The Unicode standard describes in Annex 29 [1] how to properly split strings into grapheme clusters. And here [2] is a JavaScript implementation. This is a solved problem.
This is most definitely not a solved problem, because graphemes (visual symbols) are a poor way to deal with unicode in the real world. Pretty much all systems either deal with the length in bytes (if they're old-style C), in code units / byte pairs (if they're UTF-16 based, like windows, java and javascript), or in unicode code points (if they're UTF-8 based, like every proper system should be). Dealing with the length in visual symbols is actually pretty much impossible in practice because databases won't let you define field lengths in graphemes.
The way things compose: bytes combine into code points (unicode numbers), and code points combine into graphemes (visual symbols). In UTF-16 for legacy compatibility reasons with UCS-2, code points decompose into code units (byte pairs), and high code points, which need a lot of bits to represent their number, need two code units (4 bytes) instead of one.
Java and JavaScript are UTF-16 based, so they measure length in code units and not code points. An emoji code point can be a low or high number depending on when it was added. Low numbers can be stored in two bytes, high numbers need four bytes. So an emoji can have length 1 or 2 in UTF-16. However, when moving to the database it will typically be stored in UTF-8, and the field length will be code points, not code units. So, that emoji will have a length of 1 regardless of whether it is low or high. You don't notice this as a problem because app-level field length checks will return a bigger number than what the database perceives, so no field length limits are exceeded.
There isn't any such thing as "characters" in code. In documentation when they say "characters" usually they mean bytes, code units or code points. Almost never do they mean graphemes, which is intuitively what people think they mean. The bottom line is two-fold: (A) always understand what is meant in documentation by "length in characters", because it almost never means the intuitive thing, and (B) don't try to use graphemes as your unit of length, it won't work in practice.
This is most definitely not a solved problem, because graphemes (visual symbols) are a poor way to deal with unicode in the real world.
What do you think how text editing controls work? You cursor moves one grapheme cluster at a time, selections start and end at grapheme cluster boundaries, and pressing backspace once deletes the last grapheme cluster even if it took you several key strokes to enter. Grapheme cluster are obviously useful and certainly not a poor way to deal with Unicode in the real world.
Sure, grapheme clusters are neither the most common way to talk about strings, nor are they the most useful one in all situations, but nobody claimed that. If you have to allocate storage, you of course use the size in bytes after encoding. If you translate between encodings, you may want to look at code points. The right tool for the job, and sometimes the right tool is grapheme clusters.
There isn't any such thing as "characters" in code.
Sure, there is. Actually characters exist only in code, they are not used in any field dealing with written language besides computing. A character is the smallest unit of text a computer system can address.
Backspace is typically not one grapheme at a time, though it is for emoji. For scripts such as Arabic, it typically deletes ḥarakāt when they are composed on top of a base character. For a bit more discussion of how I hope to handle this in xi-editor, as well as links to the logic in Android, see https://github.com/google/xi-editor/issues/159
clarification: It is for some emoji, e.g. backspace on a family emoji will eliminate family members one by one. (on most browsers and platforms afaict). But flag emoji will be deleted as a group. IIRC handling of multicodepoint profession emoji is inconsistent.
I would point you to Swift's implementation of its "Character" type. Swift string handling is a model for how programming languages should approach Unicode characters and their complex combinations. The standard interface into all Swift strings is its "Character" type, which works exclusively with grapheme clusters.
A "code unit" exists in UTF-8 and UTF-32; they are not unique to UTF-16.[1] UTF-8's relationship with code points is approximately the same as UTF-16's, except that UTF-8 systems tend to understand code points better because if they didn't, things break a lot sooner, whereas they mostly work in UTF-16.
Your entire argument that graphemes are a poor way to deal with unicode seems to be that current programming languages don't use graphemes, instead dealing in a mix of code units or points. But the article here shows a number of cases where that doesn't break down, and the person you're responding to clearly points out that, for the cases covered in the article, graphemes are the way to go (and he's correct).
Graphemes aren't always the correct method (and I don't think your parent was advocating that), just like code units or code points aren't always the right way to count. It's highly dependent on the problem at hand. The bigger issue is that programming languages make the default something that's often wrong, when they probably ought to force the programmer to choose, and so, most code ends up buggy. Worse, some languages, like JavaScript, provide no tooling within their standard library for some of the various common ways of needing to deal with Unicode, such as code points.
How would you implement graphemes compatibility if you can have unlimited number of code points combine into a grapheme? Designing an efficient storage solution for such text seems like a nightmare.
Any time you define an upper limit, someone will come up with more emojis that will require larger number of code points per grapheme.
> A "code unit" exists in UTF-8 and UTF-32; they are not unique to UTF-16.
Technically yes. But they are only "exposed" in UTF-16. In UTF-32 code points and code units are the same size, so you only have to deal with code points. In UTF-8 you only have to deal with code points and bytes. UTF-16 is unique in having something that is neither code point nor byte but sits in between.
That is certainly true if you only look at the word sizes at different layers. But any implementation will at least logically start with a sequence of bytes, then turn them into code units according to the encoding scheme, group code units into minimal well-formed code unit subsequences according to the encoding form, and finally turn them into code points.
While different layers may use words of the same size, there are still differences, for example what is valid and what is not. While for example U+00D800 is a perfectly fine code point, the first high-surrogate, 0x0000D800 is not a valid UTF-32 code unit. 0xC0 0xA0 is a perfectly fine pair of bytes, both are valid UTF-8 code units, and they could become the code point U+000020 if only 0xC0 0xA0 were not an invalid code unit subsequence.
So yes, while I agree that UTF-16 is special in that sense that one has to deal with 8, 16 and 32 bit words, I don't think that one should dismiss the concept of code units for all encoding forms but UTF-16. There enough subtle details between the different layers so that the distinction is warranted. And that is actually something I really like about the Unicode standard, it is really precise and doesn't mix up things that are superficially the same.
> But any implementation will at least logically start with a sequence of bytes, then turn them into code units according to the encoding scheme, group code units into minimal well-formed code unit subsequences according to the encoding form, and finally turn them into code points.
Not at all. I've never seen people using UTF-8 deal with a code unit stage. They parse directly from bytes to code points.
> While for example U+00D800 is a perfectly fine code point, the first high-surrogate, 0x0000D800 is not a valid UTF-32 code unit.
I thought that was an invalid code point. Where would I look to see the difference? Nevertheless I would expect most code to make no distinction between the invalidity of 0x0000D800 and 0x44444444, except perhaps to give a better error message.
> 0xC0 0xA0 is a perfectly fine pair of bytes, both are valid UTF-8 code units, and they could become the code point U+000020 if only 0xC0 0xA0 were not an invalid code unit subsequence.
If you say that they're correct code units then at what point do you distinguish bytes and code units? In practice almost nobody decodes UTF-8 with an understanding of code units, neither by that name nor any other name. They simply see bytes that correctly encode code points, and bytes that don't.
Especially if you say that C0 is a valid code unit despite it not appearing in any valid UTF-8 sequences.
> The encoding is variable-length and uses 8-bit code units.
By definition, code unit is a bit sequence of a fixed size which can form code points. In UTF-8 you form code points using 8-bit bytes, therefore in UTF-8 code unit is byte. In UTF-16 it is a sequence of two bytes. In UTF-32 it is a sequence of four bytes.
I said as much in my first comment, yes. I'm not sure if I'm missing something in your comment?
Code units may 'exist' on all three through the fiat of their definition, but they only have a visible function and require you to process an additional layer in UTF-16.
Surrogate codepoints are indeed valid codepoints. It's just that valid UTF-8 is not allowed to encode surrogate codepoints, so the space of codepoints supported by UTF-8 is actually a subset of all Unicode codepoints. This subset is known as the set of Unicode scalar values. ("All codepoints except for surrogates.")
Those points cannot be validly encoded in any format. I suppose you can argue that they are valid-but-unusable in an abstract sense, since the unicode standard does not actually label any code points as valid/invalid, but if you were going to label any code points as invalid then those would be in the group.
You are certainly correct that it is common to not pay too much attention to what things are called in the specification, especially if you want to create a fast implementation. Logically you will still go through all the layers even if you operate on only one physical representation.
My admittedly quite limited experience with Unicode is from trying to exploit implementation bugs. And with that focus it is quite natural to pay close attention to the different layers in the specification in order to see where optimized implementations might miss edge cases.
And I am generally a big fan of staying close to the word of standards, if it does not cause unacceptable performance issues, I would always prefer to stick with the terminology of the standard even if it means that there will be transformations that are just the identity.
The distinction between code points and scalar values will for example become relevant if you implement Unicode meta data. There you can query meta data about surrogate code points even if a parser should never produce those code points.
> There isn't any such thing as "characters" in code. In documentation when they say "characters" usually they mean bytes, code units or code points. Almost never do they mean graphemes, which is intuitively what people think they mean. The bottom line is two-fold: (A) always understand what is meant in documentation by "length in characters",
This is because languages usually have a built in char type.
> don't try to use graphemes as your unit of length, it won't work in practice.
Swift does this and it's a really good thing. Everything is in graphemes by default -- char segmentation, indexing, length, etc.
There are way too many problems caused by programmers interpreting "code point" as a segmentable unit of text and breaking so many other scripts, not to mention emoji.
Not … really. Yes, we "know" the solution, but the terrible APIs that compose so many language's standard string type goads the programmer into choosing the wrong method or type.
JavaScript has — to an extent — the excuse of age. But the language still really (to my knowledge) lacks an effective way to deal with text that doesn't involve dragging in third-party libraries. You are not a high-level language if your standard library struggles with Unicode. Even recent additions to the language, such as the recent inclusion of leftPad, ignore Unicode (and, in that particular example, render the function mostly useless).
What would you say Java is missing? Sure, it does have the "oops, we implemented Unicode when they said we only needed 16 bits problem" but unlike, say, JS, it actually handles astral plane characters well (e.g., the regex implementation actually says that . matches an astral plane code point rather than half of one).
It does have all the major Unicode annexes--normalization (java.text.Normalizer), grapheme clusters (java.text.BreakIterator), BIDI (java.text.Bidi), line breaking (java.text.BreakIterator), not to mention the Unicode script and character class tables (java.lang.Character). And, since Java 8, it does have a proper code point iterator over character sequences.
It does better than most, though Python 3 lacks grapheme support in the standard library, requiring developers to use a library like uniseg. I.e. it "lacks an effective way to deal with text that doesn't involve dragging in third-party libraries", and is thus evidently not a "high-level language".
That is what I meant, there is an existing algorithm to do this because the author tried to come up with one. That JavaScript fails to provide an implementation, well, too bad, but this is of course a problem one may have to solve in any language.
And while other languages provide the necessary support at the language or standard library level, I would guess there are quite a few developers out there that are not even aware that they are looking for enumerating grapheme clusters. But now some more know and if they made a good language choice, it is now a solved problem for them.
It's not a problem that comes up that often, to be fair. Many of the cases where you think you'd need to split a string like that, you have some library doing the work for you. One of the main purposes is to figure out where valid cursor locations are in text editors... but in JavaScript, you just put a text field in your web page and let the browser do the heavy lifting. Same with text rendering... hand it off to a library which does the right thing.
The last commit to this repo was on July 16, 2015, and the code says it conforms to the 8.0 standard. But Unicode 9.0 came out in June 2016. The document in your link [1] indicates that there were changes in the text-segmentation rules in the 9.0 release. However, I can't say whether any of these affect the correctness of the code.
The thing that frustrates me the most about Unicode emoji is the astounding number of combining characters. For combining characters in written languages, you can do an NFC normalization and, with moderate success, get a 1 codepoint = 1 grapheme mapping, but "Emoji 2.0" introduced some ridiculous emoji compositions with the ZWJ character.
To use the author's example:
woman - 1 codepoint
black woman - 2 codepoints, woman + dark Fitzpatrick modifier
It's like composing Mayan pictographs, except you have to include an invisible character in between each component.
Here's another fun one: country flags. Unicode has special characters 🇱 🇮 🇰 🇪 🇹 🇭 🇮 🇸 that you can combine into country codes to create a flag. 🇰+🇷 = 🇰🇷
edit: looks like HN strips emoji? Changed the emoji in the example into English words. They are all supposed to render as a single "character".
> The thing that frustrates me the most about Unicode emoji is the astounding number of combining characters. For combining characters in written languages, you can do an NFC normalization and, with moderate success, get a 1 codepoint = 1 grapheme mapping, but "Emoji 2.0" introduced some ridiculous emoji compositions with the ZWJ character.
No, no, no, NO.
Please stop spreading this bit of misinformation. Emoji has not changed this situation.
Hangul is one where NFC won't work well. Yes, we actually already encode all possible modern hangul syllable blocks in NFC form as well, but this ignores characters with double choseongs or double jungseongs that can be found in older text. Which you sometimes see in modern text, actually.
All Indic scripts (well, all scripts derived from Brahmi, so this includes many scripts from Southeast Asia as well like Thai) would have trouble doing the NFC thing.
I am annoyed that the unicode spec introduced more complexity into their algorithms to support Unicode, but this is because they could have achieved mostly the same task by not introducing emoji-specific complexity and reusing features that existing scripts already have and have already been accounted for.
That is why I said "with moderate success". It's not 100% reliable, but mostly good enough for basic cases. Twitter, for example, used to do an NFC normalization and count codepoints to enforce the 140 charcater limit, and this was close enough to or exactly right for enforcing 140 graphemes in probably 98% of text on Twitter. They can no longer do this because some new emoji can consume 7 codepoints for a single grapheme.
No, it's not, it's "mostly good enough for some scripts". This attitude just ends up making software that sucks for a subset of scripts.
Twitter is not a "basic case", it's a case where the length limit is arbitrary and the specifics don't matter much anymore. Usually when you want to segment text that is not the case.
Edit: basically, my problem with your original comment is that it helps spread the misinformation that a lot of these things are "just" emoji problems, so some folks tend to ignore them since they don't care about emoji that much, and real human languages suffer.
So, it was always wrong, but they didn't notice until the "exceptional" cases became common enough in their own use.
This, to me, is an argument for emoji being a good thing for string-handling code. The fact that they're common means that software creators are much more likely to notice when they've written bad string-handling code.
Whatever platform you're using should have an API call for counting grapheme clusters. It may be more complex behind the scenes, but as an ordinary programmer it should be no more difficult to do it correctly than it is to do it wrong.
Ironically, this cuts both ways. Existing folks who didn't care about this now care about it due to emoji. Yay. But this leads to a secondary effect where the idea that this is "just" an emoji issue is spread around, and people who would have cared about it if they knew it affected languages as well may decide to ignore it because it's "just" emoji. It pays to be clear in these situations. I'm happy that emoji exist so that programmers are finally getting bonked on the head for not doing unicode right. At the same time, I'm wary of the situation getting misinterpreted and just shifting into another local extremum of wrongness.
Another contributor to this is that programmers love to hate Unicode. It has its flaws, but in general folks attribute any trouble they have to "oh that's just unicode being broken" even though these are often fundamental issues with international text. This leads to folks ignoring things because it's "unicode's fault", even though it's not.
I actually prefer the ZWJ approach to just randomly combining multiple symbols into one, like with the country flags. With ZWJ you at least have a chance to reliably detect such a combined grapheme, as opposed to keeping long lists of special cases that might or might not be implemented by your OS / rendering engine / font.
The one that still surprises me is Hangul (Korean script). Hangul characters are made of 24 basic characters (jamo) which represent consonant and vowel sounds, which are composed into Hangul characters representing syllables.
Unicode has a block for Hangul jamo, but they aren't used in typical text. Instead, Hangul are presented using a massive 11K-codepoint block of every possible precomposed syllable. ¯\_(ツ)_/¯
I believe that was a necessary compromise to use Hangul on any software not authored by Koreans.
"These are characters from a country you've never been to. Each three-byte sequence (assuming UTF-8) corresponds to a square-shaped character." --> Easy for everyone to understand, and less chance of screwup (as long as the software supports any Unicode at all).
"These should be decomposed into sequences of two or three characters, each three bytes long, and then you need a special algorithm to combine them into a square block." --> This pretty much means the software must be developed with Korean users in mind (or someone must heroically go through every part of the code dealing with displaying text), otherwise we might as well assume that it's English-only.
Well, now the equation might be different, as more and more software are developed by global companies and there are more customers using scripts with complicated combining diacritics, but that wasn't the case when Hangul was added to Unicode.
For example: if NFD works properly, the first two characters below should look identical, and the third should show a "defective" character that looks like the first two except without the circle (ㅇ). It doesn't work in gvim (it fails to consider the second/third example as a single character), Chrome in Linux, or Firefox in Linux.
은 은 ᅟᅳᆫ
Of course, if it were the only method of encoding Korean, then the support would have been better, but it would've still required a lot of work by everyone.
The original version of Unicode was primarily intended to unify all existing character sets as opposed to designing a character database from fundamental writing script principles. That's why most of the Latin accented characters (e.g., à) come in precomposed form.
It is worth noting that precomposed Hangul syllables decompose to the Jamo characters under NFD (and vice versa for NFC). However, most data is sent and used with NFC normalization.
This is primarily because the legacy character set---KS X 1001---already contained tons (2,350 to be exact) of precomposed syllables. Unicode 1.0 and 1.1 had lots of syllables encoded in this way, with no good way to figure out the pattern, and in 2.0 the entire Hangul syllable block is reallocated to a single block of 11,172 correctly [1] ordered syllables.
So yeah, Unicode is not a problem here (the compatibility with existing character sets was essential for Unicode's success), it's a problem of legacy character sets :-)
[1] Only correct for South Koreans though :) but the pattern is now very regular and it's much more efficient than heavy table lookups.
I would imagine this is a legacy from the Good Old Days when every Asian locale had its own encoding. Unicode imported the Hangul block from ISO-2022-KR/Windows-949 (different encodings of the same charset), which has only Hangul syllables.
The ideographic description characters do provide a way to describe how to map radicals into characters, but don't actually provide rendering in such a manner.
There is active discussion on actually being able to build up complex grapheme clusters in such a manner, because it's necessary for Egyptian and Mayan text to be displayed properly. U+13430 and U+13431 have been accepted for Unicode 10.0 already for some Egyptian quadrat construction.
Korean doesn't use IDSes, it's a fixed algorithm (not specced by unicode, but a fixed algorithm) for combining jamos into a syllable block. Korean syllable blocks are made up of a fixed set of components.
IDSes let you basically do arbitrary table layout with arbitrary CJK ideographs, which is very very different. With Hangul I can say "display these three jamos in a syllable block", and I have no control over how they get placed in the block -- I just rely on the fact that there's basically one way to do it (for modern korean, archaic text is a bit more complicated and idk how it's done) and the font will do it that way.
With IDS I can say "okay, display these two glyphs side-by-side, place them under this third glyphs, place this aggregate next to another aggregate made up of two side-by-side glyphs, and surround this resulting aggregate with this glyphs". Well, I can't, because I can't say the word display there; IDS is for describing chars that can't be encoded, but isn't supposed to really be rendered. But it could be, and that's a vastly different thing from what existing scripts like Hangul and Indic scripts let you do when it comes to glyph-combining.
Jamo, Emoji (including flag combinators), Arabic, and Indic scripts all combine according on effectively per-character basis. There's not really any existing character that says "display any Unicode grapheme A and grapheme B in the same visual cell with A above B." The proposed additions to Egyptian hieroglyphs would be the first addition of such a generic positioning control character to my knowledge, albeit perhaps limited just to characters in the Egyptian Unicode repertoire.
Research on what to do vis à vis Mayan characters (including perhaps reusing Egyptian control characters for layout) is still ongoing, as is better handling of Egyptian.
Somebody involved with Unicode must have had the same idea, because the ideographic description characters exist. However, I've never seen them used in practice because they don't actually render the character. You just get something like ⿰扌足, which corresponds to 捉.
I'm curious. Are interlinear ruby annotation codepoints actually used for their intended purpose anywhere? And what are you supposed to do when you encounter one?
I know that they appear on Unicode's shitlist in [UTR#20], a proposed tech report that contained a table of codepoints that should not be used in text meant for public consumption. UTR#20 suggested things you could do when you encounter these codepoints, but it was withdrawn, leaving the status of these codepoints rather confused.
> Are interlinear ruby annotation codepoints actually used for their intended purpose anywhere?
Yes
> And what are you supposed to do when you encounter one?
Nothing. Don't display them, or display some symbolic representation. You probably shouldn't make ruby happen here; if your text is intended to be rendered correctly use a markup language.
----------
Unicode is ultimately a system for describing text. Not all stored text is intended to be rendered. This is why it has things like lacuna characters and other things.
So when you come across some text using ruby, or some text with an unencodable glyph, what do you do? You use ruby annotations or IDS respectively. It lets you preserve the nature of the text without losing info.
(Ruby is inside unicode instead of being completely deferred to markup since it is used often enough in Japanese text, especially whenever an irregular (not out of the "common" list) kanji is used. You're supposed to use markup if you actually want it rendered, but if you just wanted to store the text of a manuscript you can use ruby annotations)
Can you give an example of text in the wild that uses interlinear ruby annotation codepoints? Because I searched the Common Crawl for them, and every occurrence of U+FFF9 through U+FFFB seems to have been an accident that has nothing to do with Japanese.
Note that I didn't actually ask you about rendering.
I care from the point of view of the base level of natural language processing. Some decisions that have nothing to do with rendering are:
- Do they count as graphemes?
- What do you do when you feed text containing ruby characters to a Japanese word segmenter (which is not going to be okay with crazy Unicode control characters, even those intended for Japanese)?
- Could they appear in the middle of a phrase you would reasonably search for? Should that phrase then be searchable without the ruby? Should the contents of the ruby also be searchable?
Seeing how ruby codepoints are actually used would help to decide how to process them. But as far as I can tell, they're not actually used (markup is used instead, quite reasonably). So I'm surprised that your answer is a flat "Yes".
> Can you give an example of text in the wild that uses interlinear ruby annotation codepoints?
Sadly, no :( You may have luck scraping Wikibooks or some other source of PDFs or plaintext. In general you won't find interlinear annotations on the web because HTML has a better way of dealing with ruby. This is also why they're in the "shitlist", that shitlist is for stuff that's expressly not supposed to be used in markup languages.
Another way to get a good answer here is by asking the unicode mailing list, they tend to be helpful here. I know that they're used because I've heard that they are, so no first-hand experience with them. This isn't a very satisfying answer, I know, but I can't give a better one.
> Do they count as graphemes?
The annotation characters themselves? By UAX 29 they probably do, since UAX 29 doesn't try to handle many of these corner-case things (it explicitly asks you to tailor the algorithm if you care about specifics like these). ICU might deal with them better. The same goes for word segmentation, e.g. UAX 29 will not correctly word-segment Thai text, but ICU will if you ask it to. I haven't tried any of this, but it should be easy enough.
I guess a lot of this depends on what kind of processing you're doing. Ignoring the annotation sounds like the way to go for NLP, since it's ultimately an _annotation_ (which is kinda a parallel channel of info that's not essential to the text). This certainly applies for when the annotations are used for ruby, though they can be used for other things too. Interlinear annotations were almost used for the Vedic samasvara letter combiners, though they ultimately went with creating new combiners since it was a very restricted set of annotations.
They're not used much so the best way forward is probably to ignore them, really. These are a rather niche thing that never really took off.
LOL, I knew about the crazy flag characters, but I had no idea it was this bad. Does "woman + ZWJ + heart + ZWJ + hands pressed together + ZWJ + woman" become "2 women lovingly holding hands"? Unicode has become completely absurd, and I am grateful every day that I'm not one of the poor coders having to implement it.
Humorously enough, input methods have not advanced at all. To type any of these things, I need to open a character picker, then either type in the character's name if I know it, or scroll through pages of symbols until I find the one I want. Yet we still call this "text."
That's all well and good, but at the end of the day, some unknowing developer has to write this functionality into whatever input-related code for some program that doesn't use OS-level components, and it just creates a mess.
What frustrates you about it? I understand the complexity of compositions, but do you have any interesting stories to share about the complexity causing problems for you?
Before emoji, fonts and colors were independent. Combining the two creates a mess. Try using emoji in an editor with syntax coloring. We got into this because some people thought that single-color emoji were racist.[1] So now there are five skin tone options. The no-option case is usually rendered as bright yellow, which comes from the old AOL client. They got it from the happy-face icon of the 1970s.
Here's the current list of valid emoji, including upcoming ones being added in the next revision.[2]
A reasonable test for passwords is to run them through an IDNA checker, which checks whether a string is acceptable as a domain name component. This catches most weird stuff, such as mixed left-to-right and right-to-left symbols, zero-width markers, homoglyphs, and emoji.
Unicode does not require fonts to use color, and the spec does try to deal with the case where you don't want to use color; explicitly talking about black-and-white renderings in multiple places. This is no different for the skin tone modifiers, it's perfectly okay to fall back to a greyscale emoji (indeed, it might make sense to render all emoji in greyscale or B&W in a text editor).
> [...] it's perfectly okay to fall back to a greyscale emoji [...]
...if you want to destroy the user experience. Practically many implementations would be forced to support colors. (I'm personally okay with that, but just to be correct)
Not if you have to render them, or store them in a font. There are now color fonts.[1] Firefox and Microsoft Edge now support them. It's done with SVG artwork inside OpenType font files.
> Not if you have to render them, or store them in a font.
I think you misunderstood the comment to which you replied. What it was saying is that emoji fitzpatrick scale and color fonts are orthogonal concerns, you can do skin tones in grayscale.
There are multiple ways to encode colors in OpenType fonts: not only SVG (which is probably the least common way), but also the Microsoft COLR table and PNG raster glyphs (used by Apple).
> Before emoji, fonts and colors were independent.
Fonts and colors are still, for the most part, independent. Color or the lack thereof is a property of your font and text rendering subsystems. For instance Noto Emoji provides B&W emoji, and Noto Color Emoji provides colored ones.
> A reasonable test for passwords is to run them through an IDNA checker, which checks whether a string is acceptable as a domain name component. This catches most weird stuff, such as mixed left-to-right and right-to-left symbols, zero-width markers, homoglyphs, and emoji.
Why test this at all? It's not as if a website should ever need to render a user's password as text. Is there another use case for excluding this "weird stuff" that I'm not seeing?
Suppose I include 'ü': LATIN SMALL LETTER U WITH DIAERESIS in my password. I switch to a different browser/OS/language and now when I enter "ü" I get 'u': LATIN SMALL LETTER U + ' ̈': COMBINING DIAERESIS. I can't log in anymore, though what I do is identical and defined to be equivalent. Especially if the password is hashed before comparing it, you can't treat it as just a sequence of bytes.
You don't need to use IDNA for this, though. There are standards specifically for dealing with Unicode passwords, such as SASLprep (RFC 4013) and PRECIS (RFC 7564).
I would not actually disallow these characters, but you may warn the user about the existance of problematic characters in their password of choice.
If I want to use äöüßÄÖÜẞ because I'm confident that I can properly type them on all devices I'll need to type then, then let me. It's not your concern what method of input I'm using.
And maybe, just maybe, using latin characters is actually more of a hassle for a user anyway. (I think the risk of that occoring is low, but still. At the moment, it's a self-fulfilling prophecy that all users have proper method to input atin script available. We simply force them to have one.)
Edit: And the confusion is also possible with just latin characters. U+0430 looks exactly like "a", but has a different code point and thus ruins the hash.
It's interesting that in certain subcultures, including a large portion of the tech community, things that are non-racial are now considered racist. Not only do you have to be "racially aware", as they say, but you have to be racially aware in the right way. Being "colorblind" isn't enough anymore. Even the emoticons have to express race!
Perhaps predictably, this has backfired and will continue to backfire quite spectacularly; it turns out that when you force people to start thinking along racial lines, they might not end up with the exact same ideas about race that you have. I suspect this may be a large contributing factor behind the recent resurgence of ethno-nationalism (see the Alt Right et al.).
There are multiple ways of counting "length" of a string. Number of UTF-8 bytes, number of UTF-16 code units, number of codepoints, number of grapheme clusters. These are all distinct yet valid concepts of "length."
For the purpose of allocating buffers, I can see the obvious use in knowing number of bytes, UTF-16 code units, or the number of codepoints. I also see the use in being able to iterate through grapheme clusters, for instance for rendering a fragment of text, or for parsing. Perhaps someone can shed light on a compelling use case for knowing the number of grapheme clusters in a particular string, because I haven't been able to think of one.
I'm not sure about calculating password lengths: if the point is entropy, the number of bytes seems good enough to me!
The password field bug is possibly compelling, but I don't think it's obvious what a password field should do. Should it represent keystrokes? Codepoints? Grapheme clusters? Ligatures? Replace all the glyphs with bullets during font rendering?
(Similarly, perhaps someone could explain why they think reversing a string should be a sensible operation. That this is hard to do is something I occasionally hear echoing around the internet. The best I've heard is that you can reuse the default forward lexicographic ordering on reversed strings for a use I've forgotten.)
> Perhaps someone can shed light on a compelling use case for knowing the number of grapheme clusters in a particular string, because I haven't been able to think of one.
If you have a limit on the length of a field, it helps to tell the user what it is in a way they understand. For non-technical users, bytes (and the embedded issue of encoding) and code points are both pretty esoteric, but number of symbols is less so. OTOH, SMS has strict data and encoding limits, and people managed with that; also provisioning byte storage for grapheme limited fields is hard: some graphemes use a ton of code points, family emoji and zalgo text are clear examples.
If that's why you have a limit then please go and change that immediately.
No, this post is talking about having a minimum length on the password for safety reasons (i.e. a limit on the minimum entropy). You're right that a minimum byte length will ensure this, but what happens when your user types in n-1 "things" but their password gets accepted anyway. That's only a minor thing but (and I'm not entirely sure whether this is possible) what about when your user types in n "things" but the password doesn't get accepted because it's actually only n-1 bytes. Now the password won't be accepted and the user has no idea why.
I agree that these are relatively trivial things, but the point is that it's not as simple as "just use the byte length".
Some limits are technical (and in that case the hard limit is often bytes, but sometimes code units or code points, or broken if you told MySQL utf8 instead of bytes or utf8mb4), but in many cases, the limits are for aesthetic purposes: a post title or a username often is often required to be fairly short to look nice; in an ascii or latin1 world, those limits are usually expressed in terms of characters, but graphemes might be the right thing to limit in a unicode world.
To expand on this point, one resolution to the Ship of Theseus problem is that the point at which the ship stops being the "same" ship depends on how you are going to define "same." "Same" could mean different things depending on what you are trying to do, so this isn't just an it's-just-semantics cop-out. In particular, to borrow something Ravi Vakil once said, a definition is worthless unless it has a use (which in his case, as a mathematician, if it can be used to uncover and prove a theorem). This is what I have in mind: I do not think it is worthwhile to worry about "the true length of a Unicode string" unless there is something you could do if only you could compute it, and I've been trying to think of something but have come up short.
Speaking of equality: in a lecture about logic I once gave, I asked the students whether {1,2} and {1,2} were the same. In a very real sense, they are different because I drew them (or typed them) in different places and slightly differently -- I promise I typed the second {1,2} with different fingers. But, through the lens of same-means-same-elements, they are the same. That is a warmup for {1,2} vs {1,1,2}, and {1,2} vs {n : n is a natural number and 1 <= n <= 2}.
(There's also kind of a joke about how my set of natural numbers might be red and your set of natural numbers might be blue, but the theory of sets doesn't care about the difference.)
If you want to do Unicode correctly, you shouldn't ask for the "length" of a string. The is no true definition of length. If want to know how many bytes it uses in storage, ask for that. If you want to know how wide it will be on the screen, ask for that. Do not iterate over strings character by character.
How many dots/stars should one display for a password? That's a question that can't be answered by your two valid question. Are you suggesting that dots/stars shouldn't be displayed for passwords, since you can't ask how many "characters" it is?
You could divide the length of the string by the length the '*' character in a monospaced font. It doesn't really make sense for a combining or other invisible character to get its own asterisk.
If you have an entry indicator, it should probably be about the same width as the entered text; or if you're concerned about leaking precise length information for fields that aren't monospaced, you could add a dot each time the rendered text would increase in width.
I'd avoid the term "character", but I'd argue there are valid reasons to consume a Unicode string grapheme by grapheme. For example, a regex engine trying to match "e + combining_acute_accent" wants to match both the pre-combined version and the version that uses combining characters.
The main thrust of your point — that "length" without clarification of what measure of length is meaningless — I agree with.
> The current largest codepoint? Why that would be a cheese wedge at U+1F9C0. How did we ever communicate before this?
Sounds cute, but inaccurate.
If we count the last two planes that are reserved for private use (aka, applications/users can use them for whatever domain problems they like), that would be U+10FFFD.
If we count the variation selector codepoints (used for things like changing skin tone, or the look of certain other characters), U+E01EF.
If we count the last honestly-for-real-written-language character assigned, it would be 𪘀 U+2FA1D CJK COMPATIBILITY IDEOGRAPH-2FA.
But I suppose none of that sounds as fun as an emoji (which are really a very small part of the Unicode standard).
I tried to look up what U+2FA1D, the highest-numbered printable character, means in context.
It is a Traditional Chinese character. It's a variant of U+2F600, 𪘀, which is pronounced "pián". It apparently is used in zero words. It's in Unicode because it's listed in the 7th section of TCA-CNS 11643-1992, a Taiwanese computing standard.
Searching for it gives lots of sites that acknowledge that it's a character that exists and then provide no definition for it.
My guess: it occurred in someone's name at some point. Pretty strange that it ended up requiring a compatibility mapping, though, when nobody seems to use the character or the character it's mapped to!
I'm working on a project that has to handle special rendering of emoji as well, and I simply ask the system "will this string render in the emoji font" and "how big of a rect do I need to render this string" to calculate the same thing, rather than trying to handle it myself and relying on assumptions about the sizing of the emoji. I figure this way I also future proof against whatever emoji they think up in the future.
I ran into this 2 years ago on Swift when I was creating an emojified version of Twitter. I wanted to ensure that each message sent had at least 1 emoji and I quickly realized that validating a string with 1 emoji was not as simple as:
if (lastString.characters.count == 2) {
// pseudo code to allow string and activate send button
}
This was the app I was working on [1]; code is finished, but I'm not launching it (probably ever). The whole emoji length piece was quite frustrating because my assumption of character counting went right out of the window when I had people testing the app in Test Flight.
Actually, this is just due to Swift not implementing Unicode 9's version of UAX 29 (which had just come out at the time). Swift should handle it correctly, but it's lagging behind in unicode 9 support. In general a "character" in a string is a grapheme cluster, and most visually-single emoji are single grapheme clusters. The exception is stuff like ️[1]. That should render as a male judge (I don't think there's font support for it yet) according to the spec, and it should be a single grapheme cluster, but the spec has what I consider a mistake in it where it isn't considered to be one. I've filed a bug about this, since the emoji-zwj-sequences file lists it as a valid zwj sequence, but applying the spec to the sequence gives two grapheme clusters.
There's active work now for Unicode 9 support in Swift. Since string handling is heavily dependent on this algorithm (they have a unicode trie and all for optimization!) it's trickier than just rewriting the algorithm.
But, in general, you should be able to trust Swift to do the right thing here, barring bugs like "not up to date with the spec". Swift is great like that.
> I have no idea if there’s a good reason for the name “astral plane.” Sometimes, I think people come up with these names just to add excitement to their lives.
The issue doesn't really seem to be the emojis, but rather the variation sequences, which seem to be really awkward to work with, but I can sort of see why they're necessary. But the fact that we need special libraries to answer fairly basic queries about unicode text doesn't bode well.
> But the fact that we need special libraries to answer fairly basic queries about unicode text doesn't bode well.
That's always been needed to actually properly work with unicode, what do you think ICU is? Few if any languages have complete native Unicode support. And it's hardly new, Unicode has an annex (#29) dedicated to text segmentation: http://www.unicode.org/reports/tr29/
Just ran into this yesterday when I discovered that an emoji character wouldn't fit into Rust's `char` type. I just changed the type to `&'static str` but I still wish there was a single `grapheme` type or something like that.
If this interests you, read the source of Java's abstractStringBuilder.reverse(). It's interesting and very short. I am not sure it can deal with multi-emoji-emoji though.
I'm sure all browser designers out there would love it if we could switch JS over to UTF8, or in general have any system where JS uses a well formed encoding when it comes to unicode. We can't, because of backwards compatability.
Unicode is fucked. All these bullshit emojis remind me of the 1980s when ASCII was 7 bits but every computer manufacturer (Atari, Commodore, Apple, IBM, TI, etc...) made their own set of characters for the 128 values of a byte beyond ASCII. Of course Unicode is a global standard so your pile-of-poop emoji will still be a pile-of-poop on every device even if the amount of steam is different for some people.
It's beyond me why this is happening. Who decides which bullshit symbols get into the standard anyway?
Ah yes, all those bloody emoji taking the place of better worthier characters, those dastardly pictures taking up all of one half of one 16th of one Unicode plane (which has only 16 of those, and only 14 public).
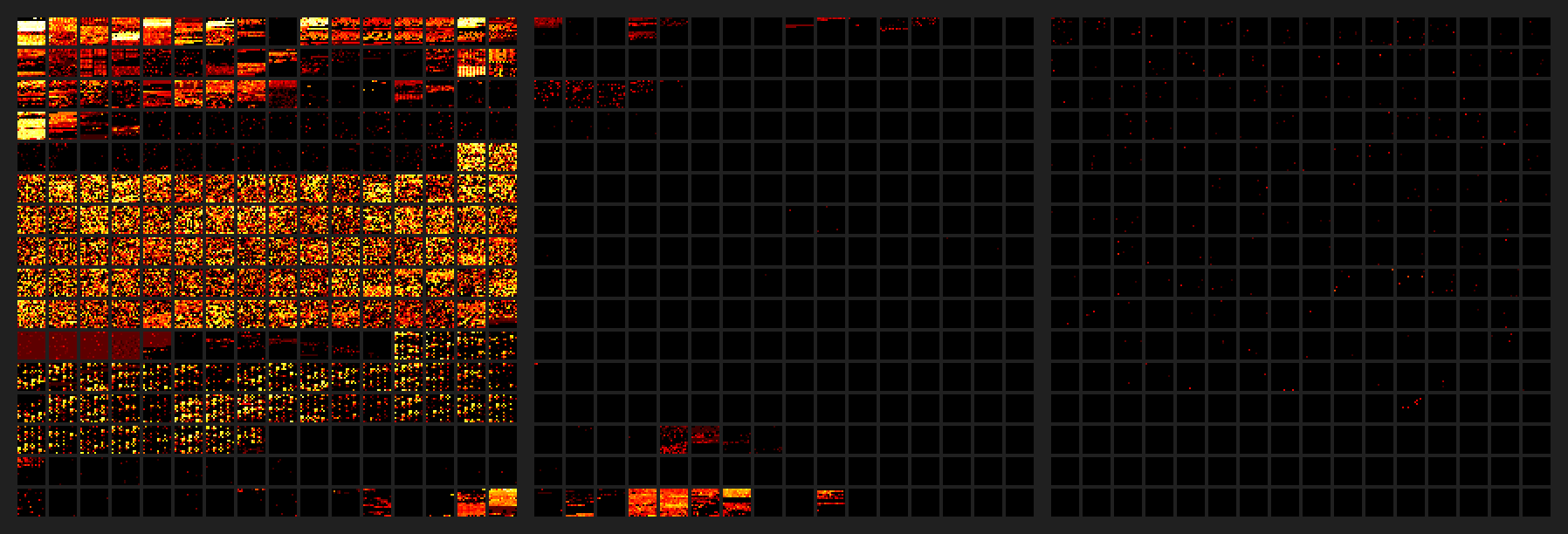
And the gall they have, actually being used and lighting up their section of plane 1 like a christmas tree while the rest of the plane lies in the darkness: http://reedbeta.com/blog/programmers-intro-to-unicode/heatma... what a disgrace, not only existing but being found useful, what has the world come to.
And then of course there's the technical side of things: emoji actually forced western developers — and especially anglo ones — to stop fucking up non-ASCII let alone non-BMP codepoints. I don't think it's a coincidence that MySQL finally added support for astral characters once emoji started getting prominent.
In fact, I have a pet theory that the rash of combining emoji in the latest revisions is in part a vehicle to teach developers to finally stop fucking up text segmentation and stop assuming every codepoint is a grapheme cluster.
Language is inherently complex, there's no way to solve this in any "cleaner" way than what we already came up with. Unfortunately the best way forward is to build up what we already have and cover all the warts with wrapper functions/libraries.
Well, there is one way, we can simplify and standardize format of language. Unfortunately that requires generations of "reeducation", so it's not a viable solution in the short term - but it does seem possible that this is where languages are going in the next few centuries, as globalization, easier travel and more interrelated communities are likely to result in slow, gradual convergence to less languages as many of the current 6000+ languages cease to be used in practice.
I am always surprised when people think that the solution to "dealing with language in programming is complex" is "let's reeducate the world by changing their language" instead of "let's reeducate programmers".
The Love Hotel (U+1F3E9) is rather obvious, maybe the kiss mark (U+1F48B) as well, though the raunchiest ones (in actual use) are a bit more… discreet?: the aubergine (U+1F346) and splashing "sweat" (U+1F4A6).
I'm not sure what use that would be? U+<hex> is a normal way to designate codepoints, and I can't put the actual emoji in the comment as they're stripped on submission.
Unicode is a conflation of two ideas, one good and the other impossible.
The good idea is to have a standard mapping from numbers to little pictures (glyphs, symbols, kanji, ideograms, cuneiform pokings in dried clay, scratches on a rock, whatever.) This is really all ASCII was.
The impossible idea is to encode human languages into bits. This can't be done and will only continue to cause heartache in those who try.
ASCII had English letters but wasn't an encoding for English, although you can and everyone did and does use it for that.
I hate this argument every time I see it because it's invariably used in the wrong place.
Yes, the goal of encoding all human languages into bits is one that's near impossible. Unicode tries, and has broken half-solutions in many places. Lots of heartache everywhere.
This is completely irrelevant to the discussion here. The issue of code points not always mapping to graphemes is only an issue because programmers ignore it. It's a completely solved problem, theoretically speaking. It's necessary to be able to handle many scripts, but it's not something that "breaks" unicode.
> It's a completely solved problem, theoretically speaking.
lol.
Unicode was ambitious for its time, but naive. Today we know better. It "jumped the shark" when the pizza slice showed up and has only been getting stupider since. Eventually it will go the way of XML (yes, I know XML hasn't gone anywhere, shut up) and we will be using some JSON hottness (forgive the labored metaphor please!) that probably consist of a wad of per-language standards and ML/AI/NLP stuff, etc.. blah blah hand-wave.)
Yes, "it jumped the shark when the pizza slice showed up". However, that doesn't imply that it did everything wrong. The notion of multi-codepoint characters is necessary to handle other languages. that is a solved problem, it's just that programmers mess up when dealing with it. Emoji may be a mistake, but the underlying "problems" caused by emoji existed anyway, and they're not really problems, just programmers being stupid.
We had multiple per-language encodings. It sucked.
I don't agree that the notion of multi-codepoint characters is necessary, I don't think it was a good idea at all. I submit [1] as evidence.
Whatever this mess is, it's a whole thing that isn't a byte-stream and it isn't "characters" and it isn't human language. Burn it with fire and let's do something else.
(In reality I am slightly less hard-core, I see some value in Unicode. And I really like Z̨͖̱̟̺̈̒̌̿̔̐̚̕͟͡a̵̭͕͔̬̞̞͚̘͗̀̋̉̋̈̓̏͟͞l̸̛̬̝͎̖̏̊̈́̆̂̓̀̚͢͡ǵ̝̠̰̰̙̘̰̪̏̋̓̉͝o̲̺̹̮̞̓̄̈́͂͑͡ T̜̤͖̖̣̽̓͋̑̕͢͢e̻̝͎̳̖͓̤̎̂͊̀͋̓̽̕͞x̴̛̝͎͔̜͇̾̅͊́̔̀̕t̸̺̥̯͇̯̄͂͆̌̀͞ it is an obvious win.). Even when it doesn't quite work... (I think I'm back to "fuck Unicode" now.)
If anything, their adaptability gives me confidence. They have little power to stop vendors from creating new emojis that are morphologically distinct from existing ones, so they might as well wrangle them into a standard.
There is a Unicode encoding "UTF-32" which has the advantage of being fixed width. This is not popular for the obvious reason that even ascii characters are expanded to 4 bytes. Additionally the windows APIs, among other interfaces, are not equipped to handle 4-byte codepages.
Being fixed width is not an advantage. Code points aren't a very useful unit of text outside of the implementation of algorithms defined by unicode. All of these algorithms generally require iteration anyway. O(1) code point indexing is nearly useless.
It's fixed width with respect to code points, but not with respect to any of the other things mentioned in the linked article. For example, the black heart with emoji variation selector (which makes it render red) is two code points.
> "UTF-32" which has the advantage of being fixed width
It's fixed width for now. It can not hold all the current available code-points, so it will probably have the same fate as UTF-16 (but it will probably take a long time).
There are currently 17 × 65536 code points (U+0000..U+10FFFF) in Unicode. UTF-32 could theoretically encode up to a hypothetical U+FFFFFFFF and still be fixed-width.
Note that, at present, only 4 of the 17 planes have defined characters (Planes 0, 1, 2, and 14), two are reserved for private use (15 and 16), and an additional is unused but is thought to be needed (Plane 3, the TIP for historic Chinese script predecessors). Four planes appear to be sufficient to support every script ever written on Earth, as it's doubtful there are unidentified scripts with an ideographic repertoire as massive as the Unified CJK ideographs database.
We are very unlikely to ever fill up the current space of Unicode, let alone the plausible maximum space permissible by UTF-8, let alone the plausible maximum space permissible by UTF-32.
{kind=link}
{kind=link}
[1] http://www.unicode.org/reports/tr29/
[2] https://github.com/orling/grapheme-splitter