We use a solution inspired by Jasper Snoek's Spearmint, which allows to somewhat parallelize bayesian search through a concept called "fantasies". If you've never read his paper I encourage you to find it on arxiv. The most gentle and thorough introduction to this topic that I've seen.
Unfortunately I have quite a backlog of other projects that I need to clear out, though Simple is AGPL so anyone is free to fork it. However I am also looking for employment opportunities.
Simple is already highly parallelizeable due to the fact that it relies on dynamic programming. Adding more threads of execution is just a matter of popping off another candidate test point from the priority queue while the objective function is already being evaluated at another point. I was planning to include this feature in a more mature release.
Any chance you could link the specific paper you’re talking about? This seems like a area I’d love to explore and the older you mentioned seems like a good starting point - I looked up the author on arxiv and there seems to be a few papers you could be referring to
This is the spearmint paper, describes how bayesian search algorithms can be parallelized in practice. There was also a very gentle introduction to bayesian optimization, I think it's one of the referenced papers. Cannot seem to find it right now.
I have a little problem understanding how to make a meaningful comparison. Your algorithm explore a simplex, whereas Bayesian optimization explore a cube. In terms of volume to explore when dimension grows, the cube is exponentially larger than the simplex with respect to dimension of space. Isn't the speedup due to that ?
If you take a simplex of length size d as starting simplex so that it contains the unit cube, does it still beat Bayesian Optimization ?
Or maybe map the simplex to the cube but it will distort things a lot.
What is a typical value for the dimension of the space where your algorithm should perform ?
You're right that it's tricky to make a direct comparison between different shaped optimization domains, however in the comparison animation each algorithm was given an optimization domain of equal area. For comparisons in higher dimensions it is up to the user to specify optimization domains with equal content.
Simple's runtime performance is not affected by the size of the optimization domain, however any global optimization algorithm will necessarily need to make more samples to chraracterize a higher dimensional space because these spaces inherently have more content to explore. Essentially the runtime performance of the algorithm and its sample-efficiency are two orthogonal concepts. Simple promises to be at least as sample-efficient as Bayesian Optimization while offering significantly lower computational overhead. Its main selling point isn't improved sample efficiency so much as better performance.
Does that answer your questions?
EDIT: Regarding the appropriate problem dimensionality, that will tend to depend quite a bit on the specific optimization problem. Simple is a global optimizer, so for extremely dimensional problems like training a deep neural net it would not be appropriate because the optimization domain would be too massive. The algorithm needs more testing, but as a rule of thumb I would say that anything under 500 dimensions is feasible.
I think you may underestimate the scaling of global optimization with dimension. You split each simplex into n+1 smaller ones in n dimensions, so even in 99 dimensions, the number of areas to consider grows as 100^k! After only a few subdivisions, the regions may be still pretty large, but suddenly you're dealing with thousands or millions of reasonable candidates. If your optimization problem is particularly easy, you might manage it, but in tricky cases it just cannot scale. This isn't a flaw in your algorithm - global optimization of non 'nice' functions in high dimensions is essentially impossible for the same reasons. Luckily, turns out that in a lot of cases you don't need a global maximum, only something good enough, so the NN folks aren't bothered.
The algorithm looks nice. However, the comparison to Bayesian optimization doesn't really hold as-is. The slowness of naive O(n^3) Bayesian optimization is well-known, and while I've never personally needed a faster solution, there's literature on eg. using approximate matrix inverse or special factorizations to speed up the process. You'll be hard pressed to find anyone actually suffering from the O(n^3) limitation.
That's a fair point about the time complexity, though the algorithm does at least demonstrate a real-world speedup of several orders of magnitude against fmfn's Bayesian Optimization implementation. However, I am not sure which performance optimizations he has implemented. Simple boils down to a handful of constant size matrix multiplies and a heap insertion at each iteration, so its performance is hard to beat.
Bayesian optimization is often applied on problems where the cost of function evaluation greatly exceeds the cost of any posterior updates etc. In this case sample efficiency is the real benchmark, and you should be looking at realistic problems with d>>2.
Generally speaking the heuristic for applying BO to optimization problems is that the objective function must take at least as long to evaluate as an iteration of BO. For an equally sample-efficient algorithm with negligible overhead, you can now take twice as many samples and find better optima for a large class of problems.
The shown examples are all 2D because plotting high dimensional space is rather difficult. Also, this is intended as an early proof of concept. A more formal description of the algorithm is coming, along with better examples.
Gaussian processes are only one implementation of Bayesian optimization- afaict, you have created another using a different prior which has nicer computational properties, mostly due to assuming the function has little global structure, a reasonable one for tricky optimization problems. I wonder how it would compare to a GP approximation using a space-partitioning data structure, only considering nearby points when calculating sample utility.
While it shares a lot of similarities with conventional Bayesian Optimization, I was reluctant to call it BO since it doesn't have a concept of explicit error bounds.
I noticed that the paper mentions constructing a triangulation of a set of initial sample points, which would allow for the optimization domain to be any convex polytope. Is this something you are planning to explore/incorporate?
EDIT: I see now that this is not an implemention of the algorithm in the paper, but its own algorithm entirely. Even so, it appears to me the same technique could be used in this case.
Yes, I hope to add that feature soon-ish. The reason I left it out of this first release is that computing Delaunay triangulations scales very poorly with dimensionality. That was why TRIOPT was restricted to low dimensional spaces. I will have to implement a more efficient way to compute nonoverlapping triangulations. In the mean time, you can simply make the optimization domain bigger to encapsulate the shape of your problem domain.
I'm currently away from my computer but I can produce a comparison animation in a few hours. While I am biased, I strongly suspect that Simple will have superior sample efficiency and at least similar performance.
Cool, I'd be really interested in seeing that and might try out myself later. It'd be really interesting to see a comparison of the two on optimization problems with a large number of dimensions which stock CMA-ES takes a while (and a lot of samples) to get "warmed up".
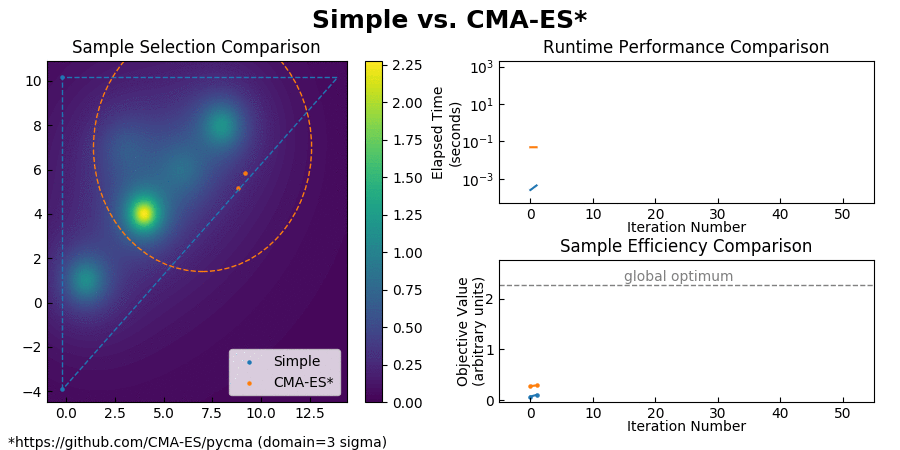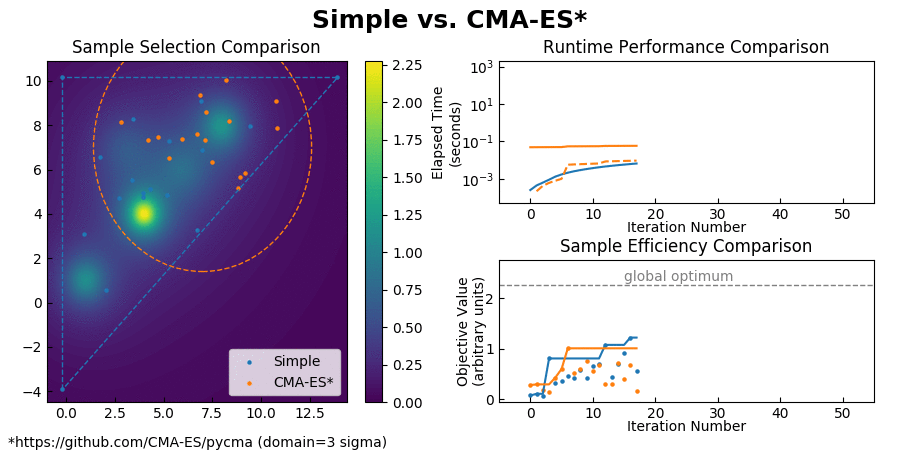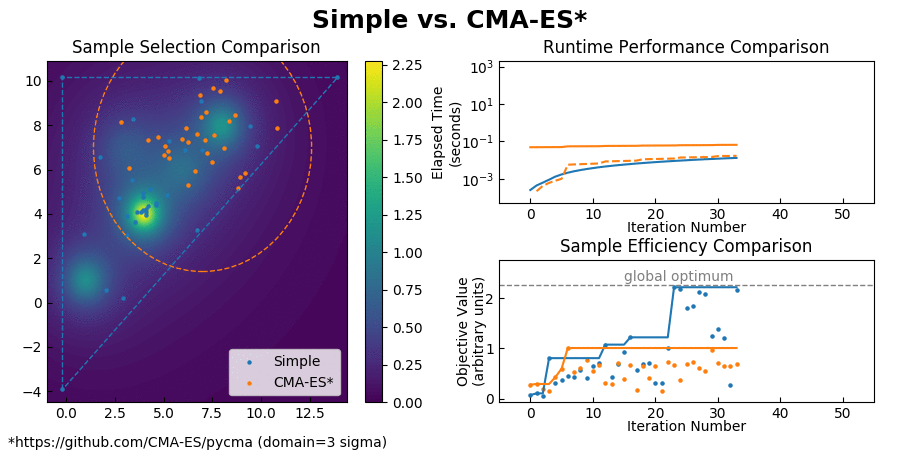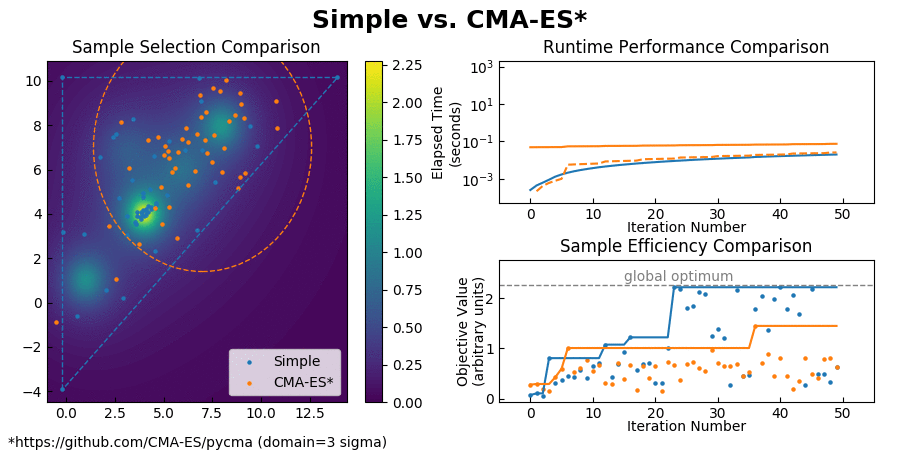
Simple is a constrained optimizer while CMA-ES is unconstrained, so I ended up choosing a sigma value such that the three sigma cutoff could be considered its faux "optimization domain." I gave the two algorithms equal areas to operate on, however CMA-ES is very sensitive to where it's initialized at. If I had started it near the global optimum it would have instantly converged without performing any optimization at all, so then there was also the issue of deciding on a "fair" starting location. Trying to get around this, I briefly tried the comparison on the Griewank function from -5:5, however CMA-ES showed nonconvergent behavior.
CMA-ES seemed to have a higher startup cost than Simple, but very similar per-iteration runtime performance. Sample efficiency ranged from totally nonconvergent to instant convergence without global search, depending on where it was started.
If you have any suggestions for a better testing methodology I would really appreciate them, because I'm still not quite satisfied with this comparison.
Thanks that's quite interesting. Your results of seeing higher startup costs definitely mirror my experience.
When I need constraints on CMA-ES for real world stuff I've been using a simple equation to map the output of the parameters before using them:
y = a + (b - a)*(1 - cos(pi * x / 10)) / 2
Where a is min, b is max and x is the unconstrained input value. (I saw some random paper recommending this years ago and have been using it ever since).
If I get a chance today I'll try and run your code and play around a bit. Really cool stuff!
Very loosely, but not particularly. Simple makes an effort to interpolate between points rather than using the Lipschitz constant to estimate an upper bound. This is important for regions of the search space which are "objective deserts." LIPO would continue to sample a large but poorly performing region of the search space even after it had been demonstrated to not contain good candidates, simply because its estimated upper bound varies linearly with distance from a sample. Simple combines a separate measure of how much it has already explored a region of space with the interpolated objective value to handle these cases better.
{kind=link}
We use a solution inspired by Jasper Snoek's Spearmint, which allows to somewhat parallelize bayesian search through a concept called "fantasies". If you've never read his paper I encourage you to find it on arxiv. The most gentle and thorough introduction to this topic that I've seen.