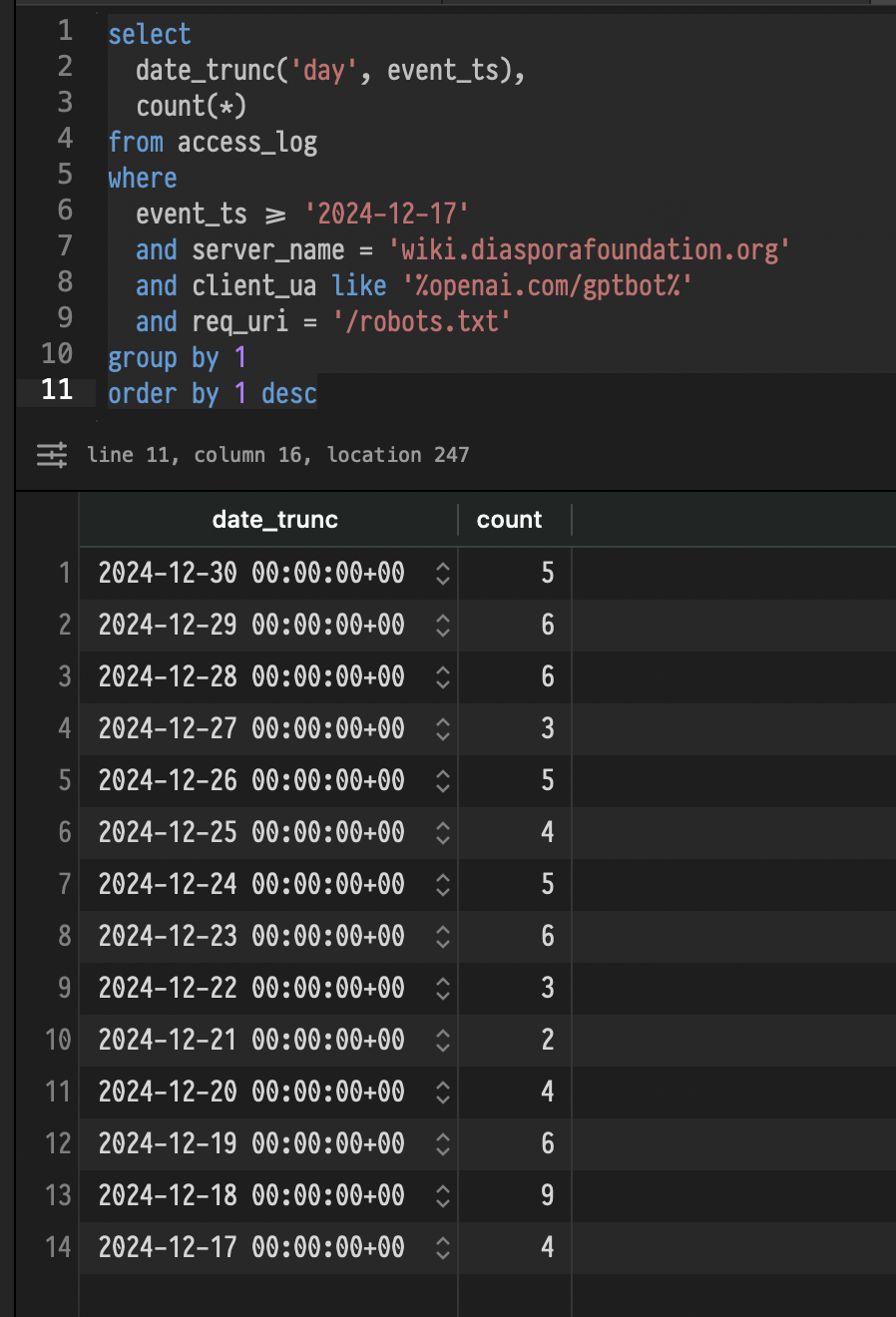
the robots.txt on the wiki is no longer what it was when the bot accessed it. primarily because I clean up my stuff afterwards, and the history is now completely inaccessible to non-authenticated users, so there's no need to maintain my custom robots.txt.
:/ Common Crawl archives robots.txt and indicates that the file at wiki.diasporafoundation.org was unchanged in November and December from what it is now. Unchanged from September, in fact.
they ingested it twice since I deployed it. they still crawl those URLs - and I'm sure they'll continue to do so - as others in that thread have confirmed exactly the same. I'll be traveling for the next couple of days, but I'll check the logs again when I'm back.
of course, I'll still see accessed from them, as most others in this thread do, too, even if they block them via robots.txt. but of course, that won't stop you from continuing to claim that "I lied". which, fine. you do you. luckily for me, there are enough responses from other people running medium-sized web stuffs with exactly the same observations, so I don't really care.
Here's something for the next time you want to "expose" a phony: before linking me to your investigative source, ask for exact date-stamps when I made changes to the robots.txt and what I did, as well as when I blocked IPs. I could have told you those exactly, because all those changes are tracked in a git repo. If you asked me first, I could have answered you with the precise dates, and you would have realized that your whole theory makes absolutely no sense. Of course, that entire approach is mood now, because I'm not an idiot and I know when commoncrawl crawls, so I could easily adjust my response to their crawling dates, and you would of course claim I did.
So I'll just wear my "certified-phony-by-orangesite-user" badge with pride.
Gentleman’s bet. If you can accurately predict the day of four of the next six months of commoncrawls crawl, I’ll donate $500 to the charity of your choice. Fail to, donate $100 to the charity of my choice.
Or heck, $1000 to the charity of your choice if you can do 6 of 6, no expectation on your end. Just name the day from February to July, since you’re no idiot.
{kind=link}
I’m just seeing: https://pod.geraspora.de/robots.txt
Which allows all user agents.
*The discourse server does not disallow the offending bots mentioned in their post:
https://discourse.diasporafoundation.org/robots.txt
Nor does the wiki:
https://wiki.diasporafoundation.org/robots.txt
No robots.txt at all on the homepage:
https://diasporafoundation.org/robots.txt