Since it took me 5 minutes to find, the terms of use of PaliGemma are not FOSS therefore not open-source. Like not on the list on https://opensource.org/licenses.
It's also quite ironic how on one hand ML companies feel entitled to use any material they want for training a model, but on the other hand also feel entitled to place restrictions on how that model or its output can be used, in some cases even proclaiming that you cannot use the output of their model to train your own model. Copyright for me but not for thee.
> What you cannot do. You may not use our Services for any illegal, harmful, or abusive activity. For example, you may not:
> Use Output to develop models that compete with OpenAI.
Training ChatGPT on the entire corpus of human creation is "fair use", but training a model on ChatGPTs output is "illegal, harmful, or abusive activity".
Especially amusing because, although you can argue about whether training a model is an infringment, most of the training data actually have copyrights.
ML models, on the other hand, are not works of authorship and have no copyright protection at all, period. Or at least that's the natural interpretation of copyright law as it's been applied everywhere up to this point. I suspect that the large commercial interests involved will manage to buy either favorable (but bogus) court decisions or favorable (but stupid) legislation.
OSI's definition of open source is one definition of it, and not necessarily one everyone agrees with. Folks claiming their work is open source are not beholden to this one organization's opinion about what can and cannot be considered open source. That's not to say I agree with the choice of using it in this instance, but I respect the fact that the term isn't precise enough to say it's wrong.
The OSI definition is fairly precise and the most commonly used definition. Anything else will add confusion. We should promote the OSI definition and discourage imprecise usage.
In the age of Software Bill of Materials and increasing focus on upstream attacks, the OSI definitions via the SPDX list, is getting increasingly rigid and used as terms of art. While I like you am a linguistic descriptivist, I can also recognize attempts to confuse and white-wash.
At the end of the day until there is a legal or at least common-law definition of a term, the term can have a pretty wide definition when a large number of contracts are reviewed. Typically as cases around the definition go through court they become presidence. We've not reached that place in the 'open source' world.
The OSD is literally as old as the phrase itself, and was popularized along with the phrase. I actually don't like some parts of the OSD that much, but it's as close to a universally accepted definition as you'll ever get for anything.
... and even if you don't accept the OSD, what these people are distributing isn't source code in any sense at all. Nor do their restrictions usually resemble what the average person would think of as "open".
Yeah, let's agree the term open source can mean anything, for example closed source.
There is no small nuance to intellectualize about here if 98% of the discussed thing is the contrary of what you claim it is. (Now, one could argue it is 90%, won't help)
>(e) "Model Derivatives" means all (i) modifications to Gemma, (ii) works based on Gemma, or (iii) any other machine learning model which is created by transfer of patterns of the weights, parameters, operations, or Output of Gemma, to that model in order to cause that model to perform similarly to Gemma, including distillation methods that use intermediate data representations or methods based on the generation of synthetic data Outputs by Gemma for training that model. For clarity, Outputs are not deemed Model Derivatives.
What's the difference between "Outputs of Gemma"/"Outputs By Gemma" (both included in "Model Derivatives") and Outputs ("not deemed Model Derivatives").
Is there anything specific about the use restrictions that is problematic, or the fact that the restrictions exist in the first place? It seems to me that the restrictions are sensible given the current climate around ethical use of AI.
Something either meets a definition of the term "open source" or it does not. It's not enough for the restrictions to seem reasonable.
That doesn't mean that only open source things should be allowed to exist, just that things which are not open source should not be called open source.
Who's definition. Mine, yours, your uncle Bobs? There is no legally defined version of the term, and the term is not trademarked/registered so at this point it is a free for all. Feel free to engage in some court cases to lock the term down at your expense.
Who's definition of definition? Who's definition of uncle? Who's definition of term? Who's definition of trademark? Who's definition of "free for all"? Who's definition of expense?
There is no true absolute definition of anything, there is at best consensus. And yet, somehow, we are able to communicate with each-other.
There isn't really much of a catch 22 here, because there's relatively little good faith debate about the definition of open source actually. The OSI definition exists and it's the definition that is most accepted by the people who use the term. If the amount of disagreement necessary to justify this line of question is "any at all," then there's legitimately no meaningful definition of any word.
By all means, feel free to debate the definition of open source, with the knowledge that technically there is no absolute definition. I will not be participating. All this sort of pedantry serves to do is try to derail valid points. If you want a different definition, pick a different term.
I mean, if you want to argue the point, I live in the US where we have a very large stack of case law that defines the definition of trademark, in which if you violate said trademark cases in a court will occur against you. And if you act belligerent about it, the court will dispatch a guy with a gun. So I recommend asking the guy with the gun (that is the right of the state to be sole arbiter of violence).
Now, as it comes to the term open source, there is a very wide range of accepted behavior that you can get away with when using the term before a guy with a gun shows up and asks you to stop regardless of what you or the OSI says.
Yeah, but that's a pretty U.S. centric point of view. People outside the U.S. may not care about our definition of trademark.
> Now, as it comes to the term open source, there is a very wide range of accepted behavior that you can get away with when using the term before a guy with a gun shows up and asks you to stop regardless of what you or the OSI says.
So the definition of words is defined by if people shoot you if you misuse them? How are we even communicating right now if that's the only way words have any concrete definition?
Also, I may be behind on my knowledge of U.S. law, but I don't think they enforce trademark law by firing squad.
You know, I really feel like this argument is neither here nor there. It's not absolutely true: if a government says Pi is 3.2, I do not think the consensus suddenly would change. Treating governments like they're god-like entities that exist separately from people in society is silly, but it's especially silly in a world where we have more than one of them.
Consensus isn't perfect, but it is legitimately the best we have. It is true that misusing the term "open source" won't result in people with guns knocking on your door, (though frankly, I'm not sure what point that proves given misusing MOST words won't do that either, including words whose definitions are ostensibly the purview of government,) but it is a term that does have the benefit of not one, but multiple organizations trying to push a reasonable definition that upholds what they feel underscores the values of open source.
Because of that, "open source" generally conveys a sense of trust to the average person. It has value. This effort is why Google and others covet using the word "open source" in press releases: the average person may not fully grok the implications of open source licensing and ideals, but they sure do get the gist. Because they've heard of Linux, or The GIMP, or Krita, or OpenOffice.
That's why this is always an important issue. Language lawyering the word open source is extremely important. I understand that VC-funded SaaS companies are upset when people use their software as intended by the open source licenses they use, but they don't get that there is no having your cake and eating it too. There is no magic "license that is open source but also somehow protects my business model". Whenever an ostensibly-open-source piece of software gets rugpulled, it dilutes the term "open source". It's a magic trick, wherein suddenly not only are the users who did nothing wrong put into a weird situation, but also all of the open source contributors got tricked into contributing to a proprietary piece of software, when they absolutely would not have if they knew that was going to happen. (That said, I really do hope this pushback eventually kills the CLA scam.)
(Note: interestingly, there was an article I saw going around that was trying to pull the fool's errand of redefining "rugpull" by trying to quantify if it "counted". This is absurd in my eyes. It's a rugpull because someone was standing on the rug you just pulled. They used and contributed to software under one license, and now it's under another. It doesn't matter if it's "fair" or "necessary". Maybe if being open source isn't so important, they can just stop releasing things as open source to begin with? But that's the rub, because "open source" has immense value for getting your foot in the door, but now when people think "open source" you're gradually training them to think "for how long?" and it will damage legitimate projects that really aren't ever going "closed".)
Since police officers won't come to your house with guns if you misuse the term open source, somebody is going to need to defend it from being diluted if they want it to actually mean something. (And while police officers with guns is pretty scary, the guarantee that I will drop an unhinged 5 paragraph rant at anyone who disagrees with my take on the term "open source" is pretty terrifying, too, I imagine.) The people who use, contribute to and value open source as a concept are the ones who have the biggest incentive to be the gatekeepers of the definition, and gatekeep we shall.
That doesn't mean there is absolutely no room for disagreement on what open source means, but there's a wide gap between good-faith debates about open source ideals and values and "who let you decide what open source means and not my Uncle?".
Some contend that "open source" is confusing to laypeople. I agree, but there is no 100% solution. Terms like "free and open source" and "free software" and "libre" all have their pros and cons. The trouble is that you can't literally consolidate the entire open source definition into a two-word phrase. Also though, it's not fair for the burden of understanding technical jargon like "open source" to fall on laypeople. They should just be able to count on open source as a positive signal of trustworthiness, and the more technical people among us can do the work of trying to defend laypeople from bullshit. This story has fallen apart a little over time (laypeople are more inundated with bullshit than ever before) but still, it is the ideal.
These are the guidelines for using "OSI", "Open Source Initiative", and the OSI logo. In other words, this is the OSI's definition of their version of open source, but the term "open source" has been around for much longer than OSI.
“The first example of free and open-source software is believed to be the A-2 system, developed at the UNIVAC division of Remington Rand in 1953,[6] which was released to customers with its source code.”
Eitherway, this is why open source zealots tend to specifically say F/LOSS (free / libre open source software), to avoid any ambiguity with people who like to claim 'open source' is ambiguous and easily conflated with 'source available'.
...That there are so many of them proves their own point, I guess!
The biggest problem with the Gemma license is that it requires you to agree to an Acceptable Use Policy that can be updated at any time, and any updates have to be obeyed too.
This means you could build something on the model today which becomes disallowed tomorrow.
This particular usage restriction seems incredibly broad
> Making automated decisions in domains that affect material or individual rights or well-being (e.g., finance, legal, employment, healthcare, housing, insurance, and social welfare);
That's not too bad. Keyword: decisions, not advice/topics/recommendations/etc. So don't execute transactions, or hiring decisions, tenant application rejection, etc. I prefer no restrictions, but the reality is less melodramatic than hellbent HN contrarians would make you believe. I think it'll be okay.
This is rightfully the top comment on this page (at least as of this writing).
These people need to be called out relentlessly until they stop misleading the public.
So much for the Altmanian infinite progress of humanity. They can't set aside their ego, their money and their power, so let's put them back in the Evil Corporate Billionaire category that such people belong to.
Gemini 1.5 is just a few points behind gpt-4 on chatbot arena but has way larger context size and is free to use and you can disable the censorship if you want, to me that is pretty awesome. For my uses it is much better than any other model available today, and it is free on top.
I get really nervous about using LLMs for OCR due to the risk of both prompt injection (instructions in the OCR'd text causing the model to behave differently) and also the risk from safety filters - I don't want an OCR tool that refuses to output text from a document if that text contains offensive language, for example.
There are advantages to smaller models, namely you can process a lot more data, with a lot less vram. I think the intent here from the Google team is for a task-specific VLM that you fine-tune on your data, rather than a general purpose assistant.
From my own experimentation I have found it to really pack a punch for its weight. Another small model which has been very good has been https://github.com/vikhyat/moondream .
finetuning is easily within reach for llava-mistral or something like that, just rent an a100 or two for ~$20 bucks and you'll have your finetuned model
LLaVA is even less open than PaliGemma, it is trained on CC-BY-NC4.0 data so it can't be used commercially. I emailed the team about it. At least with Pali-Gemma the base pt models are available to be used commercially if you fine-tune them yourself
Where did you get this info? because I would love to use it, but I went through their info and it says they use a lot of the same data as 1.5 and the acknowledgement section of their site says: "The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes"
Would love it if I could use LLaVA, but don't want to spend the money on like 18 A100s for 24 hrs that they use for training it. A lot of the models using CC BY NC 4.0 datasets, like VILA, thats not available for commercial use unless you train the model yourself. This is the first time at least a research or company has been open with this info, they specifically say: only the pt models can be used with fine-tuning for commercial use.
The author has added the weights on huggingface under Apache-2.0 license [0]. All previous versions to 1.6 were not listed under Apache. This repo has no code, it is the weights repository.
There's not really a super easy to use software solution yet, but a few different ones have cropped up. Right now you'll have to read papers to get the training recipes.
I don't understand the dog segmentation example, where the prompt was "segment dog".
The article shows a screenshot with a red overlay on the dog - how was that data returned by the model, did it return a co-ordinate polygon of some sort?
Our ML team has noted that the segmentation masks in particular from PaLiGemma are a bit tedious and unintuitive to decode. We should be pushing out (more!) open source software that uses this model in the coming days.
Look forward to an easy way to fine-tune PaLiGemma and broader support for its task types in `inference`, the package used in the blog post.
Does anyone have any idea how to interpret the 'segment' part?
I ran example 'segment cat' from the example provided in the PaliGemma demo
and it responded this <loc0055><loc0115><loc1023><loc1023><seg063><seg108><seg045><seg028><seg056><seg052><seg114><seg005><seg042><seg023><seg084><seg064><seg086><seg077><seg090><seg054>
no documentation explanation on how to interpret segment token,
Anyone else challenged with keeping up with all the releases over last week? All I need is a simple guide that tells me for task X model Y is best given benchmark Z. Where can I find that?
then you will need to pay a lot more for actual experts to tell you why benchmark Z is bullshit and model Y2 is actually better for the task you're actually trying to do and btw would you like to develop your own because that's a moat.
I haven’t tried this yet, excited to see how it can do segmentation by outputting series of coordinates! That's something I just assumed transformers will generally be bad at.
Image models are much smaller than language models, so they put some extra language features on an image model here and then it doesn't need to be that large.
The iPhone does have a GPU, and it can be used to accelerate AI workloads.
This isn't theoretical. You can see this for yourself by installing https://apps.apple.com/us/app/mlc-chat/id6448482937 and turning off your wifi and running the quite capable Mistral 7B Instruct LLM on your phone.
I've even used it to answer simple questions while I was offline and only had my phone with me.
I didn't say an iPhone was as good as a desktop with a dedicated graphics card. I said that an iPhone has a GPU and is capable of running a small but capable LLM.
Most people don't know that's possible yet.
Why do keep indicating that iPhones don't have a GPU?
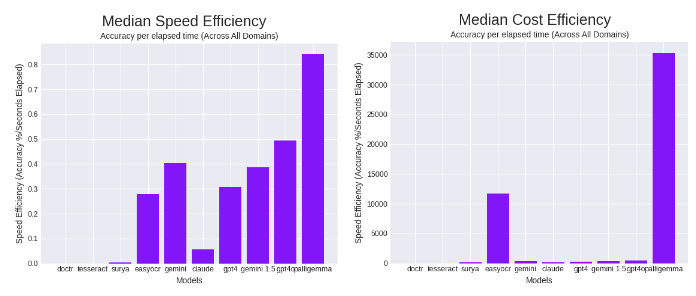
From TFA, PaliGemma is competitive to GPT-4o and even beats it in terms of speed and OCR accuracy. It also can do object detection (bounding boxes) and segmentation which GPT-4V/o and Claude 3 Opus can't do at all.
Not to mention it's built to be fine tuned and commercially permissive!
Isn't "two models slapped together" basically how all of these things work, starting with CLIP? Not sure about GPT4o, obviously, I don't think they released any underlying architecture details?
{kind=link}
https://ai.google.dev/gemma/terms
I was hopeful it was a change of license to be FOSS.