> Furthermore, these R8g instances provide up to three times more vCPUs and memory than Graviton 3-based R7g instances.
So, uh, 75% more bandwidth but 200% more cores is a net reduction in available bandwidth per core. If you rented 32 cores of a server before, you got a certain amount of bandwidth. If you now rent the same 32 cores, you'll have about half the realized bandwidth?
Narrators voice: It was always the ultimate spec, it is now becoming more obvious to more people.
One of the interesting things for me is how memory "operations" (which is to say transactions of the memory controller) can completely obliterate "bandwidth."
In the past (not sure how true this is on current microarchitectures) the controller between cache and DRAM worked by opening a "page" of dynamic memory. That was an artifact of how DRAMs use both a column address select and a row address select and then multiplex the address bits. So to "read" memory you needed to select the column, then select the row, and then read the memory. The good news was that if you needed the next word of memory in order, you could just read again. And again. Periodically if you were reading the chip would have to ask you to wait while it refreshed its contents.
Anyway, this memory operation of opening a new page was a lot slower than reading the next word in memory. So if you're requests were bouncing all around memory your effective bandwidth was limited by how fast your memory controller could open new pages. That could be one tenth the nominal serial access bandwidth. Controllers had multiple "page" registers so they could hold the state of two (or more) different DIMMS and try to interleave their access across DIMMs to hide the latency aspect of page mechanics.
Generally though, when you get to the point where your measuring memops and trying to layout your physical memory to minimize them you're in a different realm of system optimization.
Only in applications that are constrained by memory bandwidth. Many applications are not constrained by the memory bandwidth on modern architectures with significant cache.
If you have an application constrained by memory bandwidth, carefully selecting the server would make sense.
> In related news, Apple reduced memory bandwidth in their M3 chips by 25% compared to M1/M2:
Not exactly. M3 Max has the same 400GB/sec memory bandwidth as the top end M1 and M2 chips. It’s only certain lower tiers that have less memory bandwidth than their equivalent tiers in previous gens.
But it probably doesn’t matter for most applications.
> Only in applications that are constrained by memory bandwidth.
Sure but I think OPs point is that memory bandwidth is the bottleneck in more applications that you think.
Cache only helps if you're accessing the same data over and over.
My gut instinct is the amount of applications that do a lot of processing but only on a small amount of data are in the minority. The opposite seems a lot more common.
> My gut instinct is the amount of applications that do a lot of processing but only on a small amount of data are in the minority. The opposite seems a lot more common.
I doubt that. The easily way to find out is to disable the L3 cache on your CPU. If your theory is right, the performance drop should be minimal on most applications.
Note: Even with the L3 cache disabled there is still the L1 and L2 caches but those are pretty small.
I suspect that L3 impacts performance a lot. I dabbled in running a Windows VM with a GPU passthrough, and I had to spend a lot of time to properly pin virtual cores to physical ones so that CPU caches are utilized properly, as I suspected that it was the reason for decreased performance. I managed to get only L1 and L2 to be utilized properly and it somewhat helped, but L3 was still underutilized due to double-scheduling in both Win VM and Linux hypervisor. Even the basic OS shell suffered from lags, not to mention games.
I would assume that applications that process data faster than a few gigabytes per CPU-second are rare. It's more common that things are constrained by computation or memory latency.
You'd think so, but for datacenter workloads it's absolutely common, especially if you're just scheduling a bunch of containers together. Computation also doesn't happen in a vacuum, unless you're doing some fairly trivial processing you're likely loading quite a bit of memory, perhaps many multiples of what your business logic is actually doing.
It's also not as easy as GB/s/core, since cores aren't entirely uniform, and data access may be across core complexes.
I'm not sure what you mean by datacenter workloads.
The work I do could be called data science and data engineering. Outside some fairly trivial (or highly optimized) sequential processing, the CPU just isn't fast enough to saturate memory bandwidth. For anything more complex, the data you want to load is either in cache (and bandwidth doesn't matter) or it isn't (and you probably care more about latency).
I had these two dual-18-core xeon web servers with seemingly identical hardware and software setup but one was doing 1100 req/s and the other 500-600.
After some digging, I've realized that one had 8x8GB ram modules and the slower one had 2x32GB.
I did some benchmarking then and found that it really depends on the workload. The www app was 50% slower. Memcache 400% slower. Blender 5% slower. File compression 20%. Most single-threaded tasks no difference.
The takeaway was that workloads want some bandwidth per core, and shoving more cores into servers doesn't increase performance once you hit memory bandwidth limits.
It's usually bottlenecked by memory latency, not bandwidth. People talk about bandwidth, because it's a simple number that keeps growing over time. Latency stays at ~100 ns, because DRAM is not getting any faster. Bandwidth can become a real constraint if your single-threaded code is processing more than a couple of gigabytes per second. But it usually takes a lot of micro-optimization to do anything meaningful at such speeds.
exactly, a typical REST server spends a lot of compute time in json encoding and decoding. which could be sped up significantly if there is better memory bandwidth
My first guess would've been that JSON encode/decode wouldn't be memory bandwith-bound because it involves so many operations on single bytes at a time, most of which would be in the cache after the page has been brought in initially. Of course maybe much of that is done with SIMD these days?
Anyway, I have near-zero experience in this area so I'm mostly just posting this hoping for someone to explain why I'm wrong.
I don't see how the link clarifies things. simdjson is fast enough that JSON decoding can approach single-core bandwidth capacity, but it doesn't follow that a JSON-heavy load is bandwitdh constrained. In fact the existence of simdjson points to json decoding being compute bound.
It’s a bit more nuanced than that. Scalar code that does lots of branching and loads one value at a time (e.g. single character) often can’t hit memory at peak bandwidth rate. On the other hand well vectorized code that loads vectors of multiple values at a time can properly saturate the available hardware resources.
The earlier post was referring to "a typical REST server" in a context of the claim that memory bandwidth "is becoming the ultimate spec".
simdjson (impressive as it may be) existing as an interesting project seems likely to imply that most JSON parsing isn't done with such performant methods on "the typical REST server".
EDIT: Seeing that it's used in many projects including Node.js shifts me back to thinking more highly of the claim that memory bandwidth is becoming the ultimate spec!
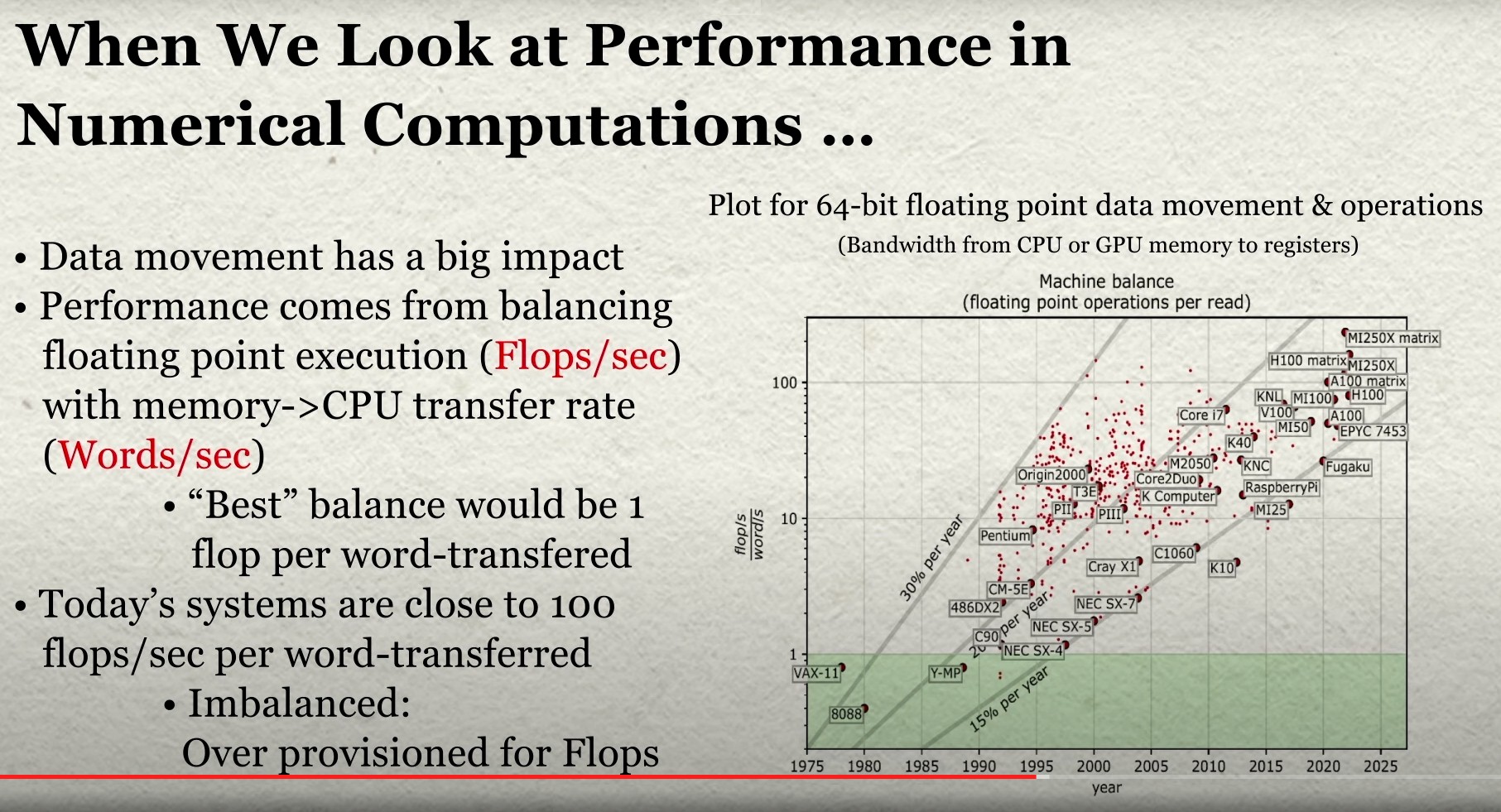
It's a shame more people aren't familiar with arithmetic intensity and the roofline model [1], which give a simple mental model for performance profiles on both CPU and GPU.
I always find this graph [2] covering decades of hardware evolution fascinating.
"Becoming the ultimate spec" is one perspective, another is "the drive toward increasingly bandwidth-starved cores starts to hit limits in some applications". Bandwidth per core has been decreasing due to increasing core counts and slowly improving per socket mem BW, and cores have gotten faster at compute.
Anyone know some example bytes per flop machine balance numbers for current and eg 20 year old systems? For older ones one source is https://www.cs.virginia.edu/stream/peecee/Balance.html - the "machine balance" for 2003 boxes seems to be between 10 and 17 there. Sadly the "MW/s" unit for machine words is not self-explanatory, what is the word size used.
The high memory bandwidth is impressive, but you’d actually have to contrive some set of artificial circumstances to saturate it. In almost all use cases the user won’t tell the difference.
Given that the "reduced" bandwidth is still more than double that of an Intel or AMD HEDT chip, you're still doing much better than you would with x86.
Intel and AMD both tend to choke bandwidth (memory and PCI lanes) on anything below their server chips.
The key here is 3x more vCPU. I wasn't even aware ARM had SMT design, so it is highly likely to be the first dual socket / CPU design for ARM.
That is 192 CPU per instances. I assume AWS will continue to work with AMD and provide 256 vCPU. Would love to see them being compared. ( ARM with Physical CPU core and AMD are SMT thread. )
>> So, uh, 75% more bandwidth but 200% more cores is a net reduction in available bandwidth per core.
My guess is that most cloud customers use fairly little compute and low average bandwidth. But everyone wants "dedicated" cores so this makes a ton of sense and Amazon is raking in billions due to stupidity. Remember the recent story how a couple clicks cut the company cloud bill by a shit-ton. That's probably the norm.
And with the crappy scheduling your typical OS provides and containerization as the virtualization mechanism of choice it makes good sense to assign one or more cores to a container.
~~Probably however Graviton3 instances will not be going away any time soon (Grav2 instances are still around). They'll likely fill a different niche where the Grav4 instances are going to be better for larger workloads that can make use of the whole CPU whole Grav3 instances will be available for people with smaller workloads.~~
Edit: Nevermind. A reply confirms the memory uplift is per core.
I wonder how they’ll compare to Ampere’s chips. I hope Ampere holds on, it is nice to have chip designer that primarily, like, designs and sells chips as a business model.
Very annoyingly, a lot of the Graviton processors are only available on larger sizes (minimum of a .medium, but often much larger), and they’re still not filtering down to the smaller sizes. Hopefully AWS will finally start making them available some time soon.
I work on Trainium (SoC design and firmware), the main thing you would lack is the Nitro management plane. The instance is not responsible for managing the Trainium chip at all. Additionally, the platform is most desirable when it's connected via side links to other Trainium chips (the 32xlarge instance type). Even more out of band management.
Of course this could all be redesigned to be a desktop PCIe card, but the design assumption that it lives in AWS is literally baked into the silicon.
Never mind the power and cooling requirements. You probably wouldn't appreciate it being next to you while you work.
Have you done any show & tells for the hardware? I miss working in Blackfoot and going to those, back when all of AWS was there. Always fun looking at S3 and EBS chassis!
We do "Annapurna ED" video series where we talk about various things Annapurna is doing internally (very interesting to see what Graviton is up to) but I don't think these get shared to the broader company.
No physical requirements are shared to my knowledge. You can glean some info about Trainium (1st gen)'s architecture from the Neuron docs [1], but even then AWS doesn't do nearly as deep dives/whitepapers as Nvidia does for each GPU architecture generation. The architecture is much more specialized for machine learning than a GPU's is (although recent generations like Hopper are adding more and more ML-specific features). If you think about a plain old feed-forward neural network, you do three broad classes of operations: matmul, activation, and reductions. Each Neuron core has a dedicated engine for each of those steps (Tensor Engine, Scalar Engine, and Vector Engine).
This is the tip of the iceberg and all the other zoo of Pytorch primitives also need to be implemented, again on the same hardware, but you get the idea. Never mind the complexity of data movement.
The other Neuron core engine is the piece I work a lot with, the general-purpose SIMD engine. This is a bank of 8x 512-bit-wide SIMD processor cores and there is a general-purpose C++ compiler for it. This engine is proving to be even more flexible than you might imagine.
It’s a Neoverse N1 architecture, whereas the new Gravitron is Neoverse N2.
It is an E-ATX form factor, and I can’t tell whether the price makes it a good value for someone who simply wants a powerful desktop rather than ARM-specific testing and validation.
Just grab a beefy x86 CPU (e.g. one based on AMD zen4) and put it in SMT=1, and you'll probably have a much better experience. A lot of windows/Linux software is already optimized for x86, and you'll get good performance uplift per logical thread from SMT=1.
If you're referring to the SMT=1 part it means not more than 1 hardware threads will be assigned to a hardware core at a time, not that the processes are single thread.
If you're referring to the general performance of single thread apps between the two yes.
What happens the older chips? Do they just keeping delivering services to a lesser AWS tier, or do they get junked? I'm not much into cloud stuff and didn't even realize Amazon made its own silicon these days.
Lifecycle replacement on a server is 5-6 years. At that age they aren't competitive for the power consumed, and failures become more common.
Now, I manage many servers at my job that are much older than that, but only because the operations budget and the capital expenditures budget do not take this into account.
The A1 (graviton1) instance type was introduced in 2018 and it's not available anymore for purchase, but I don't think they've forced anyone to migrate.
Customers will want to migrate anyway because the newest types offer much better performance and pricing. At which point AWS may decide there's no demand for new instances of that type and just remove it from the API.
They get recycled and put back into inventory as spare parts for existing SKUs they currently have deployed. And just fyi, Annapurna Labs (creator of the Graviton family) was acquired by Amazon AWS back 2015 iirc.
I think we are talking about entirely different classes of hardware.
The z16 is designed to run applications that cannot fail. In some cases, the datacenter is expressly built around these systems to accommodate their unique capabilities.
The Graviton line is designed to run as many applications per unit of volume and power possible for a multi-tenant, hyperscale ecosystem.
If a CPU core goes bad on a Graviton chip, you would likely need to redeploy your EC2 instance (or it would be done for you automatically). This would almost certainly have some downtime for your application. In the z16, if an entire CPU goes out, you hypothetically won't drop a single transaction if you followed IBM's guidance.
Just curious if anyone else had the thought, “Amazon is in the chip business?” and then subsequently wondered if the regulatory agencies should step in and force Amazon to start spinning their sub-entities off into independent companies. I mean, I’ve thought that about Walmart for years. Kinda weird…Amazon making chips.
Why in the world would Amazon need to spin out their chip design group? They are building things they use to run their business. There's plenty of potential anti-trust issues with Amazon. Having their own chip designs to use in their data centers is nowhere on that list.
Is that not exactly the problem where amazon takes profits from AWS & uses them to agressivly drive other retailers out of the online shopping business?
I don't think vertical integration should be made illegal, and "Amazon Web Services offer exclusive Amazon-designed chips" doesn't to me seem like an abuse of monopoly power any more than "Apple iPhones use exclusive Apple-designed chips" does. What is the abuse of power that forcibly splitting apart the company would solve?
Vertical integration can take us to dark places, but it can also provide incredible product experiences.
I think with Apple, Amazon, Microsoft and Google, you have a good competitive landscape to work with right now. All of these players already making their own chips. ~4 solid verticals that are somewhat compatible and highly competitive with each other in large, mostly-overlapping regions.
Honestly, things feel pretty OK to me when you factor it all in. If it was just Microsoft or Apple doing the vertical chip thing and they were going absolutely hockey stick over it, then perhaps. But there are several competent players doing this now.
Thanks for the perspective. I guess where I’m coming from is Google was a web search company. They’ve expanded into mobile and that also means their own mobile OS. They also got into browsers. Similar could be said about Apple. To me it’s less about vertical integration and more about expansion. Walmart used to be grocery. Then they added retail. Neat experience at the time as a consumer, but it killed local retail and has gut punched other national retail. Since then they’ve added auto service and pharmacy. At what point does someone come in and say, ok giant corporation, you’ve proven you’re so large you can enter into most if not all markets and decimate your competitors but it’s not a long term net benefit because we’re consolidating everything under too few umbrellas. Maybe I’m wrong to think that and I do recognize the benefits of scale. I’m just not convinced a civilization is thinking long term enough when I keep seeing small businesses go under and medium businesses get acquired (aka: bought up). It seems like this is a meaningful part contributing to the disparity in wealth.
Yeah, there's plenty of competition in the chip market — Apple, Intel, AMD, Samsung, and Qualcomm all are in the CPU business, and Amazon entering it as well seems like increased competition and a win for customers. And AWS is facing heavy competition from Azure now that MS has the exclusive OpenAI deal, so I'm not too worried about consolidation there either.
I am sympathetic to this thinking but also Google and Apple make chips too, it would be perhaps hard to make a claim for why Amazon should be split without splitting Google and Apple too, but I think Apple in particular has such a good case for making their own chips that Amazon could prob use this as a defense of their own efforts. This is perhaps more a symptom of the lower cost of entry for chip fab today than we have had in the past.
I would like to see both Google and Amazon broken up. Apple I'm not sure about, they are huge and have a lot of verticals, but when you get down it they sell personal computing devices above all else and so have a stronger defense for arguing that their custom hardware is the core product. They do have a walled garden, which is a Bad Thing, but OTOH you can use their gear perfectly well without ever creating an Apple ID, and likewise you can use the whole internet perfectly well without ever purchasing an Apple device. In contrast, I have difficulty wrapping my head around the sheer scope of Google's and Amazon's enterprises, they're like entire tribes of 800lb gorillas.
Google has been building their own hardware since they started - first racks & servers then networks/data center then boarfs, semi custom cokponents and then components.
Mandating that SW/Services companies be forbidden from silicon is every bit as absurd as prevention hardware manufacturers from toching software. The playing field for software is incredibly level these days - everyone uses the same IP vendors, design services & contract fabs.
If you want smaller companies, reform it'll be much easier to get rid of tax pyramiding that favours mega corps.
{kind=link}
So, uh, 75% more bandwidth but 200% more cores is a net reduction in available bandwidth per core. If you rented 32 cores of a server before, you got a certain amount of bandwidth. If you now rent the same 32 cores, you'll have about half the realized bandwidth?