As an approximation, we can estimate each face with an approximation to the binomial at looking at where the cut off is for rejections at p=0.05.
If you're looking at a single face,
With 2000 rolls, you would expect a range of 81-120. (0.0405- 0.0600)
At 3000 rolls, that "narrows"\* to 127-174 (0.0423 - 0.580)
At just 100 rolls, anywhere between 1 and 10 occurences looks fair.
However, it would be better to do a proper chi-squared test, this was just illustrative, so let's do that.
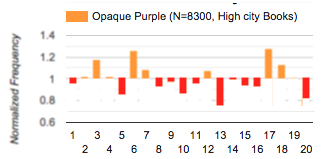
Let's take the chessex opaque purple, which looks like it has 8300 rolls.
By our approximations above, we expect to see rolls between 377 and 454.
In our actual data we appear to have a minimum of 313 with face13, and a maximum of 531 with face17.
So let's do a pearson's chi-squared test. Rolling 8300 times we expect 415 for each face.
We calculate for each observation, the difference between that and the expected value, and divide by the expected value, and then sum over all faces.
This gives a value of 155.3108 . We then have to compare this to the chi-squared test for 19 degrees of freedom. (There are 19 degrees of freedom because we have 20 faces, so after we have 19 results, the 20th must be fixed by being 8300 minus the sum of the first 19 faces).
Digging out our statistical tables (you DO have statistical tables right?), and lookup at 19 degrees of freedom, we can see 155 far exceeds even the p=0.01 level.
So we can conclude that the chessex opaque purple die rolled here is biased. (Or the die-roller is).
\* It narrows in proportion to the total, the absolute margin is wider. This is something that people often forget when dealing with the law of large numbers.
import random, statistics
num_of_sims = 10000
num_of_rolls = 3000
results = []
for s in range(num_of_sims):
sum_of_rolls = 0
# roll 20 sided dice
for r in range(num_of_rolls):
sum_of_rolls += random.randint(1,20)
# keep track of the average value
results.append(sum_of_rolls / num_of_rolls)
print("ave: ", statistics.mean(results)) # which is 10.49915
print("stdev: ", statistics.stdev(results)) # which is 0.10492
> (There are 19 degrees of freedom because we have 20 faces, so after we have 19 results, the 20th must be fixed by being 8300 minus the sum of the first 19 faces).
I've read the degrees of freedom in statistics explained so many times without actually understanding it. Now I get it. It's that simple. Thank you!
> So we can conclude that the chessex opaque purple die rolled here is biased. (Or the die-roller is).
We could use conditional probabilities to determine if the die is biased or if the roller is biased, I think: see if P(face is 19 | face was n before roll) = P(face is 19) by statistical hypothesis testing. Not that the data we have tells whether or not.
I have worked, about 15 years ago, on a contract for a company that amongst other things produced automated roulette tables.
They had a large hall packed with those that would constantly spin up, drop the ball and record results. There was mathematician employed to check series for any statistical anomalies. I had few chats with the guy, I was quite impressed the level of detail and care to make sure the wheels are perfectly symmetrical and fair.
Most of the cost of the machine goes into making the wheel symmetrical. I remember something like 20 or 30 thousand dollars spent on the single piece of metal that becomes the wheel.
Until that 5% edge turns out to be a 7% edge (thanks to the bias) and the relevant regulators come down on you like a ton of bricks for cheating your players.
Any fixed predictability can only decrease the house edge. The players make the bets, not the house. Obviously if you could vary the predictability you could cheat people by selectively avoiding payouts for large bets, but that's separate.
Yes, from what I understand, the casino edge is required to be extremely precise. Returning too much money to gamblers is penalized just as harshly as returning too little.
This is why casinos like you to gamble more, regardless of what form, because their edge is fixed by regulators. Only by increasing volume can they increase returns.
The mechanical rolling and computer vision is impressive, but wish he had noted if the results were statistically significant. Just a final touch to the article. At 100-150 rolls per face, my gut is saying no. I guess I'm going to have to whip up a couple loops in python after work to satisfy my curiosity.
You can't assign significance to a sample size alone.
A sample size of 10 can be significant (if it were 10 1's for example), and a sample size of 100,000 can be not significant, for example if you were to roll 4,953 1's.
One of the dangers, especially with statistical tests of uniformity, is that they often over detect departures from uniformity when using large samples.
Makes me wonder the extent to which the rolling surface would affect the outcome. A harder surface would cause more bouncing. Would more bouncing increase or decrease the relative fairness?
One common test of a die's fairness is floating it in salt-water, which allows any irregularity in the weight distribution to show itself. From that, intuitively I would assume that zero resistance (as much bouncing as possible/needed) would result in the unfairness making itself most apparent. Meanwhile, zero bouncing would cause the die to stick where it lands, making any unfairness the result of how it was thrown, and it's easier to cause a lot of randomness in that regard.
That said, I'm not sure that's generalizable to more realistic amounts of bouncing ("only a bit of bouncing" as opposed to "none at all", and "kinda a lot of bouncing" as opposed to "effectively zero resistance").
I've never actually heard of the salt water test. It makes sense thinking about it. I got a bag of dice from my dad, from his d&d days, from when he was younger than me. There's a huge mix of some really weird dice in there. They're fairly worn, some of the numbers aren't visible any more, and their original quality ranges wildly. I wouldn't mind dropping them all in a bucket of salt water to see now. I've drawn my own conclusions about them over the years of using them, it'd be interesting to see how well they match up.
Also, i wonder how my dad's homemade d20, made out of a double d10(d20 with 0-9 twice, 0's used as 10 and 20) with half the numbers coloured red(11-20 is red), with a pen, would rank up, it was likely just done randomly.
If you're going to do the salt water test, only use a glass of water, not a bucket. It takes quite a bit of salt to make the density of the salt water higher than most dice.
As far as I know continued bouncing would give the d20 more time to find its center, so it would be less random. That's pretty much the whole idea behind Gamescience dice. They aren't tumbled, so the edges are sharp and sometimes there's exposed mold flashing, but they stop rolling faster, meaning they're less likely to find their center
I don't know, but I used to play boardgames with a guy who would always try to do that. He'd hold the dice in his fingers so they couldn't move and would shake his hand, but the dice wouldn't change position. Then he'd just kind of drop them so they might not roll. He was successful sometimes in that it would give him a good outcome, but also there were like 4 other people around the table watching this, so we'd make him roll for real if the dice didn't move.
For the graphs showing "normalised frequencies", I'd drop the "based at zero" bars and draw them from 1 instead. You'd lose a lot of orange ink that's distracting and show the deviation much more clearly.
This reminds me of an old post with a dice rolling machine for a gaming site capable of producing 1.3 million dice rolls per day,
http://gamesbyemail.com/News/DiceOMatic
> Currently, GamesByEmail.com uses some 80,000+ die rolls for play in games like Backgammon, Gambit (a RISK clone), W.W.II (an Axis & Allies clone) and others. To generate the die rolls, I have used Math.random, Random.org and other sources, but have always received numerous complaints that the dice are not random enough.
That's a super cool machine, but the justification seems a bit silly. The randomization library in any programming language should be good enough for casual games, and random.org uses atmospheric noise which is almost certainly more random than dice: https://www.random.org/history/
I would love to see this experiment done with the d20 from The Dice Lab. They make their d20 dice with "ideally-balanced vertex sums while retaining the opposite-side numbering convention". They explain why this makes for a bit fairer dice here. https://mathartfun.com/thedicelab.com/BalancedStdPoly.html
> They explain why this makes for a bit fairer dice here.
Well... they explain why the opposite-side numbering convention makes for fairer dice. They don't say anything at all about balanced vertex sums other than "we believe it's important".
Just compare the reasoning:
> If a die is unintentionally oblate (slightly flattened on opposing sides), the flatter regions are more likely to turn up when the die is tossed. If these two opposite numbers were 19 and 20 for example, then the die would on average roll high, since these two numbers would come up too often. Having the two numbers add to 21 avoids any such bias in the average number rolled. For this reason, the opposite-side numbering convention improves fairness.
vs
> Equally important in our opinion is balancing of the vertex sums.
This does not give me confidence that the vertex sums matter.
Interesting. I went to the most recent Prerelease event for Magic: the Gathering and my first opponent told me to not use the D20 that came with the kit and to use his individual D6s. He said they had known biases. Maybe he was on to something.
The D20s that come with Magic products are spindown dice, not normal D20s. The faces are ordered for ease of lifetracking and are _not_ optimized for random rolls.
Because the dice aren't evenly weighted, they have a strong bias. IIRC, Spindown D20s crit somewhere around 30% of the time.
More specifically, in the spindown each number is adjacent to its predecessor and successor. In a regular d20 the numbers are more spread out, and opposite faces add up to 21.
I get where you're coming from, but I honestly assume no malice. It's fairly common knowledge in tabletop circles that spindown dice will have an unbalanced distribution. They're definitely made to be used only as a counter.
Now, whether it matters if you use a weighted die to determine who goes first is a different story. If you're both using the same die, who cares?
The only time I used a D20 in magic was for keeping track of life totals. If you're rolling to see who starts, it doesn't really matter if it's biased if you use the same die.
I guess some cards use a dice roll, but that's pretty rare.
I'm a former competitive MtG player. My playgroup found that with a bit of practice and a specific technique, we could roll 17+ on any spindown dice almost every time (try rolling the die with it starting in your hand with the 20 facing upwards with a sideways motion). While technically you can use any method you choose to randomly determine the start of a game, these dice have been proven to not be "random" thus cannot be used in a tournament. It doesn't matter at all in casual play, but in a tournament, you're just giving your opponent a chance to play first for free.
First thing I can think of is that it may matter if the distribution isn’t linear, although not really sure how it would.
The second more straightforward one is that the spindown dice vary from set to set and even within the set sometimes. As such the weighting is likely going to vary a lot.
I have not, but that sounds like a great kinda thing that a dice company should post! My d&d players are _kinda_ dice obsessed. What is your company? My buddy and I run a small business making dice towers/trays on a laser.
Yea, it's something that we want to do at scale (rollers, dice) via machine vision so all the "well actually" people that pop out of the woodwork with edge cases can be addressed ahead of time.
Hahaha, not ready to dox myself yet but you can probably figure it out with a little digging.
Von Neumann's algorithm for simulating a fair coin from a coin which is arbitrarily biased (but with independent throws) has moral analogs for any number of faces. By using more state you can also extract more data per throw.
Pieter Wuille created a table based implementation for a d6: https://gist.github.com/sipa/1913cf8aae565ddad0d1de7f2e9f7f3... though it isn't terribly efficient -- extracting only 2.722 bits per 4 roles, instead of the 10.34 which is theoretically possible -- because the table becomes fairly large fairly fast. d20 would be even worse.
If your application wanted uniform d20 throws a table that converted independent but biased d20 throws into unbiased d20 throws would be possible (though like above it would be inefficient unless it were very big.)
Interesting that this confirms other findings that the gamescience dice must have the sprue-stub removed for fair rolling. This is intuitively true, but contrary to Gamescience's marketing.
Hi sctb, I’m given to understand that you’re one of the moderators here. I’ve tried to contact you twice in two weeks through email without a response, so I’m concerned that it’s hitting your spam folder. Is there a better way to contact you? I don’t feel good about inserting my comment in an unrelated post like this, but I’m unsure what else to do.
I wonder about auto-correlation and repeated sequences of runs. If it isn't totally random, then it is partly not random. What is the nature of the non-randomness?
Very nice work! I am not sure what method of analysis would be the most appropriate, but the sequence matrix deserves a closer look. You mention the possibility of one side being preferentially followed by another one, but you only investigate the simple case of the two sides being equal (preference for the diagonal). However, the correlation could be less obvious, such as one side being followed by its opposite, or by an adjacent one.
{kind=link}
If you're looking at a single face,
With 2000 rolls, you would expect a range of 81-120. (0.0405- 0.0600)
At 3000 rolls, that "narrows"\* to 127-174 (0.0423 - 0.580)
At just 100 rolls, anywhere between 1 and 10 occurences looks fair.
However, it would be better to do a proper chi-squared test, this was just illustrative, so let's do that.
Let's take the chessex opaque purple, which looks like it has 8300 rolls. By our approximations above, we expect to see rolls between 377 and 454.
In our actual data we appear to have a minimum of 313 with face13, and a maximum of 531 with face17.
So let's do a pearson's chi-squared test. Rolling 8300 times we expect 415 for each face.
We calculate for each observation, the difference between that and the expected value, and divide by the expected value, and then sum over all faces.
This gives a value of 155.3108 . We then have to compare this to the chi-squared test for 19 degrees of freedom. (There are 19 degrees of freedom because we have 20 faces, so after we have 19 results, the 20th must be fixed by being 8300 minus the sum of the first 19 faces).
Digging out our statistical tables (you DO have statistical tables right?), and lookup at 19 degrees of freedom, we can see 155 far exceeds even the p=0.01 level.
So we can conclude that the chessex opaque purple die rolled here is biased. (Or the die-roller is).
\* It narrows in proportion to the total, the absolute margin is wider. This is something that people often forget when dealing with the law of large numbers.