Making coloring pages out of your own personal photos is a fun and creative way to engage kids (and adults!) with art. Instead of generic coloring pages, you can turn special memories into custom works of art just waiting to be filled in with color.
My immediate issue, as the father of a mixed son who has just witnessed him spend hours trying to represent his own appearance accurately for an art task at school:
This turns black and mixed people into white-presenting caricatures of themselves. E.g. compare [1] and [2] where the hairstyles of the black people are turned into distinctly "white" hairstyles. My son's hair is closer in texture to that of the man on the right, and there's no way of getting it into the shape of the coloring-in page.
I get there's no ill intent here, but even for far less ethnically ambiguous inputs this "whitewashes" hairstyles and general appearance, and once I saw it I couldn't unsee it.
If my son was the age to want to use this, I'd be concerned about letting him use this, because I know he is sensitive about how he is different to his friends, etc. and this would wildly misrepresent and erase his actual appearance.
This was absolutely my first reaction as well. I scrolled through the first few photos of White families where it seemed to turn even them into 1950s caricatures of "small town White Americans" and thought "hmmm, how's it going to treat Black people?"
I was not at all surprised when it turned Black people into White people.
This to me is one of the clearest examples I've seen of what people talk about when they talk about biases in training data. Clearly the training data of "coloring books" is heavily biased towards "stereotypical 1950s white people" and turns everyone into them.
(And you can add [1] and [2] to your list of comparison images.)
The artistic license thing in itself I think is fine if only it didn't go just one direction. And you may very well be right that the examples it may have seen of coloring books may well be a very peculiar subset.
“Artistic license” assumes agency, that there is some artist who understands the facts of a situation and deliberately changes them in the work.
It does not apply to a machine doing a poor job because it lacks context in its training data. Just like medieval art, which was inaccurate¹ due to ignorance, not because the person doing the drawing decided to add some flare.
Another – presumably coincidental – issue with images [1] and [2] is that there is a person missing. I assume that’s not related to skin colour, but to me it adds to the slightly irritating effect of how the resulting images may be disconnected from human reality in ways that would commonly be understood as disrespectful. (Not to speak of the “usual” AI problems, such as additional fingers, stray body parts, etc.)
Thanks for pointing this out, seriously. As a white european guy, I'd probably never have thought of this issue, that's an important reminder about our biases
We use a model but not a diffusion model + controlnet which is what I'm assuming this website does.
Would love any feedback on the results + site [2] – before it's asked: we do not use any user uploaded images for model training, they're only stored to show you the color version of your originally uploaded image
It still has the vibe of janky edge-detection that can be done without AI. Admittedly, less janky than pure edge detection but still not quite smooth enough that I'd pay for the results.
Also, just FYI, asking three different time across these comments for people to check out your site feels a bit spammy to me. I'd suggest you do your own 'Show HN' if you are trying to engage with the community here for feedback.
Fair, thanks for your feedback – some images work better than others in terms of the artifacting. There's lots of improvements we'd like to make, for now the best balance I've found is letting the user choose their level of detail on the site and add any masking lines as needed before PDF export
Honestly, when I first started reading your comment I thought you were being over sensitive but I totally get it looking at pictures 3 and 4. Even 5 and 6 completely changes the hairstyle.
I had to look for multiple examples myself before I was sure I wasn't being oversensitive. As I said, I'm sure there's no ill intent, and in a way I'm not surprised either, because as my son himself found out, if you're going to draw line art - especially with clear, thick lines like this, then accurately representing black or mixed hair without it turning into a caricature that'd be even worse is a skill.
And one that is very likely underrepresented in the training set for no fault of theirs.
And this is why getting diversity "right" (so not the Gemini fiasco way) is hard - you can be extremely well meaning and just not have it register until someone for whom it's personal looks at it.
Looks like it takes considerable "artistic license" to deviate from the photos. Every person getting turned into a stereotypical "caucasian" type is the most noticeable (and most problematic), but also the spotted cat in one of the pictures gets a "stereotypical" tabby coat. Also, it likes to insert a horizon, even if the original image doesn't have one, and sometimes it completely changes what's in the background. But I assume this is because of the images in the training set - I guess in coloring books most people have light-colored hair (which can then be colored brown, black, red... whatever) and the model then associates that with stereotypical blondes?
There are several modes (https://portraitart.app/portrait-art) - some of them are better at keeping people looking like they originally look, the "coloring page" mode seems to be the most "heavy-handed"...
After some further browsing, the "caricature" mode seems to be the strangest - caricatures are supposed to take the characteristic traits of a person and exaggerate them in a humorous way, while these images sometimes lack even the slightest resemblance to the original. For example, this mixed race couple https://portraitart.app/static/gallery/couple1_original_1024... is not only turned into two brunettes https://portraitart.app/static/gallery/couple1_caricature_10..., but they also have a different pose, different hairstyle and wear completely different clothes...
Thanks for calling this out. I think the dev cycle for production AI Systems will involve a lot of bug squashing on this kind of thing. These models handle a huge variety of inputs; by definition much more than you could hand code. It’s hard to even identify systematic failures.
Once a failure mode is known - like here - how do you fix it? The foundational problem is minorities are a minority of the training set. Good training data is expensive, so how can we practically boost representation without getting the Gemini fiasco?
One idea: start with the best coloring books. Presumably some human has mastered the art of “accurately representing black or mixed hair without it turning into a caricature”. Find them, and start buying their art. When they have drawings based on photos, use that training pair. When they have line art only, use a style transfer tool (like this one!) to convert to a photo. That gives you another pair for use in the other direction.
Another idea: make it easy to users to flag poor transfers. Add a “whitewashed” option to the standard mod report flow. Feed that into RLHF. Get better.
Another idea: focus dev cycles on this. Once you have a system to flag problems and address them, use all this fancy AI to identify input photos with black/mixed hair. Manually inspect how the model performs and push feedback into the next training cycle.
> Presumably some human has mastered the art of “accurately representing black or mixed hair without it turning into a caricature”
There absolutely are good examples, yes, and I think you're right that the failure of capturing it is largely down to volume in the extant datasets, and particularly in datasets that provide a direct match for the type of line-art colouring in style, which is in itself fairly dated.
I agree with all of your recommendations. I think it's definitely a problem that will be solved. The main thing is for people to get used to looking for it.
It's galling for me once pointed out because I know that a lot of black people have totally different hair to the degree that it's a separate skill to cut that hair versus white people hair. I knew someone who would only have her sister cut her hair because none of the stylists in town could cut it without ruining the shape. They'd use the same tools and techniques as with perfectly straight hair and would destroy it. The hair is something that seems intensely personal and to have it erased and morphed so completely is really broken.
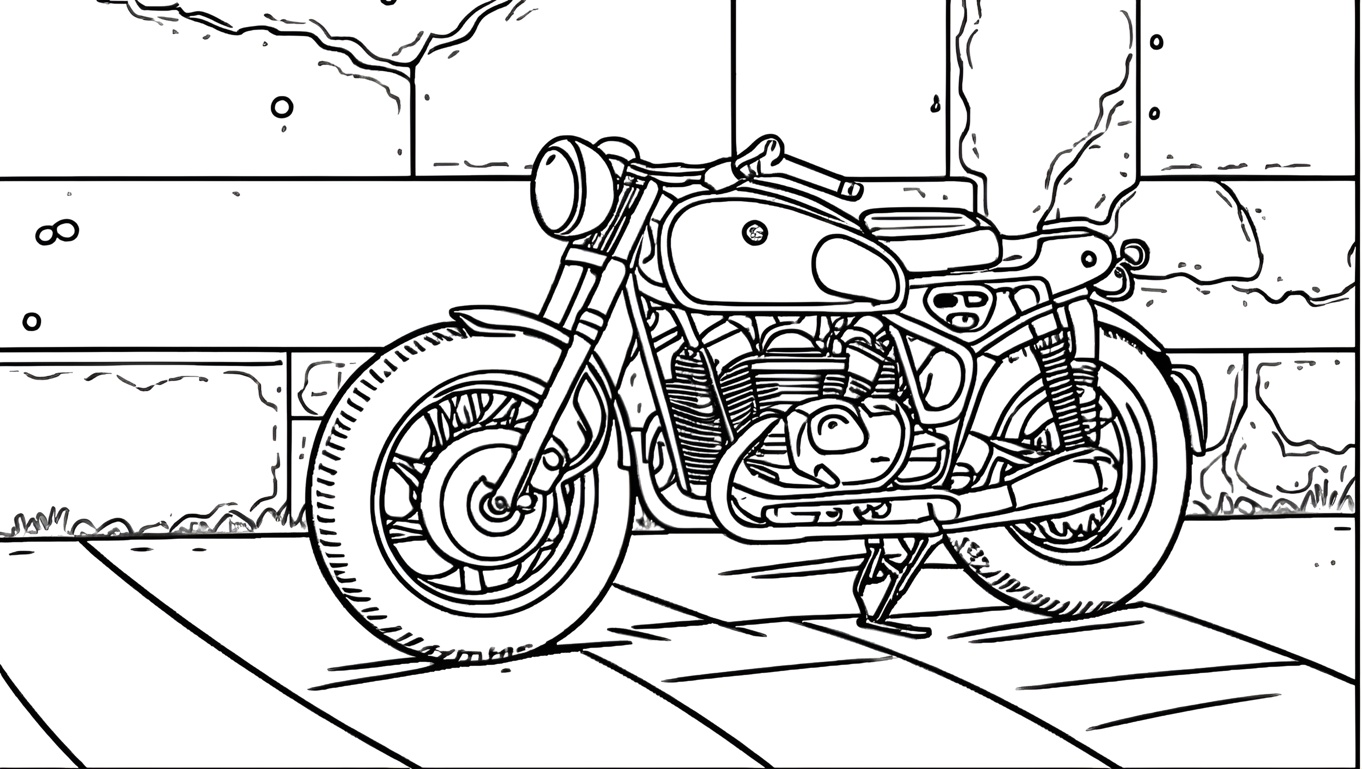
Feels more likely this is the opposite - the "originals" look like hallucinations.. what is the rear suspension attached to on this "bmw"[0]? Presumably it's supposed to be an R60[1]. It magically has a lot more (accurate) parts in the colouring page[2] (bigger front and back fender, seat, engine gets fins, frame changed shape, tail has license plate holder and signals, the front brake is connected to the leaver via a cable). At least these six fingered people[3] deserve each other - shame she moved her wedding ring, Inigo Montoya seeks them.
I really think this should have GenAI in the title on the webpage or on here, because it's taking the source photo and making best guesses while creating details out of whole cloth. This isn't just "another photo filter", it's instead taking the picture and running with it with sometimes pretty poor results.
For example, I used a random selfie of me on the beach and big rocks in the water, wearing dark sunglasses and mouth closed.
Watercolor: Added eyes to my glasses (!). The rocks and water turned green, and it looked like I was standing in a park.
Coloring Page: Ferns and trees added that weren't there before.
Both: Gave me a teethy smile when my lips were closed.
The examples on the home page must have been extremely handpicked because I'm not seeing anything to that same fidelity.
When I saw this posted late last night, I was pretty excited since I have kids, but then realized it's just determining the basic idea of what it sees in the photo, and then drawing a new image from scratch that has those elements. What I wanted is something that takes the original photo and removes things from the image until we're left with some basic line drawings, so that the people in the coloring book actually look like the people in the photo! Their examples very obviously show how different the resulting image is from the original. If Google allowed you to search by saying "Find me a coloring book image where a dad is sitting behind 2 kids with his arms around them, and the daughter is on the left and the son is on the right" then we'd end up with results almost as good.
I'm no Photoshop expert, but someone else in this discussion pointed out that Photoshop has some filters or other tools that do edge detection and can yield much more accurate results. If the techniques could be replicated in a SaaS then you'd have a much better product. Of course, if it could be done in a desktop Mac app or an iOS app, I might choose that for privacy reasons.
> If Google allowed you to search by saying "Find me a coloring book image where a dad is sitting behind 2 kids with his arms around them, and the daughter is on the left and the son is on the right" then we'd end up with results almost as good.
I've been using Stable Diffusion, and more recently Bing (app) and now GPT-4/Dall-E 3 (ChatGPT app) for that very purpose, with quite good success rate. It's perfect for when my daughter randomly asks me for a coloring page with a dancing vacuum cleaner or such. Dall-E is quite good at this, all you need to do is tack "in the style of a children coloring book" or such to the end of your prompt.
Heh, I used a photo of myself sitting on the couch with my chihuahua looking up at me over my laptop screen and it replaced her with a St Bernard. The hallucination is strong in this one.
According to whom? There’s just that sentence, surrounded by laurel leaves, above five stars. Zero indication of where that award/rating came from. Did you make it up?
When I was just starting out I made a similar app (https://github.com/rmdocherty/buck3t) using classic computer vision operations like k-means and Canny edge detection rather than (I assume) ML. It also lets you fill in the returned coloring page in the browser.
It’s simple and works relatively well but is prone to fail on high frequency objects like foliage, where the ML approach appears to a) succeed and b) stylise (seems to cause problems).
The free trial on the cloud function expired so the web app doesn’t work and the source JS code is awful but someone (maybe me) could pretty easily rewrite the cloud function into a flask server to allow local hosting.
Same here - I had a web-based system that let you do coloring pages, paint-by-number, cross-stitch patterns, etc... and it all worked in the web session. While adding an AI element does give improvements over my results. I'm not sure those improvements are worth being prompted for my email, waiting even longer for results, the results not being 100% true to the original content, and not having those results just show on-screen.
Use a personal domain with a default address that filters to a mailbox then use a different email address for every site you use. This plus random passwords from a password manager contains the privacy leakage, blast radius of credential loss, and keeps your mail spam free.
Ship sailed? Your solo rage boycott won’t change the incentive structure of the universe. Thus adblockers, black hole email addresses, etc. Using the service without providing back the value also creates incentive to avoid the dark pattern in a way that’s a stronger reinforcement than simply not using.
Or just keep a cookie to know which job to show if the user comes back. You don’t even need a cookie banner for something that simple with no personal information.
IMO your FAQ needs an entry for: when you store uploaded photos, what will they be used for. Will my uploaded photos be used as training data for your AI models for example?
Right now, we keep it for user to access it later. User can choose to delete the photo and all associated pictures, as explained in https://portraitart.app/help
We do not use the data for other purpose.
This is a good suggestion. We will definitely think about how to design the UI to satisfy both.
The coloring page that should have shown my son and daughter sitting on a bench that looked like a bear waving magic wands… turned my son into a girl with Princess Leia hair, and my daughter into a anthropomorphized bear, no wands.
Fun, but it’s no longer a special memory. There’s so little tying the source and result.
For significantly less compute you could make pretty good coloring book pages just using different edge detection methods or simply using the stamp filter in Photoshop.
I wouldn't call simple edge detection "pretty good" colouring book generation. You're just gonna get all the edges of complex shapes; it needs to be cartoonified/simplified with having large contiguous patches of colour in mind.
I actually used this exact method in the early 2000s to make "coloring books" for local businesses using their own photographs. They would give them out and use them for marketing.
Or, you can just ask openAI directly. That way only they have your holiday pictures, instead of adding a third party of unknown trustworthiness to the mix.
Does anyone know of a site that works without the gimmicky AI? Like it always seems to switch the sides of people, changing major details, etc. I just want a coloring page of the actual image I upload, not some AI's interpretation of it with creative licensing.
You could try out our site [1] – we use an AI model but not a diffusion model (like OP is) to convert photos to line art, the resulting lines are less "smooth" but it better represents the original image
> 1. What's the style name for dilbert-like comic strips? Comic? Line art?
I don't think there's a clear settled name for that specific style, but I'd describe it as an American newspaper strip with low levels of detail and inspiration from "ligne claire" (Ligne claire is the style of Tintin etc. - focuses on strong, clear lines with a lot of details omitted, rarely shading very rarely hatching; e.g. hair in Ligne Claire is usually described by its borders - even messy hair is mostly hinted at by tufts sticking out, with the rest flat shaded).
American newspaper strips by no means always use simple line work, so describing it as that in isolation is unlikely to work, but it has other characteristics (which are by no means universal - this is a regular complication in categorizing this), such as often omitting backgrounds, or just hinting at backgrounds (e.g. with a picture hanging on a wall being all you see of the wall), and often using panels that change little or sometimes not at all during a conversational exchange (basically strips have a lot of characteristics around streamlining works for artists on a deadline that's often a major stress factor, so lots of simplification, but what requires simplification to same the artist time will vary greatly).
But there is variation there too, and especially very significant variation between the classic single-strip-a-day format and the Sunday format with a bigger panel, where you often end up seeing non-traditional layout or characters "bursting out" of individual frames in various ways where the single strips are often far more regimented. Many comics do both, and will sometimes look very different between the two.
E.g. Calvin and Hobbes strips are fairly regimented, usually four panels of near uniform size, while the Sunday panels were renowned for breaking "rules" with uneven, sometimes overlapping panels, and drawings bursting out of them - the last ever Calvin and Hobbes consists of 3 or 5 or 7 frames depending on how you count - the first frame contains another frame, which contains a drawing, which contains another frame with a drawing. The two top outer frames don't even align with the bottom outer frame... [1]
You almost certainly would need to try multiple things and add additional descriptors to get the specific feel you want.
2. How do I produce consistent characters throughout the "comic box" and episodes?: controlnet "reference"
3. How do I hint the generation of the comic? E.g. I draw a stick figure of someone sitting, and it generates my character with that pose: controlnet "open pose/sketching"
4. How do I "refine" some parts of the generated image. For example I like the generated character, but I want the face to look different direction: inpainting
It's still basically impossible to get perfectly consistent character features across multiple images/without a massive amount of effort. These models have been trained to generate single/standalone images.
Maybe some of the Sora related tech (where it generates frames in parallel/each frame has the context of every other frame) for coherency can be used to improve the plain image generation stuff as well, ie being able to specify a character with multiple views (3/4, back, front etc) so that you can refer to that character in your prompt.
The tool is not perfect. Sometimes it does not fully understand the image content. Also, right now, the image is slightly watermarked, but perfectly fine for using as coloring page.
And it seems personalized coloring page is very popular, we actually just decided to make the coloring pages free of watermarks, as our minor contribution to education. Will change the code to make that happen soon (in a few days).
Sure - I don't mean to sound like I'm complaining - I think the tool could be very neat. Would be great to be able to use it easily without any email, at least for the initial trial.
I think this is just a thin wrapper around GPT-4 or similar? Parents I know have replaced colouring books by just asking GPT-4 , and the colouring pages it generates look exactly like the example outputs here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This turns black and mixed people into white-presenting caricatures of themselves. E.g. compare [1] and [2] where the hairstyles of the black people are turned into distinctly "white" hairstyles. My son's hair is closer in texture to that of the man on the right, and there's no way of getting it into the shape of the coloring-in page.
I get there's no ill intent here, but even for far less ethnically ambiguous inputs this "whitewashes" hairstyles and general appearance, and once I saw it I couldn't unsee it.
If my son was the age to want to use this, I'd be concerned about letting him use this, because I know he is sensitive about how he is different to his friends, etc. and this would wildly misrepresent and erase his actual appearance.
[3] and [4] is another stark example.
[5] and [6]....
[1] https://portraitart.app/static/gallery/group1_original_1024....
[2] https://portraitart.app/static/gallery/group1_coloring_page_...
[3] https://portraitart.app/static/gallery/portrait4_original_10...
[4] https://portraitart.app/static/gallery/portrait4_coloring_pa...
[5] https://portraitart.app/static/gallery/basketball2_original_...
[6] https://portraitart.app/static/gallery/basketball2_coloring_...