Can confirm, I can run PyTorch with ROCm just fine on 6900xt and 7900xt on Debian. The 7900xt does require the nightly build of PyTorch (for ROCm >=5.5 support, I run 5.6) in order to automatically get the gfx1100_42.ukdb miopen kernel. I must specify which gpu and which miopen kernel when starting python. My device 0 is the 7900xt and device 1 is 6900xt, so for each I run the corresponding commands:
GFX 10.3.0 for gfx1031 and GFX 11.0.0 for gfx1100, but be aware that the kernel is tied to the series, so even thought the 6700 is technically gfx1031, it uses the gfx1030 kernel, same thing if you use a newer rx 7000 series.
Seems that specific benchmark is deprecated. For me, I do get around 15 iterations/second on my 7900xt when running "stabilityai/stable-diffusion-2-1-base" for 512x512. I get around 10 iterations/second when running "stabilityai/sd-x2-latent-upscaler" to upscale a 512x512 to 1024x1024.
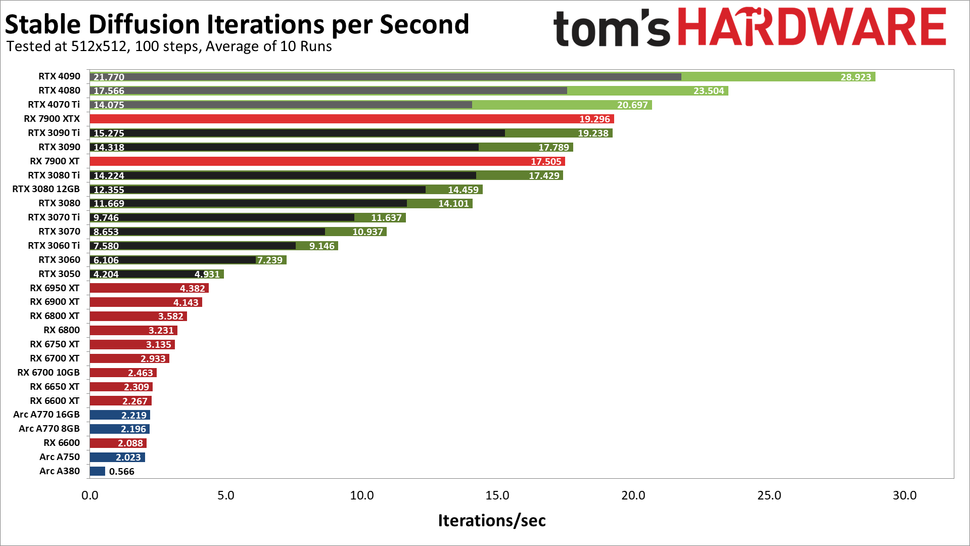
Here is a link to a tom's HARDWARE stable diffusion benchmark from January to get a rough idea on where various cards fit in for that use case:
{kind=link}