The arguments against jvm vs node I'm not buying. You don't automatically get scalability for free with node any more than any other platform. If anything the JVM has been further optimized, particularly for servers, for years over v8. You also don't see ram helping node not because node is so much more efficient -- it's because the design of the v8 limits how much ram it can use.
I'm not sure even why it serves to try and make this comparison if you're talking about node running well on modern arm processors.
There are a number of arm hosts out there now, but none seem to have caught on big. Perhaps in a generation of processor or two someone like aws will start to offer it and there might be a plausible shift.
The only real advantage to node is that it doesn't have all the "enterprise" baggage: the apps people build with it are a lot smaller and a lot more decoupled.
That baggage is concentrated in one particular JVM language and is largely self-imposed. I write NLP software in Java without resorting to the AbstractFactoryFactory nonsense prevalent in the enterprise world.
It happens in both Java and the .Net world.. every time I see "Enterprise" with a product description it makes me cringe... A lot of those abstractions only serve to scenarios; 1) Unit Testing and 2) service/storage portability. In most cases, neither are actually done. In the first case, I find actually writing unit tests in JS to be SO MUCH* better than with .Net or Java. In the latter, YAGNI prevails in my mind.
IT's entirely possible to work with "enterprise" platforms without using the excessive design patterns and abstractions, most simply don't. Not to mention that async being an option with C# for YEARS but most code I've seen even running on newer runtimes doesn't use it at all.
Node works very well for I/O constrained loads, unless you're risking running out of memory. I actually prefer the node way, and when you favor functional flows over OO design patterns, it gets to be really nice.
Java certainly has its warts, but I still think nearly all of what you describe is cultural rather than technical. Whether it's slavish adherence to GoF patterns, or obsession with code coverage metrics, or religious devotion to OO purity it's about the culture of the developer and the team. Java and C#, unfortunately, are the predominant choices of the developers and teams who share this culture. It gives the languages an unfairly bad rap, one which I agreed with until I started my current job.
You can take Java out of the enterprise, but you can't take the Enterprise out of Java.
What's sad is a bunch of us saw this coming the moment a J2EE spec first came out, and complained loudly that it was a trap, to no avail. Version 1 was written by grad students who had no idea what the 7 Fallacies were.
Version 2 was so complicated only a few big companies could implement it. It was a sad trainwreck that was hard to watch. And then Spring was supposed to save us all, and now it's more complicated than any of the things it replaced.
Which is why I do a lot of front-end code these days.
The interesting thing about the 7 fallacies is that we constantly find new ways to make the same mistakes. If we've been doing decentralized computing, someone thinks they can fix all of our problems by centralizing it. If we're in a centralized phase, someone thinks we can solve all our problems by decentralizing it.
Exactly like the node and microservices people are doing right now. If you want a front row seat to the next pendulum swing, start learning everything you can about centralized software models now. You'll be sitting pretty in three years when the backswing starts. Maybe we'll try software transactional memory again.
I think that breaking things apart can be very beneficial though... You can run microservices on the same system physically, and give preference to a local service. This does increase complexity of orchestration, but it's still beneficial. Most people wouldn't implement their own local database for a service that has to handle many thousands of simultaneous requests... yeilding to a RDBMS. By the same vein micro-services allow a similar distribution based on a type of work.
There's also a difference between writing a handful of microservices, which are a bit more broad vs. breaking every action into it's own service. Beyond this, if you can separate out of band actions via queues this can alleviate a lot.
One thing that does get me is how many services are using a SOAP or even REST interface over HTTP vs something lighter. In my current project the backend services operate over 0mq req/res interfaces, while the front-end will communicate over a REST composite interface. In this way there's less disconnect and overhead.
It's always a trade-off, but that doesn't mean an approach doesn't have merrit, it's just a matter of striking a balance. Which I would guess is the whole point of all of this.
Eh the insanely small size of individual modules (6 lines, I've seen!) creating huge nested node_modules is it's own type of hell. Seems like some programmers love ceremony and boilerplate, no matter the language.
Why not make lots of simple single-purpose modules?
My policy is that if I find myself doing something over three times and it's easily isolated and contained, I'll make it into a module. Then I can write a few tests for that code, I know it'll always work, and I won't have to think about it again. Even if it's something that's not hard, you don't want to stop focusing on your main task to implement some helper that you've already done before.
There's also a really strong argument when it comes to browser support: supporting and testing lots of things on old browsers is hard. But if you break stuff out into small modules you can test it easily in isolation and know it works in all your test browsers.
Just the tend to take a simple function, then ship it as a package. There's overhead in having a manifest, a folder, a separate code file, tests maybe, readme.md, etc. (Or in some cases, an meme-related animated gif that's referenced in the readme, that's larger than the rest of the package combined. Neato!)
It's obviously dumb from a technical perspective to break out individual functions (or even 20-100 line code files) into separate modules. But I think some folks really enjoy it.
Just like the Java or C# folks that put every single type definition into its own file. So you get some lame IHasFoo with a single bool property - so really 1 or 2 lines of actual code. Along with comments and a file header etc. Same for groups of enums, etc.
They can't have a solution to shared state anyway, because of the semantics of Javascript, so they go with the idea that shared state is an attractive hazard. Which it absolutely is, but the one isn't sufficient to justify the other.
Erlang seems to have this right. You can have all the shared state you want but it can't cross component boundaries, and therefore you can multiprocess your little hearts out.
"Node is nimble; for example, we advise our clients to kill & quickly restart when their applications enter an unexpected-error state. You can’t do this with a runtime that takes minutes to properly start and warm-up."
Hmmm. I'm running tiddlywiki (node.js app) on an ARM, and it probably takes a good ~30 seconds to start up.. Not good for an application that weighs in at 20k lines of code, 3/4 of which isn't even javascript. Worse yet, it has noticeable delays during operation, including about a 15 second delay if it hasn't been accessed in a few hours. I might blame it on a big dataset, but frankly it has less than a 100 tiddlers, and everthing is hosted on a SSD. This on a machine that generally is quite responsive, and capable (although its about 1/5 as fast as my desktop in some benchmarks I ran). It sure doesn't take that long to start apache/php on the same machine and start serving pages.
I am surprised that your application takes 30 seconds to start up in node. I have several utility scripts that run via babel-node instead of pre-build that don't take that long to start. When running pre-built JS, even using next generation syntax in source the start up is usually well under a second... Most of the lag time is in initializing database connection pools.
That said, how large is your application? Can it be broken up in to more right-sized services? Are you maintaining a lot of instantiated objects in scope? Are you using OO or FP orchestration? What kind of application is it?
"we advise our clients to kill & quickly restart when their applications enter an unexpected-error state"
Wait, what?
Shouldn't your thing actually work. How unprofessional is it to advise clients to kill and restart things instead of fixing the issue that caused this to be needed?
Our codebase (not Node-based) is over a million lines of code. It's going to crash at some point. Probably even a lot. Thus, it has been built so that it can be restarted without too much issue or ceremony.
This is doubly helpful because, as a side-effect, you can spin up or down new instances pretty easily because that operation is highly similar to crash recovery via restarting.
That was part of Zed Shaw's "Rails is a Ghetto" rant years ago, that the best Rails developer was proud that his application only crashed like 80 times per minute.
The argument here is that when things go sour you can restore a running process more quickly. Of course things should actually work and issues should be fixed, nobody is suggesting that.
This. So much this. We restart faster than X and therefore we're better? (not to mention all the other weird points of comparison the author chose to call out)
There's plenty of languages with runtimes that have fast start-up times. Does Node therefore suck because my Go application could potentially start-up faster? What about something Erlang on Xen where they're spinning up a brand new Xen domU to service a web request in the hundreds of milliseconds range? Brand new VM, can't really "crash" and need to be restarted because it's only ever there for a single request.
I'm not really sure what the end goal of the whole article is, but it seems woefully written in terms of being technically rigorous.
I've been using Node.js/io.js on ARM for a number of projects and have been pretty happy with it. For example using a cheap development board to create a build status light: https://github.com/tantalic/build-light. I'm just starting a new project where I am going to give Go a try for ARM development which I suspect may give even better results.
> Node’s development model encourages developers to think multi-process from the beginning because we know that without the crutch of threads, the only way we can scale our applications is to multiply the number of processes
>This means that Node applications scale as easily across clusters of servers as they do within a single server.
Yeah, the loss of efficiency that occurs by starting up an entirely separate V8 VM on the same machine is equal to starting one on two separate machines... But how is that a plus? Especially if you want to start more than one thread on a machine.
Also, that part had nothing to do with Node. Perhaps Node may be optimized for ARM, but that really isn't informative in how it performs compared against (say) Java on the same platform. Java's optimized for ARM, too...
What exactly do they mean by "multi-process" in the context of an event loop like Node? I'm also not sure about their claims concerning clustering - Node has no SMP capabilities, nor is there any real mechanism for enabling location transparency out of the box.
It's also interesting to note the conflict between the microservices and monolithic application camps. Both are just as adamant that theirs is the future and the other is awful. I'm sympathetic to KISS personally, but is there any real consensus forming?
Nodes I/O base actually uses a thread pool for the C++ bits that run in the background/waiting. For the most part, node/iojs is ideal in scenarios where you are I/O constrained, which is a surprising majority of them.
That said, I've run into issues actually using node for stream processing data... taking information from flat files, or sql record queries. In practice very few modules actually implement backpressure properly, and as a result it can/will eat through ram. Exposing GC and running it on every iteration in these instances helps, but once you hit 1-1.7GB of ram use, the process dies in a fiery inferno. That said, you are actually better off running the 32-bit engine in windows environments (not sure about linux, I haven't actually tried to compare).
This seems to be more of a puff piece on ARM than Node.js though... I like node a lot, but it does have it's limitations... if you need to process a LOT of data (imports/migrations) and can't chunk or otherwise break out your data, you may well run into issues. In my case, trying to run through 119m records would run out of memory faster than it could manage to push them into a message queue from node, ymmv.
This is my experience as well. When there are a lot of small or even medium sized operations or connections being performed (almost all the time), node does extremely well. When dealing with big huge chunks of data at once its not great.
I think it depends on what kind of application you're building, as well as other factors like team size, experience, and time. Microservices aren't magic pixie dust you sprinkle over your applications to suddenly make them simpler and "web-scale". They have a cost in management and maintenance. You can end up taking microservices too far, just as you can end up making the monolith too monolithic.
Having your core API all be part of a single application is great. It's my impression that for a lot of applications you can't really achieve good decoupling of resources, so trying to break it up into multiple services ends up bringing you a lot of pain. Maybe this is my lack of experience showing, I'd love to be proven wrong.
I'm currently a fan of having a big/medium app that does everything that cannot be decoupled easily, and breaking everything else into services. This is a happy medium, because you don't have to worry about managing tons of services, but you also don't have to worry about having an absurdly complicated monolith.
> While the JVM is right at the heart of the monolithic software stack and the tooling that surrounds it, Node, or server-side JavaScript, is arguably at the heart of the new SOA stack.
I love developing with node.js, but this doesn't sound right at all.
I've looked at them... but the performance still doesn't match even the relatively small VMs that are offered from cloud providers in terms of raw throughput. Part of the issue is the system builders for ARM based server boards simply aren't at near the scale.
Interesting to see a high level comparison of languages without a comparison of the important numbers: performance.
I know that Java performance is pretty crap on RPis due to the poorer Java ARM support, and I'd imagine that it's largely identical for node. All those millions that went into optimising JS performance can't help if the code generated is hobbled.
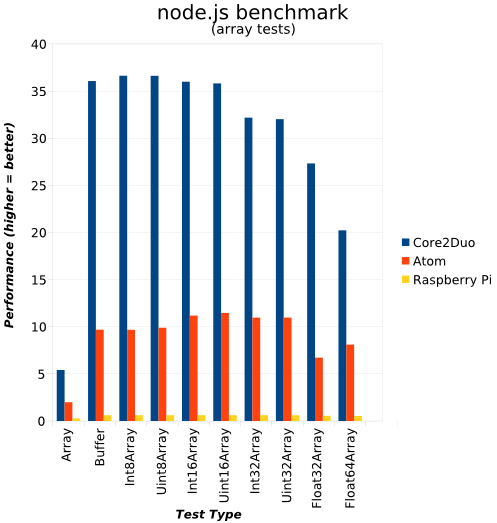
I've found little evidence to either prove or disprove my view, apart from this fairly devastating graph from a year ago, where a Pi is perhaps 100 times slower than an Intel dual core from nearly a decade ago.
I'm not convinced that ARM will be the architecture of the server, except in specialised markets (statistical multiplexing will give a big advantage to the >64 core Xeon servers that are popping up all around the place), but I'm totally convinced that this press piece is not particularly informative.
No kidding... look at the first pass of node applications written by people coming from .Net or Java... (I include myself)... it takes a while to get into the "node way" breaking your code down into discrete modules, and favoring functional flows over OO ones.
That said, once you get into it, some beautiful orchestration patterns emerge[1][2].
{kind=link}
I'm not sure even why it serves to try and make this comparison if you're talking about node running well on modern arm processors.
There are a number of arm hosts out there now, but none seem to have caught on big. Perhaps in a generation of processor or two someone like aws will start to offer it and there might be a plausible shift.