For more than a decade, evidence has been piling up that humans colonized the Americas thousands of years before the Clovis people.
It's actually been longer than that. The site at Monte Verde [1] in Chile seems to have been widely accepted as a pre-Clovis site nearly 20 years ago (1997 according to Wikipedia [2]). Awareness of the site, at least among the archaeological community predates that (1989 [3]). The first radiocarbon dates indicating a pre-Clovis origin for the site go back to 1982[4].
The idea that Clovis was not the earliest culture in the Americas, and the commensurate theory that the earliest colonists must have been traveling by boat [5] goes back decades. I know I've been reading about it (in the popular press no less) since the 1990s. It seems like every article I read about it makes it seem like some new and revolutionary idea. The only conclusion I can draw is that archaeological science operates on time scales only slightly shorter than those the archaeologists study.
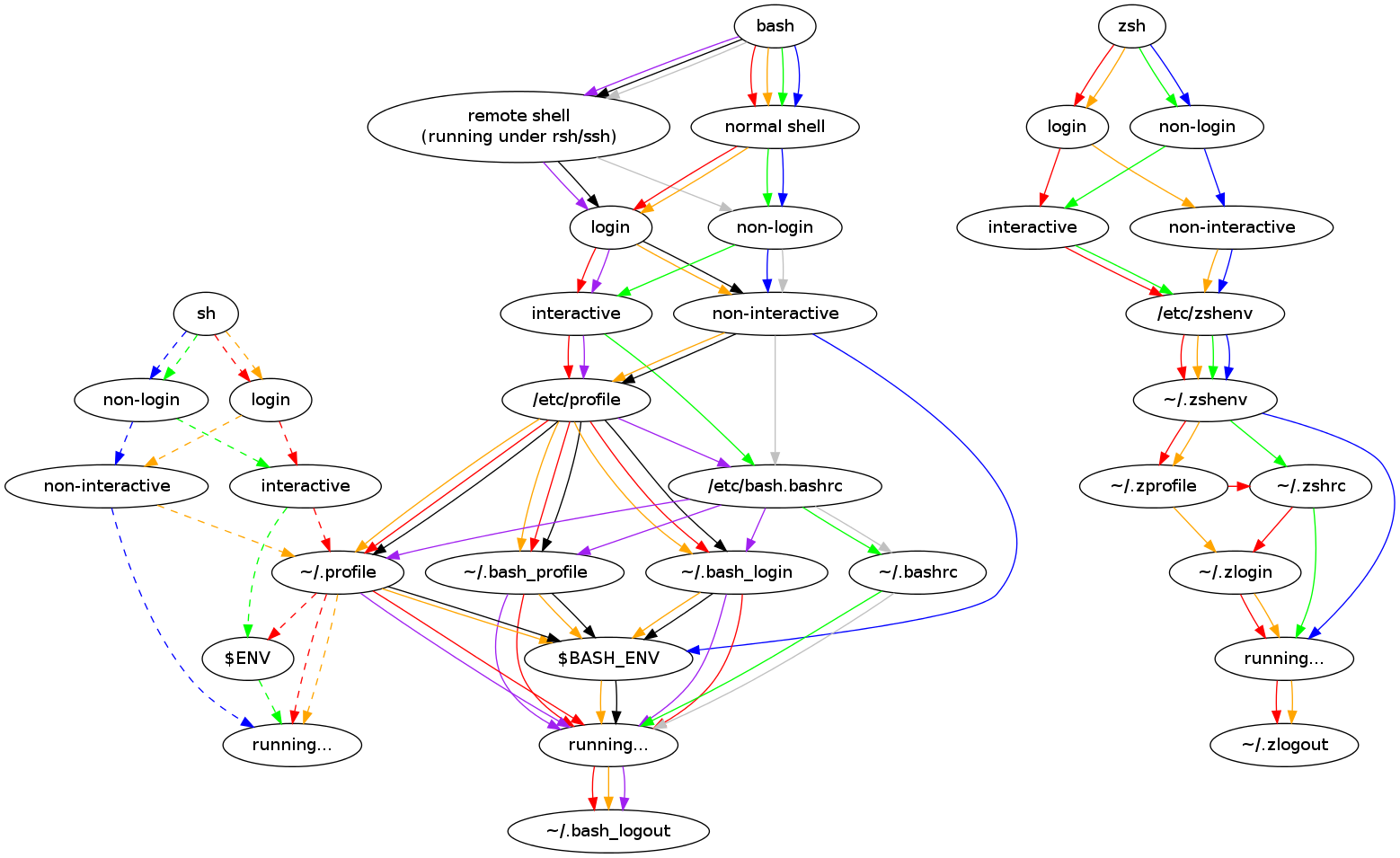
Profile is for login shells (thus executed once when logging in at the terminal or over SSH). The rc file is for interactive non-login shells (thus executed once each time you open a new e.g. xterm window).
But some systems treat all terminal emulator windows as login shells by default (e.g MacOS), though you can change that behavior.
Mostly running a shell script doesn't necessarily need to have all your aliases included, for one of many possible examples, but it conveniently doesn't really hurt things either. Making one setting the default is a way to promote "sameness" for those who aren't about to go about adapting different use cases.
But for "power users," the ability to alter the experience depending on context is there awaiting your specifics.
OK, actually this is correct and what the difference between the two files is (profile is loaded by a login shell, bashrc is loaded by an interactive shell), but can you tell me the real difference between ~/.bash_profile and ~/.profile?
The real answer is, read the entire man page to understand.
From the page .bashrc runs in every shell, so long as it is an interactive shell. Bash can be interactive according to a complex system of connected variables, including $PS1, $-, and the arguments passed into bash itself. I found all of this described fully in the Invocation section of the man page, section on interactive shells.
However, profile is loaded when the shell is a login shell. Which profile? Also from Invocation, continuing on from an explanation of when .bashrc is loaded:
> After reading that file, it looks for ~/.bash_profile, ~/.bash_login, and ~/.profile, in that order, and reads and executes commands from the first one that exists and is readable.
So, .bash_profile may or may not be loaded, and .profile being loaded or not loaded depends on the existence of those other two files in order.
Your response was lazy but on point. This is the darkest of man page magic, and nobody who hasn't read the manual will know the answer in complete detail. Everyone who has spent any real time in a shell has learned part of this answer.
The reason for that is that .profile was also read by login Bourne and Korne shells, with which bash is supposed to be backward compatible.
So if you only have a .profile, it makes sense to source that. If you have one of the bash-specific ones, then it's up to you whether you want to `source` the common .profile one or not.
The real fun comes when you want to run commands in every shell, whether interactive or not. For example, aliases that you want available when you use shell escapes like ! in vi.
The only way to do that is to have the file's path explicitly in $ENV, or $BASH_ENV of course...
Except Linux terminal emulators tend to launch a non-login shell (where .bash_profile is not read), and at the same time macOS’ Terminal.app prefers login shells.
I don't know what you've done, but you're shadowbanned or someone is killing almost all your comments, which I find egregious because your most recent comment is on point.
Very nice! If you're looking for one more variant to add: LD with a limit on the acceptable distance can be done more efficiently, and is nearly always what you want in practice.
> This implementation only computes the distance if it's less than or equal to the
threshold value, returning -1 if it's greater. The advantage is performance: unbounded
distance is O(nm), but a bound of k allows us to reduce it to O(km) time by only
computing a diagonal stripe of width 2k + 1 of the cost table.
It is also possible to use this to compute the unbounded Levenshtein distance by starting
the threshold at 1 and doubling each time until the distance is found; this is O(dm), where
d is the distance.
That's pretty cool, especially the doubling scheme. I'm using a modified form of Levenshtein Distance for comparing lines when diffing files, and that's pretty expensive since code files that are thousands of lines long are not uncommon. Since you are usually comparing one file to another version of itself, the differences are often small though, so an incremental approach would really pay off.
I'm OK with whiteboarding. I don't object to take-home assignments in principal, but I do object to them in practice -- they take up way too much time, and then part of the time you get ghosted after submitting them.
I think the right answer here, to the extent that there is a right answer, is to give applicants a choice.
It’s pretty hard to have a reliable interview process if you don’t ask all of the candidates to do the same thing. Comparing how a candidate performed compared to other candidates on the same set of tasks is an important part of the evaluation.
Consistent processes are also important for avoiding bias. For example, take-home projects are more likely to make sense for young candidates who aren’t raising families and have free time after work. If you have most of your young candidates doing take-home projects and the older candidates doing whiteboarding, you will end up evaluating candidates differently based on age.
Candidates have different strengths and weaknesses. Sure, I'll ask the base questions but in terms of assessing their coding ability I'll go with whatever they feel the most comfortable with.
If they have github, I'll ask them to walk me through a few files, asking their reasons for doing X, why not Y - what does this do?
If they prefer take-home, I'll give them something to create/improve.
Want to do something now? knock yourself out - with or without me watching.
I don't need to sort the candidate into an ordered list, just filter out the "over confident".
The questions I want answering is: Can they actually code? Does their skill match their experience? Is their skill level similar to the codebase?
The only time I've ever told a recruiter off was when I was asked to "spend about a half an hour to write a solution for [problem]" for Microsoft and it turned out to take about that long for me to set Visual Studio up on my laptop at home, and then an equal amount of time to figure out how to navigate the project files, etc. etc. and I could see that the interviewer A) had not given this any thought and B) had no idea how long this would actually take for someone who doesn't develop software at home.
> for someone who doesn't develop software at home.
Are you saying in general - or just for Windows-based software (since you mentioned needing to set up Visual Studio)?
The latter I can understand; but the former makes me want to ask, "Who applies for an SWE position who doesn't write code at home?"
I've been an SWE professionally since 1991 when I was 18; I got my first computer in 1984, and have been "coding at home" ever since. I'm not saying "to be an SWE you need a similar experience" (I know that's untrue) - I'm just relating that I've been coding for a long time, and "at home" is very much a part of it.
Then again, I've heard of people who absolutely hated coding, but were extremely good at it (and I assume made good money doing it), but when they went home, they didn't even want to think about such a thing. Maybe you are similar in that regard?
I guess I am just curious and a bit fascinated by your comment...
I'm someone who does it for 8-10 hours a day at their day job. My fiance works in a retail store. She doesn't come home and immediately start doing retail sales out of her house. Another friend is a teacher and she doesn't run a school out of her house.
Professional baseball players rest after games. They don't finish up and then immediately start practicing again. And soldiers and police get down-time.
Just because I'm doing something I enjoy and that I want to do, doesn't mean I should do it all of my waking hours. I'm not doing this to code, I'm doing this because my employer is paying me to build cool shit and I like doing that. I don't lift weights 24/7, I don't run 24/7, I don't hike 24/7, and I don't program 24/7.
Frankly your attitude is one of the reasons why we don't have any diversity in this profession at most self-described tech companies, and it also underlies a lot of the seeming ageism today. All of these self-described non-conformists expect everyone in the profession to conform to their attitude and it's sickening.
That was assuming you even had a Windows laptop to set VS on. I know a lot of people have to say no these days since they just have a MBP running OS X.
> I know a lot of people have to say no these days since they just have a MBP running OS X.
That's where the person who knows how to set up a VirtualBox VM running Windows and VS would have a large advantage; when they brought in the result, showing their MBP running VS in a virtualized manner, and explained what they had to do - that's a bit more of an impression than someone who says "they can't do it because MBP".
You can actually run Windows just fine on a mac using bootcamp. The big problem is just getting a legit Windows license, and then the hurdle is just a few hundred bucks (or whatever a non-OEM non-upgrade license costs these days).
Also, I'm nowhere near ops jobs, so I don't think those people interviewing me would care much about those kind of logistics (anyways, they wouldn't want to know the details). It wouldn't score any "points" beyond just getting the task done at all.
Last time I was looking for a job (about 3 years ago in Seattle) I had a lot of trouble getting through the initial screening to even get to a technical interview. I didn't have a lot of luck until I started applying through AngelList. One notable thing about AngelList applications is that there was no HR/recruiter screening step you had to get through first.
There's a lot of the author's opinion embedded in that paragraph, and I'm disinclined to agree with it, but ... no wait -- was that paragraph generated by a Markov bot trained to make substanceless attacks on opinions that the author doesn't like?
I wonder if it's practical to stick a couple of Space Shuttle external fuel tank-sized liquid hydrogen tanks on a typical container ship and then run it on hydrogen. One of the problems with liquid hydrogen (not the only one) is that it's impossible to keep it from slowly off gassing. However, if the tank is large enough it would off gas slower than your engines would be consuming the hydrogen.
{kind=link}
It's actually been longer than that. The site at Monte Verde [1] in Chile seems to have been widely accepted as a pre-Clovis site nearly 20 years ago (1997 according to Wikipedia [2]). Awareness of the site, at least among the archaeological community predates that (1989 [3]). The first radiocarbon dates indicating a pre-Clovis origin for the site go back to 1982[4].
The idea that Clovis was not the earliest culture in the Americas, and the commensurate theory that the earliest colonists must have been traveling by boat [5] goes back decades. I know I've been reading about it (in the popular press no less) since the 1990s. It seems like every article I read about it makes it seem like some new and revolutionary idea. The only conclusion I can draw is that archaeological science operates on time scales only slightly shorter than those the archaeologists study.
[1] https://en.wikipedia.org/wiki/Monte_Verde
[2] https://en.wikipedia.org/wiki/Monte_Verde#Acceptance
[3] https://en.wikipedia.org/wiki/Monte_Verde#Diffusion
[4] https://en.wikipedia.org/wiki/Monte_Verde#Discovery (third paragraph)
[5] I'd like to give you a citation for this, but this theory, as far as I can tell has no official name.
[Just quoting myself from https://news.ycombinator.com/item?id=12603556]