Dedicated hosting is much better bang for your buck, especially for bandwidth. If you do something like video streaming and have relatively predictable loads, I've found that you have to pay at least an order of magnitude more with public cloud compared to dedicated servers on OVH or Datapacket. Maxing out a 2gbps server on Datapacket would cost you just $320/month for 648 TB of outgoing bandwidth monthly, versus at least $6,480 just for the bandwidth on Amazon S3.
For venture-backed startups with an emphasis on growth or large scale enterprises, the convenience of the cloud may outweigh the cost premium. But for small to medium size organizations where server load doesn't fluctuate on a day-to-day basis, I haven't yet been convinced that the cloud offers a good enough value proposition.
It's not just bandwidth -- if you are not utilizing the various services of a cloud provider just use it as a glorified VPS (which many do) then it's really hard to beat dedicated providers like those you mentioned and then Incero or Dedispec -- Incero has an E3-1230, 16GB RAM, 2x 1TB HDD
2x 120GB SSD, 30TB transfer for $40, Dedispec has a E3-1230v2, 32GB RAM, 480GB SSD, 100TB transfer for $55. A real lot of websites would run just fine with servers like these. The major selling point of clouds of easy scaling often turns out not to be necessary with machines at these price points -- one machine is just enough.
Bandwidth on S3 costs something like 50x what I'm usually paying for bandwidth (Hetzner etc.) or 5x what you'll get from smaller cloud providers.
You can be successful on AWS, but you're leaving money on the table, and for relatively commodity services it's just a question of time before a competitor realise they can do the same with much better margins and lower prices elsewhere.
If your hosting is a small portion of your costs, that might not matter, so I have certainly run services on AWS too, and do in my current job as well, but it's a very expensive convenience. I've yet to come across any systems I know the internals off that couldn't cut hosting costs by moving off public cloud services.
The "commodity" distinction feel very significant here. Parent mentioned training videos, so probably very much not commodity. If you're selling something at $10/unit, it doesn't matter if your bandwidth costs are ¢0.05 or ¢2.5/unit. You're technically leaving money on the table, yes, but probably not enough to justify the added infrastructure complexity.
> but probably not enough to justify the added infrastructure complexity.
If you want to avoid infrastructure complexity, I'd go for dedicated hosting most of the time. Most of my past clients have ended up paying for more hours on operations for AWS setups than for dedicated. AWS and similar tends to force a lot of ceremony, some of which is good, but a lot of which is unnecessary on dedicated setups or on premises setups.
But yes, if your costs per unit are that low, I've typically told clients it largely depends on what they're most comfortable with. Some then pick AWS and it's a perfectly good choice.
What I'm seeing though, is that a lot of people pick AWS without first pricing out the options, and then later end up with expensive migrations to get off it.
Yes, of course. "Added complexity" was meant in the context of already having decided that the AWS ecosystem is valuable (parent mentioned running serverless, so presumably that is the case).
Some businesses don't have IT staff or technical individuals, so cloud ends up being this nebulous resource that just works. Dedicated server means you are comfortable setting up your own servers to some extent. I agree with the comments thus far, you just need to be one of the technical people to appreciate the difference between cloud vs dedicated.
If it's one thing cloud services does not do, it is "just work". Companies lacking IT staff is a bonanza for devops consultants.
The difference is minimal these days, but usually my experience is that people spend more on devops for AWS. If you want to spin up a dedicated host at e.g. Hetzner or OVH or Softlayer or wherever, it generally take no more or less effort or technical skills than spinning up an instance at AWS. Many of the hosting providers have API's, just like AWS, only they expose their bare metal instead of hypervisor interfaces.
You don't typically need to know any more about the hardware on those systems than you need to know about the virtualized hardware on AWS.
I don't have the numbers here, but I'm pretty sure the same idea applies for serverless. If you have a predictable load, you can always find a much cheaper alternative once you pass a certain threshold. The cloud is never about cost, it's about flexibility.
Predictable or flat/consistent? If my load is negligible in US weekends and outside of business hours, that's a factor of 2 or 3 you can theoretically save over baseline=peak with some "cloud on demand" service.
It's not an order of magnitude, but it's something. Probably not worth the effort, for most, though, and I have no idea if "dedicated box" services can approximate something similar.
If you have a small number of requests over a large period, serverless is cheaper (that includes an api that is idle most of the time and peaks at a very high rate occasionally).
But once you go live and start to grow, there is a point where the lambda cost equals the instance price. And with an instance, you can almost always do a lot more than that number. Again, that will work if your requests are predictable enough that you can see this number consistently over a large period, say, every week at least.
I’ve worked in a few different settings on large-scale scientific computing. For those applications:
- Not cost-efficient at large scale. When you expect and plan to run thousands of nodes at near 100% CPU and memory usage for years at a time, running a machine room can still be less expensive.
- Specialized hardware not available in public clouds, e.g., very low latency networks configured in an optimal topology.
- Lack of control over hardware upgrade schedule. E.g., a cloud probably won’t give you those shiny new GPUs as early as you can shove them in your own servers.
The balance is shifting in many of these areas, and there’s plenty of scientific computing that can use a public cloud now. But I still wouldn’t use it for problems that are both highly CPU-intensive and require low latency networks, especially if I have long-term workloads.
(Mostly academic) high performance computing (HPC) has clearly different needs from what typical cloud computing services can provide. The setup and operation costs of a medium size (~1k nodes, ~25k cores) university computing centre in Europe costs at the order of 1MEur per year, not even speaking about the large national centers with with 10-100k nodes and 100k to 1M cores. At these level of computing it is quite sensible to do it in-house, especially if the engineering challenges are welcome scientific research topics on their own (such as energy efficient HPC, research on distributed file systems or job queueing systems, usage of accelerator cards).
I've (unfortunately) run scientific computing applications on aws. The experience is awful.
1 - aws is very very very expensive for sustained load.
2 - aws offers highly variable performance characteristics, both cpu and networking. It's a best practice after creating a set of ec2 machines to immediately spend 10 minutes perf testing them and dropping slow ones, either cpu or network.
2a - machines in aws that didn't start slow may become slow, particularly for networking. What you really want for many applications is a dedicated rack with very high speed TOR switches. You do not get this in AWS.
3 - Designing ML applications for variable tradeoffs between cpu and network is extremely ugly. Detecting and dealing with network links that can suddenly become extremely slow is awful.
There's a trend for people to give up all of their information without the slightest regards for privacy or possible abuse. People do this with Facebook by allowing Facebook to, quite literally, track them throughout pretty much all aspects of life - communications, personal habits, photos, location, purchasing, et cetera.
On the business side, there's this trend to stick everything in to "the cloud" and just trust it's OK because everyone else is doing it.
It seems it's too much effort for people to imagine all the ways this could go wrong. Some of us, though, actually think and care and don't simply believe everything we're told.
What happens when we find out the true extent that our information is being used against us? For a majority of us, it'll be too late because chasing fads and trends and doing what everyone else is doing is too appealing, somehow.
For those of us who are too paranoid to just hand over data, you can't even say we're wrong any more - just look at what Edward Snowden taught us about the extent to which our own government has been flagrantly disregarding the law. Keep in mind that's barely scratching the surface.
Cloud migration specialist here. Biggest thing I see is the culture. Large shops will be 80% infrastructure and 20% developers. Infrastructure folks almost always will be fired after a successful cloud migration. Middle Managers want to keep a large staff and budget to justify themselves. CIOs often come up through the infrastructure career path and don’t trust firewalls if they aren’t made by Cisco or SANs that they can’t touch. (“So you’re telling me that their homemade switches are better than Cisco?”) I even had a CIO of a Fortune 1000 ask me what brand of fiber optic cables are in use in AWS. Overall it’s mostly shops putting their head in the sand hoping they can go another 2-3 Years in their cushy “Director of Infrastructure” jobs.
Most of my success comes not from selling to IT but the CFO or Board. Once they realize they can eliminate a dozen or so SAN Storage or networking engineers then the cloud doesn’t seem so expensive after all.
Conversely, I’ve seen executives fired out the door when the public cloud costs were much higher than on prem costs, and the savings didn’t materialize (either the execs had drank the cloud koolaid, or the business changed direction).
Edit: There is no silver bullet. Model your needs, make sure your model is accurate. You might still be wrong if your model doesn’t match reality due to unanticipated deviations.
This is the key. And worth pointing out that the moment you're set up to use cloud services for spikes, the cost of using dedicated services for your base load drops:
You can afford to let the servers handling your base load get much closer to capacity when you know you can scale up near instantly instead of having to provision new servers.
This is the biggest reason for me to run services that are prepared to run on public clouds, though it's very rare I've ever needed to make use of it - the kind of spikes that are severe enough and long lasting enough to be worth provisioning cloud instances for tends to be very rare for most people.
Hah. I think that's a pretty good example in other ways, too. Uber is losing money hand over fist- if you really want to be driven to work everyday, they are by far the cheapest way to get that done, presumably because they are willing to lose that money.
Uber is trying to pull the same trick AWS did. I mean, I don't know if AWS was bleeding money at first, but in 2008, they had pretty good prices. Hard to compete with. I tried. But the thing is, especially their bandwidth prices? to this day, they are "okay, if it's 2008" I mean, north of ten cents per gigabyte transfer is kind of a lot.
(even in 2008, their bandwidth prices weren't great. I mean, they weren't bad, but their bandwidth prices were never really a lot below what you could get elsewhere. Their compute prices, on the other hand, were really competitive, if you scored them against the same ram at another Xen based VPS provider.)
This is an absolutely standard hosted infrastructure play. The standard VPS business model is to break into the market with really low prices, get a lot of customers, and then sit on those prices for as long as you can, while your costs fall, making your margins grow. I mean, most companies eventually are forced to lower prices again, so you get this cycle of high growth/no margin and then growing margin/bleeding customers.
(Interestingly, of late, the velocity with which hardware prices fall has decreased pretty dramatically, making this model less viable, or at least making it take longer.)
Amazon took this business model to the next level, in the way that VPS companies could only dream about. People voluntarily lock themselves into services on amazon that aren't particularly standardized, that would be quite difficult to shift onto competitors. This is very good for the amazon bottom line.
Cost. Linode is cheaper than AWS if you are willing to do your own ops. Lack of vendor lock in. Yes, AWS provides load balancing. When you look at their offerings they hook you by offering thing their way. You can use AWS messaging or run Rabbit. Many people start to adopt AWS since they are deployed there rather than thinking about doing things on their own.
+1 to vendor lock-in. Being an AWS shop can start feeling like being a Windows shop in the 90s... it can creep up on you. You mostly have an open source app and slowly start acruing bits of AWS only functionality. A bit of SQS here... S3 here... Lambda there.
Before you know it your giant app is stuck on proprietary infra and core business functionality involves paying a significant tax to keep things operational.
I’m a big fan of hosted open source for this reason. But those hosts too have incentives to sell you proprietary “value add” functionality.
Price. It's SIGNIFICANTLY cheaper for me to run high bandwidth/CPU applications on dedicated hardware from ex. OVH. I end up only spending a few hundred a month on hosting vs. thousands or tens of thousands. Tools like Rancher / Saltstack / etc. work just fine for me without being in The Cloud(tm) too, so nothing is pushing me to switch.
Dedicated servers are now as easy to manage as cloud vms because good dashboards + management tooling have become cloud agnostic. I use Kubernetes + Rancher to manage a cluster of dedicated servers and it's a fraction of the cost as a public cloud.
Business continuity: Providing a good SLA isn't in the AWS business model, which allows for widespread, lengthy outages. They have a so-so SLA and if they miss you get AWS credits, big whoop. They make their money on people who are insensitive to high cost, middling performance and reliability. Not sure about the other providers. At a certain point it's cheaper and easier to do it yourself than to support a hybrid cloud approach that can survive those events. Financial services businesses can afford the higher quality.
Sure, but is there some structural reason AWS can’t have an offering tailored to requirements like yours, or have they simply not bothered to start one yet?
Some of these they have "solved", but their solutions have not been tested or audited yet, or at least not in a way that's visible. There are a few big financial players going all-in now, and I think everyone else is watching and waiting and letting them take the risk. A lot of these regulations were written assuming on-premise control and there's a lot of fuzzy area and issues with interpretation. Sometimes there's a lot more than technology in play.
They are and they have, but they certainly haven't solved all of them for everybody and probably never will. But if you look at their offerings, there's a bunch of stuff there aimed at various specialized uses.
Ignoring cost, security, etc, the biggest issue with a cloud platform is that if you need a feature (custom networking arrangement, custom hardware, custom kernel, custom software) and the provider haven't implemented it yet, you're dead in the water. Dedicated, colocated, and virtual private servers are harder to set up, but being able to treat them as normal computers saves you in the long run.
I suspect there's still a lot of FUD regarding public cloud as well as on-prem admins and engineers actively pushing back for fear of losing their jobs. (I've seen this in action)
There certainly are legitimate reasons not to move to public cloud, but it shouldn't be an emotional one.
Measure cost (including manpower), SLA's, performance, governance, and compliance. After that it should be simple to stay on-prem, go hybrid, or move full force into public cloud.
I think a more complex problem is that many companies have legacy web applications that probably should be rebuilt cloud-native/serverless. Doing a lift and shift can be cost-effective, but decomposing these applications and rebuilding them in serverless would probably provide significant savings.
I see more FUD the other way, about high devops costs etc. As someone who has spent years consulting both on on prem systems, dedicated hosting and AWS, I typically ended up billing more ops time to the AWS clients - they still have 90% of the same ops needs and then in addition they need to manage the AWS specific bits.
In terms of actual hosting costs, I've more than once been prepared to offer clients to move them off AWS and guarantee my fee will simply be a percentage of the savings - I've seen clients cut hosting cost between 50% and 90% on moving from AWS to dedicated hosting, and cut their devops costs at the same time.
For someone doing admin/devops who wants to maximize billable hours, recommending AWS would be better than recommending on-prem - it's all remote, no annoying travel etc., and you're likely to make more money, and at the same time you ironically gets less pressure from managers who have been told cloud will cut their costs.
> Doing a lift and shift can be cost-effective, but decomposing these applications and rebuilding them in serverless would probably provide significant savings.
Even if you rebuild them as "serverless" you'd probably end up saving far more by deploying said "serverless" apps on dedicated hosting providers for the base load.
as on-prem admins and engineers actively pushing back for fear of losing their jobs.
The funny thing is: those jobs already went years ago outsourced to “smart hands” in the DC. You still need people to plan and operate all this stuff. SAs who make the jump willingly have nothing to fear from cloud.
A lot of the folks in these roles have gotten lazy in legacy jobs. Lots of enterprise ops organizations are doing stuff with 10 people that could be done with 3.
I worked in IT for a large energy company as a developer. The market cap of said company is in the tens of billions.
We did use Office 365 because those people had our CIOs ear and gave various discounts to lock us into the MSFT stack, but in-house development was all deployed to our own hardware. Other platforms we ran as part of IT (databases, ERP, analytics) also all were inhouse.
The number one reason were not running all we could on AWS or Azure could be broken down as follows
1) we didn't have the technical knowledge to make the transition
2) the people who were interested in this at all were the younger kids out of college
3) the company is run by older white males who don't trust the younger kids (FTE) and certainly don't trust the IT contractors
4) there was massive resistance to change, even when our industry is bleeding because of low energy prices and little to no profitability
5) Fundamental misunderstanding or lack of understanding of how to secure out data in the cloud
6) business people saw IT as a barrier to innovation
7) IT was very risk averse and with business people not trusting them, it only reinforced their inability to progress
As for [5], we had numerous conversations with MSFT and AWS about trying to run their cloud on premise. We were convinced that we can protect our data better (even though it's not our company's vote competency) than companies like AWS, who are literally in this exact business.
Old culture and security concerns being in finance. Though that's breaking down. Once you adopt a product built on the cloud (SaaS offering), the first level of integration is nightmare from the corporate datacenter. Once it takes the toll, thats when you begin to see the mindset change.
It's been 2 years of grind and umpteen number of powerpoint but I see a sea change and hopefully soon....
We use OVH and Hetzner dedicated (2X providers, 5X data centers for redundancy). Our application is CPU bound and it's approximately 10X cheaper than AWS/MS/Google and 3-5X cheaper than Vultr and Digital Ocean. If you need a lot of CPU bare metal is vastly more cost effective. It's also a bit faster.
Bare metal is only a little more work to set up if you're using orchestration and provisioning tools. We use Chef and Consul/Nomad.
IMHO Amazon and the other big cloud providers are not a good deal if you only need compute, storage, and bandwidth and if you have any in-house IT expertise. They only make sense if you're taking full advantage of all their managed services e.g. S3, Redshift, managed SQL, lambda, etc. If you only need raw compute and bandwidth the smaller providers (DO, Vultr) and bare metal (OVH, Hetzner) are far better deals.
Are you managing the OVH and Hetzner hosts (provisioning) by hand, using general-purpose tools (Terraform etc.), or tools you've built custom against the providers' APIs?
Cloud is a utility and therefore needs to be used like a utility. What this means is you need to turn things off when they are not being used. Something like 50% of workloads in public cloud have 'the potential' to be turned off as they are non-production. The public cloud providers provided the easy button to spin things up but turning things off is more tricky. This is why we built www.parkmycloud.com Others have rolled their own scripts to achieve the same goal or use other methods to achieve the same goal albeit not as good as our solution ;)). Based on our analysis if you use Reserved Instances for Prod and schedule Non-Prod to be turned off when not being used, you will get a better overall ROI than on prem.
Academic lab in computational cognitive science / computational linguistics: we haven’t transitioned fully because of storage costs. ~$10 tb/month even for infrequent s3 storage is way too much when we have lots of 10+ tb datasets. Otherwise it’s great to be able to scale compute (scale the number of machines/ cores / GPUs as necessary) and to maintain different images for different projects (NVIDIA driver, cudnn, TensorFlow version). Open to solutions for the storage problem!
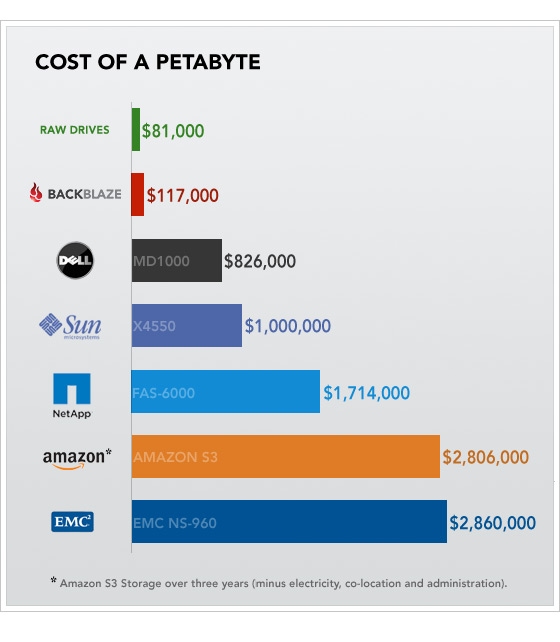
Storing on your own hardware will always be cheaper (Backblaze has a great blog post on explaining why they built out their own data storage nodes at rented colo space because of this).
You don't have to "design for it". The default storage class for S3 is your data is automstically copied across three data centers. You have to explicitly specify "reduced redundancy". Yes you pay for it, but you don't have to do anything special.
I purposefully didn't use Amazon's wording because it would be confusing to someone who doesn't know about AWS.
An "availability zone" is an isolated data center. A "region" is a group of availability zones that are geographically isolated but somewhat close to each other.
For instance, three availability zones (data centers) that are within 100 miles (making up a distance) would make up a region.
"Each region is completely independent. Each Availability Zone is isolated, but the Availability Zones in a region are connected through low-latency links".
Backblaze hosts everything in one non redundant data center.
Not a company, but I've found Nextcloud to be a better alternative to Dropbox, Google Drive, etc for personal use. I don't think Google even got around to putting out a Linux client. The straw that broke the camel's back with Dropbox was when I accidentally unzipped the MNIST dataset in a watched folder and the Dropbox sync client completely shit the bed. I couldn't even fix it through the web interface since their site is such a mess.
The expectation is that the system will run many years, so there is more long-term trust and control or own infrastructure. The same institution is still maintaining some old systems.
Some of smaller cheaper systems do run in cloud, but nothing more important or big yet. It takes time to gain trust.
At least for us there is a simple reason: We live in Iran and every major public cloud company would immediately blocks any Iranian account, without previous notice.
I've been saved a few times over the years by being able to "put hands" on the physical hard drives containing the data.
Example: a RAID1 setup, 2 drives. The drives used were literally made one after the other: the serial numbers were sequential. When 1 drive failed, the other drive failed too, at very nearly the same time.
Take drive out, mirror using ddrescue (took a long time) with retry, there was 32kb of data lost out of 400+GB and we never even really discovered what it was - we figure it was either a corrupt image or a part of the installed OS that was not used (such as a man page or text document).
{kind=link}
For venture-backed startups with an emphasis on growth or large scale enterprises, the convenience of the cloud may outweigh the cost premium. But for small to medium size organizations where server load doesn't fluctuate on a day-to-day basis, I haven't yet been convinced that the cloud offers a good enough value proposition.