Ah! Well as a systems programmer, it's not so rare. FDs are really not a friendly interface, and I'd love a better interface (FDs have their quirks), but as an application programmer, it's really sad we don't take advantage of FD passing to build more modular programs. For instance on desktop operating systems, you pass paths, not capabilities to use files, and the norm is giving programs access to read large swaths of user data. This is not secure, and it's one of the issues well-passed FDs could help solve. In general, despite the challenges in making them secure, I'd strongly advocate for more modular and integrated applications.
As for the seeking abstraction, it fits well with other buffered device driver information streams. Yes, it's a complicated and confusing interface, but the key thing is it allows you to share an OS/system/hardware level resource between multiple programs. We want to take advantage of that. It's the abstraction we've got sure, but it's what we do with it that counts!
My idea of operating system design is you do pass capabilities; actually, a message can only pass capabilities and byte sequences, and all I/O must use that interface. Furthermore, "proxy capabilities" are possible; i.e. a program can make up its own capabilities and send them to other capabilities it has access to, and then use those capabilities that it had made up to receive messages and do something with them (such as forward them to other capabilities; this is a simple case that can be used for logging or for revocable capabilities, but more complicated uses are possible). Actually, my operating system design does not have file paths.
This makes it more secure than how UNIX is doing it (if it is designed properly; the way to do this is to avoid making the interface too complicated, since a complicated interface would also increase the complexity of the more advanced uses of proxying), as well as more flexible (and allows modularity). It is possible to then allow to read only a part of a file, or to decompress (or compress) automatically without the application program knowing about the compression, or to log accesses, etc.
However, for seeking it will require a message containing a command to request to seek the file, since "seeking" is not a function known to the operating system, and there is no system call for "seeking"; the system calls are sending and receiving messages, waiting for objects, discarding capabilities, and creating new proxy capabilities.
But, the seeking command and others would be standardized and defined in the operating system specification, so that programs can use them, even though the system call interface does not directly have such a command, and proxies can handle messages in whatever way they want to (since they are just arbitrary byte sequences and/or capability passing).
(My own operating system design also allows "userspaceification of POSIX"; the kernel is not POSIX, but a compatibility layer (for at least much of POSIX, but maybe not all of it necessarily) can be made in user space if it is desired.)
Generally this aligns with what the Redox kernel is currently transitioning into, with a few limitations in order to retain compatibility for the (quite larger number) of applications we "need" to support.
> My idea of operating system design is you do pass capabilities; actually, a message can only pass capabilities and byte sequences, and all I/O must use that interface.
File descriptors and capabilities are very similar, and Redox already uses file descriptors, which are handled by scheme daemons, for most interfaces in general. I'm working on a _virtual memory-based capability_ RFC, on top of which the POSIX file table can be implemented in redox-rt (userspace) without forcing (some) POSIX semantics onto capabilities.
> Actually, my operating system design does not have file paths.
We're eventually going to switch fully to the openat* family of path calls, which would generalize the open syscall into a scheme call that sends a capability reference (dirfd), a path, and returns a capability.
> However, for seeking it will require a message containing a command to request to seek the file, ...
But that the cursor to be stored either by the client (requiring extensive messaging for each non-absolute IO call), by the server (requiring unnecessary state since almost all positioned IO nowadays is random-access), or currently, in the kernel. I'd like this state to be stored in userspace, as the article mentions, but this will first require assessing whether it would be feasible to break compatibility for this, or at least "performant compatibility".
> the kernel is not POSIX, but a compatibility layer (for at least much of POSIX, but maybe not all of it necessarily) can be made in user space if it is desired.
This is exactly what Redox is transitioning to: a kernel that's not necessarily Unix-like, with the bulk of POSIX logic implemented in userspace (redox-rt).
I have read Redox documentation; mine is in many ways very different (both the working of high-level code and of low-level code, although some goals and features are similar, e.g. "forcing all functionality to occur via file descriptors" is mandatory for all I/O in my system (although they are "capabilities"), but mine does not use namespaces like Redox does, and requires capabilities that the program uses to be passed to it in the initial message that it receives (which is the only way to receive a message without already having a capability; if the initial message does not include any capabilities then the program would be immediately terminated since it cannot do any I/O)) from Redox and from other operating systems. (Mine is also meant to be a specification independently from the implementation; so it would be possible to write an implementation in C or in Ada or whatever else, and the different components implemented independently can be used together.)
> File descriptors and capabilities are very similar
Yes, and it is what I thought too, although my idea of these "proxy capabilities" is simplified compared with UNIX file descriptors in many ways (it is something like only having UNIX sockets, created using the socketpair function, and with SCM_RIGHTS messages as well as bytes; however, there are some significant differences too).
> We're eventually going to switch fully to the openat* family of path calls
I also thought that a POSIX interface can use openat and this is better than using open etc, although my idea of operating system design does not have that either; there are no file paths.
> But that the cursor to be stored ... I'd like this state to be stored in userspace ...
Yes, and I had also considered such things. One disadvantage of requiring the client to specify the file position is that it cannot be used with non-seekable files. However, it may be possible to have a separate POSIX and non-POSIX interface (and then the POSIX interface can be implemented in the POSIX library, which will not be needed by non-POSIX programs); the non-POSIX interface might not need to use the same interface for seekable vs streaming files (a proxy can be created (in user space) if it is necessary to use a seekable file where a streaming file is expected).
I had made my own ideas independently, although there are many similarities (as well as many differences; I am describing some of them below). One difference with mine is to make a specification, and that multiple independent implementations of the specification may be made.
My ideas are like a actor model in some ways, though.
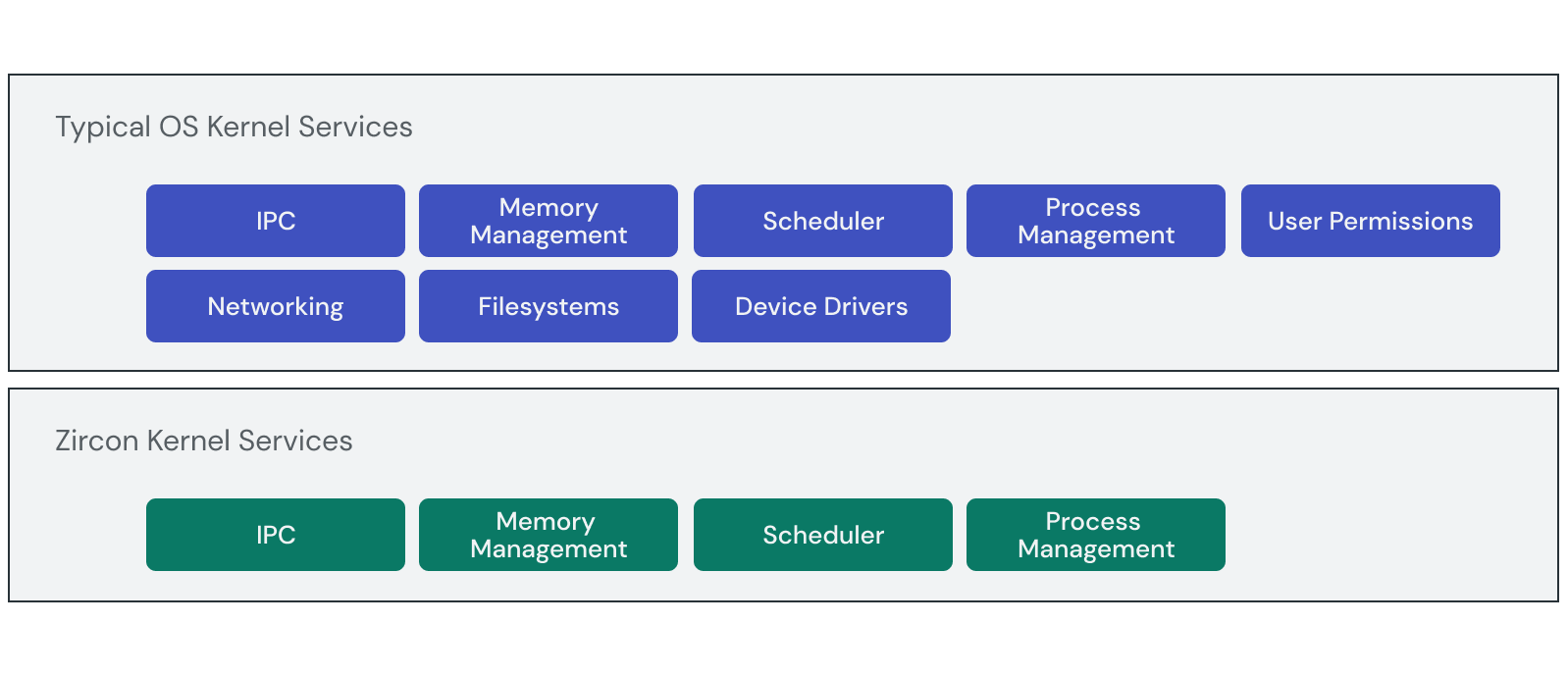
Looking at [0], my idea is very similar than Zircon kernel services. However, there are many differences than what is described by [1]. In mine, an implementation might include some additional features in the kernel, although this is just an implementation detail; user programs don't know the difference of if they are kernel services or external programs (since this is how the security model of my system is designed to work).
Mine has only one type of object for IPC rather than five; it is similar than what is called a "Channel" in Fuchsia (although it is not exactly the same, but it is a similar idea). It is the only kind of kernel objects that user processes are able to see.
In mine, process management and hardware support services are not directly exposed by the system call interface; they are only exposed by IPC channels.
Like Fuchsia, mine has no ambient authority. However, proxy capabilities are used to provide security and many other features (e.g. logging accesses, simulating error conditions, transparent compression, network transparency, revocable capabilities, etc). A program receives an initial message when it starts, and this initial message will contain IPC channels (possibly in addition to other data).
Mine does not inherently have namespaces. Files can only be accessed by capabilities, and files can contain links to other files; there are no directory structures and no file names. There is a "root filesystem" but that is only needed for purpose of initializing the system; most processes cannot see it and have no way of identifying it even if it could see it. However, when running POSIX programs, a POSIX-like namespace can be emulated by using a file containing key/value lists which work similar than Fuchsia namespaces in some ways (although such features are implemented entirely in user-mode libraries; the kernel knows nothing about them).
Also, mine does not use Unicode in any way. It also does not use JSON, XML, HTML, etc. Binary file formats are preferred; nearly everything will use binary formats. There are also many other significant differences (including UI stuff). I also consider that some other things are also no good, e.g. USB, UEFI, WWW, etc (this does not mean that it is not possible to write drivers/programs that can use them; it means that the fundamental specifications of the system deliberately avoid them, and that hardware/software designed deliberately for this system are designed to not need them).
I also would have locks and transactions, including the possibility that locks/transactions may involve multiple objects at once; this includes files, but may also need to include remote objects in some cases.
There is still i18n, l10n, a11y, etc, as well as many additional features such as "window indicators", "Common Data Format", "Command, Automation, and Query Language", etc. (The i18n does not work like Fuchsia though. For example, although language identifiers are still needed (although they are not limited to the ones included in Unicode, since it does not use Unicode), identifiers are not needed for date/time, etc (the library that deals with date/time formats can be modified to add whatever kind of calendars you want to do; the application program does not usually need the identifier for it, unless perhaps you want to reference entire months or years, but to do that requires specifying them with the data being processed by the program and is entirely separate from i18n preferences anyways).)
> As for the seeking abstraction, it fits well with other buffered device driver information streams. Yes, it's a complicated and confusing interface, but the key thing is it allows you to share an OS/system/hardware level resource between multiple programs.
As someone who has only dabbled in OS-level programming but recently had a use case that the seek interface seemed to work well for (parsing a file format that heavily used offsets to reference other parts of the data), I'm super curious about what you think the "complicated and confusing" parts of the interface are. (To be clear, I'm not doubting you; I'm asking because I suspect that my understanding might be more surface-level than I thought and there are probably some pitfalls that I might not be aware of!) Offhand, the only parts that seemed potentially confusing to me are the mix of signed and unsigned integers depending on the offset type (not sure if this was specific to the Rust implementation, but it used signed integers for relative offsets and unsigned for absolute offsets, which makes sense but maybe isn't something people would expect) and the fact that it's valid to seek past the end of a file (which I didn't need for my use case), but are there other subtleties that I didn't think of?
Not the OP but the complicated part to me is just that the fd has a global cursor which makes concurrent access require synchronization. The rust std::fs::File API at least makes this clear through mutability requirements but I imagine in other languages this either can cause a lot of bugs or requires a more complicated API to surface the functionality safely.
Ah okay, good to know. I never needed to read the same file concurrently with different cursors, so that might be why the API seemed deceptively simple to me!
One of the reasons the FD interface is so complicated is because there are many of the same operations, but they do different things to different underlying kernel implementations. In Linux, you have no standard way to tell what the underlying FD is. It's such a wide surface, different kernel surfaces might implement some of the many different file APIs (polling especially) slightly differently. In many cases, you can reuse standard tooling, but random ioctl calls mean you can't always reuse tooling. Nonstandard implementations of standard file calls can make it dangerous if you don't know which type of FD you have. So the good thing is they are standard, you use the same set of tools (file APIs) to operate with them, so it makes the system interface smaller and simpler, but it lacks the fidelity to create orthogonal meta programming over them. It sounds like an unimportant complaint that you can't tell the underlying type, but it also means most languages refer to FDs indiscriminately. You don't typically get type safety in languages for FDs (e.g. different class for an FD backed by shared memory instead of a real exclusive file), and even if you do have these classes you can't really guarantee they are correct at runtime if you get an FD from another process (e.g. over UDS from a child process), so languages leave FDs untyped.
About the global cursor, it's not an issue because you can dupe it to get a copy with a different cursor. So only references to the FD with that specific FD identifier have a location associated with itself, and that's because the OS can only look up the state on that FD. So dup gives cursor, but if an FD represents a physical seek, it might be the case that a dup'd FD actually does affect the functionality of the first FD by linking the two together, as that's a choice you can have in the kernel when implementing an FD. Dup also mean no new cursor.
So that's what I mean, the complexity of the real world means these objects are fundamentally different, and having the same APIs shoe horns them into something they're not. I've worked in large systems where you have very specific type-defined capabilities and messaging, and you end with different engineers creating many types which are equivalent but have independent implementations. This is another kind of nightmare because you need to convert many types to use them, which ends up being the source of a lot of boilerplate, and many things are nice, but it takes a very influential and powerful architect to curb complexity in such a system, and in the end complexity is inevitable, even if specific bouts of it spring up and get fixed, you end up with many many many APIs. So despite FDs being a very corset type API, it's brazen simplicity has eliminated an entire layer of complexity from our software.
Perhaps my complaints of FD's complexity are the misplaced pangs of an idealist, forgetting the importance of the big picture. FDs are the APIs we need, but not the ones we deserve. I think their role in the structure of our programs is far more important than their exact nature. Perhaps one day they can be replaced, but whatever does replace it will certainly have learned a lot from the humble FD.
I have nothing against FD passing, and indeed agree it’s unfortunate we don’t do more of it. An (almost-)everything-is-a-string (shell) language with object-capability powers is still something I’d like to figure out someday. The Lisp-2-ish way Tcl object systems approach this feels interesting, but still a bit off from a real solution.
My reading of TFA was that it’s rare for it to be important that descriptors sharing a description thus also share a file position. And shell-like redirection use cases really are the only case I can think of where that’s important.
> As for the seeking abstraction, it fits well with other buffered device driver information streams.
I don’t think I understand what you’re getting at here. My point was that having some objects (fds, whatever) support {fstat, read/write} only and others {fstat, pread/pwrite, mmap} only would get rid of the confusing user-visible notion of “file description”. Obviously I don’t expect this to happen, but it’s still nice to dream.
I think "(almost-)everything-is-a-string (shell) language" is not the way to do it; the command shell can be designed in a better way. But, my intention of design of the command shell programming language of a operating system is that it would have object-capability powers, too (and will be called "Command, Automation, and Query Language").
> but as an application programmer, it's really sad we don't take advantage of FD passing to build more modular programs.
For that programming languages need better unix socket (with SCM_RIGHTS) and directory-handle (openat & co) support. And of course windows does things differently so getting a portable abstraction would be difficult.
On Darwin, you can wrap a file descriptor wrapped in a Mach port right. That is leveraged pretty heavily on Apple's platforms for exactly these reasons.
Going straight to D-Bus feels excessive. Here's an 85-line file I had lying around that should cover most cases of FD passing: https://paste.rs/6FBFS.c.
APIs are/were designed for completeness more than friendliness. Speaking of sendmsg, the whole BSD socket API is plain horrible; it only takes a couple of uses to realize that you never want to use it directly again; you either make your own library on top of it, or a class, or whatever form of code reuse the language deems appropriate.
> the whole BSD socket API is plain horrible; it only takes a couple of uses to realize that you never want to use it directly again
That was my initial impression as well, but recently I’ve had to use it again and surprisingly did not find as bad as I remembered. Except, indeed, for the fd-passing experience, for which see my wrapper elsewhere in the thread (also other sideband stuff, but how often do you really need SCM_CREDENTIALS?).
The syscall/kernel-ABI people seem to love it as well—I remember reading an article that praised it for remaining so stable over its lifetime. I think these are actually two sides of the same coin: BSD sockets essentially layer a second ABI on top of C function invocations. It’s a tad more specific than generic ioctl-ish (selector, payload), but not that much, and the farther away you are from the happy path of send()/recv(), the closer it is to that (and the more extension capability the kernel programmer wants, and the more misery the userland programmer feels).
The Unix approach of exposing syscalls from libc essentially directly was a nice thought, but the sockets API feels like a reductio ad absurdum of it.
{kind=link}
As for the seeking abstraction, it fits well with other buffered device driver information streams. Yes, it's a complicated and confusing interface, but the key thing is it allows you to share an OS/system/hardware level resource between multiple programs. We want to take advantage of that. It's the abstraction we've got sure, but it's what we do with it that counts!