> This is why driverless cars are still just demos
Not directly the point of the article, but is it fair to say driverless cars are still just demos when they're operating on every street, road, and freeway from San Francisco to San Jose, with tens of millions of passenger miles?
I feel like once there are paying customers sitting in the vehicles, it's not a demo, it's a reality.
Eh, Outside Lands is a giant clusterfuck for human drivers every year. If human drivers and wasted riders can't manage it, that a (inebriated, if not wasted) rider didn't close a door all the way is hardly am indightment of the whole thing.
If your opinion is that it's a beta, that's your perogative. For riders in San Francisco and LA, that prefer to use Waymo, self-driving taxis are here, now. The only problem now is scaling up the fleet as the real problem with Waymo is that cars are not always available, or they're backed up and I have to fall back to calling a Lyft.
I agree that "still just demos" is an overstate. But I'd say that in 2015 a lot of people predict that in 2020 we'd have driverless Ubers everywhere. And that just didn't happen.
The challenges that are still open in getting driverless vehicles to operate in more chaotic scenarios like India or Latin America seem pretty much in line with what he's talking about: new improvements need exponentially more data.
The national school bus accident rate is 0.01 per 100 million miles traveled, vs 0.06 for commercial aviation and 0.96 for other passenger vehicles.
Approximately 9.1 driverless car crashes occur per million miles driven, while it may not always be the driverless car's fault, avoiding accidents is not a one way responsibility.
When you consider those driverless cars are only operating in good weather, while school bus drivers operate in most weather conditions while simultaneously dealing with 50+ kids...there is still a very long tail.
You are conflating entirely different statistics. For every stat other than driverless vehicles, you used the fatality rate. For autonomous vehicles, you used the accident rate, and you included all manufacturers and a stat from 3 years ago.
The statistics that have been released from Waymo are significantly different:
9.1 crashes in driverless vehicles per million vehicle miles driven
4.2 crashes in conventional vehicles per million miles driven
But to quote you link:
> The second is differences in driving conditions and/or vehicle characteristics. Public human crash data includes all road types, like freeways, where the Waymo Driver currently only operates with an autonomous specialist behind the wheel, as well as various vehicle types from commercial heavy vehicles to passenger and motorcycles.
The post I was responding to claimed freeway driving, which always has a safety driver right now.
As speeds increase, outcomes become less optimal. And the cars can't simply stop in the middle of the road and wait for a remote driver without putting the occupants at serious risk.
There is a lot more work for Waymo to do before they can drive in more conditions and locations.
Snow and heavy rain for example.
With almost half a million school buses providing transportation service daily they eclipse the number of trips in one month compared to the 7m+ Waymo is claiming.
The school bus isn't a fair comparison but commercial vehicles would be or a limo service commercial vehicles such as taxis would be even the non-commercial passenger vehicles would be a good comparison. The reason why these School bus does not offer a realistic way to compare is because these are highly visible vehicles with lights and a built-in legally binding traffic control device on them. This causes the vehicle to be very visible to all other drivers around them and where that the stop sign can be deployed at any time and that is a traffic control device when it is deployed.
amazons shop and go had thousands of paying customers and yet was still abandoned because the majority of the AI check out decisions had to be offloaded to a human to verify.
I watched a talk by the OpenAI Sora team [1] yesterday. They achieved amazing results with what they called "the GPT-1 of video", making a huge leap from the ugly messy low quality GIFs we were getting before Sora. It understands basic motion and object permanence. It can simulate a Minecraft world. These impressive abilities just "emerged". How did they do it?
Scaling. That's it. They emphasized multiple times throughout the talk that this is what they achieved with the simplest, most naive approach.
Marcus has a good point when he says that the scaling will only benefit in a logarithmic way, not in a linear way. I watched the Sora video as well and in the Q&A session, they admit that they will need a lot of data. Marcus' contention is that there isn't enough data on the internet and synthetic data will just result in errors.
Where Marcus gets it wrong is that he defines "right" as producing an algorithm that an AI will follow to get a deterministic result. So, every time Sora 2 (Gary's Version) produces a video of a glass shattering, it is the same shatter pattern being produced; and it must be a precise duplicate of a glass shattering in nature. That's Marcus' win situation, which Sora will unlikely ever reach.
Maybe transformer-based AI will never be capable of perfectly simulating reality in order to unlock its secrets. It seems to me that, according to the transformer-denialists, in order to create an AI that understands reality, we must fully understand reality first and then program the AI with that understanding.
In my mind, I imagine neural networks as drift-car drivers (I think of them as Ken_Block, Paul Walker would also be acceptable). Sure, your average drift-car driver has no idea how to solve a three-body equation algorithmically, but a great drift car driver can maneuver four spinning tires in a state of critical oversteer around a race track curve without the use of a calculator and get it right most every time.
And yes, race-car drivers have short lifespans, it's true. That's what terrifies Marcus so much about neural networks as well, and why he is so adamant that we listen to him when he says that there are dangerous curves ahead.
I personally would rather live in a world where there are Ken Blocks and Paul Walkers, and that's how I live my life (not in auto-racing, though) but I understand why that frightens people.
Wasn't the exponential increase in data and compute always part of the scaling hypothesis? That's my memory of it from reading [1] years ago. Most of the field thought scaling would hurt, openai thought you'd get logarithmic benefit from it, and openai won that bet.
Definitely true. The only way this is not true is if by some miracle we get an emergent property at a ridiculously large scale, and even then it could be something that could be simplified, which means that scale is at best a way of stumbling upon general intelligence. However, biological brains are incredibly efficient, with very small animal brains demonstrating robust mechanisms of awareness and learning. There are severe cases of brain conditions where the majority of the brain is missing, yet these people can still show awareness and basic emotions.
We know gut bacteria affects the brain and how emotions are also linked to the state of our bodies, I think there is a knowledge gap in our understanding of intelligence that involves the necessity for embodiment.
Our bodies are potentially doing a big part of the "computations" that make up our ability to have general intelligence. This would also explain a lot of how lower level animals like insects are able to display complex behavior with much simpler brains. AGI might be such a hard problem because it's not just about recreating the "computations" of the brain, but rather the "computations" of an entire organism, where the brain is only doing the coordination and self-awareness.
Gary’s articles are often a fun read, but he needs to proofread better. Almost every one (and they’re not exactly long) seems to have some sort of glaring typographical error.
Extraordinary claims require extraordinary evidence. Otherwise, it is a clickbait (if done intentionally) or delusion (if not).
Well, I was shocked to see LLMs (rather than something intrinsically related to Reinforcement Learning) reach the level of GPT-3.5, not even to mention GPT-4.
For starters, he should define what AGI means. By some criteria, it does not exist (no free lunch theorem and stuff). Some others say that GPT-4 already fulfils that. So, the question to the author is: can he say which AGI he means, and would he actually bet money on this claim?
I was shocked to see what ‘pure’ Transformer-based language models can do too, until I realised the sheer scale of training data. I don’t think we have a good enough intuitive sense of just how much is in there. The purported examples of generalisation seem to have turned out to be mostly just a result of having trained something approximating everything ever written. As a human it’s almost impossible to imagine how knowledge that is. I reckon even a Markov chain model of similar magnitude could wow us in various ways.
I think if you go check the n-gram (Markov chain) models which were trained by IBM and Google and others (eg. 'unreasonable effectiveness of data'), you'll find them remarkably chonky sample-wise. (This was possible because processing data for fitting n-grams was cheaper than training any neural net on them, so even in the '80s or '90s you could fit n-grams to billions of tokens.) But their scaling was much, much worse.
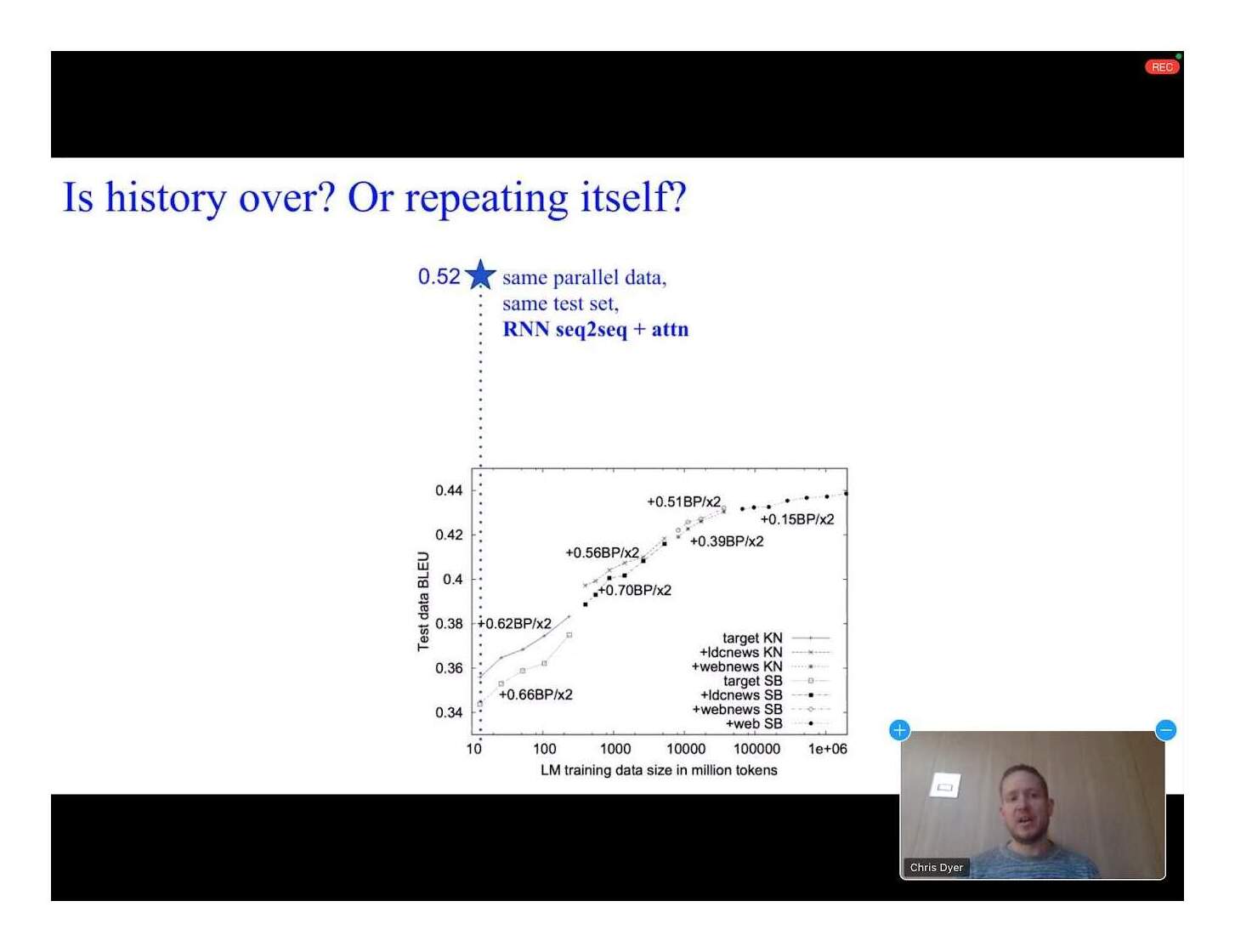
An example: https://gwern.net/doc/ai/scaling/2020-chrisdyer-aacl2020-mac... Imagine how far to the right you would have to draw out that n-gram curve before it reached the seq2seq RNN trained on a fixed dataset size - and where that RNN is considered garbage by current standards. (Note the x-axis is in "millions of tokens".)
It’s completely subjective, so it’s hard to have such a bet without further specification.
But I definitely feel like a sufficiently large Markov model could output sentences in response to input that would amaze/freak out at least some users. It would just be parroting its training data pretty much verbatim (at the level of short n-grams, at least), but due to the sheer amount of the data the exact source would be obscure and hence more easily attributed to the model ‘thinking’ for itself and being creative.
That’s all I was in fact saying — not that it would wow all of us all of the time.
Blake Lemoine was fired from Google for (/in relation to his) expressing that a language model was sentient. We all have different thresholds for thinking ‘oh my god this thing has to be conscious!’.
0) If there is any distinction between the training phase and the query phase then it cannot, ever, be an AGI.
1) LLMs at their core are an auto-complete solution. An extremely good solution! But nothing more, even with all the accoutrements of prompt engineering/injection and whatever other "support systems" (_crutches_) you can think of.
I'll end with my own paraphrasing of a great reply I got in this very forum some time ago: Bugs Bunny isn't funny. Bugs Bunny doesn't, nor ever existed. The people _writing him_ had a sense of humor. Now replace Bugs Bunny with whatever (very, extremely) flawed image of """an AI persona""" you have.
{kind=link}
Not directly the point of the article, but is it fair to say driverless cars are still just demos when they're operating on every street, road, and freeway from San Francisco to San Jose, with tens of millions of passenger miles?
I feel like once there are paying customers sitting in the vehicles, it's not a demo, it's a reality.