No its not, at least if we're talking L2 cache or faster.
Intel processors support two loads + one write per core. That can be 2x256-bit reads + 1x256-bit write. Each clock, every clock. At least to L1 and L2 (the only levels of cache which have that level of bandwidth).
AMD Ryzen supports 2x128-bit reads OR 1x128-bit write (1-read+1write is fine).
----------
The kicker is that you must use AVX2 registers to achieve this bandwidth. If you're loading / storing 64-bit registers like RAX, you can't get there.
A raw "copy" between locations (assuming they're entirely in L2 memory or faster) can be done by Skylake at 32b per cycle. The speed of this Base64 encoder however is "just" at 5bytes per cycle.
I'm curious how their code would perform on AMD's Ryzen platform, because of the lower-bandwidth of Ryzen. Ryzen's AVX is also split into 2x128-bit ports, instead of Intel's 2x256-bit ports. I'd expect AMD's Ryzen to do worse, but maybe there are other bottlenecks in the code????
> Intel processors support two loads + one write per core. That can be 2x256-bit reads + 1x256-bit write. Each clock, every clock. At least to L1 and L2...
You can approach 2 reads + 1 write in L1, but you won't get close for data in L2, especially when writes are involved. Writes dirty lines in the L1, which later need to be evicted, which eat up both L1 read-port and L2 write-port bandwidth.
You'll find that with pure writes to a data set that fits in L2 but not L1, you get only 1 cache line every 3 cycles, so nowhere close to 1 per cycle. If you add reads, things will slow down a bit more.
Even Intel documents their L2 bandwidth at only 32 bytes/cycle max, and 25 bytes per cycle sustained (on Broadwell - slightly better for Skylake client), and that's "one way" i.e., read-only loads. When you have writes and have to share with evictions it gets worse. So again nowhere close to the 96 bytes/cycle if you could do 2 32-byte reads and 1 32-byte store a cycle.
Some details are discussed here (although it's for Haswell, it mostly applies to everything up to but not including Skylake-X):
Which suggests L1 and L2 cache bandwidth was the same. But when I look at the sources you point out, it seems like your statements are correct. I think I'll trust your sources more, since they're benchmark-based... than a single graph (probably doing theoretical analysis). Thanks for the info.
To be fair, unless I missed it, that article is mostly just saying "The L1 and L2 are much faster than L3 and beyond". That's correct - but it doesn't imply that the L2 is somehow as fast as the L1 (if that were true, why have the distinction between L1 and L2 at all?).
Once you go to the L3, you suffer a large jump in latency (something like 12 cycles for L2 to ~40 cycles for L3 - and on some multi-socket configurations this gets worse) and you are now sharing the cache with all the other cores on the chip, so the advice to "Keep in L1 and L2" make a lot of sense.
Intel used to claim their L2 had 64 bytes per cycle bandwidth - and indeed there is probably a bus between the L1 and L2 capable of transferring 64 bytes per cycle in some direction: but you could never achieve that since unlike the core to L1 interface, which has a "simple" performance model, the L1<->L2 interface is complicated by the fact that you need to (a) accept evictions from L1, and (b) that the L1 itself doesn't have an unlimited number of ports to simultaneously accept incoming 64-byte lines from L2 and (c) everything is cache-line based.
The upshot is that even ignoring (c) you never get more than 32 bytes per cycle from L2 and usually less. Intel recently changed all the mentions of "64 bytes per cycle for L2" into "32 bytes max, ~2x bytes sustained" in their optimization manual in recognition of this.
Once you consider (c) you might get even way less bandwidth from L2: in L1, on modern Intel, your requests can be scattered around more or less randomly and you'll get the expected performance (there is some small penalty for splitting a cache line: it counts "double" against your read/write limits), but with L2 you will get worse performance with scattered reads and writes since every access is essentially amplified to a full cache line.
In which case, you may be surprised how fast RAM can be today.
A stick of 3200MHz DDR4 RAM has roughly 25.6 GB/s of bandwidth. You'll need to slightly overclock the memory controller to get there, but it wouldn't be insane. There are 4600MHz sticks of RAM btw (https://www.tweaktown.com/reviews/8432/corsair-vengeance-lpx...), so 3200MHz+ is kind of "typical" now, despite requiring the overclock.
The cheapest systems are dual channel, giving 51.2 GB/s of bandwidth to main-memory. Some higher-end workstations are quad-channel for 102.4 GB/s of bandwidth.
Your total RAM bandwidth per say... 4GHz clock is ~12.5 bytes/clock on dual-channel and ~25 bytes/clock on quad-channel.
Divide it further into 4-cores (on dual-channel case) and 8-cores (on quad-channel processors) we're looking at ~3-bytes main-memory bandwidth per clock per core.
A lot slower than L2 cache for sure, but not nearly as bad as it seems. So you're right, ~3 bytes per clock is still slower than the base64 implementation (which is 5-bytes per clock), but the bottleneck isn't nearly that bad. Especially if "other cores" aren't hitting the memory controller so hard.
You can't get close to 50 GB/s of bandwidth to a single core, even if your memory configuration and controller supports that because the per core bandwidth is limited by the latency per cache line and the maximum number of concurrent requests. There is a maximum of 10 outstanding requests that missed in L1 per core, so if you take a (very good) latency to DRAM of 50 ns, you can reach only 64 bytes/line * 10 lines outstanding / 50 ns = 12.8 GB/s.
In fact, you'll observe pretty much exactly that limit if you disable hardware prefetching. Of course, almost no one does that, and it turns out in particular that one can do better than this limit due to hardware L2 prefetching (but not software, since it restricted by the same 10 LFBs as above), since the concurrency from L2 to the uncore and beyond is higher than 10 (perhaps 16-20) and the latency is lower, so you get higher concurrency, but you are still concurrency limited to around 30 GB/s on modern Intel client cores.
On server cores, the latency is much higher, closer to 100ns, and so the per-core bandwidth is much lower, and the memory subsystem usually has a higher throughput, so it takes many more active server cores to saturate the memory bandwidth than on the client (which one just about does it on dual-channel systems).
But isn't the situation of base64 encoding a "streaming" situation? I agree with you that the 10-outstanding requests + latency metric is useful for a random-access situation. But base64 encoding (and decoding) starts at the beginning of something in memory, and keeps going till you reach the end.
Its about as ideal a streaming case as you can get it. No hash tables or anything involved. And WITH hardware prefetchers enabled, DDR4 becomes so much faster.
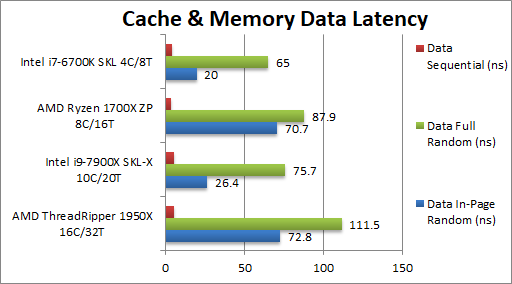
The measured "streaming" latency numbers seen in that picture are likely due to the hardware prefetcher. "Streaming" data from DDR4 is incredibly efficient! An order of magnitude more efficient than random-walks.
Intel's memory controller also seems to be optimized for DDR4 page-hits (a terminology that means the DDR4 stick only needs a CAS-command to fetch memory. Normally, DDR4 requires RAS+CAS or even PRE+RAS+CAS, which increases latency significantly). So if you can keep your data-walk inside of a DDR4 page, you can drop the latency from ~80ns to ~20ns on Skylake (but not Ryzen)
--------
With that being said, it seems like my previous post is a bit optimistic and doesn't take into account CAS commands and the like (which would eat up the theoretical bandwidth of DDR4 RAM). DDR4 3200MT/s RAM practically has a bandwidth of ~31GB/s on a dual-channel setup.
Still, I stand by the theory. If you "stream" beginning-to-end some set of data from DDR4 (WITH hardware prefetchers, that's the important part! Don't disable those), then you can achieve outstanding DDR4 bandwidth numbers.
Yes, it's a streaming situation - and that's my point: contrary to conventional wisdom, even the streaming situation - for a single core - is generally limited by concurrency and latency, and not by DRAM bandwidth, and there is just no way around it.
Now a streaming load, measured in cache line throughput, ends up about twice as fast as a random access load: because the latter is mostly limited by concurrency in the "superqueue" between L2 and DRAM, and the superqueue is larger (about 16-20 entries) and has a lower total latency than the full path from L1, while the former scenario is limited by the concurrency of the 10 LFBs between L1 and L2.
Prefetch isn't magic: it largely has to play by the same rules as "real" memory requests. In particular, it has to use the same limited queue entries that regular requests do: the only real "trick" is that when talking about L2 prefetchers (i.e., the ones that observe accesses to L2 and issue prefetches from there), they get to start their journey from the L2, which means they avoid the LFB bottleneck for demand requests (and software prefetches, and L1 hardware prefetches).
You don't have to take my word for it though: it's easy to test. First you can turn off prefetchers and observe that bandwidth numbers are almost exactly as predicted by the 10 LFBs. Then you can turn on prefetchers (one by one, if you want - so you see the L2 streamer is the only one that helps), and you'll see that the bandwidth is almost exactly as predicted based on 16-20 superqueue entries and a latency about 10 ns less than the full latency.
This is most obvious when you compare server and client parts. My laptop with a wimpy i7-6700HQ has a per-core bandwidth of about 30 GB/s, but a $10,000 Haswell/Broadwell/Skylake-X E5 server part, with 4 channels and faster DRAM will have a per-core bandwidth about half that, because it has a latency roughly 2x the client parts and it is _latency limited_ even for streaming loads! You find people confused about this all the time.
Of course, if you get enough cores streaming (usually about 4) you can still use all the bandwidth on the server parts and you'll become bandwidth limited.
There are other ways to see this in action, such as via NT stores, which get around the LFB limit because they don't occupy a fill buffer for the entire transaction, but instead only long enough to hand off to the superqueue.
This is a fabulous exchange. If you (or dragontamer) are interested in collaborating with Daniel (the blog author) on future academic papers where this level of architectural detail is relevant, I'm sure he'd appreciate hearing from you by email. Or contact me (email in profile) and I'll forward.
{kind=link}
Intel processors support two loads + one write per core. That can be 2x256-bit reads + 1x256-bit write. Each clock, every clock. At least to L1 and L2 (the only levels of cache which have that level of bandwidth).
AMD Ryzen supports 2x128-bit reads OR 1x128-bit write (1-read+1write is fine).
----------
The kicker is that you must use AVX2 registers to achieve this bandwidth. If you're loading / storing 64-bit registers like RAX, you can't get there.
A raw "copy" between locations (assuming they're entirely in L2 memory or faster) can be done by Skylake at 32b per cycle. The speed of this Base64 encoder however is "just" at 5bytes per cycle.
I'm curious how their code would perform on AMD's Ryzen platform, because of the lower-bandwidth of Ryzen. Ryzen's AVX is also split into 2x128-bit ports, instead of Intel's 2x256-bit ports. I'd expect AMD's Ryzen to do worse, but maybe there are other bottlenecks in the code????