They said the Macbook Air (specifically) is "3x faster than the best selling PC laptop in its class" and that its "faster than 98% of PC laptops sold in the last year".
There was no "in its class" designation on the 98% figure. If they're taken at their word, its among every PC laptop sold in the past year, period.
Frankly, given what we saw today, and the leaked A14x benchmarks a few days ago (which may be this M1 chip or a different, lower power chip for the upcoming iPad Pro, either way); there is almost no chance that the 16" MBPs still being sold with Intel chips will be able to match the 13". They probably could have released a 16" model today with the M1 and it would still be an upgrade. But, they're probably holding back and waiting for a better graphics solution in an upcoming M1x-like chip.
If you believe that, then you've either been accidentally ignoring Apple's chip R&D over the past three years, or intentionally spinning it against them out of some more general dislike of the company.
The most powerful Macbook Pro, with a Core i9-9980HK, posts a Geekbench 5 of 1096/6869. The A12z in the iPad Pro posts a 1120/4648. This is a relatively fair comparison because both of these chips were released in ~2018-2019; Apple was winning in single-core performance at least a year ago, at a lower TDP, with no fan.
The A14, released this year, posts a 1584/4181 @ 6 watts. This is, frankly, incomprehensible. The most powerful single core mark ever submitted to Geekbench is the brand-spanking-new Ryzen 9 5950X; a 1627/15427 @ 105 watts & $800. Apple is close to matching the best AMD has, on a DESKTOP, at 5% the power draw, and with passive cooling.
We need to wait for M1 benchmarks, but this is an architecture that the PC market needs to be scared of. There is no evidence that they aren't capable of scaling multicore performance when provided a higher power envelope, especially given how freakin low the A14's TDP is already. What of the power envelope of the 16" Macbook Pro? If they can put 8 cores in the MBA, will they do 16 in the MBP16? God forbid, 24? Zen 3 is the only other architecture that approaches A14 performance, and it demands 10x the power to do it.
Not all geekbench scores are created equal. Comparing ARM and x86 scores is an exercise in futility as there are simply too many factors to work through. It also doesn't include all workload types.
For example, I can say with 100% confidence that M1 has nowhere near 32MB of onboard cache. Once it starts hitting cache limits, it's performance will drop off a cliff as fast cores that can't be fed are just slow cores. It's also worth noting that around 30% of the AMD power budget is just Infinity Fabric (hypertransport 4.0). When things get wide and you have to manage that much wider complexity, the resulting control circuitry has a big effect on power consumption too.
All that said, I do wonder how much of a part the ISA plays here.
M1 has 16MB of L2 cache; 12MB dedicated to the HP cores and 4MB dedicated to the LP cores.
Another important consideration is the on-SOC DRAM. This is really incomparable to anything else on the market, x86 or ARM, so its hard to say how this will impact performance, but it may help alleviate the need for a larger cache.
I think its pretty clear that Apple has something special here when we're quibbling about the cache and power draw per core differences of a 10 watt chip versus a 100 watt one; its missing the bigger picture that Apple did this at 10 watts. They're so far beyond their own class, and the next two above it, that we're frantically trying to explain it as anything except alien technology by drawing comparisons to chips which require power supplies the size of sixteen iPhones. Even if they were just short of mobile i9 performance (they're not), this would still be a massive feat of engineering worthy of an upgrade.
AMD's Smart Memory Access was recently announced. In unoptimized games, they're projecting a 5% performance boost between their stock overclock and SMA (rumors put the overclock at only around 1%).
The bigger issue here is bandwidth. AMD hasn't increased their APU graphics much because the slow DDR4 128-bit bus isn't sufficient (let alone when the CPU and GPU are both needing to use that bandwidth).
I also didn't mention PCIe lanes. They are notoriously power hungry and that higher TDP chip not only has way more, but also has PCIe 4 lanes which have twice the bandwidth and a big increase in power consumption (why they stuck with PCIe 3 on mobile).
It's also notable that even equal cache sizes are not created equal. Lowering the latency requires more sophisticated designs which also use more power.
I don't see why they would care that they are destroying sales of the intel MBP 13. Let consumers buy what they want - the M1 chip is likely far higher profit margins than the intel variant, and encouraging consumers to the Apple chip model is definitely a profit driver.
Some people especially developers may be skeptical of leaving x86 at this stage. I think the smart ones would just delay a laptop purchase until ARM is proven with docker and other developer workflows.
Another consideration - companies buying Apple machines will likely stay on Intel for a longer time, as supporting both Intel and ARM from an enterprise IT perspective just sounds like a PITA.
That uses hardware virtualization which is very much dependent on the architecture. Running an x86 docker image on a M1 would take a significant performance penalty.
My Linux laptop locks up every now and then with swapping when I'm running our app in k3s; three database servers (2 mysql, 1 clickhouse), 4 JVMs, node, rails, IntelliJ, Chrome, Firefox and Slack, and you're starting to hit the buffers. I was contemplating adding more ram; 64 GB looks appealing.
I would not buy a new machine today for work with less than 32 GB.
The first 20” Intel iMac was released in the same chassis as the G5 iMac it was replacing with 2-3x the CPU speed. I beleive they continued to sell the G5 model for a brief while though for those that needed a PPC machine.
I think that’s the point? They want to show that M1 decimates comparable Intel chips even at lower price points.
This release is entirely within Apples control, why would they risk damaging their brand releasing a chip with lower performance than the current Intel chips they are shipping. They would only do this at a time when they would completely dominate the competition.
But, just looking at A14 performance and extrapolating its big/little 2/4 cores to M1's 4/4; In the shortest tldr possible; Yes.
M1 should have stronger single-core CPU performance than any Mac Apple currently sells, including the Mac Pro. I think Apple's statement that they've produced the "world's fastest CPU core" is overall a valid statement to make, just from the info we independent third-parties have, but only because AMD Zen 3 is so new. Essentially no third parties have Zen 3, Apple probably doesn't for comparison, but just going on the information we know about Zen 3 and M1, its very likely that Zen 3 will trade blows in single core perf with the Firestorm cores in A14/M1. Likely very workload dependent, and it'll be difficult to say who is faster; they're both real marvels of technology.
Multicore is harder to make any definitive conclusions about.
The real issue in comparison before we get M1 samples is that its a big/little 4/4. If we agree that Firestorm is god-powerful, then can say pretty accurately say that its faster than any other four-core CPU (there are no four-core Zen 3 CPUs yet). There's other tertiary factors of course, but I think its safe enough; so that covers the Intel MBP13. Apple has never had an issue cannibalizing their own sales, so I don't think they really care if Intel MBP13 sales drop.
But, the Intel MBP16 runs 6 & 8 core processors, and trying to theorycraft what performance the Icestorm cores in M1 will contribute gets difficult. My gut says that M1 w/ active cooling will outperform the six core i7 in every way, but will trade blows with the eight core i9. A major part of this is that the MBP16 still runs on 9th gen Intel chips. Another part is that cooling the i7/i9 has always been problematic, and those things hit a thermal limit under sustained load (then again, maybe the M1 will as well even with the fan, we'll see).
But, also to be clear: Apple is not putting the M1 in the MBP16. Most likely, they'll be revving it similar to how they do A14/A14x; think M1/M1x. This will probably come with more cores and a more powerful GPU, not to mention more memory, so I think the M1 and i9 comparisons, while interesting, are purely academic. They've got the thermal envelope to put more Firestorm cores inside this hypothetical M1x, and in that scenario, Intel has nothing that compares.
> But, the Intel MBP16 runs 6 & 8 core processors, and trying to theorycraft what performance the Icestorm cores in M1 will contribute gets difficult.
Anandtech's spec2006 benchmarks of the A14 [0] suggest the little cores are 1/3 of the performance of the big ones on integer, and 1/4 on floating point. (It was closer to 1/4 and 1/5 for the A13.) If that trend holds for the M1's cores, then that might help your estimates.
> Not all geekbench scores are created equal. Comparing ARM and x86 scores is an exercise in futility as there are simply too many factors to work through. It also doesn't include all workload types.
The meme of saying that Geekbench is not a useful metric across cores, or that it is not representative of real-world usage, and therefore cannot be used needs to die. It’s not perfect, it can never be perfect. But it’s not like it will be randomly off by a factor of two. I’ve been running extremely compute-bound workloads on both Intel and Apple’s chips for quite a while and these chips are 100% what Geekbench says about them. Yes, they are just that good.
In the case of Infinity Fabric: high speed I/O links generally consume gobs of power just to wiggle the pins, long before any control plane gets involved.
In this case, it's high speed differential signaling, and that's going to have a /lot/ of active power. There's a lot of C*dv/dt going on there!
I’m pretty sure the amount of cache on the chip was on one of the slides, according to Wikipedia it’s 192 kb for instructions and 128 kb for data.
To me it seems pretty unlikely to be that important because if you can have 16gb of memory in the chip, how hard can it be to increase the caches a fraction of that?
A normal SRAM cell takes 6 transistors. 6 * 8 * 1024 * 1024 * <total_mb> is a big number.
Next, SRAM doesn't scale like normal transistors. TSMC N7 cells are 0.027 nanometers while MY cells are 0.021 (1.35x). meanwhile, normal transistors got a 1.85x shrink.
I-cache is also different across architectures. x86 uses 15-20% less instruction memory for the same program (on average). This means for the same size cache that x86 can store more code and have a higher hit rate.
The next issue is latency. Larger cache sizes mean larger latencies. AMD and Intel have both used 64kb L1 and then move back to 32kb because of latencies. The fact that x86 chips get such good performance with a fraction of the L1 cache points more to since kind of inefficiency in Apples design. I'd guess AMD/Intel have much better prefetcher designs.
> 6 * 8 * 1024 * 1024 * <total_mb> is a big number.
No, when your chip has many billions of transistors that’s not a big number. For 1 mb that’s about 0.2%, a tiny number, also when multiplied with 1.85.
Next the argument is that x64 chips are better because they have less cache while before the Apple chips couldn’t compete because Intel had more. That doesn’t make sense. And how are you drawing conclusions on the design and performance of a chip that’s not even on the market yet anyway?
With 16MB of cache, that's nearly 1 billion transistors out of 16 billion -- and that's without including all the cache control circuitry.
Maybe I'm misunderstanding, but the 1.85x number does not apply to SRAM.
I've said for a long time that the x86 ISA has a bigger impact on chip design and performance (esp per watt) than Intel or AMD would like to admit. You'll not find an over-the-top fan here.
My point is that x86 can do more with less cache than aarch64. If you're interested, RISC-V with compact instructions enabled (100% of production implementations to my knowledge) is around 15% more dense than x86 and around 30-35% more dense than aarch64.
This cache usage matters because of all the downsides of needing larger cache and because cache density is scaling at a fraction of normal transistors.
Anandtech puts A14 between Intel and AMD for int performance and less than both in float performance. The fact that Intel and AMD fare so well while Apple has over 6x the cache means they're doing something very fancy and efficient to make up the difference (though I'd still hypothesize that if Apple did similar optimizations, it would still wind up being more efficient due to using a better ISA).
I’m sure you are well versed in this matter, definitely better than I am. You don’t do a great job of explaining though, the story is all over the place.
That's 16GB of DRAM. Caches are SRAM, which has a very different set of design tradeoffs. SRAM cells use more transistors so they can't be packed as tightly as DRAM.
The Ryzen 9 is a 16 (32 hyperthreads) core CPU, the A14 is a 2 big / 4 little core CPU. Power draw on an integer workload per thread seems roughly equivalent.
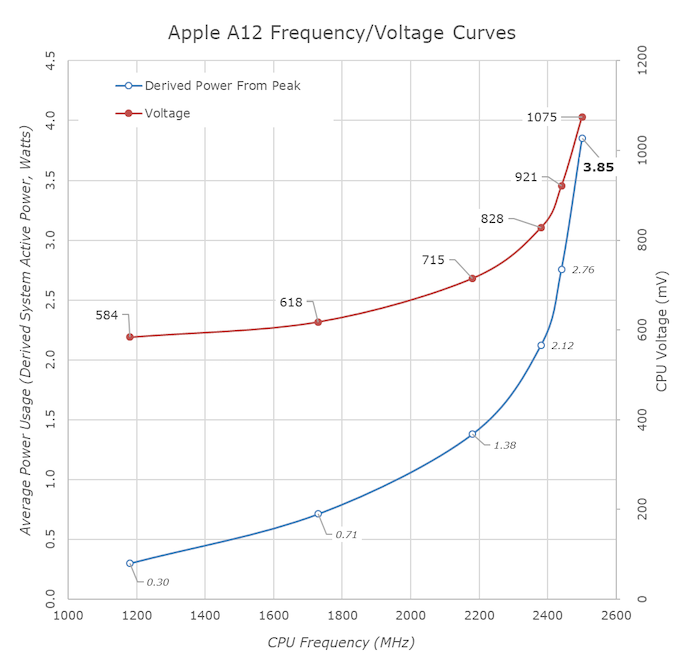
Last time I checked the TDP/frequency curve of Apple's chips was unimpressive [0]. If you crank it up to 4Ghz it's going to be as "bad" or even worse than a Ryzen CPU in terms of power consumption per core. There is no free lunch. Mobile chips simply run at a lower frequency and ARM SoCs usually have heterogenous cores.
>but this is an architecture that the PC market needs to be scared of.
This just means you know nothing about processor performance or benchmarks. If it was that easy to increase performance by a factor of 3x why hasn't AMD done so? Why did they only manage a 20% increase in IPC instead of your predicted 200%?
Isn’t this a RISC vs CISC thing though? AMD and Intel use a lot of complicated stuff to emulate the x86 instructions with a VM running on a RISC core. Apple controls hardware and software including LLVM so they compile efficient RISC code right from the get go. It’s their vertical integration thing again.
You got a point in the optimization part, it's difficult to compare both chips when you're running on completely different OSs, specially when one of them ruins a specially optimized OS like ios
The closest it could get I think would be running a variant of Unix optimized for the Ryzen.
I don't know much about this stuff but if all this is true then I don't see what's holding AMD / Intel back. Can't they just reverse-engineer whatever magic Apple comes up with, and that will lead to similar leaps in performance?
This wording is very hand-wavey. They can and should give a direct comparison; as consumers we don't know what the top 2% of sold laptops are, or which is the "best selling PC laptop in its class". Notice it's "best selling" and not most powerful.
> "faster than 98% of PC laptops sold in the last year"
Keep in mind that the $3k MBP is probably part of the 2% in the above quote. The large majority of laptops sold are ~$1k, and not the super high end machines.
Yeah, I just thought about all those 499/599 Euro (factory-new) laptops that are being sold in Germany. They are okayish but nothing I'd like to compare great systems against.
Really good observations - I suspect that the 16" MBPs may be in the 2% though.
Plus, given use of Rosetta 2 they probably need 2x or more improvement over existing models to be viable for existing x86 software. Interesting to speculate what the M chip in the 16" will look like - convert efficency cores to performance cores?
My guess is that they'd still keep the efficiency cores around, but provide more performance cores. So likely a 12 or 16 core processor, with 4 or 6 of those dedicated to efficiency cores.
The M1 supposedly has a 10w TDP (at least in the MBA; it may be speced higher in the MBP13). If that's the case, there's a ton of power envelope headroom to scale to more cores, given the i9 9980HK in the current MBP16 is speced at 45 watts.
I'm very scared of this architecture once it gets up to Mac Pro levels of power envelope. If it doesn't scale, then it doesn't scale, but assuming it does this is so far beyond Xeon/Zen 3 performance it'd be unfair to even compare them.
This is the effect of focusing first on efficiency, not raw power. Intel and AMD never did this; its why they lost horribly in mobile. Their bread and butter is desktops and servers, where it doesn't matter. But, long term, it does; higher efficiency means you can pack more transistors into the same die without melting them. And its far easier to scale a 10 watt chip up to use 50 watts than it is to do the opposite.
>This is the effect of focusing first on efficiency, not raw power. Intel and AMD never did this; its why they lost horribly in mobile.
If you want a more efficient processor you can just reduce the frequency. You can't do that in the other direction. If your processor wasn't designed for 4Ghz+ then you can't clock it that high, so the real challenge is making the highest clocked CPU. AMD and Intel care a lot about efficiency and they use efficiency improvements to increase clock speeds and add more cores just like everyone else. What you are talking about is like semiconductor 101. It's so obvious nobody has to talk about it. If you think this is a competitive edge then you should read up more about this industry.
>Their bread and butter is desktops and servers, where it doesn't matter.
Efficiency matters a lot in the server and desktop market. Higher efficiency means more cores and a higher frequency.
>But, long term, it does; higher efficiency means you can pack more transistors into the same die without melting them.
No shit? Semiconductor 101??
>And its far easier to scale a 10 watt chip up to use 50 watts than it is to do the opposite.
You mean... like those 64 core EPYC server processors that AMD has been producing for years...? Aren't you lacking a little in imagination?
Have no considered being less snarky as you careen your way through that comment without really understanding any of it? The efficiency cores on Apple’s processors perform tasks that the main, more power hungry processors aren’t necessary for, which a profoundly different situation from a typical server that is plugged in and typically run with capacity all the time. Honestly, besides being against the rules, the swipes you make against the commenter “not knowing about the industry” are just shocking to see considering how much you missed the point that was being made.
Without actual real world performance tests from neutral 3rd parties all that really really need to be taken with a grain of salt. Never trust the maker of a product, test for yourself or watch for neutral reviewing parties who don't have a financial incentive.
{kind=link}
They said the Macbook Air (specifically) is "3x faster than the best selling PC laptop in its class" and that its "faster than 98% of PC laptops sold in the last year".
There was no "in its class" designation on the 98% figure. If they're taken at their word, its among every PC laptop sold in the past year, period.
Frankly, given what we saw today, and the leaked A14x benchmarks a few days ago (which may be this M1 chip or a different, lower power chip for the upcoming iPad Pro, either way); there is almost no chance that the 16" MBPs still being sold with Intel chips will be able to match the 13". They probably could have released a 16" model today with the M1 and it would still be an upgrade. But, they're probably holding back and waiting for a better graphics solution in an upcoming M1x-like chip.