The older I get, the more my code (mostly C++ and Python) has been moving towards mostly-functional, mostly-single static assignment (let assignments).
Lately, I've noticed a pattern emerging that I think John is referring to in the second part. The situation is that often a large function will be composed of many smaller, clearly separable steps that involve temporary, intermediate results. These are clear candidates to be broken out into smaller functions. But, a conflict arises from the fact that they would each only be invoked at exactly one location. So, moving the tiny bits of code away from their only invocation point has mixed results on the readability of the larger function. It becomes more readable because it is composed of only short, descriptive function names, but less readable because deeper understanding of the intermediate steps requires disjointly bouncing around the code looking for the internals of the smaller functions.
The compromise I have often found is to reformat the intermediate steps in the form of control blocks that resemble a function definitions. The pseudocode below is not a great example because, to keep it brief, the control flow is so simple that it could have been just a chain of method calls on anonymous return values.
AwesomenessT largerFunction(Foo1 foo1, Foo2 foo2)
{
// state the purpose of step1
ResultT1 result1; // inline ResultT1 step1(Foo1 foo)
{
Bar bar = barFromFoo1(foo);
Baz baz = bar.makeBaz();
result1 = baz.awesome(); // return baz.awesome();
} // bar and baz no longer require consideration
// state the purpose of step2
ResultT2 result2; // inline ResultT2 step2(Foo2 foo)
{
Bar bar = barFromFoo2(foo); // second bar's lifetime does not overlap with the 1st
result2 = bar.awesome(); // return bar.awesome();
}
return result1.howAwesome(result2);
}
I make a point to call out out that the temp objects are scope-blocked to the minimum necessary lifetimes primarily because doing so reduces the amount of mental register space required for my brain to understand the larger function. When I see that the first bar and baz go out of existence just a few lines after they come into existence, I know I can discard them from short term memory when parsing the rest of the function. I don't get confused by the second bar. And, I don't have to check the correctness of the whole function with regards to each intermediate value.
What if I want to test some part of the function in isolation?
At my current job I have to maintain a huge and old ASP.NET project that is full of these "god-functions".
They're written in the style that Carmack describes, and I have methods that span more than 1k lines of code.
Instead of breaking the function down to many smaller functions, they instead chose this inline approach
and actually now we are at the point where we have battle-tested logic scattered across all of these huge functions
but we need to use bits and pieces of them in the development of the new product.
Now I have to spend days and possibly weeks refactoring dozens of functions and breaking them apart in to managable services
so we can not only use them, but also extend and test them.
I'm afraid what Carmack was talking about was meant to be taken with a grain of salt and not applied as a "General Rule"
but people will anyway after reading it.
Perhaps it suggests our way of testing needs to change? A while back I wrote a post describing some experiences using white-box rather than black-box testing: http://web.archive.org/web/20140404001537/http://akkartik.na... [1]. Rather than call a function with some inputs and check the output, I'd call a function and check the log it emitted. The advantage I discovered was that it let me write fine-grained unit tests without having to make lots of different fine-grained function calls in my tests (they could all call the same top-level function), making the code easier to radically refactor. No need to change a bunch of tests every time I modify a function's signature.
This approach of raising the bar for introducing functions might do well with my "trace tests". I'm going to try it.
[1] Sorry, I've temporarily turned off my site while we wait for clarity on shellsock.
Something to consider, and this is only coming off the top of my head, is introducing test points that hook into a singleton.
You're getting more coupling to a codebase-wide object then, which goes against some principles, but it allows testing by doing things like
function awesomeStuff(almostAwesome) {
MoreAwesomeT f1(somethingAlmostAwesome) {
TestSingleton.emit(somethingAlmostAwesome);
var thing = makeMoreAwesome(somethingAlmostAwesome)
// makeMoreAwesome is actually 13 lines of code,
// not a single function
TestSingleton.emit(thing);
return thing;
};
AwesomeResult f2(almostAwesomeThing) {
TestSingleton.emit(almostAwesomeThing);
var at = makeAwesome(awesomeThing);
// this is another 8 lines of code.
// It takes 21 lines of code to make somethin
// almostAwesome into something Awesome,
//and another 4 lines to test it.
// then some tests in a testing framework
// to verify that the emissions are what we expect.
TestSingleton.emit(at);
return at;
}
return f2(f1(almostAwesome));
}
in production, you could drop testsingleton. In dev, have it test everything as a unit test. In QA, have it log everything. Everything outside of TestSingleton could be mocked and stubbed in the same way, providing control over the boundaries of the unit in the same way we're using now.
I've had to change an implementation that was tested with the moral equivalent to log statements, and it was pretty miserable. The tests were strongly tied to implementation details. When I preserved the real semantics of the function as far as the outside system cared, the tests broke and it was hard to understand why. Obviously when you break a test you really need to be sure that the test was kind of wrong and this was pretty burdensome.
I tried to address that in the post, but it's easy to miss and not very clear:
"..trace tests should verify domain-specific knowledge rather than implementation details.."
--
More generally, I would argue that there's always a tension in designing tests, you have to make them brittle to something. When we write lots of unit tests they're brittle to the precise function boundaries we happen to decompose the program into. As a result we tend to not move the boundaries around too much once our programs are written, rationalizing that they're not implementation details. My goal was explicitly to make it easy to reorganize the code, because in my experience no large codebase has ever gotten the boundaries right on the first try.
I've dealt with similar situations, and it was what led to me to favor the many-small-functions myself. I like this article because by going into the details that convinced him, Jon Carmack explains when to take his advice, not just what to take his advice on.
I think maybe the answer is that you want to do the development all piecemeal, so you can test each individual bit in isolation, and /then/ inline everything...
I'm not sure. If you then go head and inline the code after, your unit tests will be worthless.
I mean it could work if you are writing a product that will be delivered and never need to be modified significantly again (how often does that happen?).
Then one of us has to go and undo the in-lining and reproduce the work :)
I think I'm going to say that, if it's appropriately and rigorously tested during development... testing the god-functionality of it should be OK.
Current experience indicates however that such end-product testing gives you no real advantage to finding out where the problem is occurring, since yeah, you can only test the whole thing at once.
But the sort-of shape in my head is that the god-function is only hard to test (after development) if it is insufficiently functional; aka, if there's too much state manipulation inside of it.
Edit: Ah, hmm, I think my statements are still useful, but yeah, they really don't help with the problem of TDD / subsequent development.
Current experience indicates however that such end-product testing gives you no real advantage to finding out where the problem is occurring, since yeah, you can only test the whole thing at once.
I’m not so sure. I’ve worked on some projects with that kind of test strategy and been impressed by how well it can work in practice.
This is partly because introducing a bug rarely breaks only one test. Usually, it breaks a set of related tests all at once, and often you can quickly identify the common factor.
The results don’t conveniently point you to the exact function that is broken, which is a disadvantage over lower level unit tests. However, I found that was not as significant a problem in reality as it might appear to be, for two reasons.
Firstly, the next thing you’re going to do is probably to use source control to check what changed recently in the area you’ve identified. Surprisingly often that immediately reveals the exact code that introduced a regression.
Secondly, but not unrelated in practice, high level functional testing doesn’t require you to adapt your coding style to accommodate testing as much as low level unit testing does. When your code is organised around doing its job and you aren’t forced to keep everything very loosely coupled just to support testing, it can be easier to walk through it (possibly in a debugger running a test that you know fails) to explore the problem.
If it's done strictly in the style that I've shown above then refactoring the blocks into separate functions should be a matter of "cut, paste, add function boilerplate". The only tricky part is reconstructing the function parameters. That's one of the reasons I like this style. The inline blocks often do get factored out later. So, setting them up to be easy to extract is a guilt-free way of putting off extracting them until it really is clearly necessary.
But, it sounds like what you are dealing with is not inline blocks of separable functionality. Sounds like a bunch of good-old, giant, messy functions.
I think the claim is that if you don't start out writing the functions you don't start out writing the tests, and so your tests are doomed to fall behind right from the outset.
I'm not fanatical about TDD, but in my experience the trajectory of a design changes hugely based on whether or not it had tests from the start.
(I loved your comment above. Just adding some food for my own thought.)
"I'm not fanatical about TDD, but in my experience the trajectory of a design changes hugely based on whether or not it had tests from the start."
I'm still not sold on the benefits of fine grained unit tests as compared to having more, and better, functional tests.
If the OPs 1k+ methods had a few hundred functional tests then it should be a fairly simple matter to re-factor.
In "the old days" when I wrote code from a functional spec the spec had a list of functional tests. It was usually pretty straightforward to take that list and automate it.
Yeah, that's fair. The benefits of unit tests for me were always that they forced me to decompose the problem into testable/side-effect-free functions. But this thread is about questioning the value of that in the first place.
Just so long as the outer function is testable and side-effect-free.
Say you have a system with components A and B. Functional tests let you have confidence that A works fine with B. The day you need to ensure A works with C, this confidence flies out of the window, because it's perfectly possible that functional tests pass solely because of a bug in B. It's not such a big issue if the surface of A and C is small, but writing comprehensive functional tests for a large, complex system can be daunting.
The intro to the post has Carmack saying he now prefers to write code in a more functional style. That's exactly the side-effect-free paradigm you're looking for.
Even most of the older post is focused on side-effecting functions. His main concern with the previous approach is that functions relied on outside-the-function context (global or quasi-global state is extremely common in game engines), and a huge source of bugs was that they would be called in a slightly different context than they expected. When functions depend so brittly on reading or even mutating outside state, I can see the advantage to the inline approach, where it's very carefully tracked what is done in which sequence, and what data it reads/changes, instead of allowing any of that to happen in a more "hidden" way in nests of function-call chains. If a function is pure, on the other hand, this kind of thing isn't a concern.
> They're written in the style that Carmack describes, and I have methods that span more than 1k lines of code.
I don't think that's the kind of "inlining" being discussed -- to me that's the sign of a program that was transferred from BASIC or COBOL into a more modern language, but without any refactoring or even a grasp if its operation.
I think the similarity between inlining for speed, and inlining to avoid thinking very hard, is more a qualititive than a quantitative distinction.
Sure, before I knew how to write maintainable code. Before I cared to understand my own code months later.
My first best-seller was Apple Writer (1979) (http://en.wikipedia.org/wiki/Apple_Writer), written in assembly language. Even then I tried to create structure and namespaces where none existed, with modest success.
Maybe you should just be testing the 1k functions, if that even, and not the individual steps they take. The usefulness of testing decreases with the size of the part being tested, because errors propagate. An error in add() is going to affect the overall results, so testing add() is redundant with testing the overall results and you are just doing busywork making tests for it.
I often question the wisdom of breaking things down into micro functions. Usually when I'm delving into a Ruby code base where they have taken DRY to the extreme(I'm looking at you Chef). There is so much indirection occurring in the most basic of operations that it becomes a huge PITA trying to get your head around what's happening. An IDE that could interpose the source in the method call could be handy in such situations... I also feel that people conflate duplicating code with duplicating behaviour, which is what DRY is really about.
You could have the best of both worlds with IDE support, once it is there people may stop putting so many innecesary layers if they aren't needed only so that function gets "inlined by the IDE"
Look at the Java or .Net worlds as a cautionary example: powerful IDEs are useful for the code you have now but they also enable people to write even more labyrinthine code and the complexity fiends are usually more aggressive at pushing those limits.
Unfortunately, this conflicts with the (common, good) advice to make as many variables final / const as possible, since it separates the declaration of a variable and its assignment.
One nice thing that falls out of Scala's syntax is that it makes this style possible without using mutation:
val result1 = {
val bar = barFromFoo1(foo)
// ...
baz.awesome()
}
val result2 = {
val bar = ... // unrelated to 'bar' above
bar.awesome()
}
All names introduced in the block go out of scope at the end of the block, but the 'value' of the block is just the value of the last line, so you can assign the whole thing to a final / constant variable. This style has all the advantages listed above, and makes it easier to avoid mutation and having uninitialized variables in scope -- I wish more languages had it.
> Unfortunately, this conflicts with the (common, good) advice to make as many variables final / const as possible, since it separates the declaration of a variable and its assignment.
In Java you can separate the declaration and assignment of a final variable as long as every branch provably assigns to the variable. For example:
final int x;
if(someCondition) {
final int a = 1;
final int b = 2;
x = a + b;
} else {
x = 0;
}
I did not know this; thanks! I think I still prefer Scala's structural style, but I'll definitely have good use for this when I wander back into the Java universe.
+1 for this. I'm still pretty new to Scala, but coming from my day job (Java) , I'm finding more and more reasons to love it.
As a side note, I'd love to see Scala make it's way into game development. I've been messing around trying to get libgdx working with it. But I would love something that lets me take full advantage of the Scala language.
Might have been because of the `else if (ch == 'q') break;` line. If he used a switch statement he would have needed to use a goto to break out of the loop.
That's a reasonable guess, but a return would work there. I think I did it this way because all the breaks you need in a switch are noisy -- too noisy if you'd like to write one action per line. However, you can mute the noise by lining it up:
switch (getchar ()) {
break; case ' ': enter_text ();
break; case 'f': view = formulas;
break; case 'h': col = (col == 0 ? 0 : col-1);
which also makes oops-I-forgot-the-break hard to miss. I hadn't thought of that pattern yet. (You could define a macro for "break; case" too; my friend Kragen calls that IF.)
But I mostly stopped coding in C after around this time.
Interestingly, in http://canonical.org/~kragen/sw/dev3/paperalgo, I haven't yet run into the desire to have more than one `case` in a pattern-matching `switch`. I just added that piece of code from Vicissicalc to the paperalgo page.
Not exactly. But it does create a no-op default. I've never seen/used this pattern, so I would have to go compile this down into assembly and play with it to give you a more complete answer.
Dropped by dead-code elimination. A compiler might conceivably issue a warning that the first break is unreachable, though that's never happened so far.
Seconded! Also I would like to see comments on how programming styles in general have changed over the years - does a 80's era high-quality program still look like a 2010's high-quality program once you factor out the syntactic sugar?
I find it fascinating that larger traditional languages have changed little over time, while the languages of front-end development seems to change daily.
My coding style seemingly morphs about every few months now. It's sad to think stuff I wrote even three years ago I would never show someone interviewing me or put it in a portfolio nowadays.
This should only be true during the early days of your career. If you're out of the novice stage, you shouldn't be writing hateful code – maybe there's a new library to use or something you now understand about the problem but that's hardly the level of hatred.
I've been taking this tack more and more as well and while the syntax is never elegant, one at least grows used to it.
I also try to explicitly name which variables I'm capturing (within reason) as it makes it obvious at a glance what can and can't be modified within the lambda. I really wish it was possible to force constness on captured variables :/
I've experimented with this, too. One thing that I also like is that you can have multiple returns within the lambdas and know that the control flow paths will merge again at a common point. The compiler can also make sure that each one returns a value of a compatible type.
I've found myself doing this a lot. Glad to know I'm not the only one. Functions with a single call site don't need to be cluttering up a larger namespace; limited scope is also good for the internal variables.
To isolate all of the initialization logic for a single object (e.g., "result1" or "result2") into its own scope. You could use a function (in fact, that's exactly what's being done here—it's just an anonymous function), but moving that logic away from its use and into global scope generally just makes the code more difficult to understand.
> There's no benefit and only drawbacks over the plain old block syntax.
You cannot initialize a const object with the "plain old block syntax." With this, you can, and that is an enormous benefit. It's also much easier to see that the object is initialized; it's not immediately obvious that an uninitialized variable declaration followed by an assignment many lines later will always initialize the variable, but if you initialize it in its declaration, you know it will necessarily be initialized. That is also a very important benefit.
What are the drawbacks? That the syntax is a little uglier? It's not ideal, but it's hardly huge syntactic overhead: four or five non-whitespace characters and a return instead of an assignment. In fact, the syntax is markedly better if you have multiple initialization paths, because you can use return instead of goto; compare
char* foo;
{
char* mem = (char*) malloc (N);
if (!mem) {
mem = NULL;
goto foo_init;
}
if (!fgets (mem, N, fd)) {
free (mem);
mem = NULL;
goto foo_init;
}
foo_init:
foo = mem;
}
the_next_thing:
to
char* foo = [&] {
char* mem = (char*) malloc (N);
if (!mem)
return NULL;
if (!fgets (mem, N, fd)) {
free (mem);
return NULL;
}
return mem;
} ();
the_next_thing:
Even after the "plain old block" version has been contorted to make assignment to foo unconditional (it's essentially a manually inlined function), it isn't obvious that it's correct. Does the block do "goto the_next_thing" or something similarly hairy? Read the whole thing to find out.
In contrast, once you've seen that foo is initialized by a function and that function ends in an unconditional return, you know that foo cannot not be initialized at the_next_thing, period (even if you throw exceptions into the mix!).
You might argue that you can verify the correctness of the first version, and of course you can, just as you can verify the correctness of an HTML parser written in brainfuck. It's all a matter of cognitive load, of the amount of context you have to hold in your head at one time to reason about the correctness of one part of your code. It's the difference between verifying that the function initializing foo has an unconditional return and verifying that every control path in the initialization block reaches foo_init, when what you're really trying to do is just to show that foo will point to a valid string at "the_next_thing."
In fact, that's basically the primary motivation behind functions, next to code reuse. All this pattern is really doing is modularization-by-function of initialization logic without the cognitive overhead induced by lexically separating the logic's definition from its use. In doing so, it delivers the same advantages as the plain-initialization-block pattern, but preserves the comparatively simple control-flow-barrier semantics of functions.
Compared to goto-spaghetti, typing "[&]" and "();" really isn't that big of a deal.
> Some practical Matters --- Using large comment blocks inside the major function to delimit the minor functions is a good idea for quick scanning, and often enclosing it in a bare braced section to scope the local variables and allow editor collapsing of the section is useful. I know there are some rules of thumb about not making functions larger than a page or two, but I specifically disagree with that now -- if a lot of operations are supposed to happen in a sequential fashion, their code should follow sequentially.
"* if a lot of operations are supposed to happen in a sequential fashion, their code should follow sequentially.*"
He is absolutely correct in this. However, he's wrong with regards to the level of abstraction. Those "operations" should be part of functions that could be scattered all over the code base in whatever order they were written. But at the end of the day, they will be called sequentially right next to each other.
I've often found this to be the case. The developers I see that make these "god" functions are unable to write and compose their code in layers. They instead see the entire run (start->finish) of their programs as one giant series of "sequential" "operations". So what ends up happening is they've got high-level code, interspersed with low level io/networking/db calls.
At work, I have a 450 line function. What it does is very simple:
1) validate the request; if it's invalid, send back an error.
2) look up some information.
3) send that information.
Step 1 is around 300 lines. But a majority of the lines are huge comment blocks describing what the check is for and referencing various RFCs. Yeah, I could have broken this part off into its own function, but ... there will only be one caller and doing so would be doing so for its own sake [1].
Step 2 is one line of code (it calls a function for the information).
Step 3 is the remainder; it's just constructing the response and sending it.
The code is straightforward. It's easy to follow. It's long because of the commentary.
[1] I did have to deal with a code base where the developer went way overboard with functions, most of which only have one caller. It's so bad that the main loop of the program is five calling levels deep. I once traced one particular code path down a further ten levels of function calls (through half a dozen files) before it did actual work.
When I confronted the developer about that, he just simply stated, "the compiler will inline all that anyway." And yes, the compiler we're using can do inlining among multiple object files, which makes it a real pain to debug when all you have is a core file.
> went way overboard with functions, most of which only have one caller. It's so bad that the main loop of the program is five calling levels deep
It almost sounds like you're talking about http://canonical.org/~kragen/sw/dev3/server.s! Or for that matter http://canonical.org/~kragen/sw/aspmisc/my-very-first-raytra...! But it's unlikely you've had to maintain either of them. I intentionally broke things up like that with the idea that it would make it easier to understand. In fact, I originally wrote httpdito as straight-line code and only later factored it into macros to make it easier to understand.
It sounds like you're saying that this was misguided and I should have just used nesting. I'll have to think about that for a while.
In reference to your 450 line function. What you just explained to me are three different sections to some algorithm that you have. One of the sections you already have as a separate function. However, the other two are quite large. Imagine you've just found this 450 line function while debugging. How would you know to not go through each line to find the problem, or step over all 300/1/150 line chunks of it?
There is benefit in being able to group the chunks, and maybe your comments are quite obvious in the grouping. But if I know I'm looking for a "validation" bug, and I come across a grouping of three functions which are called, say, "PrepareRFCRequest", "GetResponseInformation" and "ConstructResponse" then I can very easily deduce that they're not related to my problem and ignore them. You could say they're not my concern.
A lot of these things I talk about build upon each other. i.e. If you then go ahead and put some sort of input validation inside of your "GetResponseInformation" function, then the grouping / function abstraction is pretty much useless and may even be detrimental when debugging, e.g. in my example above.
"there will only be one caller and doing so would be doing so for its own sake"
No, there is benefit to putting it in its own function. Even if there is one caller. Because creating functions isn't always about reducing duplication, but of concerns/abstraction and to me above all composability.
"[1] I did have to deal with a code base where the developer went way overboard with functions, most of which only have one caller. It's so bad that the main loop of the program is five calling levels deep. I once traced one particular code path down a further ten levels of function calls (through half a dozen files) before it did actual work."
Perhaps you, I, and the developer you speak of have a different view of what the "main body/loop" of the program, or any program in general.
It's far easier to do a brain dump and write everything in sequence upfront as a proof-of-concept. That should be in the very early stages only though.
Things like database reads/writes should be refactored out immediately. This is boring stuff that only challenges inexperienced developers. Most developers with some experience can grok the idea of a function named 'SaveToDB(stringthing)' or something like it. When not dealing with common operations, the key here is repackaging your functions in a way that the meaning is significantly conveyed through the name of that function without the name being excessively long. Short function bodies also ensure that things remain quickly absorb-able.
Taking if-blocks or loops and putting them into their own function just to shrink the size of the god function to pretend you're refactoring really serves no purpose though (IMO). This is especially true if the number of times those functions are called is less than 2. (believe me, I've seen it!)
> Things like database reads/writes should be refactored out immediately. This is boring stuff that only challenges inexperienced developers. Most developers with some experience can grok the idea of a function named 'SaveToDB(stringthing)' or something like it.
They should be refactored out, yes, but refactored out in a different component with little (ideally none) logic in it, not a different location of the higher-level component.
> Taking if-blocks or loops and putting them into their own function just to shrink the size of the god function to pretend you're refactoring really serves no purpose though (IMO). This is especially true if the number of times those functions are called is less than 2.
Of course it serves a purpose. Take a codebase where you have functions that go over 5 or 10 screens. Now, take a codebase which does the exact same thing, but where the god function is split into smaller and smaller functions depending on the complexity. The second codebase is much easier to read (as long as function names are well chosen). It also means that most, if not all, of the comments necessary to understand codebase 1 (which may or may not be present, and may or may not be up to date) can be removed. The number of call sites for a function does not matter. What matters is how small functions make the code easy to read.
"It's far easier to do a brain dump and write everything in sequence upfront as a proof-of-concept. That should be in the very early stages only though."
I guess I'm different to you in that regard. To me, my "brain dump" is a bunch of function skeletons that I write out at a high-level. E.g. if I know at some point I'll have to parse a file, I brain dump it as:
result = parse_file(get_file_data())
At that point, I've already defined my "higher-level" brain dump (as you call it) without having to worry about stuff like file-format, filenames, checking for deleted files, etc.
"Taking if-blocks or loops and putting them into their own function just to shrink the size of the god function to pretend you're refactoring really serves no purpose though (IMO)"
Well, depends on the if-blocks I'd say. 99% of the time, I bet you that those blocks and loops can grouped into logical pieces of work that happen in stages. Claiming that we do it just to "pretend" we're refactoring doesn't really add anything to the conversation.
Exactly, and he also suggests that in the email: "(...) and often enclosing it in a bare braced section to scope the local variables and allow editor collapsing of the section is useful".
I hadn't understood this "maybe leave functions inlined" rant a couple years ago when I first heard about it - it makes a lot of sense now.
This is what I do as well, for exactly the same reasons. (You saved me a post. Thanks!) It works pretty well, I think. As you say, it's nice to have the code just written out in the order in which it will be executed.
It can look a bit daunting at first sight - if you're not used to this style of code, it just looks like your average rambling stream-of-consciousness function - but it's actually pretty easy to keep on top of. And if people really complain, it's super-easy to split out into functions :)
The downside is that lambdas are usually a bit more complex to write/read than plain old scope blocks.
The very nice upside would be that you could make the inputs to the blocks explicit. In contrast, the fact that foo1 is an input to step1 and foo2 is an input to step2 can only be understood by careful examination.
I don't see how you want to use first-class functions, lambdas, in this situation. Maybe, you meant to say nested functions? Lambda function is a piece of code that is usually sent somewhere else, a callback basically.
If you define a lambda function instead of a block of code and call it right there, it would create a considerable overhead: because if it is a closure, it should save its current scope somewhere. And it is really unnecesary, if you call this function right at the same place where you define it.
sjolsen did a good job of illustrating what I meant https://news.ycombinator.com/item?id=8375341 Improvements on his version would be to make everything const and the lambda inputs explicit.
It's my understanding that compilers are already surprisingly good at optimizing out local lambdas. I recall a demo from Herb Sutter where std::for_each(someLambda) was faster than a classic for(int i;i<100000;i++) loop with a trivial body because the for_each internally unrolled the loop and the lamdba body was therefore inlined as unrolled.
In the languages that I'm using (JS, and now Swift), lambdas are only marginally more difficult to write than a pair of brackets. In fact, in Swift, you actually can't write a pair of brackets to designate scope, but you can put stuff in a lambda if you wish.
This allows you to actually write what you want. Nicer still, these internal functions are aware of surrounding context, so they're full closures, and thus you can take their address and pass it around as a callback without needing any void* cookie. I've been using these more and more.
The downsides are that this is a nonstandard gcc-only extension and that it's available in C only, not C++. Depending on what you're doing, these can be deal-breakers.
My brain has taken to interpreting "GCC extension" as "supported by GCC and Clang," but nested functions are one of the few cases where that isn't true,[1] which is worth noting for readers who are concerned about FreeBSD or OS X.
Fwiw there's no real problem with gcc-specific code on FreeBSD if you're writing application software. Kernel code and core utilities in the base install are supposed to be able to compile with clang, but stuff in ports can use anything that is itself available in ports. The ports system makes it easy to specify when something requires gcc to compile vs. any C compiler, and doing so is fairly common (heck, it's not a problem to require even more exotic things either, like Ocaml or gfortran).
This is why I prefer a language where everything is an expression, and I can nest things without limit. If I need a simple, but narrow-use helper function? Why, define it inside the function I need it in, and use it a handful of times (or once).
Doesnt need to be an expression language for that. Algol and Pascal had nested procedures and lexical scope but still had traditionla imperative statements.
Could you please explain why it'd be useful to do that for something you'd only use once, esp only within that function? I honestly don't see how that's useful or more clear. Some examples with explanations would probably help. Thanks :)
So I opened up one of my files and found the first instance of this. It was a function to load some subset of data and emit some log info. It was only called once, at the end of a chain of maps and filters.
let load_x xid =
// loading code
// Later on...
let data' = foo |> map ... |> filter ... |> ... |> map load_x
Once you view functions as values like anything else, then making single-use, "temporary" functions seems as normal as temporary or intermediate variables.
Just consider naming clarity. It's just like using i for an iterator variable -- if it were global or file-wide in scope it would be disastrous, but because it's local to the block it's simple and intuitive.
Similarly you can give a little helper function a short, obvious name knowing it won't have side-effects.
I use literate programming for exactly this kind of tension. You can have blocks of code written elsewhere with a high-level overview for your function, but in the built program, you can see it all in one place the way it will be run.
I agree that dividing the largerFunction into smaller ones has a non-negligible cost, and that cost is never mentioned at school. However, I still think that the benefits provided by moving them out outweigh it.
One think that I found beneficial is that by dividing the big functions into smaller ones, the resulting functions have the same abstraction level. To give an exaggerated example: I try to split my functions so that I never deal with Countries, Provinces, Cities, Buildings, People, Body Members, Organs & Cells in the same scope. I try to only deal with one of them per function (sometimes two, in parent-child cases).
I find that 1-abstraction-level functions are easier to understand, and I gladly "pay the price" of having extra one-use names around for this reason. I do try to restrict the scope of those "extra functions" as much as I can, put related functions together, and reduce side-effects as much as I humanly can.
The ones Karmack talks about. Several "concepts"(functions in this case) with implicit relationships (like what calls what, and in what order) are (sometimes) more difficult to process for a human brain than a huge block of sequential code.
The ones Karmack talks about. Several "concepts"(functions in this case) with implicit relationships (like what calls what, and in what order) are (sometimes) more difficult to absorve than a huge block of sequential code.
Right. In my old age, I've actually come to appreciate some aspects of the C pre-99 insistence on declarations occurring at the start of blocks. I think on balance strict adherence is too much (especially the absence of initializers in for-loop headers), but as you say blocking off regions where things are used helps substantially.
Tempting but extra levels of indentation also lead to poor readability. The other problem is that this style of programming isn't commonplace and will throw off new readers. Better to just stick to a standard program, broken up into pseudocode I think. Technically, the bind time of variables are still the entire function but in practice you can choose to limit the useful scope of a variable to the code block where it is defined. It doesn't take a master coder to notice quickly that the first variable at the top is the one to remember going down the lines. The only remaining problems, then, are that variable names become a little longer to avoid conflicts between the code blocks and the compiler probably won't be able to optimize the function as well as you'd like to, since some extra variables stick around for longer when not needed.
I've found using a powerful language like Scala permits me to insert terse one liners, where in Java I might have created a function with a rich, English language name describing what the function does. Instead of a semantic description of the function, you see the function itself.
You aren't the only one. I do stuff like this all the time, although I tend to find those kind of code blocks eventually get broken out into separate functions anyway if you wait long enough.
The #region directive in c# is pretty awesome for this and I really wish every language had something similar. Sadly I'm not sure there's a great way to do it for e.g. ruby and obviously the situation would be even worse for homoiconic languages.
SSA should be thought of in terms of control flow. The immutable variables are a tool that makes it easier to reason about control flow and that flattens variable scoping. When you have nested lexical scope and immutable variables, that looks nothing like SSA. No one ever calls Java code that uses final SSA.
if certain functions are only called within one other function, couldn't the compiler automatically inline them to get rid of the method call overhead, as long as they're not externs?
His comments are on style, not performance. "In no way, shape, or form am I making a case that avoiding function calls alone directly helps performance." Although he does argue that this style indirectly leads to better performing code.
You should be able to do domething similar to the C example in most other languages with sane, lexical, variable scoping. Unfortunately, Python doesn't really play nice with nested scopes/functions so you are a bit out of luck here.
You could define local functions inside your larger sequential function, and then call immediately. Not 100% the same, but in terms of reading-code-in-order, it would have the effect, and it would create the same scope restrictions as the listed code.
You can't do it in Python, but it's not limited to C/C++ either; this is usually called "block scoping" and it's present in C/C++, C#, I think Ruby, Java, etc.
I might be alone on this, but whenever I read things by John Carmack I get a vague sense that he doesn't really get object oriented programming. He always has a lot of interesting things to say, but it also kinda reads like a C guy trying to code in C++. I'm glad his thinking keeps evolving and he's not dogmatic about anything. I'd honestly love to hear his thoughts on C++11
"The function that is least likely to cause a problem is one that doesn't exist, which is the benefit of inlining it."
That's the equivalent of saying "the faster you drive the safer you are b/c you're spending less time in danger"
You'll just end up with larger monster functions that are harder to manage. "Method C" will always be a disaster for code organization b/c your commented off "MinorFunctions" will start to bleed into each other when the interface isn't well defined.
" For instance, having one check in the player think code for health <= 0 && !killed is almost certain to spawn less bugs than having KillPlayer() called in 20 different places"
I don't completely get his example, but I see what he's saying about state and bugs that arise from that. You call a method 20 times and it has an non obvious assumption about state that can crop up at a later point - and it can be hard to track down. However the flip side is that when you do track it down, you will fix several bugs you didn't even know about.
The alternative of rewriting or reengineering the same solution each time is simply awful and you'll screw up way more often
>> I might be alone on this, but whenever I read things by John Carmack I get a vague sense that he doesn't really get object oriented programming.
I'm starting to think object oriented programming is a bit over rated. It's hard to express why exactly, but I'm finding plain functions that operate on data can be clearer, less complicated, and more efficient than methods. Blasphemous as it may seem, a switch statement does the equivalent of simple polymorphism and can be kept inline.
Many game programmers decided long ago that object-orientedism is snake oil, because that kind of abstraction does not cleanly factor a lot of the big problems we have.
There isn't anything close to unanimous agreement, but the dominant view is that something like single inheritance is a useful tool to have in your language. But all the high-end OO philosophy stuff is flat-out held in distaste by the majority of high-end engine programmers. (In many cases because they bought into it and tried it and it made a big mess.)
As a fellow game developer, I have to agree. I find that inheritance is a form of abstraction which sounds nice on paper and may work well within some domains, but in large and diverse code bases (like in games), it makes code harder to reason about and harder to safely modify (e.g. changing a base class can have a lot of subtle effects on subclasses that are hard to detect). The same goes for operator overloading, implicit constructors... Basically almost anything implicit that is done by the compiler for you and isn't immediately obvious from reading the code.
That's suspicion of snake oil paradigm is why it's interesting that game developers seem to be much more open to functional programming. Compare egTim Sweeney's "The next mainstream programming language" (https://www.st.cs.uni-saarland.de/edu/seminare/2005/advanced...)
>Blasphemous as it may seem, a switch statement does the equivalent of simple polymorphism and can be kept inline.
In the statically compiled languages that most people think of when they hear "OO" (C++ and Java), yeah, switch statements vs. virtual methods (performance differences aside) is basically a matter of code style (do you want to organize by function/method, or by type/object?)
However, the original proponents of OO intended it to be used in dynamically compiled languages where it could be used as a way to implement open/extensible systems. For instance, if a game entity has true update, animate, etc. methods, then anyone can implement new entities at run time; level designers can create one-off entities for certain levels, modders can pervasively modify behaviors without needing the full source code, programmers trying to debug some code can easily update methods while the game is still running, etc. You can get a similar effect in C or C++ with dynamic linking (Quake 2 did this for some large subsystems), but it's a pain and kinda breaks down at fine (entity-level) granularity.
The other, "dual" (I think I'm using that word correctly?) approach famously used by emacs is to create hooks that users can register their own functions with, and extend the program that way. Like switch statements, it basically amounts to storing functions at the call site instead of inside the object, except with an extensible data structure rather than burning everything directly into the machine code.
Obviously you can't really take advantage of any of this if you're writing some state of the art hyper-optimized rendering code or whatever like Carmack, I'm just saying that OO's defining characteristics make a lot more sense when you drift away from C++ back to its early days at Xerox PARC.
Switch statements are extensible in that you can add extra switch statements to your program without needing to go back and add a method to every class you coded, spread over a dozen different files. Its the old ExpressionProblem tradeoff.
All code is extensible if you have the source code and can recompile the whole thing then restart the program. I think pjmlp meant extensible in the "extensible at runtime" sense.
switch statements and method calls are kind of duals of each other. One makes it easy to add new classes but fixes the set of methods and the other makes it easy to add new methods but fixes the set of classes. It doesn't have to do with runtime.
Method calls don't need to be fixed either. Just because C++ stores virtual methods in a fixed-sized table doesn't mean Lua/Javascript/etc can't store them in hash tables. And a list of hooks is sort of like an extensible switch statement, but bare switch statements like you were describing obviously don't have that kind of runtime flexibility.
No, you can add new functions that switch over the different types without having control over the code. That way you don't have to add the same method to each of the classes.
In Oberon's case, which was lucky to have survived longer at ETHZ than Modula-3 did at DEC/Olivetti, all successors (Oberon-2, Active Oberon, Component Pascal, Zonnon) ended up adding support for method declarations.
For quite a while, there was significant buzz around OOP, and some people did, in fact, overrate it. But I get the impression that over the last couple of years, more and more people have begun to realize that OOP is not the solution to every problem and started looking in new directions (such as functional programming).
I think this why Go has become so popular. It deliberately is not object-oriented in the traditional sense, yet it gives you most of the advantages of OOP (except for people who are into deep and intricate inheritance hierarchies, I guess).
(I don't know how many people are actually using it, but now that I think of it, the same could be said of Erlang - the language itself does not offer any facilities for OOP, but in a way Erlang is way OOP, if you think of processes as objects that send and respond to messages.)
So I think there is nothing blasphemous about your statement (in fact, Go allows you to switch on the type of a value).
(I am not saying that OOP is bad - there are plenty of problems for which OOP-based solutions are pretty natural, and I will use them happily in those cases; but I get the feeling that at some point people got a bit carried away by the feeling that OOP is the solution to every problem and then got burnt when reality asserted itself. The best example is probably Java.)
I've found the rise and fall OOP to line-up well with various trends in ontologies and semantic-like KM tools (after all OOP is basically designing an ontological model you code inside of). Outside of various performance issues, the idea that you can have one master model of your problem to solve everything is an idea that hopefully seems to be running out of steam.
In the area I've worked in, I've seen numerous semantic systems come and go, all built around essentially one giant model of the slice of the world it's supposed to represent, and the projects all end up dead after a couple years because:
a) the model does a poor job representing the world
b) nobody seems to have a use-case that lines up perfectly with the model (everybody needs some slightly different version of the model to work with)
c) attempts to rectify b by just adding in more and more to the model just leaves you with an unusable messy model.
More recent systems seems to be working at a meta-model level, with fewer abstract concepts and links, rather than getting down into the weeds with such specificity, and letting people muck around in the details as they see fit. But lots of the aggregate knowledge that large-scale semantic systems are supposed to offer gets lost in this kind of approach.
I think OOP at its heart is just another case of this -- it's managed to turn a programming problem into an ontology problem. You can define great models for your software that mostly make sense, but then the promise of code-reuse means your suddenly trying to shoehorn in a model meant for a different purpose into this new project. The result is code that either tries to ignore "good" OOP practices to just get the damn job done, or over specified models that end up so complicated nobody can really work with them and introduce unbelievable organizational and software overhead.
It's not to say that OOP and other semantic modeling approach don't have merit. They're very useful tools. I think the answer might be separate models on the same problem/data, each representing a facet on the problem. But I haven't quite gotten the impression that anybody else has arrived at this in industry and are instead just going for higher levels of abstraction or dumping the models all together.
Again, OOP manages to turn programming problems into ontology problems -- which is hardly a field that's well understood, while the goal is and always has been to turn programming problems into engineering problems -- which are much more readily understood.
Most programming concepts are really about code organization and not expressiveness or the ability to express an algorithm clearly.
Object oriented programming only really starts to make sense when you are working on something that will take thousands of man-hours. If you are working alone, or on a small project is can be completely irrelevant.
The work flow you are describing is what MATLAB guys do. It's an absolute nightmare once the project gets too large. It is however very fast an flexible for prototyping.
Whatever its other pros and cons, I find OO style tends to result in significantly larger code bases.
Most programming concepts are really about code organization and not expressiveness or the ability to express an algorithm clearly.
You imply a dichotomy where none exists. For non-trivial algorithms, the ability to express them clearly and the ability to organise code at larger scales are very much related.
Even on large projects, I think there are often better ways of managing complexity. A lot the reasons for encapsulating internal state disappear if that state is immutable.
I would say that OOP makes a lot of sense on large code bases, but that it's also very easy (and dangerous) to get overzealous with object inheritance, interfaces, abstract base classes, etc.
> Most programming concepts are really about code organization and not expressiveness or the ability to express an algorithm clearly.
You could also separate your functions in different scripts with naming that is closely related. You've pretty much achieved code organization without the hidden scaffold that comes with OO codebase, only a chosen few with ridiculously large salary know about and newer developers largely having to pretend to praise with terminologies straight from CS text book because their monthly check comes from it.
Why do we need thousand different ways to write a simple CRUD web application in a language? Obviously OOP hasn't really done what it is advertised which is introduce a code organization to it's fully efficient state any better than functional coding.
If Java was supposedly so great with it's OOP as a core feature,where as humans we are supposed to model the extremely complex systems of reality into some fictional objects in our brain, where is Sun Microsystems now? It ended up as snake oil for a lucrative proprietary enterprise software company which is aimed at selling simple CRUD apps pleasing the business/government crowd. Have you seen the range of Oracle's suite of crap? It's literally insane, you have to pay to basically learn how to reinvent the wheel in their own terms and be pay a percentage back to them for speaking their language, as if landing business deals isn't hard enough already. Absolute garbage Java turned out to be. Even Android pisses me off. I used to hate on Objective C but I applaud Swift, there's no such innovation taking place because the JVM and Java is built entirely on a failing founding software philosophy, that the whole world is some simple interaction of objects interacting with each other, not it is not, there's quantum mechanics in play, with myriads of atoms that end up interacting with each other in a chaotic fashion that gives rise to some pattern our brain is supposedly good at finding.
Throw sand on a piece of blank paper, people will claim they see Jesus, and sell it on ebay.
I agree. The simplicity comes from the fact that you are focusing on different aspects at different times. I find that I will start off with defining my data structure and only focusing on the data structure. What information do I need, what is the best way to organize the data. Those sorts of issues. Once I have the data structure then I focus on what I want to do with it. This may result in some functions attached to the data structure using the object oriented features and sometimes the functions live apart from the data structure. The benefit comes from mentally decoupling the data from the functions.
To use Minecraft as an example, a player may die from falling from too high, drowning, getting attacked by a monster. If killPlayer() is called serparately for each of those cases, he asserts that it may cause bugs due to differing context or sequencing relative to other parts of the code. If OTOH you just decrement player health in each of those places and then check for health<=0 at only one place, you eliminate that class of bugs.
I am working on the most close-to-finished computer game I have written yet, and I have a bug caused by this exact thing! (I am learning a lot about what not to do as I go.) I plan on refactoring it to the check-once-per-loop style this weekend.
That makes sense - though most of the time if a method call only makes sense give a particular state, it's generally set to be protected. You can still call it with the wrong state from within the same class, but I can't honestly think of a case of that happening in my work.. You generally are familiar with the workings of the class you are currently touching. If you aren't able to do that practically, then that generally means your class is simply too large.
Wait, like, Power Towers Strilanc? I love your work :) In fact I think I did a competition with some friends to get a high score in the map credits for a while...
Pretty crazy, all the things the WC3 scene produced. Like, multimillion dollar gaming sub-genres (tower defense, MOBAs, etc). Glad to see you're still making games!
I have found myself writing "Method C" code in cases where factoring the code into methods obscures rather than simplifies. I think Carmack sums up the reason pretty well: "The whole point of modularity is to hide details, while I am advocating increased awareness of details." I ask myself, can I factor methods out of this code (a la Method A or Method B) in such a way that the code can be understood without reading the implementations of the smaller methods? If not, then the complexity is in a sense irreducible, and splitting the code into chunks just forces other people (and eventually myself) to jump around and try to knit the pieces together mentally, when it would actually be easier to read the code in one piece.
Another way to put it is that Method C is the least bad solution when factoring fails. I had a conflict with a coworker several months ago over a difficult piece of functionality that I had implemented Method C style. It was giving him headaches and he complained incessantly about the fact that the code was written in a linear "non-factored" style. I tried to explain to him that the problem was simply that hard, and the code organization wasn't making it worse, but was rather making the best of a bad situation. (Basically, if he thought the code was hard to understand, then he obviously hadn't tried to understand the problem it was solving!) He ignored me and refactored the code Method B style. A month later he was still struggling (because it was a truly complex problem) and he called me over to help him out. The code was now unfamiliar to me, so I'd point at a method call and say, "What does this method do?" "Uh... let's see. <click>" "What does that method it's calling do?" "Hold on. <click>" And so on, all the way down the call chain.
The refactored code had become "easy to read" in the sense that the methods were short, but it also become impossible to read in the sense that reading a method didn't give you any useful information unless you went on to read all the code in all the methods it called. We ended up reading the code exactly as we would have read Method C code, except with a lot of clicking and no visual continuity or context. Abstraction didn't protect us from the details; it just made it harder to see how they fit together into the whole.
> The alternative of rewriting or reengineering the same solution each time is simply awful and you'll screw up way more often
He might not have communicated it completely correctly, but I believe he wasn't advocating for getting rid of functions to reduce redundancy.
He instead was advocating getting rid of functions that simply provide documentation of the process, and instead find a way to inline those functions clearly.
> However the flip side is that when you do track it down, you will fix several bugs you didn't even know about.
I think he is saying a class of bugs is avoided. For instance if I do X, Y and Z where all are only ran when the player is alive and Y might kill the player, leaving the player alive avoids a bug in Z if it assumes that the player is alive.
> whenever I read things by John Carmack I get a vague sense that he doesn't really get object oriented programming
Can you share a bit about your background here? In the absence of more context, to me, this reads sort of like a guy who plays football on weekends saying that Lionel Messi "doesn't really get" football.
> "The function that is least likely to cause a problem is one that doesn't exist, which is the benefit of inlining it."
> That's the equivalent of saying "the faster you drive the safer you are b/c you're spending less time in danger"
What I believe he means is that functions calls at different places can be a source of trouble when you're not side-effect free.
For some reason, a lot of older game/graphics programmers seem to feel the same way about OO programming. I don't know if it's force of habit or experience on their part, but I try to keep it in the back of my head nowadays.
Haha, I like this quote: "That was a cold-sweat moment for me. After all of my harping about latency and responsiveness, I almost shipped a title with a completely unnecessary frame of latency."
I'm not a professional programmer and I rarely work with large code bases. So the fact that my code has drifted steadily over the years towards the large-main-function I thought was a factor of several things, first being my general amateurism. I still think that, but there are definitely other reasons too: I now use more expressive languages (Python instead of C) and more expressive idioms within those languages (list comprehensions instead of while loops) and more expressive structures/libraries (NumPy instead of lists of structures), so I can afford to put more in one spot. I also write smaller but more numerous programs.
But there are very real advantages. I learned through game programming and still do some for fun and I absolutely prefer having a main loop that puts its fingers into all the components of the game than to have a main loop which delegates everything to mysterious entity.update()-style functions. The lack of architecture allows me to structure the logic of the game more clearly for exactly the reasons Carmack outlines. Everything is sequenced - what has already happened in the frame can be seen by scrolling up a bit instead of digging through a half-dozen files.
But the real win here is for the beginner programmer. I strongly dislike the trend these days towards programming education being done in a "fill in the blanks" manner where the student takes an existing framework and writes a number of functions. The problem is that the student rarely has any idea what the framework is doing. I would rather not have beginners write games by make on_draw(), on_tick(), etc. functions but much rather have them write a for loop and have to call gfx_library_init() at program start and gfx_library_swap_buffers() at the end of a frame. That way they can say "The program starts here and steps through these lines and then exits here" versus having magic frameworks do the work for them. There is plenty of magic done these days behind the scenes for any beginner, but it is too much to have a completely opaque flow-control.
I particularly liked your last paragraph about beginner programmers, and I want to strengthen it. Abstraction is not just a drag on learning programming, it's also a drag on learning new codebases, even if you're already fairly experienced.
Abstraction is good for people experienced with a codebase, but as codebases grow larger and more complex that usually means the first few people, because newcomers are rarely able to attain the same grasp of the big picture.
This suggests that authors of say open source projects who want to gain more collaborators might want to go against their instincts for abstraction.
The key difference is that those who built the abstraction understand exactly what it abstracts, and thus what its capabilities and limitations are. Those who didn't, don't get quite the same picture.
I'm not a fan of excessive abstraction either - the main thing I use it for is to reduce code duplication, which IMHO is one of the real benefits. Code that contains lots of functions-called-once or classes-used-once feels like a terribly inefficient and obfuscated way to do something, and far less straightforward than it could be.
The whole "abstraction is good because it allows us to build large complex systems" notion is all too common in beginning courses in programming/software engineering architecture, and it tends to make people think that large complex systems are also good. Thus the feeling that somehow all software should be large and complex, and the resulting architecture-astronautism and disturbingly inefficient software. I completely disagree - abstraction should be taught as being a necessary evil for managing complexity, for use only when that complexity is actually justified and cannot be simplified further. Abstraction hides complexity but does not eliminate it; in fact it could be said that it probably adds to it. Code hidden by abstraction is still code that gets executed, consumes resources, and could contain bugs.
I would like to second a lot of you're thinking here. I know it's a bit cliched to bring up rails, but I believe this is why a lot of the magic trips people up. It seems to me that the higher level the abstraction the more you end up NEEDING to know about it as you start straying from the tutorials. Nobody cares how puts gets text to the screen, but it doesn't take long before all the magic relationship and routing stuff becomes nagging issue, particularly for new comers and non full-timers. And thus, micro frameworks are becoming super popular for many and especially those jumping between languages/ecosystems regularly.
Also, open source projects could seriously do with some dev docs. A UML diagram or two wouldn't hurt either.
So, that's the difference between beginners and professional engineers, right?
If you use a framework (or at least a common pump_messages->update_ents->render cycle), it's a hell of a lot easier for other people to work on your code for a longer period of time (and those other people include yourself). Imagine if you decide to change your gfx_library with something new, especially if you had decided to scatter it's draw calls all over the "game logic" (instead of, say, a dedicated entity draw() method). What about when you start allowing data-driven entity updates? What about <insert practical concern here>?
To be fair, you take it too far (as I'd once done) and you destroy performance. So, eventually, you work out how to have nice architectures that still support the fast hacky stuff.
Anyways, the beginner is allowed to make such mudballs for a while--but no longer than necessary!
Sure, I couldn't get away with that in a AAA game. But you can still have separation of physics, game logic, networking, and drawing. Honestly my previous attempts at fancy architecture encouraged more intermingling of those than my simpler approaches (which is not to say that there aren't strategies that get the best of both, just that they're either hard to design or hard to use correctly for a beginner/amateur).
If anyone other than Carmack wrote this, I doubt it would be so well received so I'm glad he did.
We all have our own programming dogma that we love and defend religiously, but we should never stop asking if our code is truthfully, objectively, clear and easy to read, prone to bugs and/or runs efficiently. "Best practices" can get you 80% of the way there, but a developer should never stop questioning the quality of their code, even if it contradicts the sacred rules.
Back when I was writing real-time signal processing code, I spent quite a bit of time refactoring code from variations of styles A and B to style C. The problem Carmack talks about is even worse when some of those subroutines were in separate source files. Over the course of my refactorings, I was able to re-arrange and combine functionality in ways that were not possible with the discrete functions. I was able to pull operations out of inner loops that repeatedly and expensively calculated the same values. I found and fixed all sorts of actual or potential bugs in doing this. The original code was extra hairy, though, because it was written for DSPs, not general-purpose microprocessors.
As a side note, the original code contained large numbers of manual loop unrolling optimizations like noted in the email. I actually saw a performance increase from removing them. Same in some cases for manually inlining the function calls. From what I could tell, writing simpler, inline code made the optimizer much more efficient.
That "premature optimization is the root of all evil" is now a fairly uncontroversial statement, but people don't realize that this insight not only applies to performance. The OO/functional/whatever-current-fashion movement almost universally starts cargo-culting with the main principles, no longer thinking about why this or that is done.
To come back to the point at hand, regularly writing all kinds of code, from embedded to desktop to mobile, I can only nod vigorously at Carmack's observations
Always writing minimal functions doesn't work 100% of the time, but is unfortunately often enforced vehemently in large teams, as the ones in charge don't trust the rest to be sensible. There should always be a good reason to follow this or that rule, but when the rules of the team are broken intenionally, it'd better be documented to avoid confusion later on!
Wouldn't in-lining make unit testing more difficult?
Admittedly I am not a very experienced programmer, but I thought the general line of thought with regards to making your program easier to test would be that each function should do as little as possible.
Yes it would, but Carmack is advocating the inlining of functions that deal with game state. These tend to be kinda hard to test in isolation anyway. But he does also advocate keeping small helper functions pure.
The algorithms we were implementing were very hard to test using conventional unit test techniques. The only way to properly test this code was to run the full system with recorded input data. We used data extractions at key points in the pipeline to verify that the code was working correctly. With a series of extractions it was possible to figure out where the problem was, and with an understanding of the algorithms it was possible to figure out what it was. The extractions themselves could be placed at arbitrary locations.
> Wouldn't in-lining make unit testing more difficult?
That depends on the nature of the inline code. If it simply unrolls a local loop that has no side effects, then it's structurally identical to the original loop, but (in some cases) faster. This is demonstrated by the fact that some compilers can be coerced to inline certain repetitive actions originally written in the form of loops, as a speed optimization.
There's an interesting game programmer problem here, that is somewhat alien to a coder like me who grew up on the web. Where for a web coder, statelessness is the default, and we have to work to recover and recreate state between 'frames', game coders live in the run loop - and so the assumption is that you have a repository of persistent global state to act on each frame.
Having noticed that he has a problem when multiple functions are all interacting with that same shared global state, it's kind of amusing that Carmack's reaction is to reduce the number of functions, rather than remove the global state.
At its core the problem game programmers run into is that game state is very globalized with a lot of dependency overlap. You can push around the data into different containers and declare dogmatic methods of access, but you always wind up with the same problems: The animation state depends on the physics. The rendering depends on the animation state. The physics of a local entity depend on its collision with the rest of the world. The results of physics depend on which things collided first. And so on and so forth.
And so games live within this environment of confusion over which things happen when. At every point there are a few defensive tools - queue up actions in a buffer, poll values instead of copying them, etc. - but the overall management of these concurrent, overlapping systems remains a challenging task lacking in silver bullets.
1. Substitutes comments for accurate and specific function names. Why better? Because comments can get out of sync with the code.
2. You can quickly see the sub-steps of the algorithm, rather than reading a multi-page-long giant function with a ton of comments.
When using this style, the inner functions are not visible outside of that source file (you can arrange this depending on your programming language). Then it's easy to make sure they are only called once within the source file, or only called appropriately.
That's because I agree with Carmack that functions called from lots of unrelated places are a terrible thing.
(Edited for clarity after people pointed out that it seemed like I was just advocating for Carmack's style A or B.)
If they aren't called from anywhere else and they're only called once (in the parent), it might be better to inline them.
Doing so goes against the urge to decompose as much as possible but it'd make the code easier to follow for the next guy. "What does do_small_thing_X do?"
Even when the next guy is you, a year from now. Do you really remember what do_small_thing_X does?
Yes, I do remember. If the function name isn't sufficient, you need a different decomposition of the problem.
Another advantage of doing it my way is that you can put multiple comments inside those "small" functions if you need to. So you get two levels of decomposition. That really helps if your overall algorithm is broken into smaller parts that still need some explanation.
> Do you really remember what do_small_thing_X does
I don't need to wait a year, I forget what functions do the next day. So I try very hard to give them descriptive names. So I don't have to remember (and I just have to read).
"1. Substitutes comments for accurate and specific function names. Why better? Because comments can get out of sync with the code."
Can you explain this a bit better? In my experience function names can just as easily get out of sync with the code. I've worked on many codebases that were full of small functions with misleading names.
Function names certainly can get out of sync, just as comments can. But my experience is that it's less of a problem.
Actually, there is an additional and probably much more important reason that I prefer "functions over comments", and that is the functions can be nested.
With comments, I often find myself needing a big comment that describes the next several chunks of things, and each of those chunks has some comments, too. So call those "level 1" and "level 2" comments.
But what if you have something that really "should" be a level-two comment (because it's just one small thing that doesn't have subdivisions), but it comes after a level-one comment? Now you need an end delimeter for level-one comments, like this:
/* *****************
done with that
******************* */
Now at this point, your code is nasty and non-readable and it's not obvious that things have been kept in sync over time. We could just avoid all this ambiguity by using nested functions that are nonetheless only called from one place and thus _could have_ been manually inlined in theory (but, per my practice, are not).
I am not convinced thats all that better than inlining and then using an editor with support for code folding. You can still get a high level glance at the substeps but are 100% guaranteed that the blocks of code are never called anywhere else instead of that just being a module-enforced convention.
All those small procedures have to be defined somewhere, his style A and B are about where they are defined. His point is that inlining them guarantees that they are not called from somewhere else and that code folding can be used to structure the code.
what happens when `do_small_thing_one()` gets changed enough that the name of the function is no longer representative of the code? Comments and method names can fall out of sync. Comments at least require less to update and don't require re-factoring code in multiple places.
A few questions: Are there any good examples of code written in this style (e.g. by Carmack or Blow)? When I tried this style, I would frequently end up with 800+ line functions: is this what the code is supposed to look like in the end, or should I be refactoring earlier? When I do end up refactoring, it's often hard to switch to a functional style. There are complex dependencies between the different "minor" functions, and the easiest route forward seems to be to replace the function with a class: minor functions become methods, and the function-level local variables become instance variables, etc. Also, this is a small issue, but how do you deal with minor functions that "return" variables? I typically wrap the minor functions in brackets, and I declare the "returned" values as local variables right before opening bracket, but it looks strange.
> "The function that is least likely to cause a problem is one that doesn't exist, which is the benefit of inlining it."
That statement (at least taken in isolation) is false. Inlining it means that you're still executing the exact same code. If it had problems as a function, it still has problems when inlined.
But that isn't the problem that Carmack is trying to address. He's concerned about bugs caused by lack of programmer comprehension of the code's role in the larger function. It's a valid concern. But inlining it makes it harder to find problems in the details of what the inlined function does (or even to realize that that's where the problem is, or maybe even to realize that there's a problem at all).
All styles help with some problems and make others worse. The answer isn't a style, it's good taste and experience to know when to use which style.
Inlining it means that you're still executing the exact same code. If it had problems as a function, it still has problems when inlined.
But if it's inlined, it's no longer a function. ;)
What he's saying here is that the function itself was fine and free of bugs but that there is a problem for the programmer. The programmer's understanding and expectation of what the function does isn't in that it affects state in a way the programmer didn't know or expect. What the function does becomes much more obvious and controllable when you inline the function's body.
I'm assuming this was posted because it was brought up during Jonathan Blow's talk last night: http://www.twitch.tv/naysayer88/b/572153991 (which have been interesting, (and Twitch is a great format for these))
An aside on tool interactions: For the past year or so I've been using a new way to do syntax highlighting[1][2] that works really well for highlighting the dataflow in large functions (whether well or poorly written): http://i.imgur.com/EmFMTtv.png
I've seen a plugin to some ide, can't remember if it was eclipse or pycharm, that would highlight the last three variables you had selected. Similar to what most editors do with the current variable under cursor but with a short memory.
I'm not sure it's reasonable to characterize this as due to a "bug" though---the software correctly implemented the specified control laws, but those laws had some unanticipated properties, and fixing it required some new developments in control theory.
The 1993 crash was due to Pilot Induced Oscillation (PIO). This is a general term for situations when the pilot makes inputs to stabilize an airplane, but the inputs instead end up exacerbating the instability. A simple example of how this could happen is if the control inputs for some reason take effect with a time delay: the airplane pitches up, so the pilot tries to push it down, after a moment the transient passes and the plane pitches down so the pilots pulls up, but the previous input amplifies the downwards movement so the pilot pulls up harder, etc.
Several of the first generation of unstable fly-by-wire airplanes had problems with PIO. Unlike conventional aircrafts, where the rudder positions exactly follow the position of the stick, here the desired rudder position is calculated as the sum of two inputs, one calculated from the stick position, and one calculated by flight control software to dampen instabilities.
Early versions of the software was "rate limited", i.e. at each iteration of the main loop the software calculates the desired rudder position and then moves the rudders towards that position at the fastest rate the rudder actuators allow. However, that leads to problems when there are very large transient stick inputs: because the rudders take some time to move, the largest rudder deflection occurs with some delay after the largest stick input (see figure 6 in [1]).
In the 1993 crash there was a wind gust causing a pitch movement, and both the pilot and the flight control software provided a compensation. The sum of the two signals was big enough to hit the rate-limitation, so the response of the airplane was strange, the pilot gave several more large inputs, and there was PIO.
Incidentally, one of the YF-22 prototypes crashed for basically the same reason, even though they run different software. The solution was to develop some new "phase compensation" methods for designing controllers [1].
Your comment implies there was some fault in the software. The wikipedia link explains that the crash was due to pilot-induced oscillation (a coupling between the plane's response to inputs and the pilot's reaction time).
Basically, the plane would have been better off cutting off input from the pilot and flying on its own.
You're right, it wasn't the software as such (more like the design of the system).
I just read more about PIO and it's funny, it reminds me of a short story I read a long long time ago, written by Arthur C Clarke, I remember the scene in it where a pilot is remote controlling his big space ship or plane of some kind, while standing on the ground. But because the remote is going through a satellite, there is a feed back delay, say 1 second or so. So when he tries to compensate for a wrong turn, a flavor of PIO is induced and the ship crashes.
Think that particular story was written in the 40's, good foresight of Mr. Clarke.
I like Clarke also, but this is less an instance of good foresight on his part than it is an understanding of feedback control theory. Control systems analysis advanced quite a bit in WW2 and by the time that story was written, the issues caused by low control bandwidth were probably well known.
"Avoid globals" is a fairly common (and good) truism for programmers of all stripes. But casting it in light of the central (and easily digestible) tenet of functional programming makes it much more approachable. Smart (but sometimes insufferably pompous ) proponents of functional programming should take notes.
Steve McConnell's classic "Code Complete: A Practical Handbook of Software Construction" cites a number of studies of real systems from the 1970s and 1980s with some surprising results. Some studies showed that function size inversely correlated with bug counts; as functions increased towards 200 LOC, the bug count decreased. Similar, another showed that shorter functions had more bugs per LOC and reduced comprehension for programmers new to the system. Another study showed that function complexity was correlated with bug count, but size alone wasn't.
There is an interesting parallel between Mr Carmack's "inlining" observations and one of the sessions I went to at Strange Loop this year. Jonathan Edwards was trying to beat back "callback hell" (i.e. unpredictable execution order leading to unpredictable side effects) by radically simplifying the control flow of his programs and keeping the execution model dirt-simple. Both would appear to argue that it's best to arrange heavily stateful code in a simple linear sequence, and use a top-down execution model, so that stateful effects are clear and easy to predict.
That being said, I've seen procedures that followed this sort of approach that were thousands of lines long. Even if we could have cut down on the ridiculous number of conditionals in that code, most of the state at that scale asymptotically approaches an undifferentiated mass of global variables. The result is testable and maintainable only via heroic effort. There have got to be limits to this kind of approach. (For Mr Edwards the solution was to break the whole thing up into a sequence of composable views, or lenses, with the interface between each stage being well-defined.)
I wonder to what extent Mr Carmack's pivot to pure functions is simply an acknowledgement that there were much better ways to refactor the code than the mess of one-timer procedures that probably seemed like a good idea the first time through...
Seems like everyone misreading the intent of the post. He is NOT advocating inlining code in this post. He is suggesting that FP is better at solving the same problems in a more sensible way.
The email was written in 2007. In there, he advocates the inlining of single-use functions into god functions as it reduces the risk of these functions being opted into other routines, especially when they all deal with shared mutable data.
Single-use functions are explicitly singled out in his email; he mentions that he does not encourage duplicating code to avoid functions.
| "In almost all cases, code duplication is a greater evil than whatever second order problems arise from functions being called in different circumstances, so I would rarely advocate duplicating code to avoid a function"
The blurb at the front indicates the intent of his post. Since then he has favoured a functional-programming approach - don't inline your functions, but avoid making your functions rely on mutable/larger scope states. Pass in everything that is needed by the function through parameters. Avoid functions with side-effects, encourage idempotence. That way, reusing the function does not lead to unintentional side-effects.
He also mentions that should you still decide to inline, " you should be made constantly aware of the full horror of what you are doing.".
it is often better to go ahead and do an operation, then choose to inhibit or ignore some or all of the results, than try to conditionally perform the operation.
The way we have traditionally measured performance and optimized our games encouraged a lot of conditional operations [...] This gives better demo timing numbers, but a huge amount of bugs are generated because skipping the expensive operation also usually skips some other state updating that turns out to be needed elsewhere.
Now that we are firmly decided on a 60hz game, worst case performance is more important than average case performance, so highly variable performance should be looked down on even more.
Two words: Battery life. In case of mobile devices, this is not sound advice.
Is this covered by the update in John's introduction?
To make things more complicated, the .do always, then
inhibit or ignore. strategy, while a very good idea for
high reliability systems, is less appropriate in power and
thermal constrained environments like mobile.
After reading this, I feel a lot better about the huge main() function I wrote for htop. I've always thought about splitting it into many functions, but somehow keeping it all flowing in sequence just made more sense.
I never wrote too many C or C++ on the desktop, but often ended up refactoring my embedded code from one style to an other.
After a while I realized this is simply my way of understanding the code better, and making sure I haven't missed anything.
The direction (inlining or breaking things to functions) almost doesn't matter. What matters is working with the code.
It's not so strange If you think about it, designers understand things by sketching and taking notes, that's why you see designers run around with their moleskins.
> If a function is only called from a single place, consider inlining it.
Funny because it's backward. If a code is duplicated, consider to make a function if the pieces of code are the same semantically. (Two pieces of code which are the same at a given time can diverge over time and you don't want to miss that. Only analyzing the sense of what you're doing (=semantic) gives you the answer.)
Never add fancy things (like adding a function which is not a function) in your code because code is not fancy, it causes bugs.
> If a function is called from multiple places, see if it is possible to arrange for the work to be done in a single place, perhaps with flags, and inline that.
Well yeah, fix the semantic if it needs to else do nothing.
> If there are multiple versions of a function, consider making a single function with more, possibly defaulted, parameters.
Well yeah, fix the semantic if it needs to else do nothing.
>Minimize control flow complexity and "area under ifs", favoring consistent execution paths and times over "optimally" avoiding unnecessary work.
The right thing to do is to never optimize unless it's to slow and you've identified the first bottleneck. "Never optimize" means: write the naive code correctly (without performance aberation like adding element in an array).
> To sum up:
Stop fancy. Stop optimization. Stop thinking about code syntactically (=the succession of operation gives the good result). Think constantly about your code semantically.
I don't have a great deal of experience tuning code, so would someone be able to explain how inlining is related to mutation of state? I'm not John Carmack or Brian O'Sullivan, and I'm not sure if I understand how purity would make things better.
We do inline our code in Haskell sometimes, but usually the real gains (in my limited experience, with numerics code) are to be had by unboxing, FWIW.
Firstly, inlining has nothing to do with state mutation. He just happens to be talking about a codebase that does a lot of state mutation - eg. a video game. Therefore the functions he's talking about inlining are state mutating functions.
It also sounds like performance is a secondary, but still important, concern in this post. What he's really getting at is what the typical modular programming style does to our awareness of details and therefore our ability to understand and optimize our programs. The commonly held conviction is that smaller functions are better for writing understandable and correct code. He's saying this isn't necessarily the case - especially not when you're trying to optimize code and understand the interrelations between the state it's mutating. Modularity can often produce deep stacks while hiding and scattering state mutations. It can also obscure interrelations you should be aware of. In the kinds of scenarios where correctness, comprehensibility, and performance are tantamount having one big long function might just be better.
As a software automation engineer, I've made this argument in the past with regards to UI/systems test code bases.
Heavy modularization makes a ton of sense with utility code made to create and tear down fixtures, as well as with general utility functions like navigation through a user interface to get to the initial point of testing.
However, in the test, where you need to have complete understanding of the sequence of events in order to keep the test valid, it's much better to inline nearly everything that would affect simulated user or client flow even if that means duplication between tests.
That's exponentially more true when more than one person/team/org/whatever would be maintaining different tests or test areas. The last thing you want to do at that point is share test sequencing code, since it's so easy to subvert the flow in other tests using it by mistake.
It's a hard argument to make, because everyone gets SPOT, yo, Fowler rules, etc. They aren't wrong, but it really only applies when the interface is everything and how you fulfill the interface is irrelevant.
For some types of code--frame-accurate games being one, tests being another--the order of events is paramount. IMO, even mature patterns like Selenium's Page Object Model gets this one wrong by encouraging test flow code to live in POM methods.
There are absolutely times where optimizing for understandability and being paranoid about implementation changes is the way to go.
>> It also sounds like performance is a secondary, but still important, concern in this post.
Not exactly. He points out that in real time systems, worst case execution time is more important than average execution time. You have to render a video frame in 1/60 of a second or it will need to be displayed twice. In that case, getting the job done faster on average doesn't matter. This can change a bit if something like power consumption becomes relevant - then you've got conflicting requirements.
Real time keeps performance a top priority, we just look at a different metric.
I think the article was about "manual inlining" rather than the kind of automatic inlining that a compiler does. Its less about raw perfomance (inlined functions have less function call overhead and open opportunities for cross-function optimization) and its more about correctness and predictability of runtime. For example, he mentions that he prefers having a dumb and sequential code flow that always runs at 60 FPS than something clever and full of conditionals that runs at 120 FPS most of the time but falls to 30 FPS every once in a while. In addition the predictable runtime there are also many bugs that happen when stateful functions are called in the wrong order and this is less of an issue if you always call them once in the same order. For example, he mentions that he would rather check for `health <= 0 && !killed` at the end of your game loop instead of potentially calling KillPlayer() in 20 different places, which might end up doing slightly different things in each frame.
As for pure code, the reason he has become more bullish about functional programming is that it by definition is less susceptible to all these subtle order-of-execution issues. You are free to structure your code in whatever way you like and split it into as many functions as you want and still have the peace of mind that you will never access an uninitialized variable or use a dead object.
"inlining" means that instead of hand-writing blocks of manually inlined code, you write a function, which can be inlined for you.
That's backwards: Carmack advocates to avoid writing such functions, manually inlining their code into the caller (with the possible exception of pure functions).
In his context, it really has to do with references.
So, if I have a value A, and it's a reference type(either by pointer, or by just the nature of the language), then if I pass that object into function DoSomething, DoSomething may change A without my knowledge, and cause behaviors further on that I wasn't expecting.
If I inline DoSomething, I see exactly what I'm doing to A, what I'm changing on it.
Inlining always works, by definition, otherwise your compiler is buggy.
In side effecting languages, inlining cannot make function calls disappear, unless the compiler can convince itself that it's safe to do so.
If an expression calls f() twice, and f has a side effect, then the inlined version of the code has to do that side effect twice, exactly if the non-inlined function were called, just without some of the overhead of a function call.
(On a different note, in a language like C, inlining a side effect actually improves safety. If we have f() { global++ } then f() + f() is safe and has the effect of incrementing global twice, whereas global++ + global++ is undefined behavior.)
Sorry, you're using a slightly different definition of inlining than I was. Fortunately, it still demonstrates the same point: you have to be aware of state/side effects in order to do inlining.
In a pure and total language the two fragments are always the same. No further thought needed.
Not really. Inlining can be done by mechanically incorporating the called function into the caller, in a way that respects lexical scopes. This will result in identical semantics. Then the resulting bloated code is optimized: subject to caching optimizations, common subexpression optimizations and whatnot. These have to obey the usual rules for not deleting or reordering side effects. The issue you're referring to boils down to the fact that in an imperative language, we cannot assume that two occurrences of a variable X can be replaced by the same value, because X may have been assigned in between. So compilers have to do flow analysis to discover in what part of a call graph does a given variable have a stable value.
E.g. if we have a silly C function like
int accumulate(int x, int y)
{
global += (x + y);
}
and then call it in two places:
accumulate(s, t);
accumulate(u, v);
the inlining is almost like just macro-expansion of the above into:
{
int x = s; /* "parameter" passing */
int y = t;
global += (x + y);
}
{
int x = u; /* "parameter" passing */
int y = v;
global += (x + y);
}
we don't have to care about side effects when we are doing this expansion. That's the job of later optimization.
The later optimization pass can worry about things like whether global is volatile-qualified. If it is, then the best that can be done is:
global += s + t;
global += u + v;
these can't be merged or re-ordered. And so this stays faithful to the original function calls. If global isn't volatile, then more can be done:
If the compiler has the full source of f() available at compilation time, it knows whether it can convert between those two. (Though not all compilers are good at knowing the memory-usage implications of doing that kind of commoning operation.)
(And, for that matter, whether it can convert that to "f()<<1".)
Sure, and thus inlining does not always work. To be clear, what I probably should have said was beta reduction, but I wanted to keep the terminology of the op.
The point being that one has to be aware of state in order to execute an inline/beta reduction. In pure and total[0] code the above can only ever change the execution speed, never the meaning.
[0] And of course "pure and total" just means "pure" since non-termination is an effect.
SHL EAX,1 and ADD EAX,EAX are the same, time wise. The only difference is that the A flag (auxiliary carry [1]) is undefined for SHL and defined for ADD. SHL EAX,n may be faster than n repeats of ADD EAX,EAX, but there are other ways to do quick multiplication by powers of 2 though.
[1] The auxiliary carry reflects a borrow from bit 4 to bit 3, or a carry from bit 3 to bit 4. It's used for BCD [2] arithmetic, and there is is no direct way to test for it.
Shift definitely outperforms "mul"; it may or may not outperform "add", but it'll probably outperform a series of adds to implement a larger power of 2. And if you're using the result as part of an address, you can use [eax*2 + ...] as an operand and the shift will happen as part of addressing.
> If something is going to be done once per frame, there is some value to having it happen in the outermost part of the frame loop, rather than buried deep inside some chain of functions that may wind up getting skipped for some reason
> I do believe that there is real value in pursuing functional programming, but it would be irresponsible to exhort everyone to abandon their C++ compilers and start coding in Lisp, Haskell, or, to be blunt, any other fringe language.
"Here, let me dismiss functional programming, and by the way OCaml and other 'non-pure' functional languages don't exist, and functional programming languages aren't useful for anything 'real' so you should do your functional programming in C, and also you may want to dump everything in one long-ass function because I don't like deep stacks".
I believe in both functional and encapsulated patterns. It all boils down to scope of the task at hand. There is a certain kind of beauty in programming in a pattern than can compliant to a particular interface and a pattern that's efficient and scoped to the result required. Inline is a great way to encapsulate in a functional way.
Seems like a big argument against type C is that it would be more difficult to unit test the code. The nice thing about A/B (which are essentially the same to me) is that each subroutine becomes an easier target for unit testing.
No, the problem with style A and B is that smallFunction() might have only been correct under the context of it executing inside largeFunctionA(). IMO this risk is actually increasing even more if it originates from a refactoring from style C, since you didn't design smallFunction() from bottom up considering all possible use cases, you most likely just highlighted a random block in largeFunctionA() because it was getting too big and clicked "extract method" in your IDE.
Imagine two months later someone writing largeFunctionB() is browsing around the code and finds smallFunction(), thinking it will do the job he requires but actually it has a hidden bug that was never triggered under the context of it executing in largeFunctionA or under the limited input range that largeFunctionA was using.
See in particular this paragraph from the article:
Besides awareness of the actual code being executed, inlining functions also
has the benefit of not making it possible to call the function from other
places. That sounds ridiculous, but there is a point to it. As a codebase grows
over years of use, there will be lots of opportunities to take a shortcut and
just call a function that does only the work you think needs to be done. There
might be a FullUpdate() function that calls PartialUpdateA(), and
PartialUpdateB(), but in some particular case you may realize (or think) that
you only need to do PartialUpdateB(), and you are being efficient by avoiding
the other work. Lots and lots of bugs stem from this. Most bugs are a result
of the execution state not being exactly what you think it is.
Rather than conditionally execute code (to avoid performing an unnecessary expensive operation) always execute the code, then discard the result if it is unneeded. The idea being that the performance gained by avoiding the unnecessary operation is not worth the complexity added.
As a minor note, conditional checks can have significant performance impacts if you don't consistently handle the conditional.
As an example performing an operation every other frame can cause your CPU to thrash due to always taking the wrong path. (I of course am oversimplifying and OOO CPUs are quite complex)
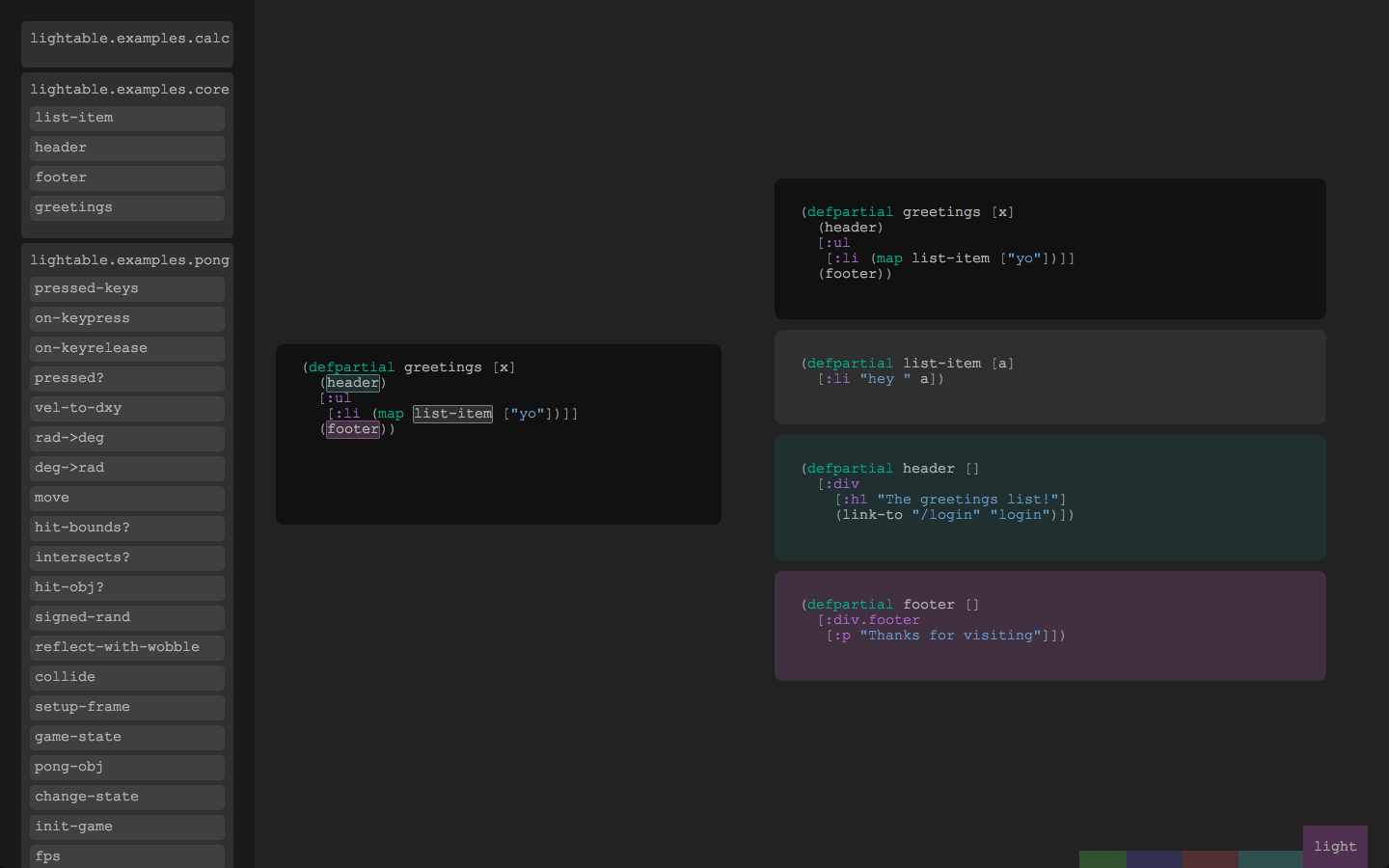{kind=link}
{kind=link}
Lately, I've noticed a pattern emerging that I think John is referring to in the second part. The situation is that often a large function will be composed of many smaller, clearly separable steps that involve temporary, intermediate results. These are clear candidates to be broken out into smaller functions. But, a conflict arises from the fact that they would each only be invoked at exactly one location. So, moving the tiny bits of code away from their only invocation point has mixed results on the readability of the larger function. It becomes more readable because it is composed of only short, descriptive function names, but less readable because deeper understanding of the intermediate steps requires disjointly bouncing around the code looking for the internals of the smaller functions.
The compromise I have often found is to reformat the intermediate steps in the form of control blocks that resemble a function definitions. The pseudocode below is not a great example because, to keep it brief, the control flow is so simple that it could have been just a chain of method calls on anonymous return values.
I make a point to call out out that the temp objects are scope-blocked to the minimum necessary lifetimes primarily because doing so reduces the amount of mental register space required for my brain to understand the larger function. When I see that the first bar and baz go out of existence just a few lines after they come into existence, I know I can discard them from short term memory when parsing the rest of the function. I don't get confused by the second bar. And, I don't have to check the correctness of the whole function with regards to each intermediate value.