I'm continually impressed by the Keras team's API design decisions. They clearly understand that usability should be the focus, and even just the small snippet they post gets me excited about using the API. Compare this to CMLE's hyper-parameter tuning API: https://cloud.google.com/ml-engine/docs/tensorflow/using-hyp...
It's unclear though from the Readme how this tool works with distributed compute. I assume much of that would be abstracted away, and I'm not sure how you'd make it flexible enough to deal with all the various possible setups.
One other aside: I assume that the Keras team has basically decided that Tensorflow is the only first class citizen in their ecosystem?
You can't just abstract away the distributed part of it. As far as I can see, it can't be easily distributed with existing data parallel frameworks (Spark,Flink,Beam,Dataflow). My other issue is that you are modifying the base (Mnist) code - and you will need to rewrite it again when you want to do (distributed) training. My final issue is that hyperparameters are spread throughout the code. Yes, this is better than having an external YAML file (more notebook friendly), but it is inferior to centralizing them in a single object/dict in the code. See my comments below for details.
It's very easy - observe that each time the model is built it samples from the hyperparameters. So it's easy to have N workers all working in different hyperparameters. To coordinate the testing of hyperparameters, you use something like vizier, which is a service that the workers can call into to get their hyperparameter assignment.
If you have a distributed model you have to make sure all of your workers on a single variant get the same HPs. Again, vizier. (Hi, I'm job 25 worker 3, what are my HPs?)
With increasing dataset sizes and more compute/experimentation needed to get state-of-the-art results, hyperparameter tuning is becoming important.
However, I think it needs to be supported by a framework for distributed computing. We also think it is better to centralize all hyperparameters is an Optimizer object rather than have to (1) change existing code and (2) have hyperparameters spread out throughout the code (which would have to be rewritten again for distributed training).
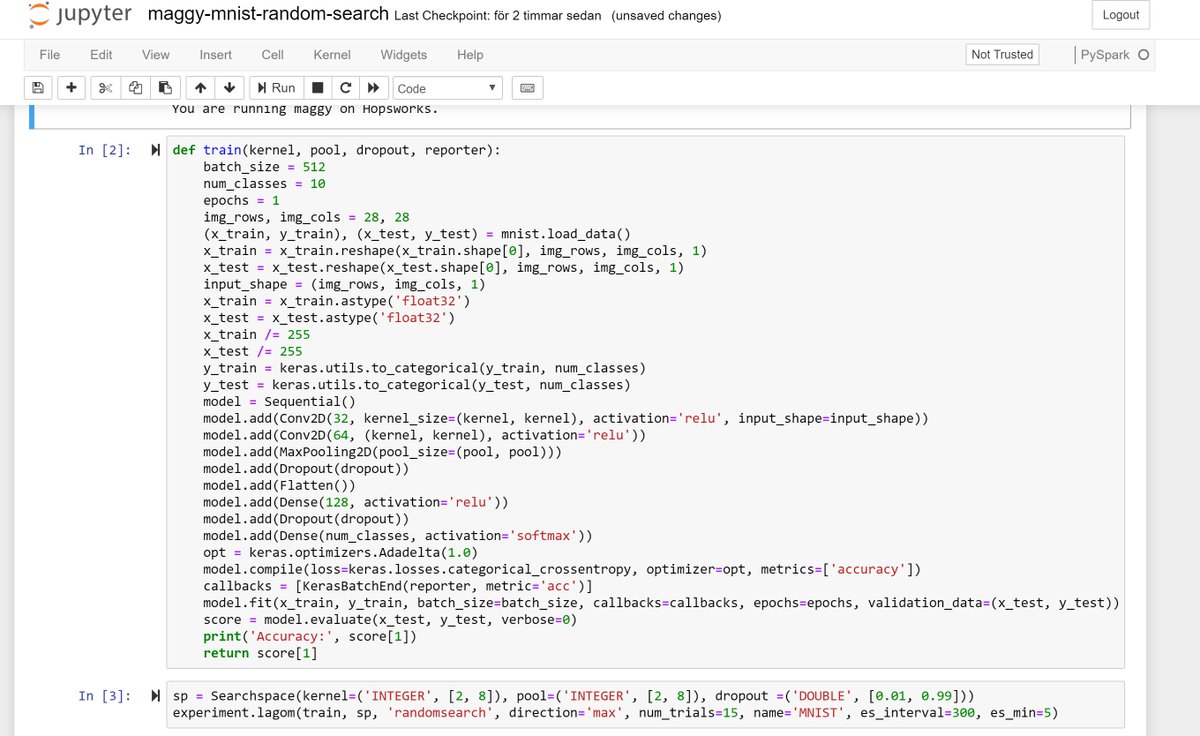
We did something similar to this, but it is data-parallel and is Python (built on top of PySpark) and supports a resource mgr with GPUs so that you can allocate GPUs to Spark executors. The main challenge we had was actually printing out logs live in the Jupyter notebook, while keeping the code Pythonic. Data Scientists do not like to leave their notebook to read logs - even if they know their are 10s of hundreds of parallel executors generating them.
Firstly, i never said it couldn't be distributed. You then ignored my (important) points about code needing to be changed (transparency broken) and hyperparameters distributed throughout the code base. And your criticism of the code linked above is suffice to say lacking in any detail.
So to summarize your reply: attack something i never claimed, then insult our work without any basis.
Super happy to see the keras team introduce official support for hyperparameter tuning. That should make it a lot easier to get off the ground for simple projects.
Currently ray.tune is by far the best available hyperparam tuning package period, and when it comes to scaleout. I bet we'll some integrations with keras soon
That looks great. It was not immediately clear to me how the parameters are tweaked. build_model has a hyper parameter tuning parameter hp that is modified but it would be good to add a paragraph explaining what values get tweaked.
{kind=link}
It's unclear though from the Readme how this tool works with distributed compute. I assume much of that would be abstracted away, and I'm not sure how you'd make it flexible enough to deal with all the various possible setups.
One other aside: I assume that the Keras team has basically decided that Tensorflow is the only first class citizen in their ecosystem?