It is great to have such a collection of rules and I hope they will be integrated into some easy-to-integrate static code analysis tool (as mentioned in the introduction). Maybe this will help people to transition to more modern C++ and to avoid some pitfalls (e.g. forgetting the "noexcept" for move constructors/assignments).
However, in some respect this list also shows what is wrong with C++: The fact that you even need such a huge set of rules to write safe and efficient code is somewhat unsettling. I'd rather hope a new version of the language standard would at least allow to hide deprecated constructs behind a "safe/unsafe" pragma.
It always seemed to me that it should be relatively not difficult to write some kind of language that limited you to the "right" way of doing things and that compiled down to C++
You could:
- prevent people from using deprecated features
- immediately remove TONS of boilerplate
- automatically generate header files from the cpp's
- have high level keywords that would generate design patterns for you (no more having to re-implement a Visitor for the first time that year and having to spend a day debugging it)
At the same time you could still leverage C++ libraries and when you do need to write an allocator or do some fancy diamond inheritance friend method templating magic shenanigans you could always drop back down to C++
EDIT: What I find kind of amusing is that with time you can do more and more of these things through Visual Studio's magical "wizards" and checkboxes (maybe it's the same for the other IDEs.. not sure), but ofcourse it's rather silly, clunky and slow to use. In the latest version you can finally make matching declarations/definitions with a couple of clicks - saves a lot of the mildly frustrating copy/past'ing!
You might like http://felix-lang.org in particular if you have a taste for the ML family of languages. It fits your description to a T. No, really, dead serious and I don't have any dog in this fight. Has had coroutines and fibres from the start. Certainly not a new language. Its relationship to C++ is much like F#'s relationship to C# or Scala's to Java
OTOH if you are really after C++ but done right then that would be D http://dlang.org
If you wish something like this for C then I would likely point to Nim.
Rust compiles to LLVM IR, which is better than compiling to C++ (for reasons I've elaborated on before).
As for library and tool support, I think a safe subset of C++ couldn't actually use tools for "real" C++, because the languages would be too different.
I'm sorry, but I feel like all these "Just use Rust!" comments are written by idealistic college students.
Yes, maybe Rust is better, and maybe if we could push a button and make everyone use it the world would be a better place.
But the reality is that there are very few code bases written in Rust and an uncountable amount written in C++ - there are decades of work behind C++ and decades of work will still be done in C++. I need to earn a living TODAY and work in the current reality, and I need tools to help me be more productive. I can't wait 5 years for some brand new language to take over.
I think you're misinterpreting what pcwalton said. Sure, seeing "use Rust" in every possible place is quite annoying, but what pcwalton described is why "compiles to C++" and "has 2 decades of libraries" don't work for new languages. He didn't say to use Rust, he was just pointing out that your two ideas aren't viable.
> But the reality is that there are very few code bases written in Rust and an uncountable amount written in C++
Most libraries use a C ABI due to it being stable, and Rust has fantastic FFI support for C (although tools to take in a .h and spit out the FFI in Rust are definitely needed). There's no performance cost to FFI in Rust, either, it's just a function call. As someone that spends a lot of time in an existing C++ codebase, FFI with zero overhead offers a very enticing migration path.
But as you were asking about making a new language, I was just pointing out the language you were starting to design has already been built.
But wouldn't factoring out the obsolete features limit the libraries that are available to use? I thought that was the point of the newly developed systems languages. Even if you follow some "sane" parts of the language, the rest of the ecosystem won't agree with you. Just look at this thread, there are tons of disagreements in what a good C++ code is.
See also http://www.stroustrup.com/SELLrationale.pdf "A rationale for semantically enhanced library languages" by Bjarne Stroustrup: "A Semantically Enhanced Library Language (a SEL language or a SELL) is a dialect created by supersetting a language using a library and then subsetting the result using a tool that “understands” the syntax and semantics of both the underlying language and the library." "The basic idea of... SELLs... is that when augmented by a library, a general-purpose language can be about as expressive as a special-purpose language and by subsetting that extended language, a tool can provide about as good semantic guarantees. Such guarantees can be used to provide better code, better representations, and more sophisticated transformations than would be possible for the full base language. For example, we can provide support for parallel operations on containers as a library. We can then analyze the program to ensure that no undesirable access to elements of those containers occurs — a task that could be simplified by enforcing a ban of languages features that happened to be undesirable in this context. Finally we can perform high-level transformations (such as parallelizing) by taking advantage of the known semantics of the libraries."
In the end though I never had enough time to bring it to a usable state, it was just a toy project for me to play around with waf-build and boost.test.
I think D is a better C++, and just for my bias confirmation, some things I read in the C++ guidelines are clearly influenced by D, or easier to do in D.
It doesn't compile to C++, but directly to machine code.
I think it's worth observing that a number of these are just common-sense guidelines for good programming practice, rather than being specific to C++. For example:
"Use exceptions for error handling only"
"Avoid data races"
"Prefer a for-statement to a while-statement when there is an obvious loop variable"
and so on. These don't really lend themselves to automatic checking, but it's still nice to see them written down in one place along with the more language-specific stuff.
Of course in Python, you're encouraged to use exceptions as part of the normal program flow.
(For example in duck typing, rather than checking whether your value is of a certain type, just assume it is, and deal with possible exceptions if it isn't)
And of course drawline(Point, Point) isn't clearer at all imo. What's the coordinate system? What are the units? Any performance notes on this function? Etc. I'll be checking the documentation the first time anyway.
void do_something(vector<string>& v)
{
string val;
cin>>val;
// ...
int index = 0; // bad
for(int i=0; i<v.size(); ++i)
if (v[i]==val) {
index = i;
break;
}
// ...
}
this is shown to be inferior to the find() version. Again, it's only inferior until the very common case where you're doing something else with the index, which is pretty common during debugging. Then you'll be rewriting the above "bad" version anyway.
Similar problems other higher order functions like for_each().
> What's the coordinate system? What are the units?
Good question. Where are you going to look that up? In the documentation of drawline?
Should drawrect, drawcircle, etc..., also include documentation about the coordinate system/units?
Of course not, that information should be centralized. That's where Point come in.
And that's just a detail, the main advantage of using a class is that is abstract details.
In the Point class, you may want to switch from int to int64_t without having to revisit all the methods.
That's the textbook explanation for this stuff, and matches what we see in the document. But I'm with the grandparent: this sort of pedantry fails badly in real-world code. What happens when you want to combine that rectangle implementation with someone else's geometry library which has its own notion of Point?
This kind of nonsense is just a recipe for everyone spending lines of code and neural cycles on a bunch of junk that will just be unpacked back into the underlying representation anyway in order to be used in the real world.
Don't do it. Simplicity trumps almost everything in real engineering. Abstract where abstractions add real value (which usually means "hide non-trivial amounts of code) and not where they do nothing but "document" stuff.
In this case the usage is clear (and IIRC I think most IDE's will avoid omitting lib1:: and lib2:: in compiled code even if you do). The whole point of namespacing is to avoid the name collision issues that are (were?) inherent to C.
I think the point may have been to call a function in one library with the arguments of types from the other library, so that you need to write less glueing code. But in that case, you don't actually know that the point types are compatible (they might be), especially since their internal details can change. I don't think this is about name collision.
Exactly. The point is that the abstracted Point hides implementation details like the underlying representation, which is good as far as it goes because it prevents goofs like overflow and trucation due to incorrect type conversions, etc...
But the second you need to match that abstraction to the code from some other developer which doesn't use it, you need that underlying representation back again. And this kind of mismatch isn't an uncommon edge case, it's the pervasive truth of modern development.
Basically: C++ can't win here, and it would be better not to try IMHO.
> you need that underlying representation back again.
But that's kind of a problem: while the underlying representations might be perfectly compatible, and you might know that for sure, that is not at all guaranteed. If you have a function that takes (int, int, int, int) instead of (Point1, Point1), Point1 = (int, int), that would not help you very much when Point2 = (int32, int32) (e.g., sometimes libraries make assumptions about internal representations, sometimes they don't).
Using low-level primitives everywhere like that can be a very misleading kind of simplicity - it might disappear. That C++ makes you reckon with the possibility that Point1 /= Point2 is supposed to tell you something about what you can know for sure about those types.
I have this issue occasionally, switching between sf::Vector2, b2Vec2, gVec2, etc. Something like drawLine({v.x,v.y},{w.x,w.y}) usually works in a lot of these cases, but I don't mind explicitly converting between representations in order to fulfil an interface.
The `(int, int, int, int)` version doesn't really help here though, because just because both libraries have int parameters doesn't mean they're compatible (eg as said above, could be different coordinate systems - but they look compatible!). At least with two point types its obvious that you need to convert between them.
What about the case when one library calls the origin the top left of the screen and the other library considers the origin the bottom left of the screen?
But... the compiler can't catch that incorrect translation code. The developer takes MyPoint and unpacks it into two doubles, then hands it to the YourPoint constructor and forgets to invert Y.
That's the point. The compiler is useless here, and this kind of glue code is probably 60+% of what developers are actually writing in practice.
But this site wants us to sit down and write a ton of boilerplate to handle a "Point" abstraction (complete with a full operator suite I'm sure, yada yada) just to solve a problem that can't be solved in the first place.
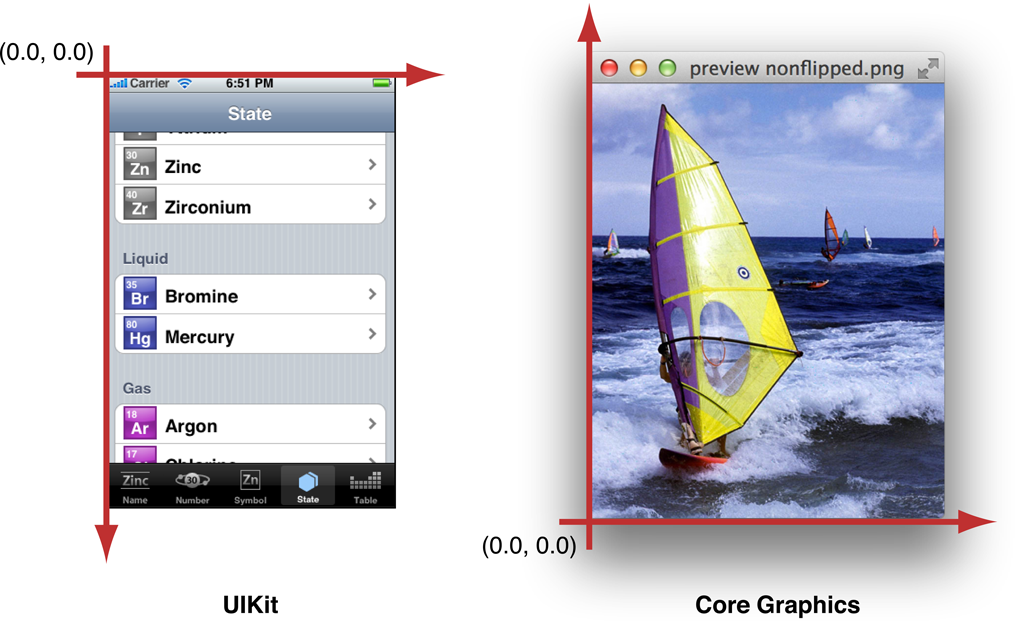
Well, you probably wouldn't be able to construct a UIKit::Point from a CoreGraphics::Point in the first place (these aren't C++ libraries but let's just go along for the analogy) if they didn't know about each other. You'd have to strip out the X and Y yourself, and this is the moment where you should be wondering if that's legal to do.
And if the libraries do know about each other then it's even better, because you can just say
CoreGraphics::Point cgp = CoreGraphics::Point(0, 0);
UIKit::Point p = UIKit::Point(cgp);
and p could already be in the right coordinate frame.
Anyways, this isn't some constant thing. Java developers typically like abstraction, ruby guys like passing raw hashes and strings/symbols everywhere. My preferences change based on language, codebase size, and how many people I'm going to be working with.
The summary is that we had two different coordinate systems in play and had many bugs caused by passing values in the wrong coordinate system around. By making the different coordinate systems different classes everything became explicit and checked by the compiler. We completely eliminated a whole class of bugs from our program.
The great thing about using an int is that it can be anything (integer). It can be an x coordinate, or the number of eggs or a selection between multiple options.
The bad thing about using an int is that it can be anything, and sooner or later you will pass the number of eggs into a function that really wants an x coordinate.
I prefer having member functions that convert to a different value, and friend functions that create instances from another type:
Distance d = feet(7);
d += meters(3);
std::cout << d.yards();
Distance d2 = 3; // I won't compile
This assumes that you want to mix units, not defeat it. It all ends up being very efficient; use MKS for the underlying representation. You can multiply, add, and so on, quite efficiently; the only conversions happen on input and output.
> That information can be encoded into the class type
This. I did the very same thing when dealing with some code that was frequently converting between three coordinate systems. Using Haskell code duplication was close to non existent and still type-safe. Not wanting to sound too fan-boyish ... but that was one of the first times that I realized that a good type-system can help you prevent whole classes of bugs.
I don't enjoy converting stuff between different formats for different libraries either, but sticking associated bits of data together really does make sense. With a function that just takes four integers, you can't easily distinguish between two Points or a Rect, for example.
Plus, a lot of problems are solved by namespacing and something like this:
At my job, we have namespace::MathConvert() which takes instances of one type, and returns const refs to other types (assuming they are binary compatible), for the case of one Point type to another.
If you're working with a lot of different point types then it probably makes sense to define your own point type that provides type conversion to all the other point types used in your codebase. That way you're not coupled to one library's point type in your own code and can add extra functions, etc. to the point class that you might need. You can also explicitly control stuff like what frame of reference your coordinate system is in and your type conversion functions handle converting to different frames of reference for other point types.
> several libraries where each defines its own "Point".
Same problem where each library defines its own "String".
Would be nice if the standard libraries would define such basic types and everyone would just use the same ones.
This might work better without OO kitchen sink approach to types. Just standardize a simple data layout or interface and leave the possibility for libraries to define their own functionality in extension methods.
Still, as Herb Sutter asked at CppCon 2015: "How many of you have your own homegrown string types at your companies? ... Don't lie. ... Right. And those of you who didn't put up your hand and are just bashful, ... we know we have them." [1]
The problem with std::string is, it was useless in the real world because its interface is basically unsuitable for handling Unicode. That's why every project that cares about i18n had to define its own string class to get anything done.
Only with C++11 did they add std::u16string, which is at least suitable for the (horrible) UTF16 encoding. Maybe we'll get an UTF8 capable std::string class in another 20 years.
You've always had the ability to put utf-8 data in std::strings, but you have to keep track of which strings are encoded. C++11 adds functions to convert to utf-8 (and utf-16 and utf-32), http://en.cppreference.com/w/cpp/locale/codecvt .
Note that with a long list of int values, it's also fairly easy to get the order wrong. Having a proper point type makes this less likely, as well as making the intent explicit.
Someone mentioned using an initializer list, which is a pretty good option if you don't want to be explicit. However, writing a small helper function or class to automatically (and using constexpr, at compile time) convert between different kinds of points can achieve the same thing without losing the contextual benefits.
For me, I don't care that
drawline(Point(vec.x1, vec.y1), Point(vec.x2, vec.y2))
is more or less clear. I mainly care about the fact that you can't easily tell which of these is correct:
drawline(Point(vec.x1, vec.y1), Point(vec.x2, vec.y2))
drawline(Point(vec.x1, vec.x2), Point(vec.y2, vec.y2))
All these guidelines are good for those who have been in C++ trenches for a while. For others, it will become another list, a list similar to what non-native English speakers have to learn by rote in order to predict the pronunciation of English words.
We have Scott Meyer's effective c++, more effective c++, effective STL, effective STL, modern effective c++.
I have read Bjarne's "A tour of C++", which is a good one to read. Also read his "design and evolitution of C++", which gives rationale for what we see the ugliness of C++.
I think we need a small book that describes the history of C++ until now, such a book can help us to remember "C++ core guidelines". This is similar to how great vowel shift in the history of Enlgih langauge helps us to see deeper patterns in English pronunciation.
I hate a bunch of guidelines, without historical explanations, because such guidelines are very hard to pin to one's brain unless one is working in hardcare C++ everyday. Maybe, this sounds like playing Piano scales:)
It's amazing how many people get these core principles wrong. I recently visited a C++ shop who hasn't even heard of RAII and don't use smart pointers or standard containers. What a nightmare.
It's great to see C++ getting an ecosystem and Bjarne's excellent writings help a lot.
Or you know, maybe they have different view on these things.
There are good programmers out there who don't use RAII or smart pointers and think that most of this modern stuff is just added cruft for little gain.
Standard containers are nice but if performance is your problem you often need to re-implement them anyway and if it is not then maybe you could have done it in the higher level language in the first place.
Whatever float your boat (and your particular niche).
I don't see many valid reasons why you wouldn't want to use RAII patterns for any sort of resource management. I would go as far as saying that if you aren't doing so, you're probably doing it wrong. Having said that, I'd be genuinely interested to hear some resource managment sceanrios where you're better off not using RAII.
You can end up needing a lot of different RAII types, which can get a bit annoying. If you're trying to interface with anything that wasn't written with RAII in mind - e.g., any library that tries to be C-compatible - this is pretty much inevitable.
In theory, doing without is a huge problem, because you're running the risk of resource leaks and stale identifiers - but in practice, neither is a huge problem. Picking these sorts of bugs out has been pretty simple in every project I've worked on. I've had far more heartache from the bugs stemming from RAII-type mechanisms holding on to resources longer than they should, than I've had from fixing bugs caused by resource leaks or stale resource identifiers.
I've been programming in a variety of environments in exchange for money for well over a decade now, and I think I can safely say that people who learn one thing and stick to it are what is known as 'wrong.'
Because, in the embedded world, you better have a good fucking explanation of why you are using dynamically allocated memory.
Bring a formal proof that you won't go out of memory. Attach additional information on how you wrote an allocator that runs in constant time and does not risk taking it's sweet time to scan a huge area of memory. Sure, it's all O(n), but who cares if determining when you are going to hit the huge n case is equivalent to solving the halting problem.
Of course, at this point, the hassle simply means you don't use dynamic memory.
I agree with you regarding dynamic allocation. RAII is an orthogonal concept to dynamic allocation though, and it's actually beneficial because it forces you to declare all your resources up front or die.
Even in the case that you're using an STL container, it's probably a hash table or tree data structure, and you're probably populating it at initialization time with a defined quantity of items. In that case, even if it's doing heap allocation it's effectively static allocation.
In my experience in the embedded world it is at least recognized that RAII should be used. It is fast becoming the exception not to use RAII and now that smart pointers are in the standard, the same goes for them.
I'm suspicious of anyone who uses smart pointers without being able to discuss the trade-offs. Likewise the STL and Boost('s smart pointers and containers).
I'm still learning c++11, but the framework I am using is not using smart pointers. It uses a single auto release pool with reference counting. Coming from Obj-C, I kinda like it but not sure what the downsides are so far into c++.
Jonathan Blow has a good point about smart pointers being a poor solution tacked on the language. As it wraps your class in another class and becomes kinda ugly.
After using Java, Python, C# and other languages. Smart pointers aren't really that smart. I'm not saying garbage collection is the solution - but smart pointers aren't a silver bullet.
Garbage collection isn't a very good solution. They're often implemented poorly (the only good one being Go's) and they're slow. Garbage collection also necessitates a runtime environment to keep track of the data.
What is not smart about smart pointers? std::shared_pointer implements reference counting just as OP describes.
> They're often implemented poorly (the only good one being Go's) and they're slow.
Do you have any evidence to support that? From my experiences and tests C# has been on par with C++ [1]. Of course it might be slightly slower but not enough for me to dismiss it. Java I think is a little bit slower - but my problem with Java is its memory requirements.
> Garbage collection also necessitates a runtime environment to keep track of the data.
Assuming they do this in a separate thread and you have an OS that schedules threads/processes in a sane way and the GC doesn't need to interact with the main thread - you should never notice a performance hit in your application.
> What is not smart about smart pointers?
They don't track the actual memory usage. John Carmack implemented his own version of memory management for both Doom 3 [2] and Doom 3 BFG [3] presumably so he could get debugging information that isn't available with the C++11 smart pointers. I've implemented something similar to Doom 3's heap where I track the line and file of where the heap memory was allocated.
The one thing I've noticed about developers today is that they have become lazy. Yeah - smart pointers will work correctly in simple cases and 90-99% of the time but it was written by humans so it may have bugs in it. Most C++ developers today refuse to run valgrind because they just assume their program doesn't leak memory when using shared_ptr/unique_ptr. I have personally found memory leaks in pretty popular open source projects. I would have told them about it - but I've found most C++ communities to not welcome new people and their ideas.
> John Carmack implemented his own version of memory management for both Doom 3 [2] and Doom 3 BFG [3] presumably so he could get debugging information that isn't available with the C++11 smart pointers.
Is this the same "Doom 3" that came out in 2004, a full seven-ish years before c++11.
I don't know how old that source is - but what does it matter? Any ameuter C++ developer can easily replicate unique_ptr and shared_ptr [1]. If he wanted to use those I'm sure he could have easily implemented it.
You're right, I'll rephrase: I agree with Blows point on it so far.
But I am pretty biased, I loved reference counting, and ARC just made it more awesome.
I want ownership, I point strongly. I don't care about ownership, I'll have a weak ref and that's it.
Thanks, I will!
But it doesn't change what Blow said, and what I agreed with.
It becomes ugly and takes more space than I need to.
My class becomes weak_ptr and what I want to use becomes the template. You should also look into his talk about c++ and its weaknesses.
The more I develop in C++, the more I wish I had a very restructure transpirer that would remove some of its most silly constructs or switch ite base defaults around.
Some examples:
- making all constructors explicit and adding an implicit keyword instead for that rare case
- automatically generated !=, <=, >= etc from == and < (with an explicit override when you want to be silly)
- removing some of the redundant syntaxes (const positioning, typedefs vs using etc
- removing the class keyword
You can easily do your != et al from < thing by using CRTP inheriting from a 'comparable' template class that provides the implementations. Sort of thing that should be in std really.
It looks like this isn't attached to the class definition, but rather to the uses. I.e. for every use of a class that only defines ==, <, you have to include rel_ops. But then it would basically provide the other comparators to all classes, maybe not something you'd want.
I must confess I am tired of all these guidelines. I mean I have learned C++ once, gone through the ordeal of learning all the best practices, memorizing all the gotchas etc. And now the language just got bigger. New features arrived along with new unexpected gotchas. Scott Meyers has written a new book and all is well. Except that the more C++ I write the more I yearn for something simpler with less arbitrary rules to memorize.
If you want to master the whole thing, sure. But for in-the-trenches application devs, it's a lot simpler now. For example, if you want to disable copying:
MyClass(const MyClass &) = delete;
That's a lot simpler than knowing the declared-private-but-not-implemented trick. There's a decent-sized list of these simplifications, especially using 'auto' instead of remembering the 102 characters necessary to describe the return type of 'begin()'.
is probably my favorite feature of C++11. Ironically it makes the recommended approach of using standard algorithms with lambdas look abstruse in comparison. Considering your example, I still feel that inheriting from boost::noncopyable is the cleanest way to declare the class noncopyable. It feels almost like a language keyword!
But the amount of new gotchas is significant too. In particular to use move semantics effectively you have to be aware of such obscure things as xvalues, std::move_if_noexcept and rules for autogenerated move constructors. The fact that the committee itself did not get it right on the first try speaks for itself.
I've only really ever made one project in C++, and I spent a good deal of time learning the "right way" to make different kinds of constructors. And all I could think is, if there is a "right way" to do it, then why isn't it the default? Why am I actually doing research on how to write boilerplate?
It's because C++ is a disaster.
Everyone likes to point out that you should only use a subset of the language. But that's not my experience with C++; only using a subset makes you vulnerable to all the problems associated with not understanding the actual language that is implemented, not just the subset you wanted it to be.
This is not completely false, but clearly the view of someone who does not understand C++.
Yes C++ carries decades of history, but since C++11 even if you can still make use of this you don't have to cope with. It is perfectly fine to use only a subset of C++, you just have to use the right one and this is what this documentation is about IMO.
Yes you have to understand the language to be efficient with it, but it is a language that allows high performance and maintainable large scale software.
Python was cited as an example in this thread and I don't get it. There a many ways to write the same thing in Python and I always end up spending more time looking on the web to figure out what is the "Pythonic" way.
The difference is that not being "Pythonic" is a style issue. A Python guru may scoff and point out that you could write the same thing more elegantly some other way, but most of the time the performance is the same, and the behavior is correct either way.
On the other hand, not following some of these C++ guidelines can mean your code is subtley broken and depending on undefined behavior, or leaking memory, or accessing something it shouldn't, etc.
I write C++ at work. We all know the language pretty well. We send people to conferences. We have somebody presenting at CppCon next week. We still get bitten by C++ more than you would belive.
You are comparing apples and oranges here. Please compare C++ to other systems languages that are regularly used to write systems / fast / "unsafe" code.
I'm sorry, but I'm not the one who brought up Python.
In any case, even compared to other systems languages, C++ is a mine field. It's sad that C++ and C are so entrenched that you've even equated systems and fast and unsafe, when unsafe really doesn't belong there.
Look at Ada. It performs just as well as C++ and is/was routinely used in low level embedded systems and safety critical systems. It's widely regarded as safe and doesn't have the problems C++ is so often associated with. It was first standardized in 1983 and C++ is just now getting around to adding some of the stuff Ada has had all along.
And then there are the newer, relatively unproven languages like Rust, Go, and D.
I'm pretty good with C, and while C has some safety issues, it doesn't usually bury them under miles of encapsulation. It's also a small, tight language that isn't trying to reinvent its syntax every 5 years.
And there's Rust: it's a pleasure to work with and has almost none of C++'s problems.
Oh, but C++ is so much fun for interviews - who can forget the joy of endless trick questions about code that looks like it should do one thing, but actually does another.
Oh man, I miss those days, ha ha.
You know you've finally reached peak C++ post-traumatic stress disorder when you walk into an interview and someone says "what does 'int x=5;' do?" and you spend half an hour trying to figure out what manner of hideous deception lies behind that simple expression. Your brow starts to sweat, your hands shake, and finally you exclaim "Undefined!".
>But that's not my experience with C++; only using a subset makes you vulnerable to all the problems associated with not understanding the actual language that is implemented, not just the subset you wanted it to be.
The real problem is your simple subset is often built with the very difficult features your attempting to avoid using. So by running from complexity you just embrace it, but don't learn that you're actually working with virtual templated necromancy until 2-3 months later when you try to extent the production code base.
I think one of the problems is that for any project that is moderately complex you really need (or at least would greatly benefit from it) to master the language + companion library Boost.
I did two relatively big projects (years apart), with the last one using Qt (because I also needed to do a GUI), and despite it working and doing what was supposed to, I wasn't entirely happy with the quality of the code.
"The rules are designed to be supported by an analysis tool. Violations of rules will be flagged with references (or links) to the relevant rule. We do not expect you to memorize all the rules before trying to write code.
The rules are meant for gradual introduction into a code base. We plan to build tools for that and hope others will too."
So it sounds like they will be introducing some tooling in the near future. It'd be nice if they leveraged existing tools (like clang-tidy)
One exception "NL.1: Don't say in comments what can be clearly stated in code
Enforcement: Build an AI program that interprets colloqual English text and see if what is said could be better expressed in C++." Pretty funny stuff for a style guide.
I first started looking at this when Cfront by AT&T Bell Telephone Laboratories came out. Let me know when the language stabilizes and maybe I'll take a look at it again.
Yeah, Classical Latin is pretty stable. Try use it in a modern conversation and you'll realize how painful that property is. Anything that's made of plastic, uses electricity, steam, actually any original idea in the last 300 years would require inventing some neologism just so you could talk about it.
I think you might still end up with something like the Lexicon Recentis Latinitatis [1] maintained by the Vatican. And unless you "make up" neologisms you'll end up with stuff like "timer - instrumentum tempori praestituendo" which would be extremely tedious to use in a conversation. Purists might argue that it would be awesome if we could make grammar "stable" though. It's an interesting thought.
That's what I really value about Go: gofmt and very good linting that embraces best practices. I know C++ is way more complex but for someone starting out it seems impossible to code in the "right (tm)" style.
auto can be a great aid to readable and maintainable code. It can also be used to obfuscate when not used in moderation.
for(const auto& elem : container)
is vastly more readable than
for(my_long_type<specialised_type>::const_iterator iter = container.begin(); iter != container.end(); ++iter)
I recently had to rewrite some C++11 code to C++98 to fit into a project. Using nothing but auto and range-based for loops, it nearly doubled in size by switching back to the older more verbose syntax. So long as you don't go to the other extreme, these have much value.
its also a death trap in winrt when combined with templates in the way they do.
debugging that typoing a callback signature results in nothing happening in asynchronous code controlled by the ppl task library is a massive pain for even an experienced programmer.
auto is nice in principle, but it is introduced in such a powerful and dangerous environment that there are subtle gotchas in real world use cases. including targetting a major platform by using its system libraries.
programming is about thinking, not typing and programmer convenience. i don't enjoy auto for that reason either... if it were to save me time it would be little. i find using the stl algorithms and avoiding the nasty stl iterator pattern like the plague means the problem you describe just doesn't exist for me as a day-to-day case.
(I didn't downvote you, but I think you're being downvoted because you said that C++ is being ruined without explaining why these suggestions are problematic or arguable, which doesn't add to the discussion)
nothing, and in fact the idea behind auto is sound if you take it out of the context of C++. in the context of adding to such a powerful and already overloaded with features language it creates subtle gotchas... i've hit them and seen them being hit, so i don't use it.
the usual examples of it shortening iterators are not a problem i have day to day... i also find arguments about typing less and avoiding typing mistakes seem to miss what programming is really about in the wild. i spend 20% of my time at absolute most actually converting my ideas into code and typing them into some document...
{kind=link}
However, in some respect this list also shows what is wrong with C++: The fact that you even need such a huge set of rules to write safe and efficient code is somewhat unsettling. I'd rather hope a new version of the language standard would at least allow to hide deprecated constructs behind a "safe/unsafe" pragma.