The thing I still don't understand about REPL driven development is how you manage state, and how you manage threads. If I have a task running and it depends on a collection of global variables, those global variables now need some machinery around them so that they can be edited from the REPL thread. If you replace a function, there now needs to be decisions made about when you now begin usage of the new function. To me, the understanding that some set of things may be replaced right under you adds a great deal of additional engineering complexity. I've gotten various answers about how one deals with this. One being "yes add the machinery" or "just yolo it, yes it's a race condition but it's rarely an issue," neither of which I find particularly satisfying.
Concerning state, I've occasionally found myself developing a long-lived lisp image, and then I need to restart the VM for one reason or another, and then found that nothing works. The state of the in-memory image had gotten totally out of sync with the codebase. Perhaps this is a manner of discipline in lisp, but I greatly appreciate the replacement of discipline (be it memory management or the aforementioned situation) with machinery of the language itself.
It's already done for you by the runtime: it holds the state in the process memory. Now, with edit-compile-run-print loop if you want your state to persist between runs, you gotta implement some scheme of data persistence.
> it depends on a collection of global variables, those global variables now need some machinery around them so that they can be edited from the REPL thread.
In Erlang, you create a public named ETS table (basically, a thread-safe dictionary) and put "global settings" in there instead (and read them from there, too). I'd imagine LISP has something similar.
And mind you, I personally prefer the ECRPL instead of REPL, even when working in Python.
The "discipline" is to put the source code into a source file, the same thing you do with every other language. Don't do this and expect positive results:
;; some-package.lisp or whatever
(defun a-critical-function (...) ...)
Is table stakes for other languages, and Lispers are no worse programmers than programmers in other languages so why would they be incapable of this basic discipline? Only fools would write that in the REPL, never commit it to a source file, and be surprised when they couldn't reproduce the system state later on.
Same with loading data. It comes from a database, file, or other source. Preserve the method of loading the data in source like all other code.
> Only fools would write that in the REPL, never commit it to a source file, and be surprised when they couldn't reproduce the system state later on.
This happened a few times while I was developing https://laarc.io. It’s so addictive to just paste new functions into a repl and see the changes instantly that it’s easy to go a few hours without committing and realize your changes rely on a now-deleted function. :)
Wouldn’t trade that workflow for the world though. C++ compile/run separation makes it horribly obvious how much productivity you lose. It feels like walking into a pit of molasses. But even Python isn’t much better — I’m constantly tabbing to the repl, typing ctrl-R “reload” <enter>, then pressing the up arrow twice to evaluate the previous function example I was working on. I wish there was an auto reload feature that would just reload everything every time I evaluate a repl expression.
(I’ve been writing Bel lisp in Python, and I put in some code to do just that for bel.interact()’s repl. It’s so much nicer not having to reload manually all the time.)
Writing stuff in the repl directly is good. I'd like to have the repl track everything that gets entered and serialise it to a log file of some sort, preferably a loadable one, so that there's an option to dig the useful parts back out when finished experimenting.
> It’s so addictive to just paste new functions into a repl and see the changes instantly that it’s easy to go a few hours without committing and realize your changes rely on a now-deleted function. :)
I think Slime is a pretty happy middle ground. Instead of just pasting, the function gets written in a source file and then C-c C-c to evaluate it in the repl. I did once or twice run into similar issues though from depending on older or newer versions of functions that changed but weren’t completely reflected until a clean restart. But that’s been pretty rare and definitely wasted way less time than “make clean all” before committing C++ code :D
yes this is the correct way, this IS repl-driven development.. The REPL is a entrypoint into the world of the running program, and ideally the editor is connected to the program via the REPL, but you still write code in the editor.
Most Lisp beginner tutorials - the ones that don't start with teaching emacs - will ask the reader to just paste code into the REPL. This sets up bad habits... Perhaps we'll have better AND easier tutorials one day.
C-c C-u is bound to `slime-undefine-function`, though it prompts you for the name of the function and doesn't determine it by the present context. `slime-unintern-symbol` is also present but not bound by default and also prompts for the name.
You’re right. I think the other commenters aren’t being straightforward with you. It is a race condition to load a file one function at a time, because any other thread can preempt you.
Arc has a particularly elegant solution to this. Any code you want to happen atomically, you wrap in (atomic …)
So
(atomic x y z)
Will do x, y, then z. During this time, no other threads are allowed to run.
Therefore your load-file function might look like (pseudo code because phone):
(def load (filename)
(atomic
(each form (read-file filename)
(eval form))))
Now any time you call (load “code.arc”), it’s guaranteed that none of the other threads will run “mid-update”. If your file contains definitions that overwrite all functions in your program, then your entire program is guaranteed to update atomically.
Under the hood, (atomic …) is implemented with a recursive lock (cf. Python’s RLock). That way, if you call a function that calls atomic, which calls another function that calls atomic, you won’t deadlock — it’s the same thread, and the same thread can always acquire the lock recursively.
And that’s it. The lock is literally a single instance of a recursive mutex, stored globally, created at program startup.
Astute readers will notice one pitfall: suppose there are 10 threads running, and then you load file, which replaces all of the functions those threads were running. What happens?
Each thread is paused in the middle of some existing function. That function will continue to exist until nothing refers to it. Since those threads refer to those functions (because we’re paused at some spot in the function), the currently-executing functions wont vanish until all the threads wake up and return.
… which is particularly problematic if your thread is a while true: “do this forever” loop! There’s no way to update it anymore. You’d have to kill the thread and restart.
Which is why the solution is “don’t do that, do this.” Get rid of the while loop, and call yourself recursively. Now whenever the new function loads, calling that function by name means you’ll jump into the new function, abandoning the old one.
In languages without tail recursion (lookin at you Python, bastard), you can still achieve this by making sure your thread runner is a while-true loop that just calls some other function, and nothing else.
But if your tail recursion gets compiled down into the standard "label whatever, code blablabla, set address register to label whatever, jump" type-code, how do you change the address that the register gets set to?
Unless you do a lookup in the environment every time you recur to find where you have to jump to, but that would kill your performance stone dead.
I suspect (but cannot prove) that environment lookups are cached, so that when the new definition is loaded with the same name as the previous jump target, the compiled code is invalidated and switches back to interpreted mode. But now that I talk through it, that sounds pretty hard.
Occasionally I dive into racket’s good old C code for masochistic pleasure (it’s good code, just … very C, and very old). I always come away with a feeling of “well, that’s an interesting puzzle… I wonder what will happen when X happens” for every X that catches my attention. (Yesterday X was “How do racket’s thread-local parameters propagate their current values to new threads spawned by a subthread?)
Still, I’m ~50% confident that my original explanation is right, even if the details are wrong. I would be shocked if a compiled tail-recursive function didn’t jump into its own new definition when a new definition is loaded for the previous jump target (the global function name). Test it out and check what happens empirically. :)
Who knows. I’ve switched to Python long ago for daily tasks, since occasionally I enjoy “actually getting things done quickly, rather than endlessly researching interesting theoretical programming questions,” and Python is 60x slower than JavaScript (which doesn’t have tail recursion either), so #shruggyface. The world has apparently decided that tail recursion was an idea best left to the 90’s.
EDIT: After thinking it over, I bet you’re right and my original point about tail recursion is mistaken. And indeed, I remember now that in Arc, all the threads tend to be while-loops that just call another global function to do its work. Probably for this exact reason.
Very impressive callout. And a nice reminder to limit myself to talking about the things I actually do, not what I might theoretically do. At least not without qualifications and disclaimers. Thanks!
Thank you for calling it an impressive call out, but I actually am that idiot who didn't immediately think "oh yeah, you just cache the lookup and invalidate the cache when the thing gets changed."
Still, it's a good thing you mentioned Racket's old C codebase, I'll have to dive into that some time to see if there's anything interesting to learn from it.
IMO this is one of the main benefits of Clojure from a lisp-er perspective: it actually takes multithreading seriously in its design. It basically chose the "yes add the machinery" option, but built the machinery into the design of the language.
For instance, vars (i.e. global bindings) are mutable storage containers that can be bound on a per-thread basis. `(def foo "bar")` creates a new var and interns it in the current namespace, binding a root value "bar". Using it in code looks up the current value of it, either in thread-local storage or in the root binding. Any thread looking up the root binding of the var will see a newly bound value immediately.
However! Data in Clojure is immutable, which means that even if a running program started by looking up the current value of a var (or any of the other concurrency-safe containers in Clojure), once it has that value it is guaranteed not to change underneath you.
e.g. if you have a process that looks up the current value of a var and does some work with it for 5s, an in-flight process will not be altered if the var is redefined in the middle of the work. Other processes could even be kicked off that would alter the var, and it will have no affect on each other unless you explicitly synchronize, since the data inside the var is immutable.
Smalltalk only got a mention in the footnotes but I think it deserves a bigger entry when talking about ways to interact with programs. If a REPL is talking to and conversing with a program then environments like Pharo take it a step further by letting you interactively and graphically look under the hood as well. It's an amazing way to interact with software once you get used to it and I think well worth checking out if only for fun. https://pharo.org/
In todays world a distinction between Smalltalk and a Lisp listener is remote connectivity. Lisp needs a simple socket, whereas Smalltalk requires the full GUI.
I can certainly be mistaken but I don’t know if you can connect a typical modern Smalltalk workspace to a remote image. Nothing to stop someone from whipping up a straightforward socket listener to a ST image, but it’s not at all the same thing as what the desktop experience is.
Obviously not impossible just a distinction between them.
ST also solves the disparity between the image and the source code by logging all changes made to an image automatically. So it’s straightforward to roll forward an older image to a recent state by replaying the changes file.
In the opening paragraphs, this post indicates that this other post of David Vujuc [1] falls victim to common misconceptions about what a REPL is. I'm not sure what misconceptions this post is referring to; perhaps I also have these misconceptions. But I also don't think this post clarifies that. Could anyone here make it more explicit?
The Vujic post describes repl-driven development as "[evaluating] variables, code-blocks, functions, or an entire module [to] get instant feedback, just by hitting a key combination in your favorite code editor."
Speaking from the perspective of long experience with Lisp and Smalltalk environments, I agree with fogus here: this is a misconcpetion--or at least an impoverished version of repl-driven development. The existence of a repl does not constitute the repl-driven programming that fogus is talking about, nor that I was talking about in the blog post he references.
In its full form, repl-driven development means communicating directly with the live dynamic environment of your running program, which contains, in addition to the code you're developing, systematic support for inspecting, controlling, and modifying all of its code by directly interacting with it, and without needing to stop and restart the program in order to do that.
Clojure can do some of that, but not all of it. For example, unlike any implementation of Clojure I'm aware of, both Smalltalk and Common Lisp implementations support handling an error or other exception by starting up a nested repl within the dynamic context of the error so that you can inspect the live stack frames that are pending in the context of the error, modify any variables or functions or methods that are pending, and restart the computation at the frame of your choice.
Both Smalltalk and Common Lisp implementations support handling an undefined type or method by defining it interactively while the program waits, suspended in the error that alerted you to the missing definition, and then resuming execution after you've supplied the missing definition.
Both Smalltalk and Common Lisp implementations support redefining classes that have live instances while the program runs, they automatically catch references to those instances when they're referenced, and they automatically update them to reflect the new definitions (dropping you into a nested repl to specify how to do that, if that's needed).
No Clojure implementation I know of provides these features. Moreover, it's not just these specific features that are missing from Clojure and implementations of the other languages that have been mentioned here; also missing is the fundamental design orientation reflected in Common Lisp and its ancestral Lisps, and in Smalltalk: they were designed with the tacit assumption that the normal way to write a program was to start the runtime going and then change it bit-by-bit into the program you want by telling it interactively, feature-by-feature, how to be that program.
I and other people have made this point over and over for the past couple of years--and that's fine. I think the fact that it needs to be said over and over simply illustrates the misconception that fogus refers to: folks who have worked with repls have the notion that having a repl means that you're doing repl-driven programming. It doesn't--at least not in the sense that fogus is talking about, or that I'm talking about.
The unfortunate thing is that if you think that's all there is to repl-driven programming, there's a whole other layer of affordances that you're missing.
I'll briefly address two auxiliary points, because they always seem to come up.
First, I do not claim that repl-driven programming is objectively better than any other kind. If the affordances I'm talking about don't interest you, if you're happy without them, more power to you. All I care about is that I personally prefer them, and I want them to continue to exist and be further developed so that I and others who prefer them will continue to have them available. I think that making more people aware of those affordances increases the chances of that happening.
Second, someone will think that "repl-drive programming" means doing all your coding at a repl prompt. It doesn't mean that. It means writing your program by communicating with a read-eval-print loop--a repl--to tell the runtime how to become the program you want. The repl prompt isn't the repl; it's just one particular UI for the repl.
I work mainly in Common Lisp, and rarely type expressions at a repl prompt. Some influential repl-driven systems, such as Smalltalk-80 and Interlisp-D, may not even show you a prompt unless you specifically ask for it.
Repl-driven programming means talking to your running program while it runs, telling it how to change itself into the program you want. How you talk to the repl is a separate matter.
In a Smalltalk image, it usually means using the System Browser and related tools to find the classes and methods you want to modify and telling them to change. The Smalltalk image automatically saves those changes in the image itself, in the Changes file, and in the Sources file. Nowadays it probably also saves them to a git or other VCS repo.
In a Common Lisp environment, it usually means writing expressions in a source file and tapping a keystroke to send the the change expression, or its whole context, or the whole file, or all changed files, to the Lisp for compilation and loading into the running program. I and everyone I've worked with for years has kept those source files in a version-control system, just like any other code.
With respect to Clojure specifically, the subset of repl-driven programming features that it provides are good as far as they go. They aren't the whole enchilada, though, and when I work with Clojure I always miss the Common Lisp and Smalltalk features that are missing.
Another thing to consider is the world of Forth development. While the experience is interactive, you have an evaluation prompt, it’s not dynamic in the way that Lisp and Smalltalk are.
While it’s trivial to add words, do testing, etc. in Forth, none of those changes necessarily have direct impact. For example, in Lisp if you change a definition, the impact of that change affects not only new code, but existing code. If you redefine ‘foo’, not only will all new references reflect the new definition, but so will the old references.
Whereas in Forth, only new code is affected. If you want to see the impact of your new routine on the existing codebase you’ll need to reload it all. The typical workflow is ‘FORGET XXX’ to reset the dictionary and reload.
This means that any changes made at the prompt are fleeting. You have a great sandbox to play in, but you’ll need to migrate the code to the base source to see the real impact.
Also consider something like the classic BASIC environment. Here you have an interactive environment, and the code cycle can be very fast. You have some introspection to your running system (using STOP or keyboard interrupt, PRINT, assignments, and CONT), not the granular access that Lisp and ST offer.
For example in BASIC, typically, if you change the code at all, the existing variables get reset. So you can’t really make changes to a live program. But the turn around is quite fast to making this less of an issue.
unlike any implementation of Clojure I'm aware of, both Smalltalk and Common Lisp implementations support handling an error or other exception by starting up a nested repl...
I think that we've not taken the development of REPLs seriously enough in the Clojure community and have left a lot of power in the past because of it. Things could get a lot better for the state of nested REPLs and I've been knee-deep in explorations along one vector lately that I hope might push that angle just a little bit further along.
That seems like a tall order, though a worthwhile one.
You of course need a way to create a repl with visibility into the dynamic context from which it's created, which implies representing dynamic context in a way that's convenient for inspection.
If you want dynamic editing and recovery features similar to those of CL and Smalltalk systems, you'll also need the dynamic context to be represented in a way that permits mutation, which is a little awkward, considering Clojure's understandable preference for immutability and thread safety.
If you want to be able to restart from a user-selected stack frame, then you need something that serves the same purpose as Common Lisp's conditions and restarts, or Smalltalk's activation records. Maybe you could borrow the design of the Common Lisp condition system.
If you want to be able to handle dynamic redefinition gracefully, then you need something like Common Lisp's and Smalltalk's ability to automatically find and update live instances of a redefined type, which in turn requires system-level features for tracking changes to the type definitions of arbitrary instances, and a facility for automatically reinitializing them on-demand (which in turn requires the very breakloop features that you're building, because sometimes reinitialization requires user input).
This set of features is kind of a ball of hair that is hard to get right by bolting it on after the language is designed. The Julia folks have been struggling with it for years now. They work well in Common Lisp and Smalltalk, but I think that's because the languages were designed around these kinds of features from the start. Language support for them in Common Lisp, for instance, is written into the ANSI standard.
Also, of course, if the system can reinitialize live instances, then they can't really be immutable or thread safe--at least not from the point of view of the development environment, because it has to be able to mutate them as-needed. Maybe they can still be immutable from Clojure's point of view, but that implies that the development environment is not bound by the same rules as the language that it implements.
That's doable, of course. No law of nature requires that the development environment obey the same rules as the language that it implements. For example, Leibniz, the development environment for the Newton version of Dylan, was written in Common Lisp.
Of course, that meant that those of use who wanted to modify and extend Leibniz had to know Common Lisp as well as Dylan. But that's not so different from the situation with Clojure and Java.
Typically an advanced UI where one types into a REPL is called a 'Listener' in Lisp. Examples for Listeners: the MCL Listener, Genera's Listener, LispWorks Listener, the SLIME Listener and others.
For an impression of a Genera Listener I would recommend to see Kalman Reti's Youtube video: https://www.youtube.com/watch?v=o4-YnLpLgtk He shows there the Lisp Machine Listener debugging/interacting with mixed Lisp and C code.
MCL and LispWorks IDEs Listeners are running in an integrated editor. The running programming runs inside the development environment.
SLIME's Listener uses an external editor (GNU Emacs) for the Listener.
Genera has an integrated application as a Listener and that one is not based on an editor.
That's also a significant difference if the Listener is an internal tool, compared to an externally attached tool. External: from a user point of view, I use an IDE and connect to a running Lisp. Internal: I use the IDE and spawn a new Listener window (which could be on another X11 screen in case of an X11-based GUI). Usually the integration with internal Listeners is higher, but they may be more fragile, since they share the process & UI with the running program.
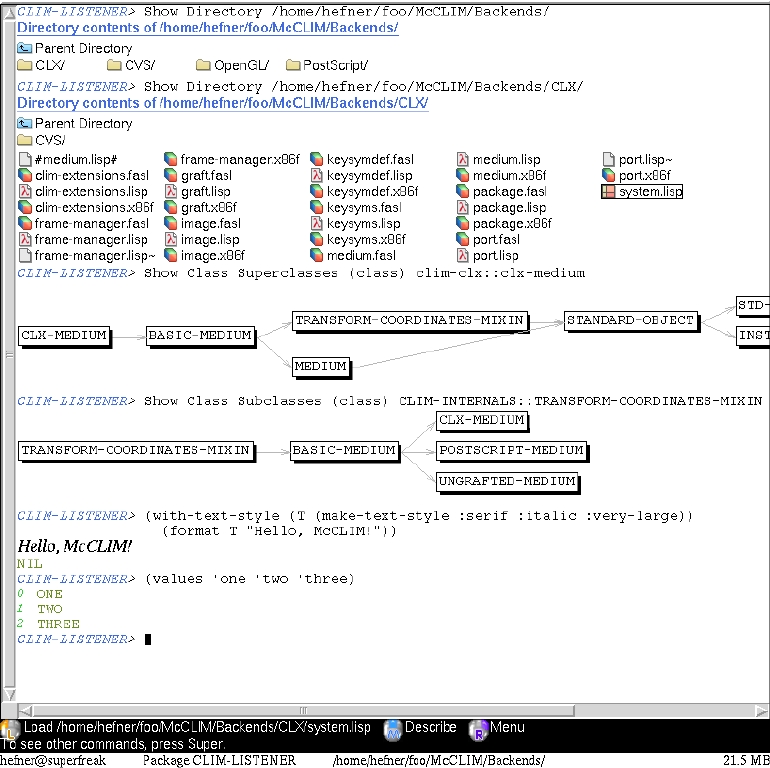
Using an editor as a base substrate has some advantages: one has usually better editing support in the Listener. But as Genera shows, a Listener does not need to run on top of an editor to be powerful. The Genera listener has for example full output recording, each listener is also a drawing plane and remembers all output and associates it with the displayed Lisp objects. That makes the interaction with code and data extremely convenient, a feature which is not provided by evaluating code from an editor buffer. SLIME provides a similar feature, but in a very limited way. The richer the Listener UI, the more of the interaction of the user will be in the Listener. Thus often an exclusive use of the editor to evaluate code is either a sign of a powerful editor integration or a weak Listener implementation. In Genera the Lisp listener is also not only a powerful data explorer, but also a shell with a lot of commands for exploring the Lisp system. A portable and in some ways slightly less polished / extensive version is the McCLIM listener. Example: https://mcclim.common-lisp.dev/static/media/screenshots/bund...
Also a Lisp might provide Listeners as panes of application frames. Thus an application window (either a tool of the IDE or any application GUI window) includes a corresponding Listener as a pane. As a simple example I can open a LispWorks Inspector and add a Listener pane. Any result from evaluation in the Listener will be displayed in a Inspector, with history.
The post by David Vujic actually mentioned the significant difference - REPL-driven in the way Clojure programmers understand it is not simply interpreting snippets of code in a separate process, but interacting with a running program, including all it's state and modifying it on the fly if needed.
Clojure programs listen on a extra port that you can connect your editor to and modify the program as it running.
Things like tests and notebooks may run the same code, but don't have the exact state and environment as your running program, be it running locally a staging env or even production.
This is not unique to Clojure, a Common Lisp program was famously running on a space probe and REPLed into decades ago, and Smalltalk code is stored in VM images, but few mainstream languages nowadays allow such interaction with a running program
Lisp programmers usually use the term "REPL" closer to its original form. read, eval, print, loop are primitives in Lisps. They consider what other languages call a "REPL" to be interpreters or mere command-line interactive interfaces.
Programmers in other languages usually suffice to calling an interactive interface a REPL.
This seems to leave out the existence of debuggers in IDEs.
These days I tend to run most new code in the debugger, and step through it so I can see what’s going on. This works great in say, Rust, Python, or Swift. I haven’t used Java for a while, but I don’t see why it wouldn’t work well there too.
True, for Java and Kotlin I use the debugger in IntelliJ like a REPL all the time.
You can even evaluate arbitrary expressions, connect to running applications even applications running on another machine.
It's not as powerful as a proper lisp repl as you cannot redefine functions or classes, but it is still very useful.
The author does mention debuggers. But you don't normally run a debugger on production or a testing environment and with a REPL you can. A debugger situates a program differently than it is normally used, a REPL connects to your code/state/environment in any stage of development.
I’ve done it in Elixir a handful of times to try to understand a bug that I couldn’t reproduce in my dev environment. And a few times to run some queries for a client and dump them out to CSV.
Elixir REPL in production yeah. Not to modify anything, but to inspect the state of the world and figure out why some OTP apps were dying. I'm drawing a blank on the name of the build tool, but the "launch binary" it produces has an option to fire up a second copy of your app, keep the console alive, and connect it to the cluster as another node. Worked like a charm, although it's something I wouldn't want to do on a regular basis :)
Nice writeup! Interesting comparison of OCaml (fast tooling but not connected to running program and data).
Lisp REPLs are something I use every day, but I also enjoy REPL development that is connected to look I've program and data with Python with Emacs, Ruby (when I used to use it), Haskel,and Julia.
{kind=link}
Concerning state, I've occasionally found myself developing a long-lived lisp image, and then I need to restart the VM for one reason or another, and then found that nothing works. The state of the in-memory image had gotten totally out of sync with the codebase. Perhaps this is a manner of discipline in lisp, but I greatly appreciate the replacement of discipline (be it memory management or the aforementioned situation) with machinery of the language itself.