I run multiple small EKS clusters at a small company. It doesn’t cost anywhere near $1 million per year, even taking my salary into account. If you don’t factor in my salary, it’s maybe $50k per year, and that’s for 4 clusters.
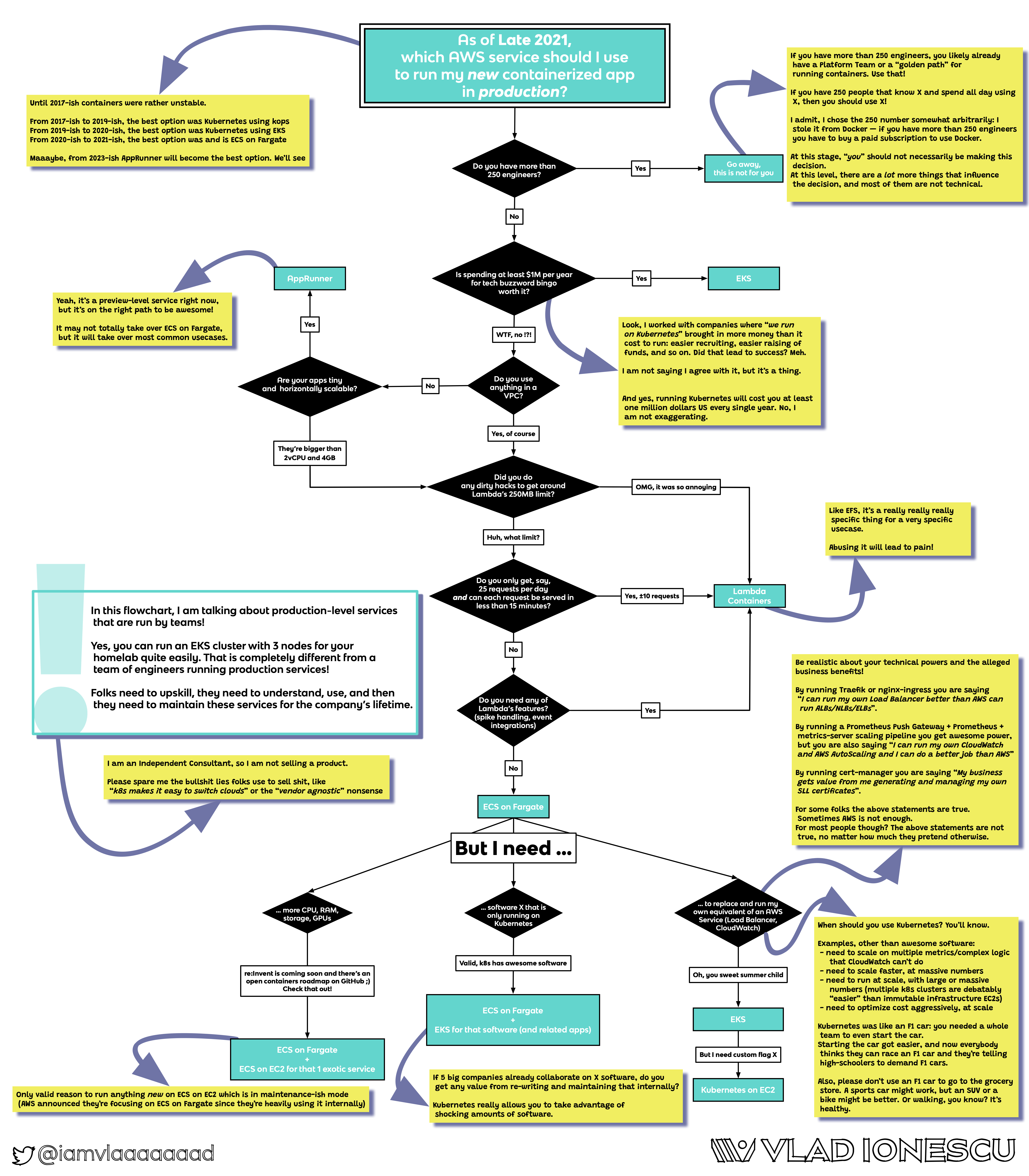
Honestly this flowchart is kind of a mess, and I certainly wouldn’t recommend it to anyone.
Same here. Multiple java/php applications on EKS. It got much better when we found a few guys who focused on resolving the issues instead complaining how hard kubernetes is.
If you have the desire to understand the individual components of running infrastructure for docker containers I'd suggest the full hashicorp stack.
Running nomad, vault, consul together isn't difficult, and will get you a better understanding how to deploy 12 factor apps with good secret storage and service discovery.
Add in Traefik for routing and you've got an equivalent stack to k8s, but you can actually understand what each piece is doing and scale each component as needed.
If you're going to run this all on AWS you can stick to just EC2 and not have to drown in documentation for each new abstraction AWS launches.
As an added bonus nomad can run far more things than just containers, so you have an on-ramp for your legacy apps.
I suppose one watch out is to not get too comfortable with the "isn't difficult" part. That seemed to be the root cause of the extended outage at Roblox. That the "it all works together" bit lulled them into not really researching the impact of changes.
How do you know that? I’ve only seen vague stuff from Roblox about the outage. Did you read between the lines in one of those posts and conclude it had to do with Hashistack interoperability? Would love to know what you read that implied that.
Then reading back their vague statements like "A core system in our infrastructure became overwhelmed, prompted by a subtle bug in our backend service communications" and seeing if that matches. It seems to.
Yeah no. ECS is the worst of all worlds, Fargate made it less shit, it didn't make it good.
If you don't have the people to do k8s then stick to Lightsail, don't do containers poorly just because you can.
Half-assing it will just make everyone miserable and end up with a mix-match of "thing that can run on ECS" and "things that can't because they need X" where X is really common/useful things like stateful volumes (EBS).
My experience with ECS is quite okay. You start a cluster, stick a container on it through a task and optionally a service + load balancer and it just works.
It doesn't seem any harder than EKS, and it's mostly cheaper.
I also find some comments on this article about vendor lock-in dubious, because in the end it's a bunch of containers created from Dockerfiles, which you can easily reuse elsewhere.
ECS can do EBS volumes via the Rex-Ray Docker plugin. Depending on how fast you need new instances to come up, installation can be a 5-liner in userdata
This is awful. It completely ignores the economics of leveraging commodity services and re-usable skills while ignoring the true places where you can get maximal value if you are willing to accept vendor lock in - the high level services.
This is more or less the equivalent of mandating that everyone use VMS once UNIX started to commodify, or use Windows for all of your servers once Linux has taken over the market. Using EKS + Fargate instead of ECS + fargate provides no savings over EKS, All it serves to do is to lock you into a single hyper-scaler infrastructure, at the same time as K8s is forcing he cloud vendors into commoditization.
Want to use AWS effectively? Depend on high level services like Glue, Athena, Kinesis Firehose, Sagemaker. Want to piss away any chance to run your business effectively? Leverage ECS.
If you are a one-man shop, and you know ECS or are willing to depend on underbaked solutions because they solve a problem, more power to you. I suspect that you may benefit over your career by investing in more universal skill sets (alternative, you may benefit from hyper-specializing on AWS toolsets as well(.
AWS is good at giving you commodity infrastructure at scale. They are really good at "stupid" services like S3 or EC2 or RDS. The high-level services meanwhile? I worked with quite a few of them and they're mostly shit.
Athena is has account-wide limit of 5 concurrent queries which cannot be increased. Even one larger dashboard will overload it.
Redshift have the same limit of 30 concurrent queries. That's good enough for casual use but not suitable for larger company.
Glue Catalog does not scale at all, and having more than few objects will break it, and you will very soon end up begging for more API limit due to throttling exceptions.
Kinesis has very strange limits (in messages per second) that make it really expensive for use cases where traffic is peaky - which is quite a few streaming use cases.
Just like you wouldn't use Amazon.com to buy high-quality, important goods (because you're pretty likely to get something broken or fake), don't use AWS "high level" services. Amazon is company focused on scaling commodity use cases, not at engineering excellency.
> Amazon is company focused on scaling commodity use cases, not at engineering excellency.
I think of it slightly differently. S3 is clearly the product of engineering excellency (as is DynamoDb).
But I think there are A teams and B teams at AWS, as you would expect from any company so large. And I get the sense that at least some of the newer, less proven solutions were written by the B teams. This likely includes some k8s-market-share-grabby offerings.
I heard same story told slightly differently - for services that process your requests when you go to amazon.com to buy stuff, you can expect engineering excellency. That would be dynamo, s3, ec2, networking (that whole side of AWS - hypervisors, networks, etc., I'd call engineering marvel).
But that would not be software they build "for someone else", like Redshift and Glue and Sagemaker and whole lot of other stuff. There's a whole lot of half-baked services in the ~200 they have.
If they actually can increase the concurrency now, that's good news!
We asked for that as well, and at first the support said they did that, but turns out they increased the Athena queue length instead of concurrency - so the queries wouldn't fail (until the queue is full, anyway) but the throughput was still the same.
Then the team of AWS account managers and solutions architects (who assured us many times that the concurrency can be increased) get into a email discussion with the support and Athena team, before coming back and telling us it cannot be increased. No apology or anything. Recommended us to run Presto on EMR instead.
I have never heard of AppRunner, thanks for posting this!
I've used Fargate as I thought it was the easiest/cheapest route, but according to the notes on chart:
"From 2020-2021 the best option was/is ECS and Fargate".
"Maybe from 2023-ish AppRunner will become the best option. It's a preview service right now but on the path to be awesome!"
"It may not totally take over ECS on Fargate, but it will take over most common usecases."
And according to this chart, AppRunner apparently is the service I ought to be using for most of my apps.
It comes to the same conclusions that I intuitively had as well:
- EKS if you really have to use k8s
- ECS if you have a modicum of complexity but still want to keep it simple
- AppRunner if you just want to run a container
But AppRunner also scales down to zero (albeit with reduced instead of zero billing).
For use-cases like distributed job scheduling, an EventBridge event triggering either an AppRunner request or a CodeBuild execution or an ECS task could work. It's still a little tricky to figure out what the best choice is.
Cool link, although I think that in case your deployment package is <100MB then it's preferable to use AWS Lambdas by simply deploying the zip file archive instead of pushing a container image.
Last time I tried it (~May 2021), Lambda containers had terrible cold start times. Even a node hello world would cold start in 2-3 seconds. Same code packaged as a ZIP file would cold start in less than 1/10th the time. Maybe its better now?
It's been a year since I touched an AWS lambda, but I'd bet money that cold starts are still an issue. There is a common hack that half works: have your function run every minute (you can use eventbridge rules for this); in the function handler, the first thing you should evaluate is whether or not it's a warming event or not, and exit 0 if it is. Your results may vary (mine did lol)
Unfortunately, my enterprise scale employer forced me onto ECS on EC2 for some of my apps for a very specific reason: Reserved instance pricing. I think there’s reserved instance-like pricing for Fargate now. For one particular set of containers (Java application we license from a vendor and then customize with plugins somewhat), the CPU and RAM requirements are fairly large so the savings of ECS on EC2 with the longest Reserved Instance Contract means that I will forever be dealing with the idiocy of ASG based Capacity Providers.
For those not in the know, ASG based Capacity Providers are hard to work with because they are very immutable so you end up having to create-then-delete any changes that touch the capacity provider. A capacity provider cannot be deleted if the ASG has any instances. Many tools like terraform’s AWS provider will refuse to delete the ASG till the capacity provider is deleted. The terraform provider just cannot properly reason about the process of discovering and scaling in the ECS tasks on the provider, scaling in the ASG, waiting for 0 instances, and then deleting the Capacity Provider. It’s honestly beyond how providers are supposed to work.
TL;DR: The flow chart is somewhat correct: Do everything in your power to run on ECS Fargate. It’s mature enough and has excellent VPC and IAM support these days. Stay as far away from ECS on EC2 as you can.
As for EKS, I like it but this company runs on the whole “everyone can do whatever” so each team would have to run its own EKS cluster. If we had a centralized team providing a base k8s cluster with monitoring and what not built in for us to deploy on, I’d be more amenable to it. As it stands, I would have to learn both the development and ops AND security sides of running EKS for a handful of apps. ECS while seeming similar on the surface is much simpler and externalizes concepts like ingresses and load balancing and persistence into the AWS concepts and tooling (CDK, CloudFormation, Terraform) you already know (one hopes).
I would go as far to say avoid ECS as much as necessary. Using ECS heavily either means using CloudFormation or Terraform heavily, both of which are shitty tools (TF is probably the best tool in it's class, haven't tried Pulumi yet but doesn't stop it from being shit).
Importantly both of which are almost impossible for "normal" developers to use with any level of competency. This leads to 2 inevitable outcomes, a) snowflakes and all the special per-app ops work that entails and b) app teams pushing everything back to infrastructure teams because they either don't want to work with TF or can't be granted sufficient permissions to use it effectively.
k8s solves these challenges much more effectively assuming your ops team is capable of setting it up, managing the cluster(s), namespaces, RBAC, etc and any base-level services like external-dns, some ingress provider, cert-manager, etc.
Once you do this then app teams are able to deploy directly, they can use helm (eww but it works) to spin up whatever off-the-shelf software they want and are able to easily write manifests in a way that they can't fuck up horribly as easily.
Best for both teams, ops and devs. Downside? Requires competent ops team (hard to find) and also some amount of taste in tooling (use things like tanka to make manifests less shit), not to mention the time to actually spin all this up in peace without being pushed to do tons of ad-hoc garbage continually (i.e competent org).
So in summary, k8s is generally the right solution for larger orgs because it enforces better split of responsibilities and establishes a powerful (relatively) easy to use API that can support practically everything.
People focus way too much on the orchestration aspect of Kubernetes when the real draw for larger, more mature organizations is that it provides a good API for doing pretty much anything infrastructure or operations related. You can take the API primitives and build whatever abstractions you want on top of them to match up with how your org deploys and operates software. Once you get into stuff like Open Application Model and start marrying it to operators that can deploy AWS resources and whatever GitOps tool you want to use, you end up with a really nice, consistent interface for developers that removes your infrastructure folks as a bottleneck in the "Hi I want to deploy this new thing everywhere" process.
> So in summary, k8s is generally the right solution for larger orgs because it enforces better split of responsibilities and establishes a powerful (relatively) easy to use API that can support practically everything.
And therein lies the problem, my employer won't consolidate the enterprise like that. They're still throwing 100 or so teams around and telling them BIRI (build it, run it) and making everyone write their own infra and application code because "DEVOPS".
Makes me think there is probably a market for a k8s w/batteries distribution + ops as a service available via AWS VPC peering/transit GW if such a thing doesn't already exist. i.e pre-setup with good patterns, pluggable/easy OIDC auth, cert-manager and friends.
Essentially to cater to the "I need k8s but I don't have the people for it and this makes me sad" crowd.
Even without using reserved instance pricing, ECS on EC2 is much cheaper, isn't it? At work we use Hasura, which is written in Haskell and cannot be (easily?) run as a Lambda. Our alternative solution is to run it as a container on ECS. Given that it's a permanently running service, with Fargate we'd pay just to have it sit idle for half of the time, and Fargate is not cheap.
Even when running non-reserved EC2 instances to make up our ECS cluster, it is cheaper than using Fargate.
Well, to begin with, I think people worry too much about vendor lock-in. Use the tools your cloud vendor provides to make your life easier. Isn’t that one of the reasons you chose them?
That said, moving containers to another container orchestrator isn’t terribly difficult, so I don’t personally worry about vendor lock-in for containerized workloads. If your workloads have dependencies on other vendor-specific services, that’s a different story, but basically a container is easy to move elsewhere.
My current company has a cluster on Amazon, one on Azure, and used to have one on a local hosting company. So it's very important to not be stuck too much with one cloud providers locks.
We also chose our current cloud providers because the alternatives were worse.
Vendor lock-in can be a real issue as you scale. I work at a company going through a hypergrowth phase, and we're more or less locked into Azure, which has been objectively awful for us
Yes it's significant, that's why I don't like vendor lock-in. It's very simple to use VMs on various cloud providers but as soon as you use their more integrated products, it can be a disaster.
It’s that simple. If you need extensions into the AWS infrastructure, check out their CRD extensions that allow you to provision all of the infrastructure using K8s.
our infra is running on ECS because we set it up right before docker on lambda haha. Now we dont have the time to switch. Would be much better for us though.
> If you have less than 250 engineers, this guide is not for you? Strange.
I'd guess that if your org is big enough to have 250 engineers in its payroll, AWS services are a waste of cash given you can deploy better and cheaper. For example, Hetzner has less than 200 employees, and it's a global cloud provider.
At the high end AWS was a huge win for "traditional enterprises" because it broke them free from being held hostage by their own internal IT bureaucracies.
Enterprises provided many of the things inside AWS but much, much worse.
I actually think the political revolution it (cloud) triggered was a bigger thing than the technical and engineering changes.
AWS is expensive compared to a machine under your desk but not so much compared to the fully loaded cost of (say) a VMware VM at a bank DC, which includes multi-year enterprise hardware & software commitments to make it go plus staff and admin costs.
The DC model choked off innovation that was not approved "from the top" and severely damaged agility.
Totally agree with this and have made the same point many times. The chance to reset the culture, operating model, politics and suppliers is the really big opportunity for big companies adopting cloud.
I think the people complaining about cloud have never had to work in a large enterprise with an internal IT department managing a physical datacenter. Even at Google people complain about that side of things.
This apples to oranges comparision always keeps coming up. Comparing AWS to a VPS/Physical Services provider is strange. AWS has more services than Hetzner has as employees. AWS bandwidth, computation has huge and unreasonable price, but there are also superb services in AWS like S3, SQS, DynamoDB, Lambda.
All major cloud providers have similar computation pricing. As much as I love Hetzner, they are not a major cloud provider.
In my experience the productivity cost on a larger company of physical servers is massive. The IT department is a monopolistic provider of compute services to other departments. At the same time IT competes with those departments for overall company budget. Needless to say the result of these mismatched economic and political incentives is a mess.
I don’t think this is true at all. AWS has a lot more in an org than “the bill is smaller.” There’s a restrictive factor when hiring if you move away from Google Cloud,Azure, and AWS.
> I don’t think this is true at all. AWS has a lot more in an org than “the bill is smaller.”
The bill is not only astronomically high but it's also unpredictable and uncontrollable. Which added valued do you believe justifies this?
Meanwhile, keep in mind that the likes of Dropbox gave AWS a try but in the end learned from their experience and opted to migrate out after only 5 years.
> There’s a restrictive factor when hiring if you move away from Google Cloud,Azure, and AWS.
I disagree, considering that in AWS you either run vanilla VMs from EC2, or containerized solutions in ECS/EKS. Either way you are already better off using either your local VMs or your company's kubernetes deployment.
>The bill is not only astronomically high but it's also unpredictable and uncontrollable.
If you've got 250 engineers then the AWS is going to be fairly predictable and well monitored.
>Meanwhile, keep in mind that the likes of Dropbox gave AWS a try but in the end learned from their experience and opted to migrate out after only 5 years.
Dropbox is memorable because they migrated off which says what many other companies don't do.
As you can tell by the massive growth of Azure many large enterprise companies definitely see the value despite already have their own datacenters.
> If you've got 250 engineers then the AWS is going to be fairly predictable and well monitored.
This is the very first time I hear anyone describe AWS services as "fairly predictable and well monitored", because there is simply no such thing. There are professional services being sold at a premium whose value proposition is to make sense of AWS billing and reign it in. With AWS, your company simply sets a budget with a significant slack and hope for the best.
> Dropbox is memorable because they migrated off which says what many other companies don't do.
Not true. Dropbox is memorable because it was depicted as a poster child of AWS, which ultimately found out it was not worth it at all. And Dropbox is not alone.
{kind=link}
Honestly this flowchart is kind of a mess, and I certainly wouldn’t recommend it to anyone.