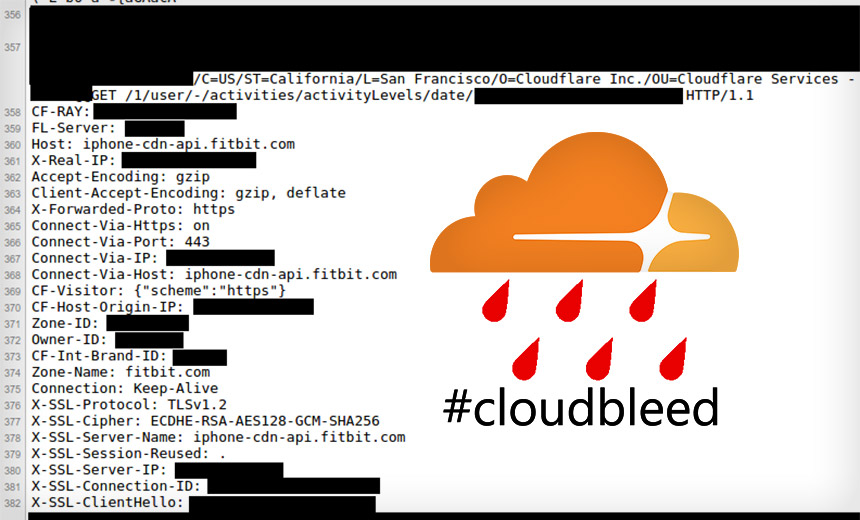
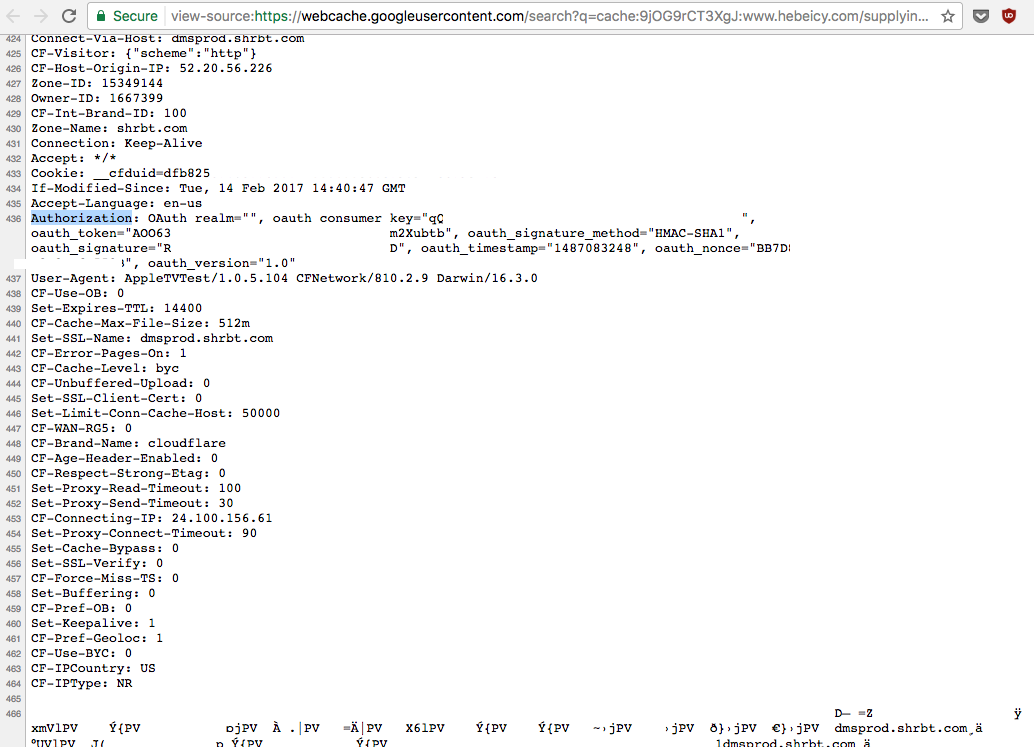
So I understand what happened with the Cloudflare bug, that https POST request content was leaked into HTML documents on the same or other servers and some of it was cached by search engines or malicious foreign powers. Whenever something like this happens the HN community whips up into a frenzy with people coming out of the woodwork that appear to be experts saying that "this is the end" and "this is so bad, we're f*cked".
Meanwhile - none of my friends in the
"real world" (outside the HN bubble) seem to be affected by this at all. I have a client that's a Cloudflare customer and they got an email saying they just weren't affected. And I haven't seen any huge leaks or items in the press about some terrible hack or theft that has brought someone or a corporate "down".
Should we always take news like this with a grain of salt? When can we tell when an attack like this is a fundamental undermining of the entire internet infrastructure, an attack that will cripple a few major companies, or just an issue that revealed some data but was mostly just overblown? Would love to hear some opinions!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Some people's accounts will be compromised, and nobody will know if it's been due to fishing, insecure passwords, or an information leak such as the Cloudflare bug, or an undisclosed or undiscovered breach somewhere.
The more responsible Cloudflare customers have invalidated existing sessions; that's much less hassle than forcing a password reset, and since session tokens are transmitted in every request, a leaked token is much more likely than a leaked password.