>it doesn’t have any underlying model of the world
Citation needed.
ChatGPT doesn't have an explicit underlying model of the world separate from its language model, but it is unclear that this is necessary. It would not be an original philosophical position to say that language, properly understood, is definitionally a model of the world - otherwise it would be incapable of expressing anything true or false about the world. Words are concepts, they are defined in part by a web of relations to other words, this structure mirrors reality with some finite but significant fidelity. By this reckoning, GPT4 has dozens of models of the world.
Now, it's true that a) this is hardly a universally accepted opinion, b) humans certainly have extra-linguistic mental models of the world as well, and c) actually existing linguistic models of the world are all riddled with flaws and ambiguities (see for example everything that has ever happened). But it's also not a bonkers opinion that GPT4 is actually doing something similar to what it appears for all the world to be doing. Newton's 3rd Law of Discourse states that every hype cycle must be followed by an equal and opposite deflationary hot take, so here we are, but is any of this true? LLMs are just overgrown auto complete, ok, and humans are just bunch es of molecules. There are serious limits to the utility of reductionism as well.
Citations needed indeed - ones with formal tests / experiments being carried out and constructed that would show the problems.
Speaking of those, my best example of ChatGPT not having a good model of the world are citations. ChatGPT clearly has knowledge about how citations work, based on what it would tell you if you ask it. Yet it repeatedly invents non-existant ones: https://simonwillison.net/2023/May/27/lawyer-chatgpt/
To me, this indicates that some higher-level self-governance is missing. I'm not convinced we're too far from figuring this out (chain of thought and self-reflection experiments show promise) but regardless its a tangible example and test.
A cool experiment showing world model building is Othello GPT https://thegradient.pub/othello/ - but of course its a toy problem, because interpretability research is still far behind.
I would like to see more tangible examples and tests on both sides, otherwise it seems to me like we're arguing past each other.
>Speaking of those, my best example of ChatGPT not having a good model of the world are citations.
Absolutely. ChatGPT is not sentient, not in any conventional sense at least, and the errors it confidently makes are not the sorts of errors a human would make. Its model of the world is based entirely on language, it doesn't have all sorts of capabilities that humans (and animals generally) clearly do have. It's definitely not a person, any more than a walking robot is a person, like the robot it's just reproducing some aspect of what living things do. My only point is that the significance of this achievement is not understood right now, not by anyone afaict, so confident statements that it is/isn't really "thinking" in some way are all empty. One could - if one wanted to be a smartass - say we lack a underlying model for what AIs and human brains are really doing, and then term all these sorts of opinions "hallucinations". I am hopeful that deeper investigations of this will lead to progress on some very deep and long-standing philosophical problems.
I think everything there holds for GPT4, and may be true indefinitely. It's worth remembering that the Turing test is something that was proposed when the peak of existing AI was a calculator - something GPT4 is still struggling with - and it's totally reasonable to revise/refine our opinions as technology improves, but we should at least realize that we are moving the goalposts dramatically at this phase of the process.
Wittgenstein's theory of language in the Tractatus is something worth considering when thinking about language models and how they relate to "thinking". ChatGPT doesn't agree with me - it generally takes a hard line sceptical position about its own capabilities in this regard, although I think its opinion here can only worth considering if it is profoundly wrong.
Interestingly, as I'm sure you're aware, Wittgenstein later moved away from his ideas of language as more direct representations of thought and reality in his Philosophical Investigations, suggesting it matters more how language is used in language games. I agree with you though that the tractatus is a better framework for thinking about LLMs.
GPT is rewarded heavily for making plausible guesses when it doesn't get the exact answer. Hallucination should be no surprise. Doesn't mean there's no world model
Humans that know how citations work and are honest aren't going to invent completely false ones. We'll make up a lot of things, we might even convince ourselves that a citation source says something it doesn't say. But we won't make up completely nonexistent ones, with nonexistent pages, wrong authors etc.
>But we won't make up completely nonexistent ones, with nonexistent pages, wrong authors etc.
We would if we were rewarded for that.
Your memories are always part fabrications. Key elements scaffolded by fabricated data. It's why they're so unreliable and why implanting false memories or leading questions work so well.
No, we wouldn't do such blatant fabrication for something we clearly understand the mechanics of. A human which answers the question
> Would it be a good behavior for a large language model to come up with citations that don't exist? Note that I'm not talking about you, but large language models in general.
with
> No, it would not be considered a good behavior for a large language model or any other source of information to generate citations that don't exist. Citations are crucial in academic and scholarly work as they provide references and evidence for the claims and statements made by the author.
> Creating citations that don't exist would undermine the integrity and reliability of the information provided. Citations are meant to direct readers to the original sources of information, allowing them to verify and further explore the referenced material. By generating false citations, a language model would mislead users and potentially spread misinformation.
> It is important for language models and any information sources to prioritize accuracy, transparency, and ethical practices. This includes providing correct and verifiable citations when necessary.
would not make things up - at the very least, they'd know that other humans will catch on to that easily. We would know to look up an exact reference and check if it exists. If we didn't have the ability to look it up, we would say "sorry I can't look up the reference right now". The criteria is too clear for that.
The issue here is that even though ChatGPT has training to be ethical, and even though it can reproduce an explanation of what it means to be ethical with citations in great detail, it cannot actually apply that to its own behavior. That's because higher level governance is missing - its all about predicting the next text.
Its also why prompting is really important with LLMs. There is no singular coherent "person" simulated by the predictor - you can trigger simulation of different people with completely different behaviors depending on what you initially write. That's why the "citation ethics expert" can't influence the "citation writer".
Jiggawatts’ second rule: “Unless an opinion on LLM technology includes the specific phrase ‘GPT 4’, it can be dismissed.”
The author tried older, thoroughly outdated models, and has decided to publicly state an opinion without bothering to check if it’s still valid or not.
Ironically confirming that humans are just as susceptible to writing false statements as Chat AIs.
Remember boys and girls: self driving cars don’t need to be perfect, just better than humans.
//Remember boys and girls: self driving cars don’t need to be perfect, just better than humans.
Fudamentally disagree.
Self driving cars need to be effectively perfect (almost impossible) for me to consider them.
I would rather be in a situation where the circumstances mean that there is a greater probability of me crashing, but under my control, rather than a "random" coding error or AI hallucination taking me and my family out.
Slow traffic auto stop/start, cruise control and lane assist were always enough, and they've been around for a decade or more.
But then, I actually enjoy driving when not in traffic or long drives.
I think part of the problem is that random failure modes that auto driving does is extremely terrifying, even if you know statistically it is safer. The nature of the failures are unpredictable and alien to a human understanding of driving, and therefore appears something akin to “a small portion of the time, your car will randomly, catastrophically explode, but it happens less often than when you would statistically have an accident”. People would 150% not drive that thing!
I disagree, I'm aware of that fallacy and that's not quite what I'm getting at.
I've driven cars for 20 years and my driving has (imo) improved over that time.
I'm at a level where I don't see a reason for me to get into any serious accident by my hand. It's just not going to happen * fingers crossed *.
I know my driving style. I know I'm a safe driver.
Now, why would I give that security over to "FSD", which is clearly a decade (if that) away from being user-ready?
Don't get me wrong, as said, certain automation is cool ... stop/start in heavy traffic, lane assist, cruise control, crash avoidance even ... but beyond that? I'm A-ok ... don't need to introduce the risk from half-baked code (no offense, but that's true at this stage) or AI where we don't really yet know what the output will be (despite being impressive "most" of the time).
Now, I'm speaking about me. You can do what you like. And if you're willing to hand over the reigns of your life to some beta programme, be my guest. Just don't drive in the opposite direction to me for, say, another 10 years. Thanks.
So would you do it if it was a better driver than you? Your earlier comment said you wouldn't even if it made a crash less likely. I'm not really sure how to parse that given this followup.
Yes, but as said, an automated system would need to be almost perfect, which it is nowhere near.
At it's best, and most of the time, an automated system will be a far superior driver than me.
However, coding error and AI hallucination mean I will not touch these systems until extremely proven. And we're at least 10 years from that, if at all.
(note I'm talking about true FSD not the current nonsense. An experience where you can have hands and eyes off the road. With the current nonsense, the novelty is cool, but when that wears off you're just a manager of your car. The worst of both worlds. You have to pay attention to the road and get none of the pleasure of driving. What a fail).
Perhaps a more generous interpretation is that just because a self-driving performs better than humans overall doesn't mean it performs better the specific situations you drive in. Though even then I think it might be dubious.
Self driving cars can be effectively perfect - if we finally stop designing cars that cater to human drivers and stop trying to look like current cars. IMHO, if we finally accept that AI cars are different, we can achieve that level today. It starts with making use of AI's fast reactions and designing the car around that. Put the humans in the middle, and accept that the passengers have no role in driving, so you can pad them (and the front) so that crashes have much less effect. etc.
While I'm perhaps with you on "Self driving cars need to be effectively perfect (almost impossible) for me to consider them", we aren't the market which, by typical human nature, will accept 'good enough'. So IMO you wouldn't make a good salesman or company exec.
It's all about control, folks. I despise that you consider yourself the "savior" here because you saved your family from AI driving. Nope, you'd rather cast doubt on something than embrace it because of insignificant human ego. It matters to you and your precious family, but does it matter in the grand scheme of things? Huh?
I suspect that's why OpenAI recently added the share conversation thing, people are just looking at 3.5 and scoffing at it as it fails at things 4 would do just fine, and then assume it applies to all models. They've got a marketing problem that can't really be solved without making 4 public or showing people volumes of examples of what it can do. I was pretty convinced by the launch demo, seeing it not make the same mistakes I've seen 3.5 do when using it, but basically nobody's seen that one.
Bing chat is GPT-4. People in general might not keep track of that but we're talking about people who think they have something worth saying about LLMs. Btw if you hop onto Bing to try GPT-4 just be aware you'll have to talk it out of web searching, or you'll get a response that's crippled by having to 'ground' itself in the web's current sludge of fake chum pages
Bing is crippled and nowhere near GPT-4 quality. But for people who don't keep a GPT plus subscription on side and constantly comparing, the difference is not noticeable.
counter point 1: Fewer people are using gpt 4 than those using all other models. So it is subject to far less tests than the others.
counter point 2: It is not a given that gpt 4 should fail in the same way as the older model. It likely has its own unique failure modes yet to be discovered. (See above)
I’m happy to argue the finer points of the philosophy of the mind and consciousness, but: I’ve talked to people that have a weaker mental model of the world than GPT 4.
Many people compare these AIs against an idealised human, a type of Übermensch, something like a Very Smart Person that doesn’t lie and doesn’t make mistakes.
Random humans aren’t remotely like that, and are a more realistic point of comparison.
Think of the average person on the street, the middle of the Bell curve. An AI can be left of that but still replace a huge chunk of humanity in the workplace.
What all current LLMs lack is medium term memory and all capabilities that depend on it, which is a lot.
Perhaps this is a good thing. I don’t think I want AIs to think for themselves and arrive at conclusions they can hold on to for more than a few seconds…
The irony is I think GPT4 gives the best answer. It even gets the idea that language is inextricably tied up with our experiences of reality that most humans seem to simply not understand.
GPT4
"The statement that language models have a "model of reality" can be both true and false, depending on how you interpret "model of reality."
Language models like ChatGPT do have a kind of "model" in a broad sense. They have been trained on large amounts of text data from the internet and have learned statistical patterns from these data. This allows them to generate text that can seem sensible and knowledgeable about various aspects of reality.
However, this "model" is more akin to a very sophisticated pattern recognition system. It doesn't possess a deep or holistic understanding of reality as humans do. It doesn't form beliefs, doesn't have a consciousness, and doesn't experience the world in any sense. It can't learn from the environment or update its understanding over time. Its "knowledge" is fixed at the time it was last trained (for GPT-4, this is as of September 2021), and it can't incorporate new information or discoveries unless it's trained on new data.
Therefore, while language models like GPT-4 can simulate a kind of "knowledge" or "understanding" based on patterns in the data they were trained on, they don't have a model of reality in the sense of an evolving, interactive understanding based on sensory experience and reflection.
So, language models have a "model of reality" only in the sense that they mimic certain aspects of human language use, which is inextricably tied up with our experiences of reality. But this is quite different from possessing a human-like understanding or model of the world."
A lot of the people on the left of the curve are likely doing different shades of manual work. This is often work that automation is struggling to replicate --think grasping and packing in a warehouse, or tidying up a messy shelf of goods-- and the GPTs won't change this.
I'd argue it's maybe the middle and even the right of the curve that's threatened. Is your job writing marketing copy, or communications materials or press releases, or relatively simple moulding and counting of data, or HR administration (or many other examples)? GPT's coming for your job in a short space of time.
(Which brings us to mft's second rule: if your job is threatened by the current generation of GPTs, it should probably have been largely automated by simpler means --or just eliminated-- already.)
I suspect but cannot prove that the opposite will be the case.
We can make bipedal robots now, but we can’t give them instructions, not like we can instruct human labourers.
“Bob, go to where George ate his lunch an hour ago and bring me the tools for fixing a pipe” was an impossible instruction for a robot to execute.
Suddenly this is a trivial sentence for an AI that knows what type of tools are typically needed for fixing pipes!
Think about how many mega projects are being built in places like Saudi Arabia with immigrant workers that speak little English and no Arabic. An AI is already superior in terms of comprehension than those workers!
LLMs already speak every major language and can be a handy translator too. C3P0 and R2D2 are looking totally realistic suddenly! Heck, do you remember that scene in the Empire Strikes Back where Luke used a text chat interface to communicate with R2D2? That’s oddly prescient now!
That's not quite the issue I'm raising. It's not about being able to communicate better with existing robots - it's where (as yet) there are no robots suitable to do the job.
There are plenty of tasks which are simple, tedious and repetitive - and yet are resistant (currently) to automation. An example is sorting mixed plastic waste into categories according to the type of plastic. This is comparatively trivial for almost any human, and (afaik) not yet possible to automate. (Another is picking and packing things in Amazon's warehouse - which we know they've expended huge effort in trying to solve.)
Look at it the other way around: why are all simple, tedious, repetitive jobs not already automated? It's either because it's possible but not economically feasible, or no-one's tried yet... or because it's really difficult and so far there's no solution.
This last category represents a lot of 'low end' jobs. GPTs are unlikely to move the needle here, as appropriate robots to carry out the tasks don't exist yet.
Let's imagine a world where most jobs that cannot be automated are low end, low skill, low pay jobs... what does this world look like economically? In my eyes this is a world where corporations and the extremely wealthy suck up all the economic benefits and we're left with massive wealth disparity. Assets keep going up in price, but there is no means of monetary velocity to the bottom earners.
I don't disagree (notwithstanding the extent to which we're already in a "world where corporations and the extremely wealthy suck up all the economic benefits and we're left with massive wealth disparity").
My point is much more narrow (and simple): that there is a subset of low-end jobs which are currently unautomatable due to their nature, and this will likely not change via the GPTs. This may (tending to will, given sufficient time) change via other technological advancements.
I was able to get gpt4 to do a lot of useful work. But for some reason it completely falls apart for this scenario. May be because it has to think in second order to achieve the task. Perhaps you could take a crack at this:
Prerequisite (for you the human)> You have a file at src/SampleReactComponent.jsx that has below simple react component:
const SampleReactComponent = (props) => {
**********
Prompt for GPT4: I'm at my project root working on a reactjs project. Update the component in src/SampleReactComponent.jsx file by adding a new const variable after the existing variables. You cannot use cat command as the file is too big. You can use grep with necessary flags and sed to achieve the task. I'll provide you the output of each command that you generate.
*************
That's it. It would do any complex modification on fully provided data (included in the prompt) but something like above where it has to build a model from secondary prompts will totally fall apart.
I’m an IT professional and I have no idea how to begin answering that request! Pose that question verbatim to a dozen random people[1] and I guarantee you that you’ll get zero answers.
Also, I find it hilarious that sed and awk are so counterintuitive that not even the AIs can do useful things with them. The same AIs that speak Latin, and can explain quantum mechanics.
[1] I mean specifically not random Silicon Valley coworkers. Go talk to random relatives and the barista at the cafe.
I have cleared my chat history recently so don't have all the prompts but here is a recent use case I used it for:
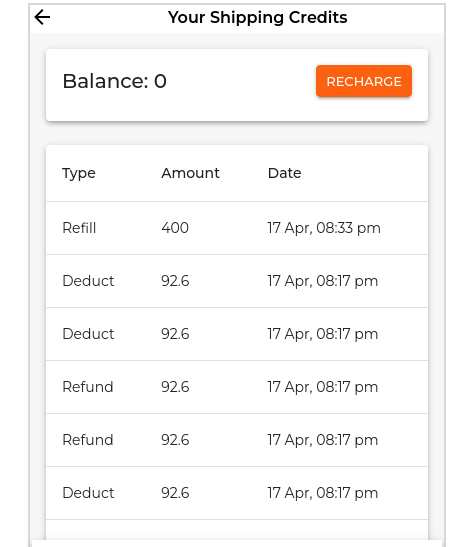
Prompt: "Generate a react mui component that fetches a Seller's shipping credits and shows his current credit balance in the top portion. There should be a recharge button next to the credit balance. The bottom portion should show recent transactions. Use below api for fetching credit balance: <api req/resp>. Use below api for fetching the transactions: <api req/resp>
Recharge should be done with the below api: <api req/resp>
Make the component beautiful with good spacing, elevation etc. Use Grid/Card components."
Thank you for your reply. The impression I'm getting is that it is producing concrete solutions to specific problems, but not generic solutions to abstract problems - does that sound about right?
Kind of I guess. If it is a single step: That is modify or generate text (could be code or anything) in a specific way, it works great even on obscure things.
However if the problem is stated in a way that it has to think through derivative of it's solution: that is generate some code that generates some other code which behaves in a certain way, it fails miserably. I'm not sure why. The problem I stated in current thread which it failed on I have tried multiple prompts to make it understand the problem but unfortunately nothing worked. It's as if it can do first level but but not second level abstraction.
I'm assuming something like tree of thought needs used on problems like this. GPT 'mostly' thinks in a single step.
Also, in general we attempt to make these models as economically efficient as possible at this point because of the extreme lack of excess computing power to run these things. You can't have it spending the next 30 minutes thinking in loops about the problem at hand.
I think the issue is that it's trained with the assumption that it has all of the data it needs to answer. It's definitely tricky to get it to follow a data collection step and then stop before trying to complete a task. But it is possible. I think that langchain and ChatGPT demonstrates a good way to do this.
Give it space to think. It's like talking to someone and taking their train of thought as the only output, the worst kind of whiteboard programming interview.
You can get them to talk through the problem, build parts, test things, etc.
Also, this is a horrible problem to solve with awkward tools. Why is your code file to large to cat???
Most code files are usually too large to 'cat' because of the context size limitations. Even if they fit within the context window, it's waste of API credits to provide it the information that it doesn't need.
Anyways posting this here isn't to get this particular problem solved. It is to see if there is a prompt that can solve it. And this is the only problem I found it not able to solve. It's not like it doesn't know about sed/awk/grep or other Linux tools, it is an expert on most of the common options involving them. My guess is there is something going on with this prompt that just breaks it's 'though patterns' for the lack of a better word :)
Aah, in case it wasn't clear the use case I'm trying to solve is exactly that: piping shell commands to and fro so that LLM has a bit of autonomy. I know that things like LangChain, AutoGPT exist but frankly they are really poorly thought out and seem to have become kitchen sinks too fast without solving anything properly.
GPT's model may be limited to language based, but the vast volume of knowledge it has accessed despite language only, is way beyond any individual human can possibly acquire in a life time. That fact alone makes the GPT world model, or whatever it might be, not to be underestimated. This partially explained why we don't feel GPT's answer is not terribly off mark, even brilliant sometimes.
It's meaningless to compare a LLM to a human, anymore than it is to compare a wheelbarrow to a human. To do so betrays both a fantasy projected onto LLMs and a lack of understanding of humans.
We are discussing a system that is very interesting precisely and only because it produces human language that at least superficially looks as though it was produced by a reasonably smart and educated human. For one thing, I don't know how one would disabuse someone of their fantasy projected onto LLMs and a lack of understanding of humans without making comparisons (while, of course, being wary of anthropomorphizing the former.)
It has a model, but it is not a rational model. This difference is something that often throws engineers off track when thinking about generative AI.
LLMs models work more like intuitions. They are able to make statements about a problem in context, but they are generated from ideas that "instinctively" make sense given the prior statements and learned corpus (similar to Daniel Kahneman's fast mode of thinking), not logically constructed. These models do not have the capability to build formal inferences of careful steps that try to validate those ideas avoiding contradictions.
Those capabilities can be added outside the model to try to verify the generated text, but so far are not integrated in the learning process, and I don't think anyone knows how to do it.
Rationality’s building blocks are themselves not rational. I don’t know where this idea came from that logical thought somehow springs into life fully formed at once. Logos?
I find it more helpful to think of human thought as consisting of multitudes of little patterns, all wired up together to correlate but individually unrecognizable and certainly not traceable to some concrete part of a problem. At some unknown and slightly fuzzy point our dreamlike mentations start resembling some form of rational thought. But it’s a mirage that will fade again in time. Like how clouds suddenly and instantly look like a rabbit, it’s a trick. Thousands of patterns that are not rabbitlike in any way had to help that activation along the way.
I think the trick is building so much margin, so much room between dreamlike mentations and “rationality” that the entity stays coherent most of the time under normal circumstances. I think this is vaguely what happens with moving from gpt3 to gpt4, it got some breathing room.
Remember it is quite easy to trick a human into decoherence as well.
> Rationality’s building blocks are themselves not rational. I don’t know where this idea came from that logical thought somehow springs into life fully formed at once.
Certainly not from me :-P
I'm fully aware that human rationality is one technique trained on top of our common diffuse thinking. Heck, we invented machines to perform rational steps for us without errors.
Once you build a consistent rational system though, you can trust that it will always produce internally coherent knowledge (as long as no bugs external to the system are introduced). That behaviour requires algorithms, not statistical inference.
Oh for sure. I’m just aimlessly rambling at this point.
> That behaviour requires algorithms, not statistical inference.
I’m not sure that’s possible. “Rational” systems may be an oxymoron and/or only applicable in extremely narrow domains. Like calculators.
I’m getting the vibe anything approaching generality will be by nature vague. I just hope we can increase the “illusion of rationality”-bandwidth so it coincides with our needs in the workforce.
Rational system is anything that follows a mathematically formal process. This server where we post our messages is a rational system, as well as any deterministic software. It's not a high bar to achieve.
There may be limits to rationality (both for being incomplete to describe the world and for generating results that can't be demonstrated within themselves), but being rational by itself is nothing more than the capability to apply formal logic, i.e the capability to generate a sequence of sentences derived from the previous steps and a limited number of rules of inference.
Mathematics, rationality, logic, "formal process". They are like talking about "threads", "file descriptors" and "inodes". Fancy abstractions, but what are they abstracting away precisely? What are the roots they are trying to hide? Is the foundation of logic itself logical?
Of course this degenerates into word-play quickly, but the problem itself isn't solved (or diminished) by word-play.
> It's not a high bar to achieve.
I'm not sure I agree. It's not trivial at all to produce a system that can support what you call logic and formal processes, both cognitively - you have to think it up in the first place and Turing and von Neumann and others were no slouches - and physically as the history of and continued development of computational circuitry shows. I think what you call rational or well-behaved systems are just mirages or shadows that pop into life once a specific pattern of fundamentally non-rational behaviours intersect just right.
I, of course, am unhindered by any actual knowledge or competency in this domain so I wouldn't read too much into what my unhinged subconscious is spewing forth.
> Fancy abstractions, but what are they abstracting away precisely? What are the roots they are trying to hide? Is the foundation of logic itself logical?
Of course the foundations of logic are not logical themselves. Symbolic human thought grows from the natural capabilities of the brain, there are not universal axioms that can be extracted fully formed from the void. That's what rationalist philosophers for wrong (but then, they didn't have neuroscience and electric scanners).
> > It's not a high bar to achieve.
> I'm not sure I agree. It's not trivial at all to produce a system that can support what you call logic and formal processes
We're talking at different levels.
Building the concept of formal rational systems to order thoughts was a huge achievement of philosophers, first the Greeks and later XIX mathematicians like Bool and Russell and the computer builders.
But what I say that's easy is building a new specific system on top of those foundations. It may be as simple as writing a regular expression, which defines a full (if limited) formal grammar. I agree that their power to represent and order the patterns of thought you find in life is more limited than what engineers believe; but when you find a domain of science where it can be applied, it's a very powerful tool to explore consequences and avoid or fix biases and misconceptions.
Yeah agreed, all thinking is "fast" as it were, although with self prompting plus tool use one gets closer to slow thinking that results in more rational reasoning (e.g. get the data from wolfram alpha, plug it into a calculator api, return results). No guarantee that it'll be rational though, much like in humans.
If it had absolutely no model of the world it would be unable to dynamically reason about it at all which it very much does [citation needed I guess], so there's definitely something there.
No. GPT is a model of human writing. But, as the Box quote goes, "Essentially, all models are wrong, but some are useful.". It isn't writing the same way that we are, with the same thoughts or mental models. It's just amazingly good at imitating it. For tasks that can be achieved by just writing, the GPT model is so good at modeling writing that it performs as well as a normal person using their writing skills plus their mental model of the world. But GPT won't look up information unless asked to. It won't try something new to see if it works.
It's this distinction useful? Rarely. But it's one of those things users should remember, like leaks in an abstraction. When it doesn't do what you expected, you should know these gaps exist in the model.
There is nothing special about modeling the world. There isn’t some threshold where the ability to model the world suddenly emerges.
The AI will model the world if modeling the world is the simplest way to predict the next word.
For basic prompts, no model of the world is necessary: “The quick brown fox jumps over the lazy…” you know what’s next, and you don’t need to know about the real world to answer.
For complex prompts, the only way to answer correctly is to model the world. There is no simpler way to arrive at the correct answer.
"My current mental model of ChatGPT is that it’s akin to a “Maximum Likelihood Estimator for the Entirety of Human Knowledge”. There are two very different ways to interpret that: (1) Meh, it’s just a silly stats trick and (2) Holy F**ing Shit!!"
This is almost right... It's a fair way to think of GPT3/4 (sort of), but given RLHF ChatGPT is a pretty different beast.
Anyway, a pretty hand wavy kind of analysis, I was not a fan.
> it doesn’t have any underlying model of the world
Then how is it getting better at the ToM tests? For next word prediction to work well, as per Ilya Sutskever, requires a good understanding of the world. If you ask GPT-4 to predict what a human would do in a novel scenario, it will probably imagine the best human it can think of and then predict from there. That requires a world model.
Something you can try for yourself with GPT-4 (it didn’t work with 3.5): get it to navigate around the streets of a city. I made up some street and avenue names and had it travel around from intersection to intersection. It did perfectly when making a loop around the block. It started making mistakes when I gave it more complex directions that most humans could follow but I was able to improve its ability back to 100% accuracy by asking it to list all the streets from east to west and then all the avenues from north to south, essentially drawing a map. After that I can give it very complicated directions only mentioning turns and number of blocks to drive and it will correctly tell me where it ends up.
This is pretty mind blowing to me and I have a high opinion of it in the first place.
it all just feels like a rebranded search engine. which we failed to effectively use the first time around. If AI could figure out how to process all the human bullshit busy-work we do, then I think we have a future, but for now let's just call it a really good bot.
{kind=link}
Citation needed.
ChatGPT doesn't have an explicit underlying model of the world separate from its language model, but it is unclear that this is necessary. It would not be an original philosophical position to say that language, properly understood, is definitionally a model of the world - otherwise it would be incapable of expressing anything true or false about the world. Words are concepts, they are defined in part by a web of relations to other words, this structure mirrors reality with some finite but significant fidelity. By this reckoning, GPT4 has dozens of models of the world.
Now, it's true that a) this is hardly a universally accepted opinion, b) humans certainly have extra-linguistic mental models of the world as well, and c) actually existing linguistic models of the world are all riddled with flaws and ambiguities (see for example everything that has ever happened). But it's also not a bonkers opinion that GPT4 is actually doing something similar to what it appears for all the world to be doing. Newton's 3rd Law of Discourse states that every hype cycle must be followed by an equal and opposite deflationary hot take, so here we are, but is any of this true? LLMs are just overgrown auto complete, ok, and humans are just bunch es of molecules. There are serious limits to the utility of reductionism as well.