4 dies per package is a pretty interesting way of doing things - probably helps yields immensely, but I can't imagine it does anything good for intra-processor latency. 142 ns to ping a thread on a different CCX within a die isn't too horrible, but I really want to know what sort of penalty you'll have from going to a different die within a package.
I think it's less about yield, than it is about amortizing a large R&D budget across more chips. Keep in mind that they are competing with Intel who ships huge volumes and is using this generations profit to fund the next generation fabs.
So AMD pours everything into a single die and manages to hit the desktop (Ryzen with 1 die), workstation (thread ripper with 2 dies), and server (Epyc with 4 dies). All with a single wafer of silicon, and as a bonus the memory bandwidth, max memory capacity, and total number of cores scales to fit all 3 markets.
Pretty crafty. This is far from new of course, various Power CPUs, Intel cpus as far back as the pentium pro, and of course the previous generation Xeons.
Intel's strategy has been one die for most of their low end/low power chips (max 2 core/4T) and a larger die for their desktop (max 4c/8t) that use the same socket (LGA1151).
Then Intel targets HEDT (High end desktop) and server with the same chip, same die, same socket, just marketing to differentiate the x-servies chips and the regular single/dual socket chips that share chipsets, sockets, and a lga2011 socket.
AMD seems to have scared Intel pretty bad. They have held off on the skylake xeons, only shipping them to cloud providers while they wait for the AMD release before releasing skylake xeons to the masses.
I'm glad to say AMD performance seems pretty good, SpecINT (using GCC) is around 50% faster than the similar Intel chip and SpecFP is even better. Seems fair unless you use the Intel compiler to compile all your binaries anyways. In fact the fastest AMD + gcc-6.2 is faster at SpecFP than the fastest Intel + Intel's compiler (1330 vs 1090 respectively).
Intel also shares dies across their laptop and desktop lines. I'm not sure how many dies there are, but they don't have much more than a 2 core and a 4 core version of each generation of silicon.
Skylake generation servers will have at least three different cores (LCC, HCC, XCC; low core count, high core count, and extreme core count) + a Xeon-D successor (presumably).
That's a desktop chip rebranded as Xeon, with a different set of feature flags. The server chips are a totally different beast, with many more cores, dual socket support, network on chip, AVX 512, upgraded connectivity etc.
These are different skylake xeons. Skylake E3 were available in 2016. They are limited to only 4 cores. The OP refers to the server-grade Skylake Xeons, previously referred to as E5 and E7. They will reach a lot higher number of cores.
Is there any Intel core with 128 PCIe links then? I'm not aware of any. Iirc Intel is at 40 lanes / socket, which is more like 10 per core rather than 128.
No, because if they did it would be wasted. Board manufacturers wouldn't lay out all of those lanes to slots because of the increased expense and limited market at that pricepoint that's interested in saturating all that I/O.
Intel did the same thing with their first Core 2 Quad processors. The Kentsfield generation may have had more limitations to it's multithreaded performance than the single-die Yorkfields but the performance penalty was so negligible that dual-die chips like the Q6600 stayed relevant as long as the next generation of single-die successors.
I forgot the Q6600 was dual-die, probably the best bang for buck CPU I've ever purchased (first popular quad-core & huge overclocking potential).
I think AMD reusing the same dies is quite elegant (everything* scales as you add more cores). The inter-die bandwidth/ latency shouldn't really be a problem, because if more than 8 cores are dependant on the same data - locking issues would make any additional cores useless anyway. If they can get NUMA tuned correctly things should work nicely.
*it's strange that they all have the same amount of L3 cache.
Does anybody have contacts with AMD's marketing/ engineering department who can provide test units?
Maybe AMD pulls something akin to the "Iris chip" from Intel and makes L4 standard in a few years. Speaking of which, never understood why Intel wouldn't push a bit more for Iris, when used as L4 it gave close to 20% increase in performance (due to lesser cache mises I believe).
When Intel did the dual-die thing with Kentsfield, AMD mocked them for not being "true quad-core" and refused to follow suit. They had quad-core dies back then, so they could have easily hit back with an 8-core part if they swallowed their pride and put more than one die on a chip! I think it was a terrible move, just when AMD was starting to become irrelevant again.
10 years later, Intel sticks to single-die chips, and AMD has no qualms stuffing a gazillion dies on a chip. Looks like they've learned a lesson or two :)
I think taking that approach can lead you astray. If you think of it as an "easy" way to build a four socket motherboard using only one actual socket it might make more sense. The "sweet spot" for the old Opteron was 4 CPUs (4 socket). You got to trade off parallelism, memory locality, and a bit of cache thrashing but you could run rings around the Intel offering at the time. Unfortunately it was both expensive and hot to run, this works out much better with regards to total system cost.
Well it's one hop over the in package Infinity Fabric which presumably should be less than the cross the package Infinity fabric.
From my understanding though chip A in socket 1 is directly connected to chip A in socket 2. So the worst case would be chip A in socket 1 to chip B, C, or D in socket 2. I don't think that number is public yet.
It is probably to differentiate motherboards. You don't want the consumer to plug in Epyc into Threadripper's mobo and complain that there is not enough PCI-E lanes or memory channels.
I would really love it if there was a benchmark around running VMs and containers for something like this. Our dev/test system is all docker containers so that is what we would care about.
I guess it would be hard as there are to many ways to scale out what you run - how many VMs, how many containers, what are you running in them? It would be an interesting benchmark matrix to sort for.
It would be interesting just to see how many containers you could start, run lighttpd and each server a static web page? Maybe 1/2 with the page and 1/2 with an application that builds the page? Who knows...to many variables.
I think we will just by a system when we can and try our workload on it. Oh, well.
I don't think running processes inside a container will be any more interesting for benchmarking than just running the processes normally. What overhead does a container add? A little indirection in syscalls? I would imagine the number of instructions involved in that are beyond trivial for serving a page, so I can't see how benchmarking running containers would be different than just benchmarking running your processes.
VMs - now with processor virtualisation technology I'm sure the different processor architectures do make an interesting difference there.
In some of our scaling test where each container had an IP connecting out to a remote system we ran in to a ton of issues at scale that we did not see running the same number of processes on the bare metal. The overhead of the namespace can add up.
The issue had everything to do with how Linux handles networking when you have 1000 container interfaces on a single system. Tweaking net.ipv4.neigh.default.gc* solved most of the issues.
I am familiar with Calico and it would not have solved it.
The difference being of course that this 4.8-second compile in 2002 was done on an IBM p690 which cost half a million dollars. Whereas the 15.6-second compile was done on the EPYC 7601 which is only $4k for the CPU, ~$6k for a whole machine.
Last response from AMD: "The vast majority of users using Ryzen for Linux code and development have reported very positive results. ... A small number of users have reported some isolated issues and conflicting observations. AMD is working with users individually to understand and resolve these issues."
I doubt there's any single root cause here. "I get crashes when running big compiles" is a classic symptom of hardware that is almost, but not quite, stable. This can be due to power delivery problems, thermals, marginal RAM, overclocks, faulty CPU (yeah, it happens sometimes) and so on.
There used to be a long running joke (I think perhaps Linus even coined it?) that the kernel codebase grew about as fast as CPU performance improved. I guess that died around the time AMD released their dual core CPUs..
It seems reasonable, considering anyone working on it enough to need to recompile would have a minimum change time correlated with compilation time. (Incremental compilation aside)
Going to get a cup of coffee takes the same amount of time as it did 15 years ago, so devs still need a compile time which is roughly equivalent. 15 seconds would be much too fast, for example.
I'll admit the endless compiling was often torturous, but I have the Gentoo docs to thank for most of what I know about the innards of Linux and operating systems. Bet I'm not alone in judging the time spent worth it :)
No, I'm sure lots of things have changed. More of the code would be using C99 semantics now, and I have no idea how GCC would have improved or regressed since then. It's possible that it's trading improved runtime performance on ever-more complex hardware for longer compile times.
I see that gnu89 is the default, to avoid compatibility problems with older code, but does that mean there is no code in the kernel which requires gnu99? I saw some work was done to make the whole kernel gnu11 compatible as well.
I still remember doing a make world on FreeBSD on a 75MHz Pentium. Went out for the night and it was still going when the hangover wore off the following afternoon. This was mainly because it spent most of it's time swapping.
You know, I had a desktop build of a similar vintage (late 2008) until recently. High quality for the time - C2D E8500 with 8GB of RAM, newer SSD and video card.
I said exactly that, "things haven't changed much since then". It ran well and all, and never overtly irritated me.
But the newest round of affordable mid-high end CPUs is a huge upgrade. Same with SSDs, even compared to ones a few years old. It's one of those things you don't really realize how big the difference is until you use them back to back.
I had a Q9300, and than upgraded to some i7 because I needed more slots on the motherboard. I was very surprised by how much quicker the whole system was, even if I was under the same impression, that in the last years things didn't change a lot.
CPUs get faster by around 20% per year, but in 8 years this can get compounded a lot.
I am in a similar spot with a 7-year old, 6C/12T overclocked Xeon W3680. If Threadripper frequencies are decent it might finally be time to join the current generation of hardware. I would "settle" for a 12C/24T Threadripper if it were clocked as high/higher than the 16C/32T version, and at the right price point (ala the Ryzen 1600X). Doubly so if Intel follows through on opening up Thunderbolt licensing and I can add a Thunderbolt 3 expansion card to a non-Intel system in the future.
Optane isn't interesting, and while I have a fascination for AVX512 from discussions with a friend who does HPC, I know I concretely won't use it most of the time. The only unique thing that Intel offers me right now is Thunderbolt 3.
Threadripper is a 2-chip module rather than 4, so will have half the L3 cache.
Threadripper has half the memory channels and half the PCIe lanes.
EPYC is available with up to twice the cores.
The main advantage I see for Threadripper is that at 16 cores EPYC will have half the cores disabled, so for problems that fit in L2 you lose some performance from the reduced L2 sharing. That and it should be priced better than server chips, with I suspect the 12 - 14 core being the sweet spot.
Based on leaks I think Threadripper might boost a few 100 MHz higher, with base clock up to 3.6GHz.
I would not be surprised if there will be no 14 core part. None of the Zen based CPU's so far have a uneven CCX configuration but 14 cores would require that.
The Ryzen 5 1600 and 1600x have two CCX modules with 3 cores each (one core disabled on each CCX). So it wouldn't be impossible for AMD to make a 14 core part.
Yes, but what I meant is uneven CCX. The 4 core parts have 2+2, the 6 core parts have 3+3, the 8 core parts have 4+4. There is no uneven CCX combination like 2+4 for example.
If this applies to multi die solutions like Threadripper, there will be no 10 and 14 core parts as they would require uneven CCX combinations.
If the Epyc lineup is an indication this might be true. Especially since there is no 12 core part for Epyc. Since it has 4 dies you could produce 12 cores by using only 3 cores of each die, but this would require uneven CCX (1+2 or 0+3).
I suspect that uneven configurations aren't allowed. IIRC, in the die each core has a direct link to the same core on the other CCX, a direct link to the same core on the other dies in the MCM, and a direct link to the same core on the other chip if in a 2P motherboard.
IOW core #13 is the 5th core in the second die, aka the 1st core in the second CCX on the second die. So it would have a direct link to the 1st core in the first CCX on the second die, as well as a link to the 5th core in the other 3 dies as well as a link to the 13th core on the second chip if in 2P.
So it seems quite likely that all 16 CCX's in a 2P server must have the same number of cores.
Hm? L2 is per core. Always has been in a three+ layer architecture.
Zen has 512K L2 per core and 8M L3 per CCX (two CCX per dice). L3 is a victim cache iirc, unlike previous generations where the L3 was inclusive.
Intel usually went with a similar scheme in the last few years, where the L3 is partitioned into slices assigned to cores; accessing the local slice is faster than a non-local slice. Skylake-SP deviates from this (significantly), for better ... or worse.
L3 is a victim cache? Intels L4 is the victim cache for their inclusive L3. How does that work? And their L2 is basically a buffer between their L1 and L3.
That doesnt make sense to me. I can't find any good info on this.
I think Threadripper will have 2 chips per unit instead of 4 like Epyc. That should make them smaller and cheaper. If so it would mean that making motherboards would be simpler so those would be cheaper too.
I think AMD also stated there will be no dual CPU Threadripper setups. so the CPU interconnect stuff also won't need to exist on threadripper motherboards.
They're marketed as different sockets, so I wouldn't be surprised if that does not work. E.g. because a SP3r2 motherboard doesn't route power to unpopulated dice on the module.
Past experience suggests it's very likely they will be compatible, at least at a basic level.
See eg. or Socket 'L' vs. 'F' in AMD's history (hint -- they're the same thing), or the various Socket 2011 Intel iterations across server/enthusiast markets.
You may lose out on some features (eg. RDIMM support with server CPU, overclocking support in either direction, etc.)
Untimately, I hope, the cross-compatibility of EPYC CPUs on enthusiast chipsets will be a decision for motherboard manufacturers to make, as it has been in the past. 64 PCIe lanes should be enough for... at least some of us ;)
ETA:
As parent mentioned, the situation this time is more complicated.
Threadripper in an EPYC board is likely to be problematic -- the CPU doesn't have enough PCIe/Infinty Fabric connectivity to allow CPU links and PCIe to be active simultaneously. Even in a 1P system, only half of the board's potential PCIe lanes would be available. Due to these issues, it's likely such a setup may not be supported. It would be a strange thing to try in the first place, however, especially if equivalent EPYC parts end up similarly-priced to Threadripper.
EPYC in a Threadripper board is the news I'm hoping (and expecting) to be better -- the parent talked about powering the extra dies... an interesting consideration, though I expect (and hope) the only pins which won't be broken out on a Threadripper board will be the extra PCIe lanes.
Those TDPs look pretty high, what are vendors willing to put into 1U high 0.5U wide style servers with 2 sockets these days? Last I looked I seem to recall it was around up to 145W.
Keep in mind that AMD puts more on chip than Intel, so you should look at system power, not socket power. The comparisons so far I've seen show AMD doing as well or better than Intel on perf/watt.
Granted the AVX2 performance of the Zen processors is intentionally crippled. It's more of a software compatibility implementation than actual performance boost.
Agner on microarchitecture [1], page 213, another mention as a bottleneck on page 216:
The Ryzen supports the AVX2 instruction set. 256-bit AVX and AVX2 instructions are split
into two µops that do 128 bits each.
AVX2 increased register width from 128-bit (AVX) to 256-bit, yet Ryzen cores can only process them 128-bit at a time. There is more to AVX2 than just width but that means in comparison to Intel processors, which can do the full 256-bit in a µop, the Ryzen throughput will suffer in tests that heavily emphasize AVX2 instructions (think video encoding).
not sure if they play a role in designing CPUs, but AMD says that their Zen CPUs have a neural network inside for branch prediction [1] which is not something new [2] [3]
CPU layout and routing optimizations are global discrete optimization problems. Neural networks don't have much edge on these problems. Simulated annealing is the most used optimization method in routing and layout tools.
There are number of research papers that attempt to use neural networks for combination optimization, but no interesting results.
In the designing of CPUs or if they are designed for running various neural networks? Because Nvidia seemed to be building giant products aimed pretty much exclusively at that. Google has their own "TPUs" for that. Intel's next Phi is designed for running that stuff.
As for the design of CPUs, they do some automated layouts and some things like that, but I think that might not be what you mean.
Yes, i mean in the designing of CPUs. Like transistor layout. It seems like a big problem space where optimal arrangement is hard to find. So i wondered if people trained NN to do that.
A compiler does a lot of AIish things in turning my C code into a sequence of instructions. Much more classical AI than machine learning but still within the AI umbrella.
I was referring to the RTL-based IP that goes into each subsystem of the CPU, hence the analogy to code. You're talking about compiler instruction scheduling, a lot of which are a bunch of non-AI algorithms. If I'm missing something, I would appreciate the references to the functionality you're referring to.
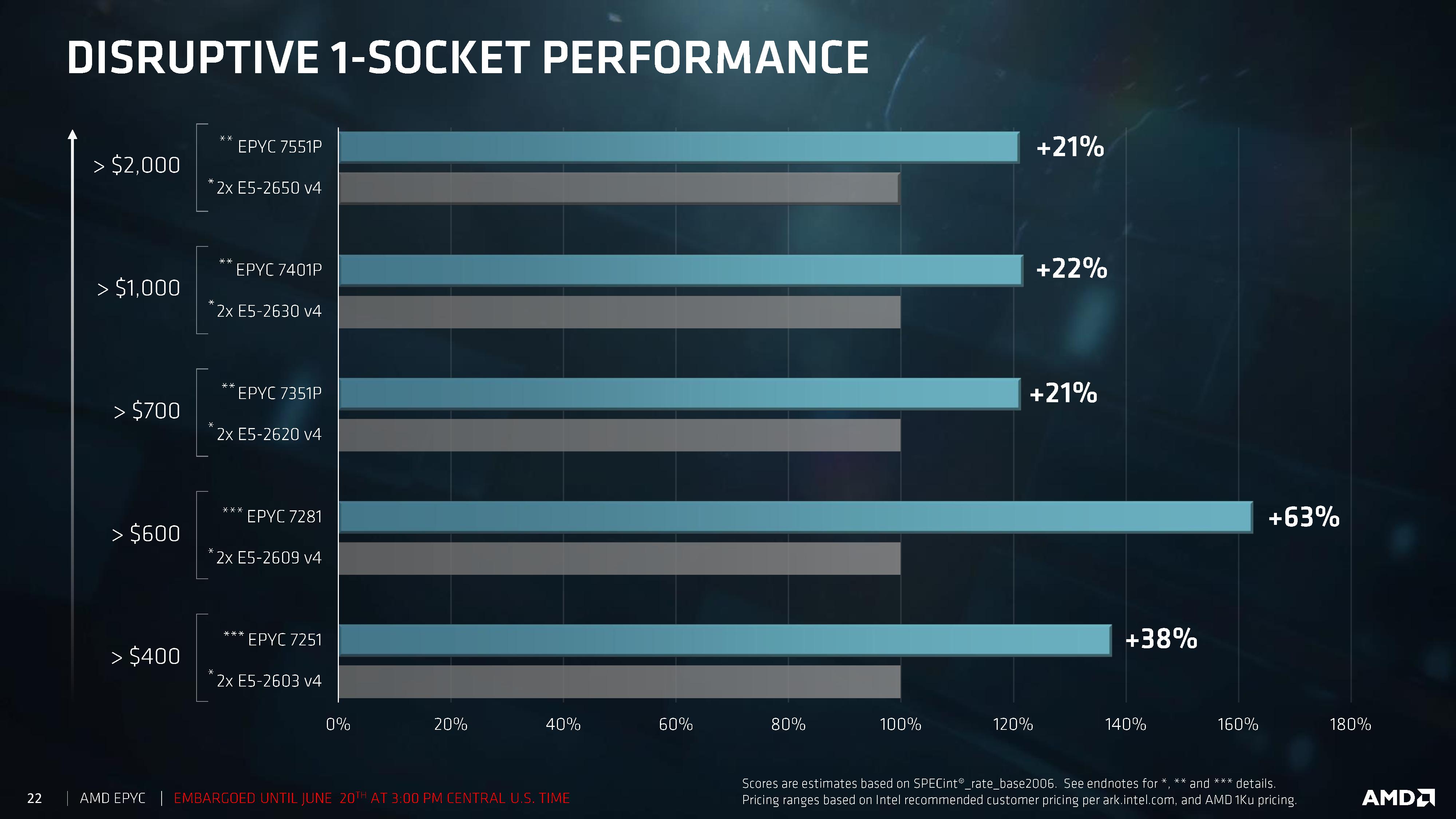
I think the idea is that single-socket EPYC CPUs beat many Intel dual-processor setups. If you break it down by sales numbers, a single EPYC might beat the most popular dual-Intel platforms. http://images.anandtech.com/doci/11551/epyc_tech_day_first_s...
The lower end dual socket E5-2xxx are the most popular servers. AMD claims they can win on performance, match or beat maximum memory, and win on perf/watt when comparing a single socket AMD to a lower end dual socket Intel.
Seems reasonable to me, I'd consider getting a quad system in 2U amd system with single sockets if it beat price and perf of a quad system in 2U intel system with dual sockets.
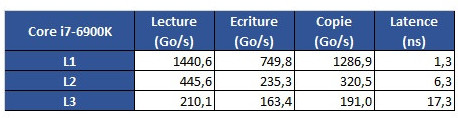
You have to be careful when comparing latencies as the numbers can be completely meaningless depending on workload.
Also, note that the numbers have changed significantly for Zen since its original launch due to updates from AMD/Manufacturers, so many of the numbers you see in older reviews are no longer accurate.
If you read reviews of the new Intel processor today, you'll see latency numbers have increased for Intel with their new architecture:
They mentioned in the article that the full cache of each die is available. Additionally, EPYC uses the same dies used in Ryzen. I'd look at earlier articles for Ryzen to determine latencies within a single die.
So for whatever cores are enabled on each die, you get the L1/L2 caches for each core as per the Ryzen launch. Additionally, you get all of the shared L3 cache, irrespective of the number of cores disabled per core complex. This pattern follows across all four dies in each socket.
"Each Epyc has 64KB and 32KB of L1 instruction and data cache, respectively, versus 32KB for both in the Broadwell family, and 512KB of L2 cache versus 256KB. AMD says Epyc matches the Broadwells in L2 and L2 TLB latencies, and has roughly half the L3 latency of Intel's counterparts."
SSE performance is comparable, so is 128-bit AVX. 256-bit AVX is in theory half as fast.
Despite this, apparently Ryzen beats Kaby Labe on SPECfp, so theorethical max throughput is only part of the story. It does not help that Intel needs to heavily reduce their boost speeds when using the full AVX unit.
For the new AMD releases there's none yet, but for Ryzen 7 Phoronix did one comparison for code compiled with -mavx2 and Ryzen did really poorly. The other benchmarks which use more integer math or relies heavily in multithreading puts AMD in an advantage. The post was in 18 May 2017 and AMD may have released some microcode updates that nullifies the results.
I'm... actually shock that somebody care about Xilinx.
I had to do Xilinx in my CE classes. It was terrible software, we joked that the CE and EE people code that software. Crashed all the time, made me so paranoid that to this day I would often ctrl+s every few minutes just in case my IDE crashes.
FWIW new Xilinx silicon is programmed by a new software suite, Vivado - which is much better than the terrible ISE you probably had to use in your class.
While I'm excited to see AMD's offering, as a scientific-HPC user I can't help but wonder how much marketshare AMD will be able to gain without more information on supporting software - specifically good compilers + math libraries (cf. Intel compilers + MKL).
Strangely, I've not seen much on HN, or elsewhere, make mention of AMD's software support. Is this because it doesn't exist, or because compilers are less "sexy" than shiny new hardware?
> While I'm excited to see AMD's offering, as a scientific-HPC user I can't help but wonder how much marketshare AMD will be able to gain without more information on supporting software - specifically good compilers + math libraries (cf. Intel compilers + MKL).
My take is that AMD's newest offering will be very well received by everyone who has a relatively tight budget but needs a small supercomputer on the desktop. This means data analysts and people doing all kinds of structural analysis work. As some optimization algorithms fit the definition of embarrassingly parallel, the expected turn-around time of anyone doing that sort of work will benefit greatly from the extra speed, bandwidth and core count of AMD's Ryzen/Threadripper/Epyc line.
Good thing most servers use Linux and other open source software. I actually read something recently that Microsoft almost got in trouble during the antitrust days for trying to sell Windows licenses "per processor." They seem to be doing exactly that. I guess they've gotten bolder since the governments stopped monitoring them closely.
The rules are different depending on whether you have a dominant market position or not. Microsoft clearly does not have a dominant market position on server hardware, so they can use "creative" licensing there.
Inertia and vendor lock-in are really powerful forces. Previous decision makers chose a Microsoft stack, and those who came before them did the same. Our third party services provider was a staunch Microsoft supporter. Before anyone knew it, we were completely locked in to a Microsoft ecosystem, paying tens of thousands per core for new SQL Server licenses.
{kind=link}
{kind=link}