Genuine question: do you think that writing your own editor was a better investment than extensively customizing an existing editor like Vim or Emacs (even going so far as to change the keybinds and UI)?
I guess I'll never know for sure. I believe it has been worth it for me, as there are several things I can do now that I'm not sure whether I'd have been able to achieve by customizing them (unless you include "rewriting their source code extensively" as customizing them; but at that point I think I'd be roughly doing the same as what I did?).
I'll give three examples:
1. Being able to run
edge -view=all src/*.cc
This loads all those files, splits the screen, showing all matching files (up to a minimum area for each, with "Additional files: 498" (not shown) at the bottom), and lets me modify all files simultaneously (e.g., "search for a given regexp, make all cursors active, advance 5 words, delete to end of line, save all files, quit).
I just recorded an example of that (where I'm just renaming "OpenBuffer" to "Buffer"; you can trivially do that with Perl, but obviously you could do much more than just a simple regexp replace): https://asciinema.org/a/XNbNGL38kOrok2HO7zrarrQad
These are things that even heavy Emacs/Vim users would typically do through sed/awk/perl; I see that as a limitation in their editors (since you wouldn't use the same sed/awk/perl technique if you're just going to edit a single file).
2. I've supported multiple cursors (within one buffer) natively for a while (and I use it very often; for example, searching for a regular expression just leaves a cursor in each occurrence).
I guess I'd have been able to accomplish things like this, but I'm not sure of the quality of the results. In other words, I feel that it would have to rely on putting a lot of complexity in extensions and I'd guess that it would be too brittle and difficult to maintain. There are probably extensions for these things for Vim and Emacs, but I would be slightly worried that they may not integrate very well with other features and may brittle. But I don't really know.
3. I also got fed up that these editors would block on most operations (such as when you typed ":make" in Vim or when you opened a file from a networked file system); my editor never stops responding to user commands (rather, it simply visually indicates that it is executing something; perhaps you'll see side-effects as they occur). For example, here is how "make" works (you'll see me switching back and forth; most of the time you'll see the dots next to "make" (at the bottom line) moving, reflecting make's progress; in case it helps understand what's going on, I save the file, which causes "make" to be killed and restarted): https://asciinema.org/a/es4O4UdxPzB0vl7Tr88TKlq9N
I bet you can make Vim/Emacs operate this way (compile asynchronously, overlay errors with the files (as you can see around second 0:31); be able to nest commands with a pts within them, so that you can use them as you'd use tmux/screen). I'm not sure you make them load/save files asynchronously, never blocking?
Those are the examples.
When I started I was a heavy Vim user, but I got fed up of having to edit vim syntax, which I considered a, hmm, suboptimal programming language (yes, I'm aware that there are bindings for nearly every language under the sun, but still). I considered Lisp slightly preferable (and at the time I was still somewhat enamored with Scheme; I had been contributing some ~important modules to the Chicken Scheme implementation; these days I'll go to great lengths to avoid coding in languages that make static typing difficult, mostly because I don't think I'm smart enough to use them successfully for large/complex enough projects), but I was more into Vim than into Emacs. But I felt like it ought to be possible to do better than either. I felt that they suffered from carrying a lot of assumptions that were valid in the 90s (or earlier, perhaps 70s) but no longer applied, so I wanted to see how far one could go and experiment.
For example, as the user is typing, between each keystroke, something like ... hundreds of milliseconds pass. That's an incredibly long time for a computer! However, these editors mostly just sit idly, waiting for the next keystroke, not doing anything. My philosophy is completely different: burn as much CPU as you want, as long as you can give me something useful in return (and as long as you never stop responding). In other words, do whatever you can to maximize the value for the user.
You can see an example of the type of things I mean in the prompts in the above recordings:
- In the 1st recording (https://asciinema.org/a/XNbNGL38kOrok2HO7zrarrQad), around second 0:16, where I start typing a search regexp. As I type, the editor tells me things like "this would match 394 positions; in 32 buffers; and there's 2 search patterns in the search history that this matches".
- In the 2nd recording (https://asciinema.org/a/es4O4UdxPzB0vl7Tr88TKlq9N) around second 0:12, where I start typing a path (of a file to open). The editor scans the filesystem (asynchronously, obviously) and history log and tells me something like "you've typed `buffer_` so far; this matches 17 files (in all registered search paths) and 8 entries in this prompt's history".
(The key point is that all this functionality is asynchronous so it never blocks the user. If you type the next character as it is still scanning something, it just throws away those partial results (I'm somewhat simplifying; it's a bit smarter than that).)
You can probably achieve these things with extensions for Emacs/Vim, but I'd guess you'd still be somewhat limited by assumptions they make?
At the point where I'd be basically rewriting most of their source code ... I think it'd have been a significantly longer route (because I'd probably have had to care for a lot of additional things that are irrelevant to me).
Anyhow, to wrap up (sorry for the long rant!), this has been a great experience for me. I've learned a lot (e.g., I think I have more informed opinions about things like fuzz-testing, or the use of settable futures vs continuation-passing-style vs callback spaghetti) and I'm somewhat doubtful I would have been able to achieve so much through my own custom extensions for existing editors.
Those are some super cool screencasts, thank you for sharing! What are you showing on the right side gutter of your editor, visible at 20 seconds on https://asciinema.org/a/es4O4UdxPzB0vl7Tr88TKlq9N?
It looks like the function or loop scope? What are you using to generate/output that information? What languages does it work in? How hard is it to add support for new languages?
Aww, thank you for your reply, I'm very flattered. I usually get very skeptical/cynical comments when I mention to my coworkers and friends that I use my own text editor, so receiving comments like yours is very encouraging.
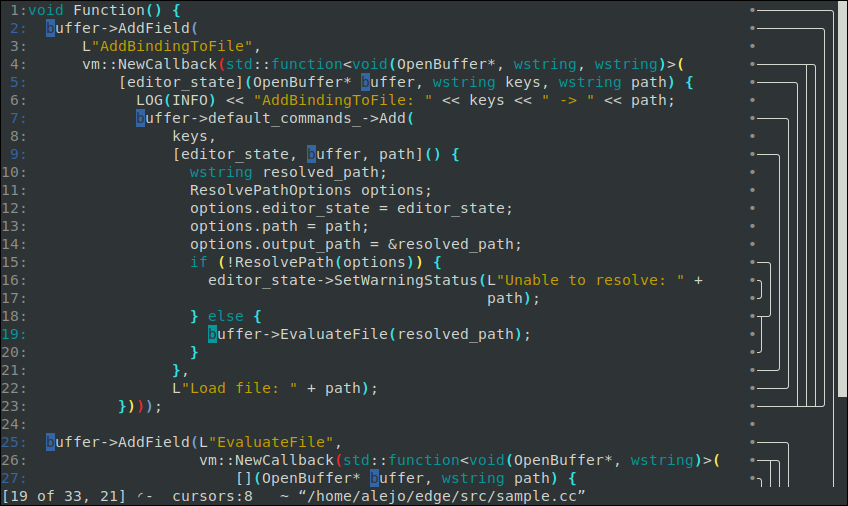
Yeah, what you see there corresponds to the syntax tree of the file being edited. You can see it fairly clearly in this screenshot (which has the advantage of showing how this really looks in an actual terminal, without some noise from asciinema): https://raw.githubusercontent.com/alefore/edge/master/screen...
In this screenshot, the very last column is just a scrollbar. Right next to it you see a representation of a subset of the syntax tree. It is a subset because I deliberately drop from it any subtrees that don't span more than a single line.
In the recording you also see something on the right of the scrollbar. The things shown on the left of the scrollbar correspond to the lines currently shown on the screen; the parts on the right are a representation of the tree for the entire file.
The syntax parsing is a bit dumb: just just based on things like parenthesis, comments, quotes, and brackets and such, not really aware of high semantic concepts (like classes or methods). For C++ (and other C like languages such as Java) this is implemented here: https://github.com/alefore/edge/blob/master/src/cpp_parse_tr... (if it seems too complex, part of it is because I cache previous states, as an optimization, since this runs every time you type a character into the file, refreshing the tree; I want this to work with very large source files, where most of the time you type a character the vast majority of the previous outputs can be reused).
I have two other parsers, for Markdown and diff (patches). It should be easy to add more parsers, but I want to clean up the API used by them.
Anyhow, you just have to generate a representation of the syntax tree (in this structure https://github.com/alefore/edge/blob/master/src/parse_tree.h). I've been considering integrating this with clang or vscode but haven't gotten around to it.
Once you have the ParseTree, the editor will display this information about the scopes (the logic that does that is a bit complex but lives here: https://github.com/alefore/edge/blob/master/src/buffer_metad..., function DrawTree, which returns a string with the characters for a given line).
I probably gave you more information than you wanted. :-P Thanks again for your comment.
{kind=link}