I don't recall where I heard this analogy, but I repeat it frequently.
"Not using a hadoop is like cutting down a forest with a single chainsaw. Using it is like cutting a forest down with unlimited hatchets. It will usually be faster and cheaper with the chainsaw."
I would second this. I've used Hadoop at two jobs, and both times the added overhead in terms of operational and programming complexity wasn't worth it. Most everything could have been done on a beefy machine with the most basic knowledge of parallel programming.
It's definitely a resume builder. The "Teradata" on my resume has sort of gone out of style. Other than cost, though, I've really not run into a practical situation where Hadoop would help me with something that Teradata wouldn't do. I work for large companies that can generally afford Teradata and to scale it as needed (Teradata is awesome when you need to scale easily), so my professional Hadoop experience is near zero.
I read the link and agree with most of it. All except for when he gets to the 5TB part, but I get that it was written in 2013 and probably not to a fortune 500 audience. If Teradata Cloud could get a reasonably priced entry level tier going, I think they'd be talked about a bit more.
I am learning this as part of academics, but I belive Map reduce was introduced for handling google page rank and it seemed to handle it well, so SHOULD I SAY "USE HADOOP BUT IN A SENSIBLE WAY WHERE IT REALLY HELPS" or is it like never use it ?
Since you mentioned page rank, you can also check out graph processing frameworks, eg Pregel/Giraph, which are designed specifically to run graph algorithms on big data.
Replying to this again. Using Scala and Scalding or Spark makes it super simple to do algorithmic stuff. I haven't used Pregel/Giraph ever, so I can't say how it stacks up.
And OP, if you see this, using raw M/R to do things like graph processing is going to be a HUGE pain in comparison to all the libraries built around it.
I started with Hive and worked backwards. It gives you a nice SQL interface and allows you to do M/R operations on CSV files easily. Once you get the hang of it, going back towards raw M/R or even something like Cascading/Scalding might be less of a shock.
If you know Cassandra or other NoSQL, you can try your hand at Hbase. To do anything with it beyond adding or removing data from a key, you'll need to write an application of some sort. Cataloging tweets is a decently simple exercise.
In my work, the only time I accessed the HDFS directly was doing a put/delete of a flat file CSV that I was going to load into Hive. I'm not saying there's not use cases for using HDFS, just that in the set ups I've used, I've never seen it.
But my as its part of my academics, I need to start from scratch that is to learn HDFS and move upwards, so anything that can help me when the situation is like this ?
I read the O'Reilly books on Hadoop and Hvae in 2013. That was helpful, but I still think Hive is a good place to start. If you know how a join and an aggregate work, you can see how Hadoop turns those into into M/R operations.
If you really have to learn how Hadoop works, you'll probably have to look at the source. Write the Hello World program and get it to run on AWS EMR (as others have suggested). Then clone the source to Hadoop and open it in your favorite editor. If you have to understand the nuts and bolts, the source code is the way to go. If you only have to know how to use it, then a book + online tutorial + simple project will get you up to speed within a week or two.
Do you want to learn how to setup Hadoop clusters and Zookeeper etc. on bare metal and understand all the maintenance of such a system. Or do you want to learn how to use the tool for enabling data science projects?
If it's the former, companies like Databricks are becoming popular because they abstract a lot of that complexity away: https://databricks.com/try-databricks
Because you're coming at it from scratch I'd strongly advise you look at the future trend and start straight with Spark. It is also made by Apache and is the next generation solution. https://spark.apache.org/
thanks !! well I'll start with hadoop and quickly understand HDFS and mapreduce by doing small projects like page rank or wordcount and move on to spark soon.
Hadoop ecosystem is ptetty vast. I used the book "Haddop the definite guide" and "Hadoop Security". But I see more and more organizations moving to solutions that augment Hadoop (or even replace it) such as Apache Spark.
I've never seen a customer yet that would prefer a classic map reduce job over a spark app after understanding the performance and developer productivity benefits. But I might just be lucky.
AWS EMR is as others said a great place to get started and you can get Hadoop, Hive, Spark, Presto and other great projects easily installed and ready to go.
Big Data University has several relevant courses and learning paths. They are all free, give you certificates upon completion, and open badges backed by IBM: https://bigdatauniversity.com/courses/
In general, after you get some Hadoop fundamentals, I would recommend focusing on Apache Spark instead.
Disclaimer: I'm part of the Big Data University team.
Do you want to learn how to use a tool or how to solve some specific kind of problem?
If resources are what you were expecting, Coursera used to have a course named "Mining massive datasets" that covers some of the topics I saw you mentioning in your comments (MapReduce, HDFS, PageRank etc). It was ministered by Jure Leskovec, Anand Rajaraman and Jeffrey D. Ullman.
That answer could go a number of directions depending on your level of experience. I would say find a problem you need a distributed system before and then as said previously, use AWS EMR. If you're more interested in the infrastructure side of things than its always a good experience to setup a cluster from scratch.
Start with a higher level interface and work backwards? Possibly something like Hive/PIG/MRJob, get familiar with them to wrap your head around MapReduce.
Past the scope of your question - but I'd also recommend learning Spark as well, it's probably more relevant and marketable at this point than learning pure Hadoop.
But my as its part of my academics, I need to start from scratch that is to learn HDFS and move upwards, so anything that can help me when the situation is like this ?
I was thinking about this today and stumbled across hortonworks sandbox which is a whole bunch of big data stuff including hadoop set up to run on a vm with a load of tutorials built in. Seems like it would be worth checking out!
I started an open source project for NoSQL training in all Big Data and machine learning technologies [1]
We have not done Hadoop yet - is there anyone that would like to help? We are considering crowdfunding to pay for all trainers so that the videos and book would be free - or should we charge per course?
Hadoop's source code has been on my reading list for a long time now. I have tried it before, but couldn't go through all the bits and pieces. Is there any strategy you should follow while reading any source code? Are there any code walkthroughs of hadoop's source code?
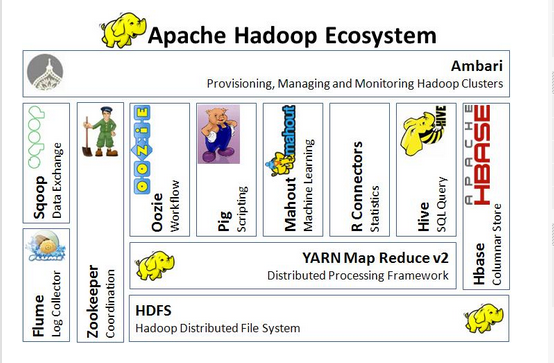
I would recommend first of all that you get familiar with the names and versioning. Hadoop is a mess, and its basically a family of big data projects.
You have two/three main components in hadoop:
- Data nodes that constitute HDFS. HDFS is Hadoop's distributed file system, which is basically a replicated fs that stores a bunch of bytes. You can have really dumb data (lets say a bunch of bytes), compressed data (which saves space but depending on the codec you may need to uncompress the whole file just to read a segment), arrange data in columns, etc. HDFS is agnostic of this. This is where you hear names like gzip, snappy, lza, parquet, ORC, etc.
- Compute nodes which run tasks, jobs, etc depending on the framework. Normally you submit a job which is composed of tasks that run on compute nodes that get data from hdfs nodes. A compute node can also be an hdfs node. There are alot of frameworks on top of hadoop, what is important is that you know the stack (ex: https://zekeriyabesiroglu.files.wordpress.com/2015/04/ekran-...). So you have HDFS, and on top of that you (now) have YARN which handles resource negotiation within a cluster
Since hadoop jobs are normally a JAR, there are several ways of creating a jar ready to be submitted to an hadoop cluster:
- Coding it in java (nobody does it anymore)
- Writing in a quirky language called Pig
- Writing in an SQL-like language called HiveQL (you first need to create "tables" that map to files on HDFS)
- Writing generic Java framework called Cascading
- Writing jobs in scala in a framework on top of cascading called Scalding
- Writing in clojure that either maps to pig or to cascading (Netflix PigPen)
- ...
As you can imagine, since HDFs is just an fs, there are other frameworks that appeard that do distributed processing and that can connect to hdfs in someway:
- Apache Spark
- Facebook's Presto
- ...
Back to your question, I suggest you spin your own cluster (this one was the best I found: https://blog.insightdatascience.com/spinning-up-a-free-hadoo...) and run some examples. There's alot of details about hadoop such as how to store the data, how to schedule and run jobs, etc but most of the time you are just connecting new components and fine-tuning jobs to run as fast as possible.
Make sure you don't get scared by lots of project names!
{kind=link}
{kind=link}
(although it might look good on your CV)