various taxes on re-encoding input and output streams to the desired bit depth and sample rate. It can really throw a wrench into optimizing at the DAW level because you can't just go in and fix the plugins to do the right thing.
Then add in the widely varying quality of the plugin developers, from "has hand-tuned efficient inner loops for different instruction set capabilities" to "left in denormal number processing, so the CPU dies when the signal gets quiet." Occasionally someone tries to do a GPU-based setup, only to be disappointed by memory latency becoming the bottleneck on overall latency(needless to say, latency is really prioritized over throughput in real-time audio).
Finally, the skillsets of the developers tend to be math-heavy in the first place: the product they're making is often something like a very accurate simulation of an analog oscillator or filter model, which takes tons of iterations per sample. Or something that is flinging around FFTs for an effect like autotune. They are giving the market what it wants, which is something that is slightly higher quality and probably dozens or hundreds of times more resource-hungry to process one channel.
If all you're doing is mixing and simple digital filters, you're in a great place: you can probably do hundreds of those. But we've managed to invent our way into new bottlenecks. And at the base of it, it's really that the tooling is wrong and we do need a DSP-centric environment like you suggest. (SOUL is a good candidate for going in this direction.)
This is a simple fact of life and downvoting isn't going to change it.
Plugin cannot start processing before it gets data from previous plugin (sure it can do some tricks like pre-computing coefficients for filters etc). How are you going to get around it?
What's happening within a plugin of course can be parallelised, but other than that, the processing is inherently serial.
If a computing a filter takes X time and a length of the buffer is Y you can only compute so many filters (Y/X) before it starts stuttering. You can spread that across different cores, but these filters cannot be processed at the same time, because each needs the output of the previous one.
Pipelining means that each stage further down the pipeline is processing an "earlier" time window than the previous stage. They don't run concurrently to speed up one buffer, but they run concurrently to sustain the throughput while having more active filters.
For N stages, instead of having each filter run at 1/N duty cycle, waiting for their turn to run, they can all remain mostly active. As soon as they are done with one buffer, the next one from the previous pipeline stage is likely to be waiting for them. This can actually lower total latency and avoid dropouts because the next buffer can begin processing in the first stage as soon as the previous buffer has been released to the second stage.
I think this is one of the most misunderstood problem these days.
Your idea could work if the process wasn't real-time. In real-time audio production scenario you cannot predict what event is going to happen so you cannot simply just process next buffer, because you won't know in advance what is needed to be processed.
At the moment these pipelines are as advanced as they can be and there is simply no way around being able to process X filters in Y amount of time to work in real-time.
If you think you have an idea that could work, you could solve one of the biggest problems music producers face that is not yet solved.
Something like a filter chain for an audio stream is truly the textbook candidate for pipelined concurrency. Conceptually, there are no events or conditional branching. Just a methodical iteration over input samples, in order, producing output samples also in order.
can instead be written as a set of concurrent worker loops.
Each worker is dedicated to running a specific filter function, so its internal state remains local to that one worker. Only the intermediate sample buffers get relayed between the workers, usually via a low-latency asynchronous queue or similar data structure. If a particular filter function is a little slow, the next stage will simply block on its input receive step until the slow stage can perform the send.
This is how it is typically being done. This is not a problem. Problem is that being concurrent, end to end this process is serial, so you can't process any element of this pipeline in parallel. You can run only so many of those until you run out of time to fill the buffer.
I think it could be helpful for you to watch this video:
https://www.youtube.com/watch?v=cN_DpYBzKso
Sorry for the late reply. We have to consider two kinds of latency separately.
A completely sequential process would have a full end-to-end pipeline delay between each audio frame. The first stage cannot start processing a frame until the last stage has finished processing the previous frame. In a real-time system, this turns into a severe throughput limit, as you start to have input/output overflow/underflow. The pipeline throughput is the reciprocal of the end-to-end frame delay.
But, concurrent execution of the pipeline on multiple CPU cores means that you can have many frames in flight at once. The total end-to-end delay is still the sum of the per-stage delays, but the inter-frame delay can be minimized. As soon as a stage has completed one frame, it can start work on the next in the sequence. In such a pipeline, the throughput is the reciprocal of the inter-frame delay for the slowest stage rather than of the total end-to-end delay. The real-time system can scale the number of pipeline stages with the number of CPU cores without encountering input/output overflow/underflow.
Because frame drops were mentioned early on in this discussion, I (and probably others who responded) assumed we were talking about this pipeline throughput issue. But, if your real-time application requires feedback of the results back into a live process, i.e. mixing the audio stream back into the listening environment for performers or audience, then I understand you also have a concern about end-to-end latency and not just buffer throughput.
One approach is to reduce the frame size, so that each frame processes more quickly at each stage. Practically speaking, each frame will be a little less efficient as there is more control-flow overhead to dispatch it. But, you can exploit the concurrent pipeline execution to absorb this added overhead. The smaller frames will get through the pipeline quickly, and the total pipeline throughput will still be high. Of course, there will be some practical limit to how small a frame gets before you no longer see an improvement.
Things like SIMD optimization are also a good way to increase the speed of an individual stage. Many signal-processing algorithms can use vectorized math for a frame of sequential samples, to increase the number of samples processed per cycle and to optimize the memory access patterns too. These modern cores keep increasing their SIMD widths and effective ops/cycle even when their regular clock rate isn't much higher. This is a lot of power left on the table if you do not write SIMD code.
And, as others have mentioned in the discussion, if your filters do not involve cross-channel effects, you can parallelize the pipelines for different channels. This also reduces the size of each frame and hence its processing cost, so the end-to-end delay drops while the throughput remains high with different channels being processed in truly parallel fashion.
Even a GPU-based solution could help. What is needed here is a software architecture where you run the entire pipeline on the GPU to take advantage of the very high speed RAM and cache zones within the GPU. You only transfer input from host to GPU and final results back from GPU to host. You will use only a very small subset of the GPU's processing units, compared to a graphics workload, but you can benefit from very fast buffers for managing filter state as well as the same kind of SIMD primitives to rip through a frame of samples. I realize that this would be difficult for a multi-vendor product with third-party plugins, etc.
Assuming your samples are of duration T, and you need X CPU time to fully process a sample through all filters. Pipelining allows you to process audio with X > T, nearly X = N * T for N cores, but your latency is still going to be X.
If it is possible to process with small samples (T), with roughly correspondingly small processing time (X), there shouldn't be a problem keeping the latency small with pipelining. If filters depend on future data (lookahead), it is plausible reducing T might not be possible. Otherwise, it should be mostly a problem of weak software design and lots of legacy software and platforms.
You cannot run the pipeline in parallel. Sure you can have a pipeline and work the buffers on separate cores, but the process is serial. If it was as simple as you think it would have been solved years ago. There are really bright heads working in this multi billion industry and they can't figure that out. Probably because that involves predicting the future.
> These cannot run at the same time as the output of one feeds into another one.
This precludes parallel processing of individual packets, but does not prevent concurrent processing of packets.
Plugin A accepts a packet, processes it, outputs it. Plugin B accepts a packet from A, processes it, outputs it. Plugin C accepts a packet from B, processes it, outputs it. [...] Plugin G accepts a packet from F, processes it, outputs it.
Everything is serial so far. Got it. Here's the thing though: Plugin A processes packet n, Plugin B processes packet n-1, Plugin C processes packet n-2, [...] Plugin G processes packet n-6. Now you have 7 independent threads processing 7 independent data packets. As long as the queues between plugins are suitably small you won't introduce latency.
The mental model here should be familiar to anyone in the music industry; each pedal between the instrument and the amp is a plugin, each wire is a queue. Each pedal processes its data concurrently (but not parallel with) with every other pedal.
It's relatively common in game development for AI/physics to generate the data for frame n, while graphics displays frame n-1. (there's a natural, fairly hard sequential barrier separating physics from graphics, and there's a hard sequential barrier when the frame is finally shipped off to the GPU) Especially on consoles that have 8 core CPUs but each core is really slow. PS4/XBoxOne use the AMD Jaguar architecture, which was the mobile variant of Excavator. The single core performance of these CPUs are absolutely atrocious, but the devs make it work for latency sensitive activities like gaming.
> Data travelling from one core to another could mean additional performance loss.
Only if it is evicted from the L3 cache, and the 3950X has 64MB of it. That's over a second(!!) of latency at 16 channel+192kHz+32 bits/sample audio.
Speaking of channels, that seems like a natural opportunity for parallelism.
I get that legacy code is legacy code, and a framework designed to run optimally on Netburst isn't necessarily going to run optimally on Zen 2. (or any other CPU from the past decade) But this is an institutional problem, not a technical one. It sounds to me like somebody needs to bite the bullet and make some breaking changes to the framework.
> Everything is serial so far. Got it. Here's the thing though: Plugin A processes packet n, Plugin B processes packet n-1, Plugin C processes packet n-2, [...] Plugin G processes packet n-6. Now you have 7 independent threads processing 7 independent data packets. As long as the queues between plugins are suitably small you won't introduce latency.
The process is realtime so you cannot receive events ahead of time. It is actually running how you describe, but you can only process so much during the length of a single buffer. Typically solution is to increase the length of the buffer, but that increases latency or reduce the length of the buffer but that introduces overhead.
> Each pedal processes its data concurrently (but not parallel with) with every other pedal.
That's how it works.
> The single core performance of these CPUs are absolutely atrocious, but the devs make it work for latency sensitive activities like gaming.
I am talking about realistic simulations. You can definitely run simple models without latency, that's not a problem.
> Only if it is evicted from the L3 cache, and the 3950X has 64MB of it. That's over a second(!!) of latency at 16 channel+192kHz+32 bits/sample audio.
That's nothing. Typical chain can consists of dozens of plugins times dozens of channels.
There is no problem with such simple case as running 16 channels with simple processing.
> Speaking of channels, that seems like a natural opportunity for parallelism.
That works pretty well. If you are able to run you single chain in realtime you can typically run as many of them as you have available cores.
Different workloads have different IPC characteristics. A generalized benchmark like this doesn't really give any guidance on how fast a single core would be for audio processing.
But, as another person mentioned, this benchmark wasn't run at the full boost clock for the 3950X, assuming this isn't a faked result entirely.
Please excuse my lack of experience with audio processing, but...
What you're describing about the output of one plugin being fed into the input of another is analogous to unix shell scripts piping data between processes. It actually does allow parallelization, because the first stage can be working on generating more data while the second stage is processing the data that was already generated, and the third stage is able to also be processing data that was previously generated by the second stage.
Beyond that, if you have multiple audio streams, it seems like each one would have their own instances of the plugins.
So, if you had 3 streams of audio, with 4 different plugins being applied to each stream, you would have at least 12 parallel threads of processing... assuming the software was written to take advantage of multiple cores.
If the software is literally just single threaded, there's nothing to be done but to either accept that limitation or find alternative software.
I really think you should really wait until you see audio processing benchmarks before making dramatic claims like "It looks like I wouldn't be able to run my chain in realtime on this new AMD" based on a -3% difference in performance on a leaked benchmark of a processor that isn't even running at the full clockspeed. How can you be so sure that a 3% difference would actually prevent you from running your "chain" in realtime? But, based on the evidence available, the chip should do 9% better than the recorded result here (4.7GHz actual boost divided by 4.3GHz boost used in the benchmark), reversing the situation and making the Intel chip slower. Suddenly the Intel chip is inadequate?! No, I really don't think so. Even though Zen 2 seems like it will be better, I feel more confident that even a slower chip like the 9900K would be perfectly fine for audio processing.
> is analogous to unix shell scripts piping data between processes
Conceptually yes, but technically, multimedia frameworks don’t have much in common with unix shell pipes.
Pipes don’t care about latency, their only goal is throughput. For realtime multimedia, latency matters a lot.
Processes with pipes have very simple data flow topology. In multimedia it’s normal to have wide branches, or even cycles in the data flow graph. E.g. you can connect delay effect to the output of a mixer, and connect output of the delay back into one of the inputs of the mixer.
Bytes in the pipes don’t have timestamps, multimedia buffers do, failing to maintain synchronization across the graph is unacceptable.
I’m not saying multimedia frameworks don’t use multiple cores, they do. But due to the above issues, multithreading is often more limited compared to multiple processes reading/writing pipes.
I think you're correct on both counts. With the plugins running on separate cores, they wouldn't be trashing each other's caches or branch predictors, so they might actually run faster and offer lower latency than stacking them all onto a single core... but odds are low that the difference would be significant.
The main advantage is that you wouldn't be limited in the number of plugins you could run by the performance of a single core, since you could run each plugin on its own core, like you mentioned.
Obviously, having faster individual cores means that each plugin introduces less total latency, but the difference in single-threaded performance between Zen 2 and Intel's best is likely to be very small, and I fully expect Zen 2 to have the best single-threaded performance in certain applications.
You wouldn't want to run a plugin on each core, you would want to run a chunk of samples on each core. Then the data is staying local (and the instructions aren't going to change so they will stay cached as well).
Single core performance is the only reason I chose Intel this time around.
Even though I do a lot of docker and some rendering and Photoshop - most development tasks, docker builds, and even most Photoshop tasks that aren't GPU accelerated are bottlenecked on single core performance.
Same goes for the overall zippiness of the OS. The most important thing for me is that whatever I am doing this moment is as fast as possible and single core performance still rules since most software still does not take advantage of multiple cores.
For the next home server though, I am definitely planning on a high core count AMD.
I would add though, that all the new processors are getting so fast, that the difference in single core performance is probably not noticeable. Your main issue would be long running single core tasks which are generally more likely to be multithreaded.
What kind of workflow requires so much power? I haven’t touched audio in a while, but back in 2012 I could already comfortably run layers upon layers of processing per track, I would have imagined any current processor is more than up to the task.
I am struggling with i9 9900k running @ 5.1GHz. Plugins that process signal with extreme accuracy require a lot of power. It's like with game - your PC probably wouldn't struggle with running many instances of Solitaire, but multiple instances of GTA V with ultra details could be problematic.
Can you share what kind of plugins? Is it music production? I recently got a 6-core Mini thinking it would be overpowered for Logic Pro X... now I'm worried.
For example, recently released IK Multimedia T Racks Tape Machine collection. One instance of the plugin takes about 15% of one core. In a large project this is a lot and you need to think where to use it or use freezing. Then you have a suite of plugins by Acustica that use a variant of dynamic convolution (volterra kernels) to simulate equalizers, compressors or reverbs. Virtual synthesizers like Diva in pristine mode and enabled multi core can also take a lot of resources. You really need to budget what to use where so that it won't break up - which is a skill in itself, that hopefully in the future won't be relevant as much.
> You really need to budget what to use where so that it won't break up - which is a skill in itself, that hopefully in the future won't be relevant as much.
I totally agree with this. I can't stand having a resource limit on creativity when I'm making music. What's worse, is even if you get dedicated hardware (DSP chips, etc.) they are normally designed for specific software, and aren't (and likely can't be) a 'global accelerator' for all audio plugins, regardless of the developer.
I was surprised that Apple demoed the new Mac Pro not with video editing but with audio editing/generation/whatever it's called. Guess there are quite a few performance hungry audio applications out there
How does 16 core Ryzen 9 3950X have the same TDP as 12 core Ryzen 9 3900X (105W)? It even has higher max boost frequency. Is it just because of lower base frequency?
TDP doesn't tell you what the actual power consumption in practice will be. It is defined in some weird ways (different between manufacturers), and generally not intuitive. I would recommend to avoid trying to read too much into the TDP, wait for actual measurements of power consumption.
My understanding is that typically the TDP is designed to fit to the base clock of the processor, and doesn't necessarily include the amount of power necessary to achieve the boost clocks.
Anandtech do a deep dive on how Intel calculate TDP numbers [0]. It's complicated (and completely different from AMD, so never try to compare numbers).
Interesting, thanks! From that article, Intel's TDP is roughly equal to the power draw during full load on base frequency. How does AMD define it then?
I've read some in-depth analysis of AMD's calculation somewhere too, but I forget where. I do remember that the TDP numbers on AMD are closer to maximum power draw.
Never investigated GPUs. One way to find out would be to trawl Anandtech reviews and collect TDP and measured power draw numbers, they always take measurements.
It is just different "class" of CPU power usage and cooling, not their actual Power usage. So if you have a 105W cooling system both CPU should be fine.
This is different to Intel's TDP which meant Typical Design Power, i.e Power usage when running in base frequency, in reality they run quite a lot higher.
Boost frequency is not related to TDP. Just because a processor says it can hit a maximum boost of 4.7 GHz doesn't mean it can do that with all cores active and stay within the TDP. It may not even be close. Base frequency is what is tied to TDP, hence the 300 MHz drop for the 16c model.
TDP is the maximum thermal power in watts that gets generated as waste heat that needs to be removed. A processor can consume 50 watts, but produce 100 watt waste heat, another processor can consume 400 watts and produce 100 watts of heat. Both have 100w TDP, but one consumes 150w, the other 500w. This is why TDP doesn’t tell the full picture.
Because Ryzen 2 is manufactured on 7nm, it’s extremely efficient in that it doesn’t convert its energy into waste heat. Both 3900X and 3950X are designed to produce no more than 100 watts of heat. But of course, that doesn’t say how much current they actually draw under full load. That specification is the key and is very hard to find.
When these chips are released, you will likely see reviews that measure the total system power, that is the power CPU draws plus PSU inefficiencies, VRM inefficiencies, motherboard component inefficiencies, on top of all the power ram, ssds, and everything else uses. So it will not be an accurate measurement, but it will give you an overall sense of how power hungry it really is.
AMD CPU designs have historically been very power hungry, and I expect the new ones to be no different. Looking at how their 7nm GPUs compare against RTX in power consumption leads me to believe the 3000 series will require quite a bit of juice.
Why do you think Apple hasn't moved to AMD cpus for its Mac products?
In the past I thought maybe the rumored move to ARM could be the reason, but now with the new Mac Pro I doubt Apple will move to ARM except for some of its laptops.
That Apple have married themselves to Thunderbolt (co-developed by Apple and Intel) may have had something to do with it. Previously Thunderbolt was not well supported on AMD platforms, as I understand it. This appears to be changing though.
Thunderbolt has been an open standard (and now royalty free) for some time. I'm sure if someone as big as Apple wanted to adopt AMD that was the only blocker, it wouldn't be a blocker for long.
AMD having one good generation doesn’t mean anything when Apple signs multi-year deals. They aren’t HP/Dell/Lenovo who will just contract Foxconn to make a bunch of different boards with standard chipsets to satisfy consumer demand, instead focusing on a tightly integrated platform that they won’t throw away willy-nilly.
If AMD can keep it up this time (or Intel keeps flopping) then it may very well happen down the road. Until then, the age old investor relations statement rings true: “past performance is no guarantee of future results.”
Note: I have a Ryzen 5 1600 in my gaming rig and a Ryzen 5 2600 in the wife’s, I love these chips - but I also see the reality of Apple’s ecosystem is all.
As a AMD stock holder I have not forgot. My opinion still stands.
I have not seen a time I can recall where AMD has been competitive in every vertical against INTEL, not only in PRICE, but node, IPC, single core performance/multicore core performance, and manufacture scaling of several core cpus.
"Competitive" does not ever mean "uncontested". It means the trade-offs are reasonable. Choosing Intel after Zen was released meant making trade-offs -- giving up advantages, such as losing a large amount of multithreaded performance and paying a much higher price, as well as having to disperse more heat at maximum load for the chance at that lesser performance.
Just the same as choosing AMD would involve trade-offs in terms of a very slight loss of single threaded performance, or a higher idle power consumption, particularly in laptops.
In either case, you have good options. Neither product is completely devastatingly useless for any task, as was the case with Bulldozer, which had single threaded performance that was nearly half that of Intel's.
With the release of Zen, there was no longer a clear market leader dominating in performance of all classes, or pricing, or whatever other metric you want. That's called "competitive."
Zen 2 looks like it will be "uncontested." It will have the advantage in essentially everything, including single and multithreaded performance, gaming performance, power consumption, and price... if AMD's benchmarks are to be believed. The general sentiment is that AMD's benchmarks were actually conservative.
The benchmark leaked above in this thread is not running at the production boost clock, which would be 9% higher than the benchmark given, making it theoretically uncontested.
Obviously, we will have to wait for extensive third party benchmarking, but Zen has always been competitive, immediately and unequivocally reducing Intel to merely being competitive as well. Zen 2 has the opportunity be more.
No I didn't. I've even been very happy with my 2700x after a decade of using Intel. But this is a very recent development in the grand scheme of things, and AMD isn't really pulling ahead of Intel until Zen 2 launches next month.
They've not had the IPC of Intel for Sometime (I haven't owned an AMD CPU since the Athlon days, even though I was a fan of AMD as they were better value than Intel).
Where AMD does compete is thread-count. A higher number of slower cores did feel a few niches. Except... Many software vendors charge per core (a Windows Server License is limited to 16 cores), so fewer, faster-cores work out better value for most business users. Plus, power usage is a huge issue in data centres, again favouring Intel.
The biggest problem right now is virtual machines can't move (live migrate) from Intel to AMD hardware (and vice versa) without having to be restarted. So AMD is only really a viable option for new clusters, but I would think Intel is still nervous.
Zen+ has about the same IPC as the Intel processors from when it was released, the problem was just lower clockspeeds. The single threaded gap was somewhere around 5%, not the 40%+ of Bulldozer.
Zen 2 raises IPC by 15%, and raises clock speeds by a solid 10% or more. Single threaded Zen 2 performance is not even a slight concern for me.
Add 9% to the benchmark result this entire thread is about, because this engineering sample was not running at the specified boost frequency that the 3950X will have. Intel has nothing to compete against that... it should be uncontested.
On Epyc, their clock speeds were generally comparable to Intel's, and the single threaded performance was already great there, except for a few specialty processors that Intel released for servers that don't care about high core counts. Epyc 2 stands to completely annihilate any advantage Intel had left.
AMD Zen has always used less power than Intel for each unit of work done, which was one of the original surprises, so... power consumption is absolutely not favoring Intel.
I really feel like you're mentally comparing to the old Bulldozer Opteron processors, based on the concerns you listed.
AMD did have a huge amount of catching up to do after Bulldozer. One of the things that has been keeping Intel ahead is their fabrication has been going smoothly, generally ALWAYS ahead of what AMD had available to them. Here's the first article I hit (AMD loses on both idle and load): www.anandtech.com/show/11544/intel-skylake-ep-vs-amd-epyc-7000-cpu-battle-of-the-decade/22
Intel seems to be in a perfect storm, while AMD seems to have all their ducks lined up (architecture, Fabrication Process, clock speeds).
Still, exciting times! Intel has stagnated on quad-core enthusiast CPUs for a decade (Q6600 - 7700k), it's good to finally have some competition again.
One reason Apple has given in the past was they needed reliability for large quantities of supply. Intel had better fab capacity then, so Intel it was.
Now that AMD is using TSMC and/or Global Foundries, not sure if still the case.
- Don't want to rely too much on a single manufacturer (they already use AMD GPUs). Always keep multiple supplies alive/well.
- Don't take away too much from Intel to not affect other components (they were in the game for LTE modems which Apple needed/needs)
- How good are integrated intel vs amd gpus? Could play a role as well
Agreed though, 10 Years is a much longer timeline than what current leaks are rumoring, which is 1-3 years.
Currently in fanless environments (Such as the iPad Pro) the latest CPU, A12X, outperforms Intel's fanless offerings by a good amount.
I would imagine that Apple could build like performing parts if not better using current A12 Tech and don't forget that Apple is already using TSMC's 7nm process. Additionally, Apple could make sure of big.LITTLE in varying sizes to bring large power consumption advantages to Macs as it stands, along with their Neural Core.
Let's assume in 10 years a descending order of the best laptop cpus are 1. Future ARM 2. Future AMD 3. Future Intel.
When I say leapfrog I am implying that I believe this list to be correctly ordered and that Apple will not use AMD chips but wait until they can use ARM.
Because this type of things are a +10 year commitment and Apple wants stability, they can't risk their whole Mac product line if AMD makes another Bulldozer dud.
AMD is clearly better now, but Apple just needs the CPUs not to suck, so Intel it is.
Pretty stoked about what AMD is doing. Even if these benchmarks are inflated, it's an amazing bang for your buck and you can build some really solid budget machines. The next generation with PCI 4.0 looks extremely promising. I wish they'd concentrate on pressuring motherboard companies to make more professional non-server boards for the Ryzen 9 chips.
thunderbolt: in some motherboard: "The ASRock X570 Creator is focused towards content creators with a range of high-end features including 10 G LAN, support for DDR4-4600, and dual Thunderbolt 3 Type-C ports. "https://www.anandtech.com/show/14461/made-for-creators-asroc...
Unfortunately there's no news of threadripper for Zen 2 yet. Hopefully we'll hear something about it sometime next year. The assumption is they're using all their initial production capacity for consumer-grade (Ryzen) and server-grade (Epyc) chips first.
I went with a ryzen for my newest desktop and it’s been great so far, I love it.
Not only does it work well, but it fixed the issues I was having. I used to have shutdown took 5-10 minutes due to some systemd nonsense, mysteriously fixed with the new mobo and cpu. Definitely a plus to have it gone now.
Tested with Ubuntu and also windows, Keras and games.
I think it all depends on if ThreadRipper gets a new socket. Matisse is 2 channel DDR, Threadripper is currently 4 channel, and Rome, the new server platform, is supposed to be 8 channel.
Using the Rome platform unmodified means 8 channel matching DDR4 kits for consumers. Re-using Matisse silicon glued together makes next-gen ThreadRipper into a NUMA device. Maybe AMD has an I/O die just for the low volume ThreadRipper in production. Hopefully, AMD will just harvest Rome I/O dies for ThreadRipper and tease us with 32, 48, and 64 core models that work on the existing TR4 socket.
I'd suspect that TR.next will be somewhere in between. The MMU for TR based closer to Epyc, while having more chiplets than Ryzen, but at close to the same clocks (higher than Epyc, less than top Ryzen, and less but faster cores than Epyc). Probably top binned from Ryzen and Epyc for chiplets, but low binned from Epyc for MMU.
3950X and the single socket versions of new EPYC chips aren't NUMA. Instead of each CPU die having its own memory controller there is a central I/O die with an IF link to each CPU die.
This was true up until now, but the upcoming 3900X and 3950X have 2 separate dies ("chiplets"). I assume this means it will have the same architecture as the current TR 2920X and 2950X.
Edit: opencl post above says apparently not, it's a different memory architecture.
The 2 smaller chiplets are for core complex, the memory controller is on the IO die(the other bigger one) that these 2 CCX share. So there is still one single memory controller, and hence, not NUMA.
AMD processors have so far been immune to all but one attack and in the previous gen processor the mitigation caused a 2% performance hit. This gen has specific hardware for mitigating these side channel effects so the numbers you're seeing are with the mitigations.
I think the parent comment is asking if the patches have been applied to both chips in the benchmark. Yes, AMD perf will be largely the same but comparison between patched and unpatched will be different.
If you're already on a 16c Threadripper, it may be worth it... presuming the shared IO/Memory controller carries over, it'll have much better throughput on memory constrained workloads that bottleneck with NUMA.
Why? Threadripper is for workstations, Ryzen for consumers. Core count does not have anything with that. There was 8 core Ryzen along with 8 core Threadripper in the past.
I'm out of the loop. Why is single core performance important, since no one (I think) buys a multi-core CPU just to limit themselves to using only 1 core?
What makes you think anyone limits their computer to run only one core? I'm flabbergasted.
Many people choose the CPU that has the highest single core performance, for both gaming or real-time multimedia processing.
Games are usually optimized for a single core, or a low number of cores, not to use all 4 or 6 or 8 cores of a system. Therefore, for gaming single core performance is still very important.
You can read some opinions about people still choosing Intel because of single core performance in this very discussion.
Additionally, modern CPUs move running threads among cores to avoid a single core from overheating. It's a strategy for thermal management.
I wish it wasn't but I'm tired of seeing many processes locked at 12% CPU i.e. one core. Granted I mainly use old software. If you recode video or play modern games I assume it's better. But by now I'll keep judging the worth of a CPU by its single-core performance.
You just said something in general, then replied about "for you".
There are millions of PC gamers and video encoders and multi-workload users. If you're running intense, non-multithreaded workload and need the absolute best without caring about security (Spectre/Meltdown) or cost, go Intel.
I'll agree even for video games, single core performance matters a lot. Most workload that can use multiple cores are on the GPU. Whereas the main event loop will be single core constrained. Maybe AI. But Again AI should be on the GPU or dedicated chip.
I do software development, and video reencoding mostly... For dev, I've usually got 2+ databases and several background services running. For reencoding, the kids' Ryzen 2600 is faster than my now aging i7-4790K w/ 32GB.
Likely going to this 3950X or the next ThreadRipper (will depend on TR news/release timelines in the fall)... been holding out for a while as I knew this gen Ryzen would be a big bump.
{kind=link}
{kind=link}
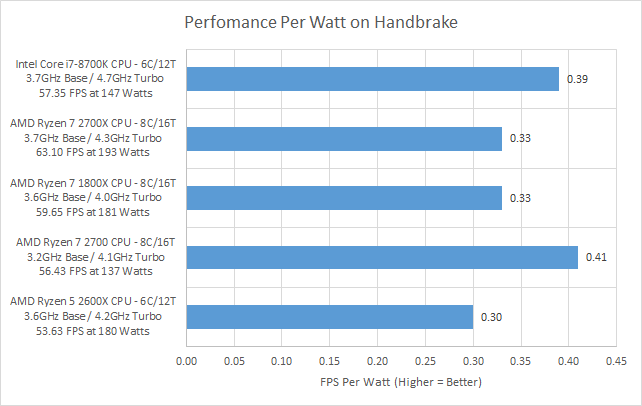{kind=link}
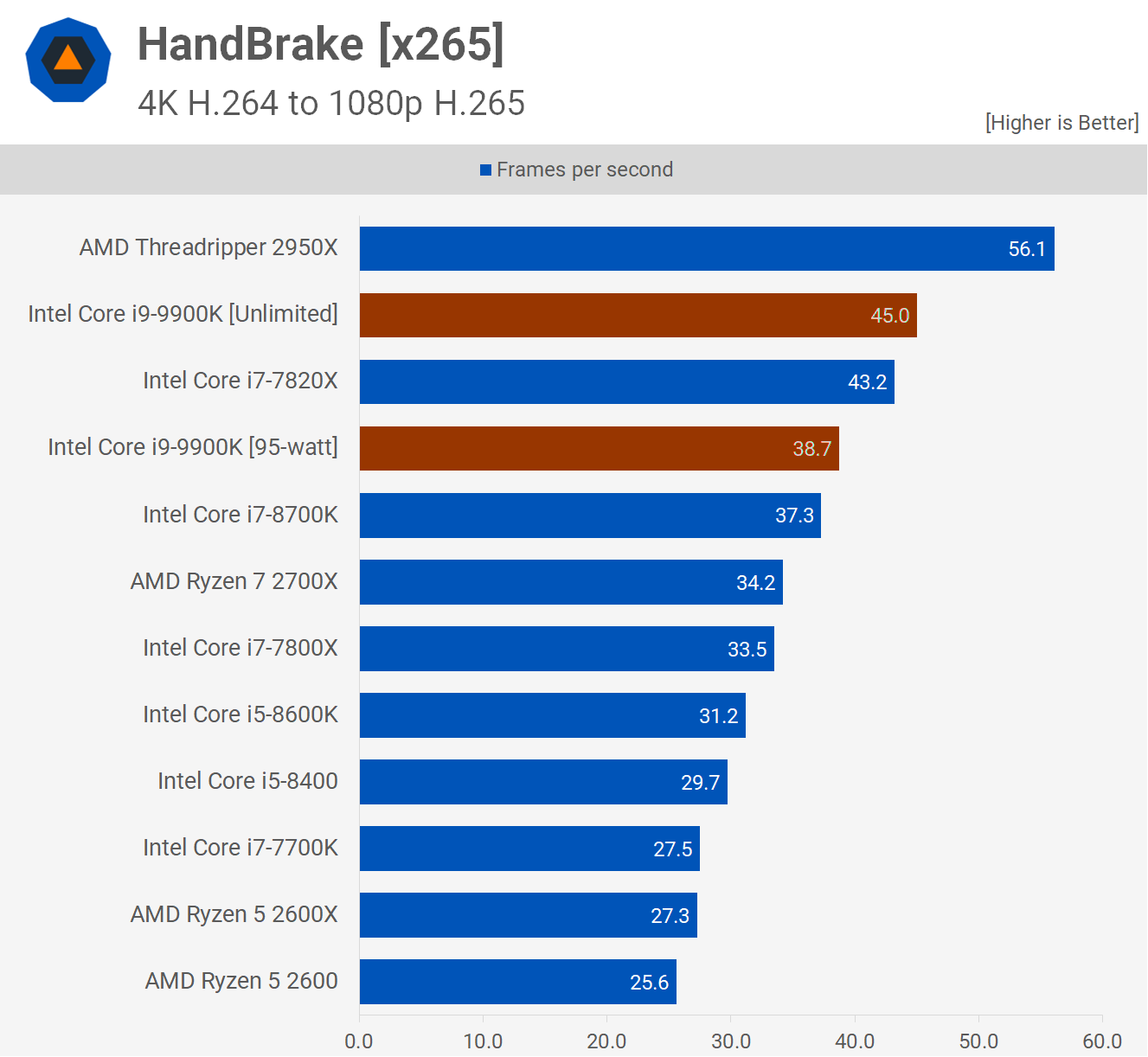{kind=link}
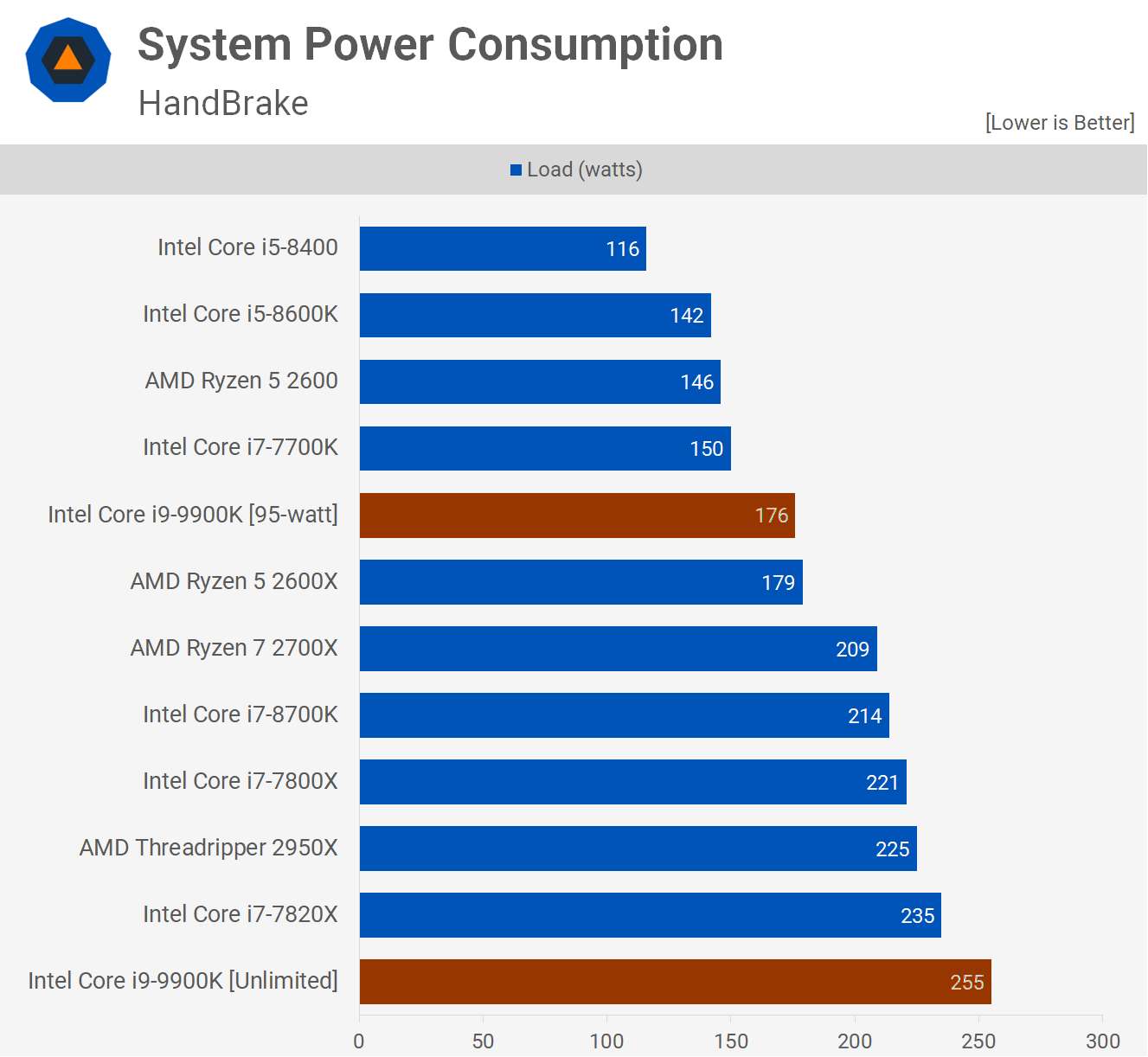{kind=link}
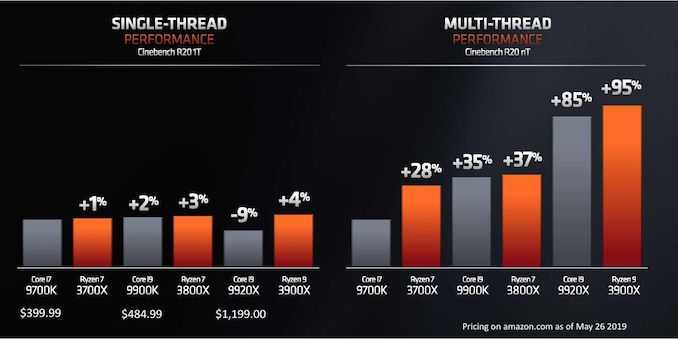{kind=link}
{kind=link}