The visual description of the colliding files, at http://shattered.io/static/pdf_format.png, is not very helpful in understanding how they produced the PDFs, so I took apart the PDFs and worked it out.
Basically, each PDF contains a single large (421,385-byte) JPG image, followed by a few PDF commands to display the JPG. The collision lives entirely in the JPG data - the PDF format is merely incidental here. Extracting out the two images shows two JPG files with different contents (but different SHA-1 hashes since the necessary prefix is missing). Each PDF consists of a common prefix (which contains the PDF header, JPG stream descriptor and some JPG headers), and a common suffix (containing image data and PDF display commands).
The header of each JPG contains a comment field, aligned such that the 16-bit length value of the field lies in the collision zone. Thus, when the collision is generated, one of the PDFs will have a longer comment field than the other. After that, they concatenate two complete JPG image streams with different image content - File 1 sees the first image stream and File 2 sees the second image stream. This is achieved by using misalignment of the comment fields to cause the first image stream to appear as a comment in File 2 (more specifically, as a sequence of comments, in order to avoid overflowing the 16-bit comment length field). Since JPGs terminate at the end-of-file (FFD9) marker, the second image stream isn't even examined in File 1 (whereas that marker is just inside a comment in File 2).
tl;dr: the two "PDFs" are just wrappers around JPGs, which each contain two independent image streams, switched by way of a variable-length comment field.
Wow, nice. Thanks. It seems everyone is thinking the secret sauce had something to do with embedding appropriate junk to the PDF format itself.
I was cynically thinking that Google might, as an aside, be recruiting with this disclosure; looking for people (like you) who actually solved the "how they did it" puzzle.
So if one were hashing data or a document format that also contained a bit of self-referential integrity data, e.g. the end of the data has a CRC of the rest of the block, or maybe a cryptographic signature using some other hash, wouldn't that further constrain the search space? Then not only would one need to back out the random bits needed to complete the SHA-1 collision, it would also have to satisfy a some other constraint within the other data in the block.
The best thing would be if one could prove a mathmatically incompatible set of counter functions where data colliding in the hash of one function would prevent the other function from validating correctly.
> The best thing would be if one could prove a mathmatically incompatible set of counter functions where data colliding in the hash of one function would prevent the other function from validating correctly.
I'm a rank amateur, so this is completely outside of my wheelhouse, but this sounds suspect. I don't think you can make hash collision impossible, even with multiple functions, unless the combined hashes contain as much data as the originals or the combined functions have restricted inputs. The point of hashes is making collisions hard, not mathematically impossible - the latter is, I believe, itself impossible.
Like I said, I'm totally unqualified to speak on this, so I may well be missing something here.
You are correct: by the pigeonhole principle, if the sum of the lengths of all the hashes/checksums is less than the length of the checksummed data, then collisions exist.
(A detail: If checksums are included into the input of other checksums, their length doesn't count towards the amount of checksummed data, because they are not free to vary.)
Yes, this is correct. It's a really simple principle, and I think an explanation can help you understand :)
Suppose you have 3 holes, and 4 pigeons, and you stuff the pigeons into holes. There must be 1 hole with at least 2 pigeons, right?
The same is true with hash functions. If you're hashing data down to a fixed length, like say 256-bits with sha-256, and the data is longer than 256 bits, there must be a collision somewhere.
I'm an amateur in this area too, but I'm not suggesting to avoid collisions, I'm suggesting adding a validation function for the hashed data so that if one were to generate an intentional collision, you would still have to contend with generating it in a way that also validated.
Issue with that is we already addressed that during the MD5/cert collision era; the final cert, as delivered, would by definition contain additional data over the CSR (the signer reference and the start/end dates) but because that information was predictable, the collision could be generated for the expected emitted cert, rather than the input data. Same would apply to git; if you were building the submitted data block, you would know what type and length it was going to be, so could build it with that in mind while colliding.
The composition of the result of the original hash function and the result of that validation function can be taken together to be some larger function. Call that an uberhash. Such an uberhash is created by putting some number of bits in and getting some smaller number of bits out. There will unfortunately still be collisions. That trick is an improvement, and newer hashing algorithms contain similarly useful improvements to make creating collisions difficult.
It's a good thought, but if the functions have bounded-length outputs (as with all major hash functions), then your combined hash value is still a bounded length. A collision must therefore exist because there are many more potential messages than potential hash values.
If your functions produce unbounded-length hashes, then you may as well just be compressing your input to guarantee there are no collisions in your "hash".
True - I suppose the hash function just ends up being the convolution of say an interior CRC and some exterior hash function. That gives us low to zero chance of something mathematically provable. But perhaps some arrangement of functions forces an attacker to scramble the inputs in more drastic ways such that the original data must be altered by more than a handful bytes it could perhaps raise the difficulty on a practical basis.
But to make a strong cryptographic hash, you don't want predictability based on inputs. If you end up with some kind of pattern where getting the same output values requires modifying huge ranges of bytes, that lets attackers reason about inputs that generated a hash.
The differences are confined to two SHA-1 input blocks of 64 bytes each. The first block introduces a carefully-crafted set of bit differences in the intermediate hash value (IHV), which are then eliminated in the second block. After the IHVs synchronize, all future blocks can be identical because SHA-1 can be trivially length-extended.
The notion of "document security" is a common desire in business and legal contexts. PDFs are a standard representation of documents, whereas JPGs are less common (TIFF might count since it's a somewhat common scanned document format, but I digress).
Subverting the most popular document format, one which even provides built-in support for digital signatures is probably much more interesting than subverting the JPG format.
Open challenge: build two signed PDFs with identical signatures and different contents - it's not necessarily hard, and it would definitely drive the point home.
I wonder if this is the 'standard' thing to do when you have a broken hash function. I took a introductory course in computer security a year ago and we had to create MD5 hash-colliding documents for homework[0].
I'm interested in taking a look at this assignment for my own learning, but it looks like there are a bunch of files you need. It would be cool if you put them in a git repo!
Because many automated systems/image hosting website (imgur, etc) will process JPEGs to optimize them, which I assume would no longer cause there to be a collision.
On the other hand, PDFs are almost universally sent as-is, increasing the risk of being able to 'fool' someone.
Perhaps to be taken more seriously by management. All things being equal, the content of PDFs (auditor reports) is more important than that of JPGs (cat memes).
I used Hachoir (https://github.com/haypo/hachoir3), a Python library that I've contributed to. Hachoir disassembles files using a library of parsers, with the intent of describing the function of every single bit in the file. You can see the resulting disassemblies (rendered with the hachoir-wx GUI) here: http://imgur.com/a/F1cnV
What an incredible tool... I have a webapp that has as a small component the analysis of JPEG metadata, this will be very useful for future development.
I use Hachoir for a lot of tasks - digital forensics (examining file tables on a filesystem, discovering slack space taken up by hidden data, etc.); for metadata extraction (for which the hachoir-metadata subproject is designed); for file carving (either with hachoir-subfile or manually); and just to geek out about file formats (did you know .doc/.ppt is secretly a FAT filesystem?).
Funny, I had no idea it could do all that. I've been using it in production for years to extract width/height/duration of media files at compile time so my loading placeholders are perfectly sized at runtime in a basic web app.
To put things into perspective, let the Bitcoin network hashrate (double SHA256 per second) = B and the number of SHA1 hashes calculated in shattered = G.
B = 3,116,899,000,000,000,000
G = 9,223,372,036,854,775,808
Every three seconds the Bitcoin mining network brute-forces the same amount of hashes as Google did to perform this attack. Of course, the brute-force approach will always take longer than a strategic approach; this comment is only meant to put into perspective the sheer number of hashes calculated.
- Google used GPUs, much of the Bitcoin network relies on fully custom ASICs now and mining without them isn't really profitable anymore
- SHA1 hashes can also be computed over twice as fast as SHA256 even on GPUs, so if someone were to go out and build SHA1 ASICs, you could probably do this very, very fast. It's almost certain that intelligence agencies could invest this effort to say, break SHA1 SSL certs.
It's almost certain that intelligence agencies could invest this effort to say, break SHA1 SSL certs.
To the contrary, it is unlikely that they can do so.
There is a world of difference between "come up with two things that hash to the same value" and "come up with something that hashes to a particular known value". It gets harder still if you're trying to add constraints about the format of your text (such as making them look like a potentially valid SSL cert).
To illustrate the difference, suppose that you can constrain the algorithm to produce one of a trillion values. If you generate a million possibilities, odds are good that 2 of them will have the same hash value. You've generated a collision! But you need to do a million times as much work to have good odds of generating any particular value.
That said, attacks only improve over time. While it is highly unlikely that intelligence agencies can break SHA1 certs today, it is extremely likely that they will eventually. Where eventually is 5-20 years.
> There is a world of difference between "come up with two things that hash to the same value" and "come up with something that hashes to a particular known value".
Doesn't the PDF on their site pretty much prove they can do both of these - at least, in a way? They were able to change the color without impacting the contents of the PDF and get the same SHA1.
They probably have a fair bit of garbage data to work with in the PDF format, but it seems likely that you might be able to do similar in certificate formats.
Remember, you only need a very small modification to change a valid web cert into a CA cert or a global wildcard.
No. I don't know the details of the attack, but a third possibility (as I read it) is that both PDF documents are modified in the process until they arrive at a collision.
PDF has the convenient property that you can inject arbitrary bogus data into the middle of it with a constant head and tail and it will still be valid. The tail of the file contains a trailer that points to the dictionary that describes where all of the resources in the file are located. The entire file need not be covered by the dictionary (and typically won't be for PDFs that have gone through several rounds of annotation/modification). This leaves the opportunity "dead chunks" that can be modified arbitrarily without changing the rendered result.
Or, if you're really clever - and Ange Albertini is quite good at this kind of trick - you can design the PDF so that the different garbage in the middle causes the other, unchanged content to be interpreted differently in the two PDF files, possibly even designing it so that the intended contents of each PDF is treated as garbage and ignored entirely in the other PDF.
With many image formats, you can just concatenate whatever you want at the end of the file, and the OS and programs will obliviously read and copy the whole file, while the image libraries will happily ignore the extra data.
And then you put PHP tags in that content at the end, and change the .htaccess file to process *.jpeg as PHP scripts, and your webshell looks benign until someone has that in mind looking through the account.
Re-reading it and checking out the demo on https://shattered.io/ it looks like it's even stranger -- some PDFs are "safe", so it may be that it requires the original document (and hash) to have certain properties to be able to generate a collision (but if it has those properties they may be able to generate them arbitrarily). It sounds like this is going to be reaaaalllly interesting when the 90 day window passes.
(also, should've mentioned in original post just for clarity -- I work for Google, but do not know any of the details of this work)
It's entirely possible that "dangerous" PDFs are simply ones with a dead chunk containing image data in in the middle of it, and if there's no dead chunks, or if the dead chunks don't allow for arbitrary garbage data, then it's "safe".
I haven't seen the actual PDFs, but the way my crypto prof taught me about this attack in college is that you generate a PDF of the form
if (x == a) {
// display good content
} else {
// display bad content
}
You have to craft this PDF file in such a way that given a SHA1 collision (a, b) that the file with x = a and the file with x = b have the same SHA1. (There are some nuances about aligning to block boundaries, IIRC.)
More technically, the reason why this is possible is that this is a block cipher. You take the file, and proceed block by block. So if two files are identical except for one block, and those differing blocks generates the same SHA-1, then the whole files will generate the same SHA-1. You can make it look like any pair of documents, but the actual content of the source includes both documents.
This trick works better with some document formats than others. PDF is great. Plain text, not so much.
This trick is absolutely useless unless you control both documents. But if you already control a certificate, then you have no need to try to switch to a fake one
> So if two files are identical except for one block, and those differing blocks generates the same SHA-1, then the whole files will generate the same SHA-1.
Is it really that simple? If that were the case, then you could take the two colliding blocks from Google's PDF and trivially use them to create an arbitrary number of colliding files. I would be really surprised if it was that easy.
It may be a question about the implications of https://en.wikipedia.org/wiki/Length_extension_attack, which allows computing H(X∥Y) from H(X), len(X), and Y (without knowing X!). I'm not immediately sure how that applies or fails to apply in the case of a hash collision; that's an interesting thing to think through.
I was a bit surprised to see this because I thought there might be more constraints on it, but I tried adding arbitrary strings to the end of both PDFs and re-hashing, and the hashes continue to be the same after appending arbitrary arbitrary-length strings. I guess this is indeed a consequence of the length-extension attack; we can argue that if -- for this kind of hash -- H(X∥Y) always depends only on H(X), len(X), and Y, then if len(a) = len(b) and H(a) = H(b), H(a∥Y) must also equal H(b∥Y).
I suspect you would see the same behaviour even with a hash function that is not vulnerable to length extension attacks.
My understanding is that protecting against length extension is about hiding the internal state of the cipher in the result hash, for the purposes of protecting a secret in the plaintext. But if the state is the same between each document, and you have access to the whole plaintexts, I don't see why length extension would play a role.
My intuition about this would be about hashes with "hidden state" that is neither reflected in nor reconstructible from the digest. For example, suppose the hash has a 1024-bit internal state and a 256-bit digest. Then two inputs that have a hash collision have the same digest but only about 2¯⁷⁶⁸ probability of having the same internal state, so if you continue to extend them, subsequent hashes will be different.
I think there are engineering reasons why this isn't typically the case for the hashes we normally use, but I'm just hypothesizing a way that this could be different.
Maybe I should consult a textbook (or a cryptographer) to understand more.
My intuition is that Merkle and Damgård may have thought that you get the greatest efficiency (or "bang for your buck") in some sense by simply outputting a digest that is as long as the internal state, since for some properties related to the intrinsic strength of the hash you would prefer that the digest be long. However, Lucks was apparently explicitly concerned about length extension and wanted to have some hidden state in order to prevent such phenomena, and hence proposed deliberately engineering it in.
But I'm not sure if that accurately presents the reason why the internal state and digest lengths have typically been the same in the past.
Edit: https://en.wikipedia.org/wiki/Comparison_of_cryptographic_ha... lists the internal state size alongside the output digest size. According to this chart, these functions have the same output and internal state lengths: MD4, MD5, RIPEMD and variants, SHA-0, SHA-1, Tiger-192, GOST, HAVAL-256, SHA-256, SHA-512, WHIRLPOOL.
These functions have a larger (hidden) internal state: RadioGatún, Tiger-160, Tiger-128, HAVAL-224, HAVAL-192, HAVAL-160, HAVAL-128, SHA-224, MD2, SHA-384, SHA-512/224, SHA-512/256, BLAKE2 variants, SHA-3 and all its variants, and PANAMA.
Sometimes the larger internal state is achieved simply by deliberately truncating (limiting the length of) the output hash, so the end user (and attackers) don't know the full original output hash and hence can't deduce the full original internal state.
I didn't know about this distinction before, although I once heard someone mention it in connection with BLAKE and SHA-3 candidates.
But if you already control a certificate, then you have no need to try to switch to a fake one
The way previous certificate collision attacks have worked is that you generate two certificate signing requests that are for different domains, yet will hash to the same value once the certificate authority applies their serial number, date &c. You get the certificate request that applies to your own domain minted into a genuine certificate, then transplant the signature into your colliding certificate for the other domain.
This relies on finding a certificate authority that is using the vulnerable hash function and being able to predict the serial number that will be applied to the certificate with reasonable probability. Doing the latter tends to imply being able to generate the collision very quickly.
No, they can't chose the hash value. Or, to put it an other way, they can't find a collision for an arbitrary file, they can only craft two particular files that happen to collide.
The "collision blocks" is where the magic happen, given the two different prefixes (with the different colors) they have to craft two sequences of bits that will put the SHA1 state machine in the same internal state once processed.
Once the state machines are "synchronized" you can add whatever identical content you want to both files after that and it'll always hash up to the same value. You can't control that value however.
> given the two different prefixes (with the different colors) they have to craft two sequences of bits that will put the SHA1 state machine in the same internal state once processed.
> Doesn't the PDF on their site pretty much prove they can do both of these - at least, in a way? They were able to change the color without impacting the contents of the PDF and get the same SHA1.
I think they prepared both PDFs and then tweaked with bits in both of them. This is much easier than tampering with only one PDF.
So I think it's still very hard to generated a CA cert where you can just copy the signature of an existing cert.
But maybe you can predict exactly what parts from your signing request and what timestamp and serial number and so on the CA will use, then you can maybe precompute a signing request that will result in a cert where you can replace some parts with other, evil, precomputed ones.
> But maybe you can predict exactly what parts from your signing request and what timestamp and serial number and so on the CA will use, then you can maybe precompute a signing request that will result in a cert where you can replace some parts with other, evil, precomputed ones.
That was true in Sotirov's MD5 collision attack (which I mentioned elsewhere in this thread) and is no longer true because of CA/B Forum rule changes requiring randomized serial numbers (currently, containing at least 64 random bits).
You are thinking about this in a wrong way. It is in fact true that being able to generate collisions allows you to break SSL. What you do is this: generate two certificates with colliding hashes, one for google.com, the other for your own domain. Verisign will gladly sign the second one, since you own the domain, but since the hashes match, you can also use the same signature for the first one. Now you can impersonate google.com.
Of course, the real certificate issuance process is more complicated and has some extra precautions to protect from it, my point is that you don't need preimage, collisions should suffice for breaking SSL.
Those extra precautions are designed explicitly to prevent the ability to get a certificate using a collision attack. CA's now must explicitly introduce entropy into a certificate to prevent exactly this, and will not sign a certificate exactly to the specifications of a client.
There's a great deal of handwaving there saying that a collision attack alone is sufficient for breaking SSL.
Moreover, how quickly we forget! An intelligence agency did in fact carry out such an attack on code signing certificates using an MD5 collision as part of the FLAME malware.
Maybe, and probably, but probably not within the scope of this attack. This attack relies on being able to have a large similar prefix and a lot of control over further internal data; SSL certs are somewhat more constrainted.
This attack is applicable to SSL certs. Not most CAs as they have deployed counter-measures (such as using a long, random serial number) after the publication of the colliding MD5 rogue CA (https://www.win.tue.nl/hashclash/rogue-ca/) but I'm sure there are tons of companies with IT department and internal CAs who don't follow best practices and could be attacked with SHA1 collisions.
Even root CAs have been known to not comply with the randomized serial number requirement occasionally, see [1] for a recent example, with the most recent (SHA-1) certificate being issued in August of last year.
Would a TLS certificate not offer such a large similar prefix? Just change the domain to a wildcard or something like the RapidSSL MD5 attack from a few years back.
In https://www.win.tue.nl/hashclash/rogue-ca/, Sotirov et al. were able to use the ability to create MD5 collisions to create a pair of colliding certificates because the content of an about-to-be-issued certificate was almost completely predictable. In response to this, the industry added requirements for CAs to include unpredictable values (such as an unpredictable serial number) in certificates. For example, the certificate for HN has serial number 00:EA:21:7C:EA:6C:1F:97:9E:6A:91:90:B7:68:52:D6:63, which is at least in part nonsequential and random, specifically in order to prevent an attacker who knows a collision attack in the hash function used by the CA from being able to exploit it.
This precaution means that an attack like this isn't immediately directly usable against TLS, because the work factor has been increased dramatically.
Edit: the adopted change to the rules is at https://cabforum.org/2016/07/08/ballot-164/ and requires at least 64 bits of CSPRNG entropy in the serial number, specifically as a response to Sotirov. I forgot the history of the section that it replaced (which recommended at least 20 unpredictable bits), but I think that may also have been a response to Sotirov; if the old recommendation had been in use then Sotirov's original attack would not have worked.
Well, certainly there's a lot of work that can be done by a computer network that spans what? 500+k computers all pegging their many cpu/gpu/asic processors at 100% 24/7. The bitcoin network, if seen as one processing unit, is history's most powerful computer. Of course it can punch out difficult work quickly. That doesn't mean your average Russian hacker can.
Of course this cuts both ways, we'll probably be seeing ASIC's designed just for this work that'll vastly cut down how much time is required to make these collisions.
Also, I find it impressive SHA-1 lasted 10 years. Think about all our advances in that time from both a hardware and cryptographic perspective. A decade of life in the cryptospace should be seen as a win, not a loss. I'm not sure why we thought these things would last forever. If anything, the cryptospace is faster moving now than ever. The concept of a decades long standard like we had with DES or AES is probably never going to happen again.
I wonder if SHA1 was used instead of SHA256 for Bitcoin mining, how much optimization these SHA1 discoveries would bring to the mining process (since it's more like partial brute forcing rather than finding collisions) i.e. what would be the percentage difference in the difficulty because of them - on the long run, since it takes some time to implement those things as ASICs.
>since it takes some time to implement those things as ASICs.
not really. it's just a few man-years to develop a kickass hdl and a lot of money and you're good to go. all bitcoin did was create a massive market for sha1 asics. i wonder if those asics can be used to reduce the 110 gpu-years down to a few asic-years?
It certainly raises an interesting question. The go-to response when anybody discusses brute forcing bitcoin is that the sheer number of possibilities makes finding a collision infinitesimally small. And that's true. Same for .onion certificates.
But Google certainly haven't been attacking this for the last 6,500 years. With a sufficiently obscene amount of resources, it IS feasible to create an index of every possible public/private keypair. It's not profitable to do so just for the purpose of plundering bitcoin wallets, but if you're a government doing it for other reasons, it might be worthwhile.
That's right. The numbers above are in the vicinity of 2^60. A typical ECC keylenght is 256 bits, and all numbers in that space are equally good secret keys. The remaining almost 200 bits still present something of an obstacle.
42U, 4 sockets, 8 cores = 1344 CPUs per rack.
two PCIe slots per U = 84 GPUs per rack
That's not even that exotic of hardware.
fifteen racks = 20160 CPUs and 1260 GPUsyum info
So five months or so assuming the GPUs can't be fed until the CPUs complete processing, give or take, in 15 racks of decently higher-end off-the-shelf stuff.
I guess with their 2 year timeline they were using at least 3250x whatever they define as a standard CPU - I wouldn't be surprised if it was simply 3250 cores @ 2 years or an equivalent higher number and less time.
I'd be interested about the actual specs of the hardware if anyone see's that info pop up.
One practical attack using this: create a torrent of some highly desirable content- the latest hot TV show in high def or whatever. Make two copies, one that is malware free, another that isn't.
Release the clean one and let it spread for a day or two. Then join the torrent, but spread the malware-hosting version. Checksums would all check out, other users would be reporting that it's the real thing, but now you've got 1000 people purposely downloading ransomware from you- and sharing it with others.
Apparently it costs around $100,000 to compute the collisions, but so what? If I've got 10,000 installing my 1BTC-to-unlock ransomware, I'll get a return on investment.
This will mess up torrent sharing websites in a hurry.
Edit: some people have pointed out some totally legitimate potential flaws in this idea. And they're probably right, those may sink the entire scheme. But keep in mind that this is one idea off the top of my head, and I'm not any security expert. There's plenty of actors out there who have more reasons and time to think up scarier ideas.
The reality is, we need to very quickly stop trusting SHA1 for anything. And a lot of software is not ready to make that change overnight.
I may be confusing p2p protocols, but doesn't BitTorrent grab different chunks from different sources, so that if there are different people spreading different versions that are viewed as the same, people are going to mostly get either the original (and initially more common) version or broken junk that is a mix of the two versions?
Not only that, BitTorrent also uses a Merkle tree of the torrent data split into pieces (e.g. 1 MB per piece), meaning you need to compute thousands of colliding hashes, with the added restriction that the data must be exactly the piece length.
The torrent ID is the Merkle root hash, which is a hash of all the piece-hashes hashed together in a tree structure: https://i.stack.imgur.com/JVdvj.png
If you find a collision for the smallest piece, you don't need to find collisions for any higher nodes on the Merkle tree because you'll just be hashing the same values as the legit version.
I don't know enough specifics about sha-1 or bit torrent, but it would seem to me that it depends on the data that is chosen for the base ("leaves") of the tree: if it just consists in taking the hashes, concatenating them, and move higher until you only have one hash, then yes.
However, if the data itself is concatenated for the first step, that might not be the case (depending on the sha-1 algorithm). I seem to recall that md5 operates on 512 bit chuncks (padded if necessary), and takes the result to seed the next computation. So, with md5 (if I recall correctly, still), the attack could work if each part of the torrent was a multiple of 512 bits, Merkel or not, and regardless of the base.
Of course, you cannot change the whole torrent in that case, as it would be prohibitively expensive. And you still have to keep the same file size.
I would love to hear a bit more on the topic from someone more knowledgeable about hashes and torrents.
The process is fairly simple. Files are concatenated and that blob is then chunked into multiple-of-16KiB-sized pieces. Each piece is hashed. The hashes are concatenated and embedded as string in the torrent file. Then a specific subdictionary of the torrent file including the piece hashes, filenames and the length of the data is hashed to yield the infohash.
Magnets only convey the infohash. .torrent files convey the whole metadata, including the pieces hash string.
Well, you could put most of the payload in other parts of the file. People probably wouldn't notice if they didn't go looking. And the small part could exploit a popular codec instead of being an executable itself.
Good point. It should be possible to create a video file that fills ups exactly the first n pieces, such that the last piece contains only the ambiguous data.
Most torrents use a flat list of hashes. The merkle tree is an extension. With a collision you could replace the metadata wholesale though, pointing at completely different content.
But then the torrent client would also present that different content from the start when asking you what to save.
Do you know of anybody that's actually using merkle torrents? I expect they're probably being used in some limited scenarios, but they're probably less than 1% of BitTorrent activity, so it's a bit misleading to refer to it when defending BitTorrent's security model.
Well, you really don't need the complete file either. Since torrents are usually shared unzipped, they can just replace a chunk with a bad one (It varies usually from 256KB-2MB) and a single chunk can be replaced with a bad one embedded with malware to cause problems.
Especially something like a buffer overflow attack on a video file.
Edit: Nevermind, I misinterpreted something in the report. Collisions between malicious and non-malicious documents are indeed most likely feasible.
Original comment:
While theoretically possible, I don't really see that particular attack as being an actual, practical problem anytime soon.
In order for that to work not only would you have to find _a_ collision, but you'd have to find one with the additional constraints of "one copy is malware free while the other isn't", which would be significantly more difficult (at least, as I understand it).
That said, I agree it's probably time for torrents to start moving to another hash function. With time and additional research, it's entirely possible that theoretical attacks like the one you described could eventually become practical.
Because the 10k people that would fall for such a trick (and I don't doubt there's at least 10k of them), are most probably already part of at least 23 other botnets.
No, that's not the big problem. Every collision of this kind so far just requires a random looking section, and allows another section to be whatever you want. You can just swap out one file for malware.
Ah, sorry. I got confused by this section on shattered.it, which seemed to be saying that merely requiring a certain level of entropy in the resulting documents would be enough to mitigate the attack:
> Are TLS/SSL certificates at risk? [...] it is required that certificate authorities insert at least 20 bits of randomness inside the serial number field. If properly implemented this helps preventing a practical exploitation.
After giving it a bit more thought though, I realize now though that this mitigation actually works by preventing the attacker from fully controlling the hash of the first, non-malicious document.
The project's site is referring to an outdated version of the requirement. As I noted above, the requirement they refer to is only a SHOULD (some CAs might not have complied with it) and was replaced at the end of September with a SHALL which requires 64 bits rather than 20.
this isn't quite true, bittorrent have checksums for each piece in the torrent, I not saying its impossible to do but its significantly harder than just finding 2 files with the same hash.
Wouldn't that make the attack easier, since you just have to manufacture a pair of pieces with the same hash, instead of having to make the whole file have the same hash?
that depends on the attacker objective, if you just want to trash the file you can just search for any piece that have a hash collision, but if you want to turn the file into a malware you will need to modify the file in a specific way, possibly spanning multiple pieces, and there's less room for fuzzing the hash.
As mentioned else were in this thread, you can put a lot of the payload outside the single collision piece. People are unlikely to go looking for executable code inside a video.
All you need for the colliding pieces is for one to trigger the payload and the other not to trigger the payload.
Okay, so the challenge gets broken down into creating a single piece that hides the malware. Even better really, I can join the network with a fleet of hosts all sharing that particular piece at a very high rate- but it's my bad version of it. Those hosts can focus on just distributing the malware, rather than the whole file.
Realistically, the closest low-cost attack is to just upload a malware-laden torrent of the latest TV show and not even pretend. It won't get seeded as widely, but you can do the same thing again next week.
>Edit: some people have pointed out some totally legitimate potential flaws in this idea. And they're probably right, those may sink the entire scheme. But keep in mind that this is one idea off the top of my head, and I'm not any security expert.
Well to be fair to those people, you started out saying its a practical attack when it wasn't even a theoretical one.
Well, it's practical on a small scale. You could wait until a torrent has only 1-2 seeders, and then you can hope to give leechers all blocks of a file. Or, you could deliver a torrent with a 1GB installer (for some software package) and a 100kb keygen (which you replace with malware) fitting inside a 1MB block and you can be sure to spread that around regardless of the number of other seeders.
1) wouldn't search time be proportional to file size for hashes? These guys worked on 400kb pdf's, while most popular torrent content is in the GB range
2) Wouldn't this only work for users that got the entire file from you? fileA and fileB may have the same hash, but some random portions from each will have a different hash.
You could replace a single chunk with your malware. Then it could be any size and the rest of the chunks could be the legit content. I don't know much about video codecs, but this assumes there's some way to break out of the playback and run your malicious code. Maybe a buffer overflow, or maybe if your malware is the first chunk of the file you could get it to run first somehow before the video?
Or even better, torrents of apps sometimes come with an executable that you run to crack the DRM (so I hear). You could swap that out undetected, and you can probably also convince people they have to run it with sudo.
> Maybe a buffer overflow, or maybe if your malware is the first chunk of the file you could get it to run first somehow before the video?
If you have an exploit in a video player, you don’t really need the collision.
> You could swap that out undetected, and you can probably also convince people they have to run it with sudo.
Also don’t need a collision (or more sudo than usual) for this; just make it patch the application (like it’s supposed to!) with something that runs with low probability.
You could have a buffer overflow attack talking advantage of a specific popular video player out there.
Since video players are usually not very security focused, someone determined could do it.
And since video torrents are unzipped, a single chunk can be replaced with the malicious chunk with the attack code. It can look like a tiny jitter depending on the chunk size/total video size.
Yep, and even if you feel the need for low-frequency attacks to keep seeding high, you could probably just fix a low chance of actually executing malicious behavior.
I wonder if you could model this similarly to populations. As in will the malware ever go extinct? Obviously an attacker probably won't stop seeding, but let's say shim does stop seeding. At this point x% of seeders have the payload. Seeders on average share the file y times. Will x tend to zero below a threshold of 50%?
And if the attacker does not stop seeding, will the infected quota stabilize?
Couldn't you get nearly the same intermittent-attack behavior just by saying something like "break out of codec, only do malicious behavior one time in 1,000"?
With a buffer overflow. Video players are supposedly pretty vulnerable to these kinds of attacks since they need to deal with many different types of media, which means there is quite a large attack surface and they have to accept all kinds of odd video files.
There's a book called "A Bug Hunters Diary" that explained this exact thing in a video played using a particular version of VLC. Quite far over my head how he did it but it was interesting to read.
It can use buffer overflow (which is often easier than it looks in a large codebase written with memory unsafe languages) to execute arbitrary code. Modern OS have protections from such attack vectors, but they are not sufficient enough and well-funded attacker can bypass them.
You could replace the video by an executable probably, I'm sure many users would launch it, especially if the source of the torrent is "reputable" and with positive comments.
Alternatively you could exploit a vulnerability in a codec library or something similar.
Plenty of people download executables on BitTorrent too, so it'd be easier just to target that. Go inject your malware into a popular torrent for pirating the latest version of Photoshop, or Windows, or a popular game.
Both Installer.py and Installer-evil.py result in the same piece hashes, with piece size chosen as 512. The only difference between the files is the shattered pdf fragment, encapsulated in a variable. This fragment starts exactly at the piece boundary, resulting in identical hashes.
I don't actually know the in's and out's of BitTorrent structure but wouldn't that not work as the 2 files would be completely different?
ie: I'd be downloading (and putting together) some blocks of the "real" movie and some blocks of the "malware". I'm guessing the resultant file wouldn't even open?
Video files are purposely made to work even with some data blocks missing. It's the feature that enables video streaming. Valid header is usually enough for video player to at least try to play a file.
If they MPAA could subvert torrents of their property and and replace sections of the footage with just warnings (ruinning the download) i would find that much less objectionable than DRM.
Frustrate the people pirating instead of punishing everyone else.
If such technique would be as accurate as their DCMA take-down notices, I wouldn't be surprised in resulting subverted Linux installations and whatnot.
Not every part of a file codes for its apparent output. Comments, symbol names, whitespace, color tables... for most file formats, there are countless variations of the bytes on disk which produce outputs which are visually indistinguishable.
The trick is to identify this space in a way that lets you efficiently iterate through it until you find a version which matches the target hash.
It's easier just to upload malware to a torrent site. Windows crack, let other people or botnet to download it and suckers will get your malware too. If AV complains, say that is an expected behavior.
New clients could support multiple hash algs, so old torrents would not be a problem. New torrents could provide hashes for multiple algs, depending on the extensiblity of torrent format. Otherwise the torrent sites could provide two URLs or torrent files.
We're at the "First collision found" stage, where the programmer reaction is "Gather around a co-worker's computer, comparing the colliding inputs and running the hash function on them", and the non-expert reaction is "Explain why a simple collision attack is still useless, it's really the second pre-image attack that counts".
This point seems to be getting re-hashed (no pun intended) a lot, so here's a quick summary: there are three kinds of attacks on cryptographic hashes: collision attacks, second-preimage attacks, and first-preimage attacks.
Collision attack: find two documents with the same hash. That's what was done here.
Second-preimage attack: given a document, find a second document with the same hash.
First-preimage attack: given an arbitrary hash, find a document with that hash.
These are in order of increasing severity. A collision attack is the least severe, but it's still very serious. You can't use a collision to compromise existing certificates, but you can use them to compromise future certificates because you can get a signature on one document that is also valid for a different document. Collision attacks are also stepping stones to pre-image attacks.
UPDATE: some people are raising the possibility of hashes where some values have 1 or 0 preimages, which makes second and first preimage attacks formally impossible. Yes, such hashes are possible (in fact trivial) to construct, but they are not cryptographically secure. One of the requirements for a cryptographically secure hash is that all possible hash values are (more or less) equally likely.
The severity between the preimage attacks depends on context.
For Git, for example, a first-preimage attack won't buy you anything, but a second-preimage could be potentially devastating depending on how lucky you get.
If Mallory wanted to make it look like you signed a document you didn't, second-preimage would be devestating. And with the demonstration of two PDFs sharing the same hash, this is a pretty severe one: many PGP signatures, for example, still use SHA-1. But even so, you could take some signature from any point in the past.
If you can do a first-preimage attack, you can do a second-preimage attack. Just hash the document you have. Therefore a first-preimage attack is strictly more severe.
If you can do a first-preimage attack, then just keep doing it until you get a distinct document. I'm not sure what sort of first-preimage attack you have in mind that is only capable of producing a single preimage for any hash.
Since the parent was claiming that first-preimage attacks were strictly more severe, which seems to be a theoretical claim for all possible first-preimage attacks, I was pointing out that doesn't necessarily hold. First-preimage attacks are not guaranteed a priori to be able to produce multiple distinct documents for a given hash.
1) If you have some first-preimage attack against a hash, that attack can probably be "continued" such that it produces multiple preimages.
2) Even if your attack can only ever produce one preimage, since there's an infinite number of documents that can produce the same hash, it's vanishingly unlikely that your attack will produce the exact preimage that you already have (note: this is assuming a cryptographically secure hash, where all outputs are equally likely). Therefore, even if you can only get one preimage, it's still almost certainly a second preimage.
mikegerwitz is technically right. As an illuminating example, consider a hash-algorithm in which there's at least one hash that occurs precisely once. Then a 2nd-preimage attack is formally impossible no matter how much computational power you have (assuming by "second" you meant "distinct second"). But a 1st-preimage attack is formally possible.
A 'good' hash function (exhibiting uniformity) that converts arbitrary-sized documents to finite-sized hashes should not have any hashes that occur precisely once.
This can occur with ill-conceived hash functions, for example if it bundles the length of the document with the hash, so there would be only 256 distinct hashes with length=1.
One of the requirements for a hash to be cryptographically secure is that all possible values are equally likely. So yes, it is possible (in fact trivial) to construct a hash of the sort you describe, but such a hash would not be cryptographically secure to begin with.
It's easier to use and to reason about a uniform hash, but you can design a secure system with a non-uniform hash.
I'd be willing to bet that an altered version of SHA3-256 that replaces four bits in the middle with length%16 is better for most purposes than SHA256, despite being non-uniform.
For that to be the case, in real hash functions, it would require you to be constrained to a certain number of possible preimages, not too many more than the number of possible hashes, so that it's likely that H^-1(H(x)) = x but there can still be a distinct y such that H(y) = H(x).
So I concede that this could be the case under very specific circumstances, but I doubt it makes much difference in the real world.
Getting the first-preimage of the document and hashing that same preimage just gives you back the original hash---it's like an identity function. It doesn't give you a second document.
Edit: I misinterpreted your message. I added "same" above to convey what I thought you were saying.
You seem to be mistaking or misreading something here.
* Collision attack: find X and Y such that hash(X) = hash(Y)
* Second-preimage: given X, find Y such that hash(X) = hash(Y)
* First-preimage: given hash(X), find Y such that hash(X) = hash(Y)
> If you have an encrypted message that you hashed/signed _before_ encrypting, and Eve wants to know what you said, first-preimage would be worse, and second-preimage wouldn't buy you anything.
first-preimage doesn't do anything here. It gets you some text that matches the hash. It's overwhelmingly unlikely to be the original message, and if it's not the exact original message, it won't have any similarity to it. Unless you can enumerate all hash collisions for a value efficiently, which is a much a stronger claim, this isn't any better than brute-force guessing the text.
> Getting the preimage of the document and hashing that preimage just gives you back the original hash---it's like an identity function. It doesn't give you a second document.
The second-preimage attack supposes you have X, the first-preimage attack supposes you have hash(X). If "all" you have is a first-preimage attack, then it's trivial convert it into a second-preimage attack. You hash(X) and feed it into your attack.
Ah good point. It could be that the first-preimage attack gets you exactly X, in which case it fails to handle second-preimage. I would expect this to be incredibly unlikely (especially since they seem to generally involve generating some random garbage). I would also expect most first-preimage attacks have a way to "continue" to a third value, eventually.
A first-preimage attack just means you have H(P), find preimage P (where H is SHA1).
If you found preimage P and wanted another document that hashes into it (so, H(P) = H(P')), you'd have to perform a second-preimage attack and brute-force one. An "ideal" hash function is one where the only way to compute a second-preimage is through brute force. Due to the pidgeonhole principle, there will always be a second preimage---it's just whether it's computational feasible to compute it.
> UPDATE: some people are raising the possibility of hashes where some values have 1 or 0 preimages, which makes second and first preimage attacks formally impossible. Yes, such hashes are possible (in fact trivial) to construct, but they are not cryptographically secure. One of the requirements for a cryptographically secure hash is that all possible hash values are (more or less) equally likely.
True, but the main issue with these proposals is that we want hash functions that are much shorter than the original thing being hashed. For instance, we want every string of length one million bits to get hashed down to some string of length 4096. So those 2^4096 short hash strings can't mostly have 1 or 0 pre-images, in fact on average they have to have gazillions of pre-images each.
As someone who knows only the very basics of cryptography - would verifying hashes of a file using SHA-1 and a "weak" hash function like MD5 provide any additional protection over just SHA-1? I.e. how much harder would be it be to create a collision in both SHA-1 and MD5 than in just SHA-1?
My common sense intuition is that it would be a lot harder, but I'm guessing theoretically/mathematically it's only a little bit harder given how easy collisions in MD5 are?
It’s actually not much harder at all, as first noted by Joux, “Multicollisions in iterated hash functions. Application to cascaded constructions”, 2004.
"For example, by crafting the two colliding PDF files as two rental agreements with different rent, it is possible to trick someone to create a valid signature for a high-rent contract by having him or her sign a low-rent contract. "
Talk about ridiculous scenarios only people living in a tech bubble could come up with.
How many landlords do you imagine know what sha-1 checksums even are, let alone would try and use it as proof the evil version of the rental agreement is incorrect?
"I would have gotten away with it, if it wasn't for you meddling kids and your fancy SHA-256 checksums!"
Obviously the landlord doesn't know or care what SHA-1 is, but he may care if his Adobe Reader says "This file was signed by the Department of Housing" at the top of the screen when he opens the PDF. As Reader fully supports signed PDFs and they do get used, believe it or not, this attack is not theoretical.
The "signing" usually doesn't involve any cryptography. You just express your agreement, which can be as trivial as typing your initials in a box.
It's purely a legal, not technical thing, so if you cleverly forge the document using collisions, you'll be shouting "but the SHA-1 matched!" from behind the bars.
The legal thing does make reference to the technical thing in Europe[1] (and probably elsewhere too), by making digital signatures (which use crypto) legally binding. The question is more how courts would rule in a case where a colliding document is signed. That would probably depend on whether you can prove which of the two parties authored the colliding document (since that's a requirement for this particular attack).
(Note: I don't know whether this attack is practical for qualified electronic signatures as used by EU countries.)
Presumably they're talking about digital signatures. I don't know how common that is in the U.S., but it's used quite a bit in many European countries as a means to sign contracts and such. (I also don't know enough about the implementation details to say whether a colliding pdf file would be sufficient to trick these systems, but let's assume so for the sake of this argument.)
* DHT/torrent hashes - A group of malicious peers could serve malware for a given hash.
* Git - A commit may be replaced by another without affecting the following commits.
* PGP/GPG -- Any old keys still in use. (New keys do not use SHA1.)
* Distribution software checksum. SHA1 is the most common digest provided (even MD5 for many).
Edit: Yes, I understand this is a collision attack. But yes, it's still a attack vector as 2 same blocks can be generated now, with one published, widely deployed (torrent/git), and then replaced at a later date.
anilgulecha is correct. Consider the following attack:
You wish to undermine the security of an important codebase managed by git.
You write a valuable and useful contribution to the code. You also create another version of the commit that has the same SHA-1 as the first, which breaks the security of that code.
You submit the first commit, it is accepted and merged.
Now you wait for your target to do a git clone on the repository, perhaps because it's a build environment. You then MITM it (e.g. using infrastructure like QUANTUM INSERT) and redirect the clone to your own git server, which serves the bad commit.
The target compares the top commit hashes of what it expected to get and what it actually got, and is none the wiser. They now compile the code and produce a backdoored binary.
You need enough leeway in the first commit though. As this is a collision attack, you need to be able to tweak both commits in order to get their hashes to collide.
The mangling in the first commit is probably going to look mighty-suspicious. You might be able to handle this if you get to mangle e.g. code comments. In any case, you need something similar like PDFs malleability where you can change one document without the change being noticeable.
You could (try to) collide one of the blocks at the end of the tree. The tree of hashes will still be the same since the hash of the block didn't change.
Then join the torrent with a client that doesn't download but only upload that block (there will be some that will pick it from you). Many legit copies, except for those that were so unlucky to fetch the block from you.
If you manage to build such a block based on one in recurring content (eg. a distributor's logo at the beginning of the file), it could be reused, too.
> You could (try to) collide one of the blocks at the end of the tree. The tree of hashes will still be the same since the hash of the block didn't change.
Except you can't do that as this isn't a preimage attack. You can't create an arbitrary bad file matching an existing SHA-1 with this.
That means you can't use this to match an arbitrary SHA-1. That means you can't use it to generate bad parts of a larger file.
What you're describing is already possible by having clients connect to a swarm, pretend they have parts of a file, and send gibberish. The receiver won't know until they finished downloading the part and hence waste the part-size in download capacity (i.e. DOS). I bet with IPv6 it'd be really easy to have a single malicious client pretend to be a world of swarm members.
Yes that's my understanding of it. In the PDF example on the site, the file format allows enough tweaking to the raw data without impacting the content to make it feasible.
One of the good parts of doing it at the leaf hashes over the top level hash as proposed further up the thread is that quicktime/avi/etc are much more amenable to carrying some "junk" data than trying to figure out two colliding merkle tries with the same hash.
The initial torrent metadata is pulled from nothing but the first hash. This is the point where the rest of the data forks.. someone gets the movie, another gets the .exe.
That's not an issue with the torrent. That would be with the magnet link format.
Also, and more importantly, this isn't a preimage attack so replacing an existing torrent's SHA-1 hash with a malicious one isn't computational possible.
This requires the addition of random garbage in the first file which someone will detect anyway. Why not release an infected file with a timebomb malware instead of colliding SHA1? Much cheaper. Still, none of this allows you to attack an already existing torrent.
PGP V4 key fingerprints still use SHA-1 exclusively. There hasn't been an update to this part of the RFC as far as I know [1]. Collisions where both preimages are of the attacker's choosing matter less in this context, but who knows what clever attacks people can come up with.
> * PGP/GPG -- Any old keys still in use. (New keys do not use SHA1.)
> * Distribution software checksum. SHA1 is the most common digest provided (even MD5 for many).
Software distribution seems to be the greatest threat (e.g. a Maven repository or Debian repository).
It still seems like an enormous amount of work. You would have to go after a package with an old PGP key and then I guess go spoof a mirror (most of these guys already use SSL so that is a problem). There are probably easier and far more cost effective attack vectors.
>* Distribution software checksum. SHA1 is the most common digest provided (even MD5 for many).
Maybe I'm mistaken, but isn't the purpose of those mainly to verify that you've downloaded the file correctly? At least, the use of MD5 suggests that this is the case.
SHA hashes cannot protect you against the distribution site getting compromised and the hash replaced.
That is why most package manager include a form of cryptographic signatures (e.g. Ed25519 for OpenBSD's).
SHA and MD5 hashes are just used to protect against accidental corruption, not targeted attacks.
No. Signatures provide the same amount of integrity protection. In fact, all practical asymmetric signature schemes sign a hash. If an attacker can control what somebody signs, he can switch out signed documents using this vulnerability.
You can use SHA for this purpose if you retrieve the hashes from a trusted and secured source.
Buildroot does that for 3rd party packages for instance. It downloads the source from the original website (possibly completely non-secured) but then validates the checksum against a locally trusted hash list. Buildroot supports a variety of hash algorithms but many packages still use SHA-1.
To be complete, it should be pointed out that the signature techniques you mention are signing not the document itself but a hash of the document. This attack does allow a bait and switch attack on cryptographically signed documents that utilize SHA-1 as the hash.
If you can switch between the images, you can also switch hashes. Without a signature they serve _only_ for making sure the network didn't barf into your stream.
The GP probably means "that it wasn't corrupted during the download", as there are a few attack vectors for someone who could serve a different file (they could trivially serve a different hash).
You haven't seen my collection of cat pics torrent ;)
Also from a more serious stance the danger is the malware vector or the destruction of the ability to have integrity and not the data in the torrent itself.
and it's super effective: The possibility of false positives can be neglected as the probability is smaller than 2^-90.
It's also interesting that this attack is from the same author that detected that Flame (the nation-state virus) was signed using an unknown collision algorithm on MD5 (cited in the shattered paper introduction).
Schneier predicted "between 2018--2021 depending on resources". He explicitly says "Since this argument only takes into account commodity hardware and not [...] GPUs". Since Google used GPUs that very well explains the speedup to 2017.
I'm trying to play with this in git. Added the first file, committed, and then overwrote the file with the second file and committed again. But even when cloning this repository into another directory, I'm still getting different files between commit 1 and 2. What does it take to trick git into thinking the files are the same? I half expected "git status" to say "no changes" after overwriting the first (committed) pdf with the second pdf?
This is because git adds a header and zlib compresses the PDFs such that they no longer collide when stored in git. But of course, they still collide when extracted from git:
$ ls -l; for i in 1 2; do sha1sum < shattered-$i.pdf; \
git cat-file -p $(git hash-object -w shattered-$i.pdf) |
sha1sum; done; find .git/objects -type f -print0 | xargs -0 ls -l
total 1664
-rw-r--r--@ 1 jay staff 422435 Feb 23 10:32 shattered-1.pdf
-rw-r--r--@ 1 jay staff 422435 Feb 23 10:32 shattered-2.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a
38762cf7f55934b34d179ae6a4c80cadccbb7f0a
38762cf7f55934b34d179ae6a4c80cadccbb7f0a
38762cf7f55934b34d179ae6a4c80cadccbb7f0a
-r--r--r-- 1 jay staff 381104 Feb 23 10:41 .git/objects/b6/21eeccd5c7edac9b7dcba35a8d5afd075e24f2
-r--r--r-- 1 jay staff 381102 Feb 23 10:41 .git/objects/ba/9aaa145ccd24ef760cf31c74d8f7ca1a2e47b0
It's worth noting that either of the changes, adding a header or deflating the content, would remove the collision. The former because this is a chosen-prefix collision attack, the latter because the compression alters the content entirely.
I'm not a cryptographer, so I wonder: do the git header and zlib compression add significant complexity to manufacturing two files that collide inside git?
Probably just as easy. They used a fixed header for PDF and a tweakable middle. So just add the git blob header, as long as the tweakable middle is fixed size.
Git stores the files as so-called blob objects, they're prefixed with a simple header. So even if sha1(file1)==sha1(file2), your git will still get different hashes, because it's doing sha1(prefix+file1), sha1(prefix+file2). You'd need a file that collides with this prefix. This is certainly possible, but not sure if it may mean you need to pay for that several thousand cpu/gpu cluster google used to make it feasible. Maybe there are precomputations that can be reused somehow.
Why wouldn't the header be the same? The files have the same size and same name here? Does it have anything to do with zlib compression (I'd imagine the two files compress differently since they are actually different?)
Even if you use exactly the same headers it means that at the moment the SHA1 algorithm encounters the specially crafted data that creates the collision it's in a different state than with the "naked" files, so the collision (very probably) won't happen. Adding more content at the end of the file would work though, since at this point the SHA1 state machine would be in the same state on both sides.
You can test that easily with the files provided:
$ sha1sum shattered-*
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-1.pdf
38762cf7f55934b34d179ae6a4c80cadccbb7f0a shattered-2.pdf
$ echo 'more content at the end' >> shattered-1.pdf
$ echo 'more content at the end' >> shattered-2.pdf
$ sha1sum shattered-*
42cfb194d7e7d557c00d9f2c8d590641ee8f871c shattered-1.pdf
42cfb194d7e7d557c00d9f2c8d590641ee8f871c shattered-2.pdf
$ echo 'more content at the start' > other-1.pdf; cat shattered-1.pdf >> other-1.pdf
$ echo 'more content at the start' > other-2.pdf; cat shattered-2.pdf >> other-2.pdf
$ sha1sum other-*
ed2ab5fc6c7109a7c7da13fdc05585e4d9e4fe0c other-1.pdf
a41e3539ca0e317a4097bb26ae978e79119d09c8 other-2.pdf
True, but the attack already builds upon modifying the state machine to get the same end result, creating data to allow for a specific prefix (e.g. always getting the desired intermediary state) should also be doable in some form of this attack.
Would it help if we padded the prefix so that the rest of the files are aligned to the block size of SHA1 (512bits), so that the crafted blocks are still block-aligned? Or does the different initial state (due to a different prefix) break any chance of re-colliding with these specific files? (i.e. you'll have to run the full brute force attack again with a valid git blob header as a common prefix?)
That's not the attack on git -- it's the commit ID. You can have two patches that have the same commit. Apply one now, and in the future replace it with the second one, without affecting any other commits IDs afterwards.
But I thought files in git were also identified by the sha1 of their contents? Why isn't there a conflict/de-duplication happening when committing one file over the other? I must be misunderstanding something, but I thought the commit points to a hash of a tree (file list) which has a list of blobs (file referenced by their sha1 sum), how does it know which of the two pdf file blobs to pick out of the blob store?
It's not simply a sha1(contents), but sha1(header + contents); the addition of that header means that SHA1's internal state is different from what it was in the raw PDFs when we encounter the section of the PDF that — without the header — would cause the internal state to align in the two PDFs. So, the header throws things off. But, if you took the header into account, redid the giant computation that Google did, then you could get two PDFs with different SHA1 hashes that, when committed (and thus get the header added) hash to the same thing.
No, a commit is not the SHA-1 of the diff. The fundamental object model of Git does not store diffs, it stores the actual state of the source tree as represented by a commit. For instance, here's a commit file [1]—
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
A commit object just points to the tree object (in turn, another SHA-1, this time of the complete directory listing) and other meta information such as author name etc.
It's semi-relevant to your question, but if you want to learn more about Git internals, I recommend the last chapter of the "Pro Git" book, which is free:
This tool is simply testing whether or not the file has a disturbance vector that makes it a potential file with higher than usual probability to be in a collision
For those of us who are totally clueless about the construction of these hash functions, what is the fundamental flaw in SHA-1 that allows this attack? How do newer hash functions avoid it?
From what I understand, no hash function has ever stood the test of time as some block ciphers have. SHA-2 is of related design and although no one's found an effective collision attack yet, I don't think it would really surprise anyone if one were found. This was in large part the motivation for picking a SHA-3. If you use SHA-3, it's of unrelated design to SHA-1, but it's also much newer and hasn't gotten as much cryptanalysis yet.
Computing a collision today costs about $100K from my reading of the paper. So most uses of SHA1 are protecting documents of far lower value, and would not be likely attack targets (today).
There are many areas of security where you can genuinely get by with obfuscation, hoping the attacker looks elsewhere, or general security-through-obscurity.
You can't in crypto. When the entire system relies on an axiom being true, you need to make sure it's true. The attacks are only going to get better. The attacks are going to come from the future. The embedded systems will not be replaced in time.
SHA1 use cases are not limited into integrity verification of documents, but used a lot for traffic integrity and generation of authentication codes:
- Torrents of all kinds.
- Version control systems (where ability attacks like displacing release pointers become easier).
- IpSec, SSH, PGP and a number of other protected data exchange systems.
Being able to subvert integrity guarantees is a nice building block for complicated man-in-the-middle attacks.
Because if we can drive storage costs much closer to zero (e.g.: a beefed up local server), we can keep storing hashes and the next collision should be much closer. Starting and stopping and throwing away the previous work does work out to $560K per collision, but doesn't it just keep getting cheaper if you keep going?
Eh, at that point you may as well buy the servers yourself and let them run on-premises. Even with power, etc. that cost could easily come down 50% or more. Once you own the servers, additional tasks just cost power.
Say you want to replicate this in 1 month, you need 1320 GPUs for a month. They didn't specify which ones, but say at 1000 bucks per GPU, that's a 1.3M USD investment. And some pocket change for power etc.
There isn't anything new about this result actually, Google just set aside the necessary resources to demonstrate it.
With depreciation over a year, that falls to a USD 100k investment per attack; if realistic to depreciate over 3 years, that falls to USD 30k per replication. Not so expensive on these terms.
Thank you. It took me a while to realize that the paper you're citing is not directly linked in the Google blog article. It is actually found at shattered.io:
71 device years, on an p2.16xlarge instance, I think the NSA could certainly come up with something way moar better in a shorter timeframe, assuming they haven't already done so.
> The time needed for a homogeneous cluster to produce the collision would then have been of 114 K20-years, 95 K40-years or 71 K80-years
If I'm reading that correctly, 852 (71 * 12) K80 cards gets that down to a month, which sounds well within the reach of NSA et al.
Even getting it down to a day (71 * 12 * 30=25,560 cards) seems feasible. Assuming $10k per card ($5k launch price + doubled to account for supporting hardware), the upfront investment is around $0.25 billion, a figure that sounds plausible given, e.g., that the Utah data centre is budgeted at around $2 billion.
Edit: formatting fix. Also, this is of course assuming custom hardware designed for a specific hash function isn't employed.
I was interested if just using standard hardware was feasible due to the flexibility it provides (same hardware to, e.g., forge SHA-1 collisions, bruteforce other hash functions, or run speech-to-text/train ML models on a pretty much unbounded dataset), though I agree anything that is required frequently and/or quickly would probably be moved to specialised hardware.
The writing has been on the wall for a long time, but Linus has been dead against it.
> And we should all digitally sign every single object too, and we should use 4096-bit PGP keys and unguessable passphrases that are at least 20 words in length. And we should then build a bunker 5 miles underground, encased in lead, so that somebody cannot flip a few bits with a ray-gun, and make us believe that the sha1's match when they don't. Oh, and we need to all wear aluminum propeller beanies to make sure that they don't use that ray-gun to make us do the modification _ourselves_.
He says it's not a security issue, so there are no "attacks" to protect against.
> the point is the SHA-1, as far as Git is concerned, isn't even a security feature. It's purely a consistency check. The security parts are elsewhere, so a lot of people assume that since Git uses SHA-1 and SHA-1 is used for cryptographically secure stuff, they think that, OK, it's a huge security feature. It has nothing at all to do with security, it's just the best hash you can get.
Someone has discovered a computational equivalent of bypassing tamper-proof seals, but only a specific brand of seals (SHA1) which is very currently popular. Other types of seals still work fine. This means we can no longer trust if the cake from the baker hasn't been tampered with even though the packaging it comes in has an intact SHA1 seal, we should therefore demand that the baker start using SHA256 seals lest we get poisoned by the delivery boy who wants to steal the shiny PS4 he noticed the other day.
Edit: perhaps delivery boy underplays how costly the attack currently is. Perhaps make the poisoner a person of means who wants inheritance money. As the attack costs go down, even delivery boys will start to afford it, multiplying the risk.
Er, if I'm following your metaphor correctly, you seem to be implying that if I create something and "seal" it, then send it along, that you can no longer trust it because someone may have tampered with it. That is not an accurate assessment of this vulnerability. The attacker needs to construct both the "good" and the "bad" document in order for this to work.
In non-technical terms I guess it's more like getting a document notarized with an embossed stamp or something, and this vulnerability is something that allows you to create a special document where you can get the stamp to apply to two documents at the same time (maybe one of them could be a document accepting $100 inheritence, and the hidden one is a document signing over the title of your house).
It's a bit hard to explain why this matters because most people have no non-technical equivalent of the sort of thing that this would matter for, because people use fuzzy social proofs where forgery isn't out of the question anyway (even notarized documents don't really have any indication of the contents of the document, as far as I can tell).
Some cryptography (everything that uses SHA-1) has been broken and we need to move on to a better scheme. Luckily, we did this years ago because we suspected it could be broken. But unfortunately some people are still using the old stuff so if they haven't switched already they DEFINITELY need to switch now.
If you are talking to the general public, the words 'hash', 'one-way', 'function', 'trapdoor', 'collision' should not appear in your statement.
I don't know. What's your wife's background? If she already knows what one-way functions are, you could just explain that we've found collisions for the first time in an old one-way function that was used for file authenticity but isn't used much anymore because we knew ten years ago we were probably going to start finding collisions in it.
If she doesn't know what one-way functions are, it seems like something that could be explained with examples to an average person who was interested in learning?
One-way functions are not cryptographic hash functions, which have the three properties preimage resistance, second preimage resistance, and collision resistance.
For example, say f(x) is a one-way function. Then define
g(0x) = f(x)
g(1x) = f(x)
Here given some z, it's easy to find another z that maps to the same output, just flip the first bit. However, g is still a one-way function:
Assume we could break g with non-negligible probability, that some program A(y) outputs x such that g(x) = y with probability p.
Then say someone gives us q = f(a) for some a. We can compute A(q) that will either give us 1a or 0a by the definition of g with probability p. In either case we can discard the first bit to find the preimage for a. By contradiction, g is a one-way function.
Google found a way to crack an algorithm designed to ensure the uniqueness of documents, allowing them to be forged. Although it's expensive to do this, the price will fall, and it's a good idea to retreat to a different algorithm that does the same thing but is so much more difficult to break that no one will be able to do so for many years.
Google created a complicated and expensive method of undermining an integrity check, making that integrity check less safe to use. The method will get cheaper and easier to use, so systems using that integrity check have to be moved to integrity checks that are believed to be better.
Assume there is a machine that is giving out unique numbers per person. If person A presses the button twice, they get the same number they got previously. If person B presses the button, they get a different unique number. Now, I searched for a long time to find a person who is not A, but will get the same unique number as A.
So now your wife can agree that the machine does not provide unique numbers per person and is, thus, broken.
You don't really need to talk to anybody about this except people who torrent both illegal and legal torrents.
Torrent poisoning is the most ripe for exploitation and the one with the highest return for a malicious attacker.
So when you talk to someone who torrents, just tell them that the way the torrents verify a file is the correct one is no longer secure, and they have to keep an eye out for the next software update. And if anyone is paranoid, then stop downloading new torrent files, although there is no problem with seeding.
Now that I think about it, I think it is crucial for everyone to keep seeding as much as they can, because it reduces the probability of a bad torrent chunk from spreading as much across the network.
EDIT: Here's a good article that isn't very technical
wont an easy fix be to just hash it again with sha256? Sure that will take time to bake it into software, but wont they just be able to put a text label next to the description and say "sha256: abc...123" ?
> We then leveraged Google’s technical expertise and cloud infrastructure to compute the collision which is one of the largest computations ever completed.
And this, my friends, is why the big players (google, Amazon, etc) will win at the cloud offering game. When the instances are not purchased they can be used extensively internally.
What's the impact to something like git that makes extensive use of SHA-1?
In their example they've created two PDFs with the same SHA-1. Could I replace the blob in a git repo with the "bad" version of a file if it matches the SHA-1?
This is not a pre-image attack, so you can't create a file that matches an existing SHA1. It's a collision attack, so you can create two files whose SHA1 is the same.
So what I could potentially do (given a multi-million dollar budget) is create from scratch two git repositories with different content, whose HEAD is the same. This would allow me to serve different repositories to different users.
What is currently still not feasible is to create a custom git repository whose HEAD matches that of the Linux kernel.
> What is currently still not feasible is to create a custom git repository whose HEAD matches that of the Linux kernel.
Hang on, that doesn't matter though, does it?
I was under the impression that git's SHAs were to be treated as repo-wise unique; not universally. There must non-adversarial 'collisions' across repositories already, surely?
I thought this attack potentially allows creating two commits in the same repo with the same hash - although it may only be possible for these to be root commits.
I don't think there's ever been an example of two different pieces of content hashing to the same SHA-1 before. An infinite number of such examples obviously must exist but they're incredibly improbably to encounter by accident.
> What is currently still not feasible is to create a custom git repository whose HEAD matches that of the Linux kernel.
I'm not convinced that's good enough.
In git, the SHA1 is always the hash of a gzip, which is subject to tricks[1] where a header might be prepared and then some padding inserted to collide a malicious tail.
Nobody's saying it's "good enough". Once we see one attack we expect to start seeing more. What's being pointed out here is that this particular attack does not let you craft custom git repos whose HEAD matches one of an existing repo. Nobody is asserting that to be generically impossible, and this new attack is at least weak evidence that such an attack may eventually be practical.
I think this is perhaps not the case. HEADs move. People contribute code. Sure, if you take a snapshot of every git repo you will ever use today and never move past those commits, this attack doesn't help. Obviously nobody will do that. People, potentially malicious people, will continue to contribute commits which they could have collided with one that does something different. I'd think that using commit hashes as a security mechanism will soon be dead.
No, Git does not hash its internal gzip'd content to produce hashes. It purely hashes the uncompressed content you give it as-is. Any compression like gzip is purely done internally as an optimization and has no impact on hashes.
That was changed early on git's history. Originally, the object was hashed after being compressed; it was changed to be hashed before being compressed.
Linus' answer is correct, as far as it goes, but the threats he considers are only a subset of the real problems.
Laying aside the fact that this attack isn't the one you need to attack a hit repo, and recognizing that the theoretical weakness of SHA-1 (that has been known since (IIRC) before the conception of git) has now become a practical weakness
If an attacker can forge an arbitrary part of a git tree, then if they can poison an upstream repo (we are presuming a motivated attacker given the costs involved), then they can undetectably compromise anyone downstream that clones the repo.
Linus describes in 2006 a trust model where you don't trust remote repos more than your local repo. This isn't how git is used by most users today
Addendum: given a known good repo, an infected repo can be detected by diffing all elements of the repo. A parallel hash scheme with a strong hash function (SHA-3 at this point) could be used, which would easily detect if parties have differing histories by comparing commit hashses using both schemes (both should match!)
We should assume that nation state adversaries may have known this for a while - whether they have acted on it remains to be seen. I suspect it is unlikely for git because it is measurable after the fact (unless you contaminate every instance) I'd be more worried about signing schemes.
Read the 'whole' [not that big] page. The explanation is there, in short: yes.
>How is GIT affected?
GIT strongly relies on SHA-1 for the identification and integrity checking of all file objects and commits. It is essentially possible to create two GIT repositories with the same head commit hash and different contents, say a benign source code and a backdoored one. An attacker could potentially selectively serve either repository to targeted users. This will require attackers to compute their own collision.
Previous brute forcing efforts [1] have fiddled with commit and author timestamps.
If you had seven commits, and two timestamps per commit, and each timestamp could be fudged by 90 minutes without detection, you might not need any dummy comments or files at all.
By design, in case of a collision the new version will not replace the old (older version has preference in case of a collision). Not sure if you could somehow fiddle with the meaning of old and new from the systems POV though.
So, since Git uses SHA-1, does this mean we're going to see a new major version number of Git that uses SHA-2 or SHA-3 in a few years?
I don't expect one overnight. For one, as noted, this is a collision attack, one which took a large scale of power to achieve. In light of that, I don't think the integrity of git repos is in immediate danger. So I don't think it'd be an immediate concern of the the Git devs.
Secondly, wouldn't moving to SHA-2 or SHA-3 be a compatibility-breaking change? I'd think that would be painful to deal with, especially the larger the code base, or the more activity it sees. Linux itself would be a worst-case scenario in that regard. But, it can be pulled off for Linux, then I'd think any other code base should be achievable.
My rough summary: given there is no known second-preimage attack on SHA1, this is not an immediate danger to Git security because of the way Git works. The Git developers do want to move to a non-SHA1 hash at some point in the future.
Linus, from thread:
"I think that's a no-brainer, and we do want to have a path to eventually move towards SHA3-256 or whatever.
But I'm very definitely arguing that the current attack doesn't
actually sound like it really even _matters_, because it should be so
easy to mitigate against."
> Secondly, wouldn't moving to SHA-2 or SHA-3 be a compatibility-breaking change?
If git allows for extra fields in commits and tags (I don't know if it's the case), one could have "tree3" and "parent3" entries on each commit, which point to a parallel sha-3 tree (with sha-3 nodes and leaves) and sha-3 of the parent commit(s). Old git would ignore these entries, new git would use them (and check they point to the same parents/blobs as their sha-1 equivalent). Hacky and ugly, but doable.
About tor: if an attacker produces a public key that collides with the SHA-1 hash of someone else's hidden service, then he would still need to generate the corresponding RSA-1024 private key, which is infeasible as of today.
The two private keys need not be the same; if their corresponding public keys both hash to the same value, a signature from either private key is acceptable.
It's interesting to note that when the first MD5 collisions were discovered a bit over a decade ago, they were computed by hand calculation. Next came the collision generators like HashClash/fastcoll (remember these?) which could generate colliding MD5 blocks within a few seconds on hardware of the time. I wonder how long it will be before the same can be done for SHA-1, because it seems here that they "simply" spent a large amount of computing power to generate the collision, but I'm hopeful that will be reduced very soon.
As for what I think in general about it: I'm not concerned, worried, or even scared about the effects. If anything, inelegance of brute-force aside, I think there's something very beautiful and awe-inspiring in this discovery, like solving a puzzle or maths conjecture that has remained unsolved for many years.
I remember when I first heard about MD5 and hash functions in general, and thinking "it's completely deterministic. The operations don't look like they would be irreversible. There's just so many of them. It's only a matter of time before someone figures it out." Then, years later, it happened. It's an interesting feeling, especially since I used to crack softwares' registration key schemes which often resembled hash functions, and "reversing" the algorithms (basically a preimage attack) was simply a matter of time and careful thought.
There's still no practical preimage for MD5, but given enough time and interest... although I will vaguely guess that finding SHA-256 collisions probably has a higher priority to those interested.
Maybe just writing 2^63 would have been easier to interpret than that huge number in the context of cryptography. (Unless you assume this targets a non-technical audience, which I doubt.)
Pretty impressive, though. And worrying, because if Google can do it, you know that state-level actors have been probably doing it for some time now (if only by throwing even more computing power at the problem).
PDFs with the same MD5 hash have previously been constructed by Gebhardt et al. [12] by exploiting so-called Indexed Color Tables and Color Transformation functions. However, this method is not effective for many common PDF viewers that lack support for these functionalities. Our PDFs rely on distinct parsings of JPEG images, similar to Gebhardt et al.’s TIFF technique [12] and Albertini et al.’s JPEG technique [1]. Yet we improved upon these basic techniques using very low-level “wizard” JPEG features such that these work in all common PDF viewers, and even allow very large JPEGs that can be used to craft multi-page PDFs.
Some details of our work will be made public later only when sufficient time to implement additional security measures has passed. This includes our improved JPEG technique and the source-code for our attack and cryptanalytic tools.
One can insert arbitrary data into JPGs. Given that, the researchers embedded a JPG in a PDF, and manipulated the arbitrary data until it resulted in a collision.
It's still quite impractical, m sure with some quantum computer or a custom ASIC built by those "super nerds" at the NSA its possible but but for you general adversary aka "hackers" (skiddies IMHO) it will be infeasible.
What this means is for all of you [developers], is to start new projects without SHA1 and plan on migrating old ones (if it's totally necessary, normally don't unless you use SHA1 for passwords).
This makes it technically possible to get a backdoored linux repo with the same commit hash.
EDIT: this is wrong, it's not a second pre-image attack only a collision attack. That is, you can create 2 git repositories with the same commit hash, but not a git repo that matches an already existing repo. In other words, you can create 2 things with the same hash, but can't control what that hash actually is.
You might be able to fashion 2 commits to the linux repo with the same hash but a different modification though.
EDIT: My original comment was wrong. Git commit signing apparently only signs the commit hash itself, so it's only as trustworthy as the integrity of the hash. However, see also other comments which point out that this isn't a pre-image attack; you can't find a collision for a given thing (in this case, the linux kernel); rather, you can generate from scratch two pieces of data which happen to collide. Still, this is worrying.
ORIGINALLY (INCORRECT): Git commit hashes were at least never intended as a form of authentication. That's why git has commit signing. That said, they list GPG signatures as one of the things affected by SHA1 brokenness, so maybe even that's not enough? I don't know enough about how git commit signing or GPG works to tell.
The commit object is signed; which contains a signature to both the tree and the parent. I don't see it as feasible to do a collision on both at once with the method outlined here, but maybe I'm missing something.
Tagging on the other hand is at risk, as it's just the hash that's signed.
Edit: You can check what is actually signed with `git cat-file -p $obj` where $obj is a commit or tag id.
It seems that commit object contains metadata and sha1 hash of the commit tree. In other words, signing comment object is not detecting if data is altered somewhere in the tree and creates identical sha1 hash.
Isn't there still an attack where you create to different commits to the linux kernel with the same hash? (I presume here that a git commit hash is calculated over the diffs, not the end state of the repo).
If that is the case, you can still sneak code into the repo, though it would be easy to detect by seeing repos diverge.
When git signs a commit it pipes the entire commit, including the message at the end, and all headers to git. Then it goes back and adds the signature in a new gpgsig header.
I often see people getting this wrong in HN threads. Probably because that's how signed tags work.
I don't think we're likely to see it used for torrent poisoning if it takes 110 GPUs 1 year to compute a collision - the electricity costs for such a rig would be enormous. 110 GPUs * about 300 W each = about 290 thousand kilowatt hours to break. Electricity costs of at least 10s of thousands of dollars. For a single torrent. You better be damn confident that those torrenters are going to go buy your product and that they won't just go to the next torrent down the list.
That said, attacks only get better, so it could happen at some point in the future and it's probably worth switching the hash function used sooner rather than later.
In the case of MD5 collision research, initially it took a cluster of PS4 months to find one. But a few years later a laptop can find a collision instantaneously. So yeah, expect rapid improvement of SHA1 collision feasibility.
Bittorrent is not a static/unchanged old protocol. It has constantly evolved to keep up with any attacks that could be mounted on it's distributed nature.
I'm sure a BEP will also come up, and speedtracked on the back of this news.
This attack required over 9,223,372,036,854,775,808 SHA1 computations. This took the equivalent processing power as 6,500 years of single-CPU computations and 110 years of single-GPU computations.
If you're very careful with your machine maybe you can make it last 6500 years, but I think that is way outside the expected lifetime of a mobile CPU under full load.
Funny, just yesterday I thought about what would be necessary to change and deploy this. Apparently the SHA1 hash wasn't designed as a security feature, but I would not be surprised if it is being abused as one today.
It's not used as a security feature in Git (though SHA-1 is designed as a cryptographically secure hash) but Git commit singing does use SHA-1 b/c GPG.
It's not supposed to be used as a security feature, but I think some tools use it as such. Dependency management tools that reference by SHA-1 hash come to mind. Of course they should have used other primitives all along, but we know how it is..
How do you actually create a collision? The paper is beyond my level of comprehensions. Are we going to see someone writing up an open source tool to allow one to generate another file with the same hash?
It should also be noted that their examples files also have the same file size, in this case 422435 bits, after creating the collision - which I find fascinating!
Forgive my ignorance, but it seems a solution to collision worries is to just use two hashing algorithms instead of one. We have two factor authentication for logins, why not the equivalent for hashed things?
Give me the sha1 and md5, rather than one or the other. Am I wrong in thinking even if one or both are broken individually, having both broken for the same data is an order of magnitude more complex?
The complexity of creating a collision for both hashes is pretty much just a sum of the two complexities. Since the sha1 collision is more difficult, that dominates the cost.
Once you have the sha1 collision, making the md5 collide should only take a few seconds of CPU time.
I don't think that's how averages work. But it's true that relying on the birthday paradox, you can reduce the average. I was just trying to compute the "cloud" cost of 110 GPUs for 1 year (or the equivalent for a day, assuming this is embarrassingly parallel).
I found my mistake g2.8xlarge have 4 GPUs each, so it cuts the cost by 4 (~626k per collision). p2.16xlarge have 16 GPUs (~867k per collision). Exact model of GPU not taken into account, so this could vary widely.
I wish there were sample documents, but if one had two computed hashes would this mitigate this SHA1-shattered flaw ? e.g. good_doc.pdf sha1=da39a3ee5e6b4b0d3255bfef95601890afd80709, md5=d41d8cd98f00b204e9800998ecf8427e ? With the sample project I'm looking at (GraphicsMagick) on Sourceforge for example, it provides both SHA-1 and MD5 hashes...
Only for the case like I mentioned (SourceForge example above) of verifying payloads that only ship with those two broken hashes. Not advocating for publishing new work like this.
Is a 30 day disclosure period really enough for something like this? It's obviously not possible to 'fix' big systems that rely on SHA-1 such as git or github in only 30 days. Hardware devices that use SHA-1 as a base for authenticating firmware updates?
Saying it was shown to be flawed is being nice. It was outright broken 12 years ago as it was shown that you could find collisions with far less complexity that a bruteforce attack.
What has happened is that someone created the code to actually carry out an attack, and showed that it will cost around $110K today.
> we will wait 90 days before releasing code that allows anyone to create a pair of PDFs that hash to the same SHA-1 sum given two distinct images with some pre-conditions
My attempt at TL;DR: SHA-1 works on blocks, and each block is processed and it's data "mixed" with a previous intermediate result based on the previous blocks (Merkle-Damgård construction). A freestart collision only shows blocks and values for the intermediate results which lead to a collision. For a full collision you still have to figure out what sequence of blocks gets the intermediate results to the necessary values.
This is one of the reasons it is important to have multiple hash algorithms in use. Even when a collision can be triggered in two systems, it becomes markedly harder to trigger a simultaneous collision in other systems at that same point (payload).
Looks like a typo. They might have been referring to sucessful cryptanalysis of SHA-1 which seems to have started around 2005 https://en.wikipedia.org/wiki/SHA-1#Cryptanalysis_and_valida... or maybe the BOINC project to create a collision, which did start 10 years ago.
Would providing multiple SHA-1's from both the whole and N subsections (or defined regions) of the byte stream make this impractical... or at this point is the cost just going to drop and make this not relevant?
I get a SHA256 certificate for that site. What user agent are you using? Is there some kind of middlebox on your network, or do you use AV software that intercepts TLS connections?
Fair enough, I was using Chrome "Version 50.0.2661.102 (64-bit)" on Linux Mint. I have updated it to 56.0.2924.87, now I'm getting a full error page "Your connection is not private" NET::ERR_CERT_WEAK_SIGNATURE_ALGORITHM. I need to search for this issue now.
No I'm not using anything that intercepts TLS connections.
If you trust a signer, does this attack do anything to invalidate their SHA-1-based signatures? Or is the scenario strictly an attacker generating both versions of the message?
As I understand it the attacker would have to generate both versions of the message. If an attacker could generate a second message with a hash that matches that of an existing message from a third party, that would be a second-preimage attack, not merely a collision attack.
This only works if the attacker controls both sides, or at least a piece of both sides. That's a collision attack, and it's much easier than a pre-image or second pre-image attack which tries to match an existing hash.
10 million GPUs is not insane when you have a billion dollar security cracking infrastructure budget. Especially when you compare it to the rest of the cyber warfare budget.
Is it coincidental that this GPUs on Compute Enginge were announced recently? This seems like a nice burn-in test and it being completed should free up ressources.
That said the file format was switched pretty early on (2006 I think, less than a year after initial release) to reserve space for 32 bytes instead of 20 for the hash, thus allowing hash migration more easily (sha1 is 20 bytes, sha2 which at the time was the obvious replacement was 32 bytes).
https://www.mercurial-scm.org/wiki/RevlogNG
I believe there is a way to do it so that the MD5 collision would only be 2^64. This is also how MD5 collisions can be created without any special techniques, meaning that MD5 was always only barely more secure than 56-bit DES for example.
Recent versions of Chrome will show a warning if you try to browse to a site that uses a SHA-1 certificate. Mozilla is doing the same thing as of Firefox 51, but they're enabling this gradually to measure impact. Microsoft has an update ready to disable SHA-1 support in their browsers - I think it was delayed a few days ago due to some issues (not sure if they were related to disabling SHA-1).
You can use [1] to test how your browser behaves.
Technically, the sites cannot be said to be vulnerable because of their SHA-1 usage. Rather, continuing issuance of SHA-1 certificates by publicly-trusted CAs increases the risk that someone obtains a certificate that collides with a certificate for a different domain or for a certificate that could be used to sign other certificates for sites the attacker does not own. [2] does a good job of explaining this. The mitigation for this is to use a browser that disables (or warns about) SHA-1 certificates. Publicly-trusted CAs are also not supposed to continue issuing these certificates, but there have been quite a number of cases where they did so anyway - most notably WoSign.
Of course, a site might use SHA-1 for other things behind the scenes. There's really no way to detect that in general.
"as google, we spent two years to research a way of generating sha-1 collisions and made quintillions of computations to generate an example" <- not very convincing or practical. It's like those japanese animes where the nerdy kid boasts about having computed your every move.
`security.ssl.treat_unsafe_negotiation_as_broken` to `true` and `security.ssl.require_safe_negotiation` to `true` also. Refusing insecure algorithms (`security.ssl3.<alg>`) might also be smart.
More generally, there is this fantastic repo on github that lists a bunch of such things that can be tweaked in about:config (mostly from a security/privacy standpoint):
https://github.com/pyllyukko/user.js
Why chance with Firefox? Google has Chrome already safe and clearly on top of things. This is not a static thing as in there will be others with parts of the crypto tool chain or maybe stack?
Worth noting that Facebook stopped offering SHA-1 back in November[1]. Cloudflare still offers SHA-1 for paying customers (via a root certificate pulled from trust stores, i.e. which are only supported on outdated devices/browsers). Not sure about Twitter.
{kind=link}
{kind=link}
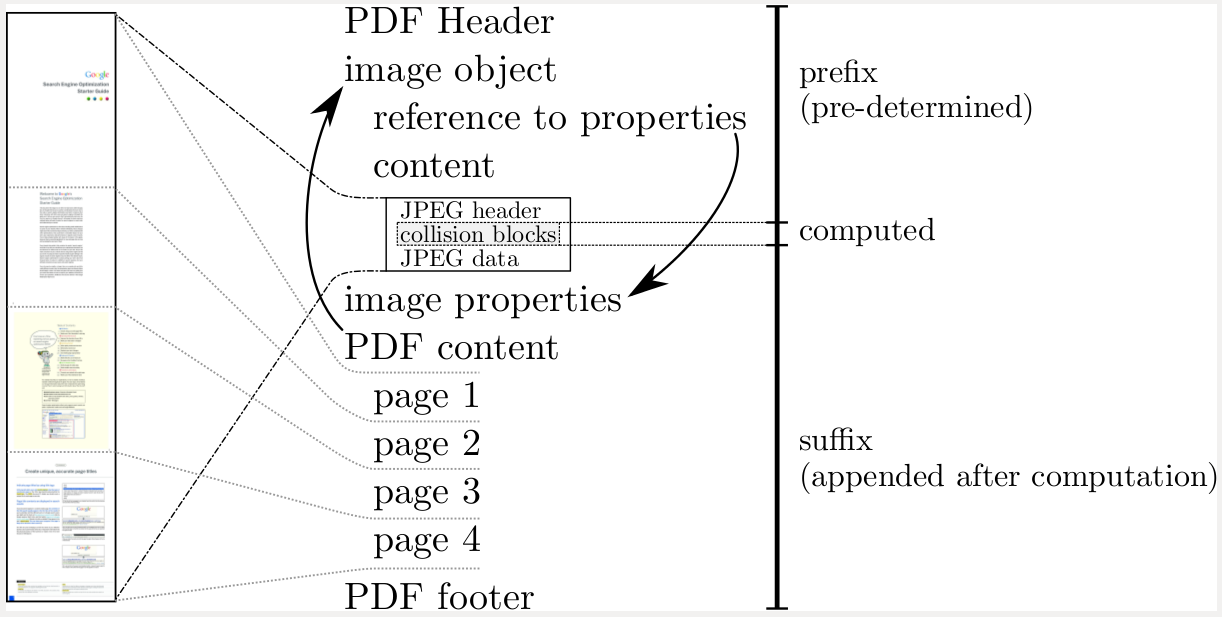{kind=link}
{kind=link}
Basically, each PDF contains a single large (421,385-byte) JPG image, followed by a few PDF commands to display the JPG. The collision lives entirely in the JPG data - the PDF format is merely incidental here. Extracting out the two images shows two JPG files with different contents (but different SHA-1 hashes since the necessary prefix is missing). Each PDF consists of a common prefix (which contains the PDF header, JPG stream descriptor and some JPG headers), and a common suffix (containing image data and PDF display commands).
The header of each JPG contains a comment field, aligned such that the 16-bit length value of the field lies in the collision zone. Thus, when the collision is generated, one of the PDFs will have a longer comment field than the other. After that, they concatenate two complete JPG image streams with different image content - File 1 sees the first image stream and File 2 sees the second image stream. This is achieved by using misalignment of the comment fields to cause the first image stream to appear as a comment in File 2 (more specifically, as a sequence of comments, in order to avoid overflowing the 16-bit comment length field). Since JPGs terminate at the end-of-file (FFD9) marker, the second image stream isn't even examined in File 1 (whereas that marker is just inside a comment in File 2).
tl;dr: the two "PDFs" are just wrappers around JPGs, which each contain two independent image streams, switched by way of a variable-length comment field.