One of the comments I always have when I see environments like this is that it looks really neat to have all these adjustable sliders and partial debugging and whatnot, but when you attempt to apply this to any truly useful program (ie: Anything that performs side effects) it really starts to break down if that side-effect isn't idempotent, like writing a file to a disk, or making a network call you really only want to make once, etc.
Do you have any strategies for that, or is the idea that these features are really only for testing functions that don't cause those sorts of side effects?
I wonder if the debugger could be combined with a really good mocking framework. That seems like a good idea for a "live" testing framework. Maybe that's something that could be used to help prototype unit tests themselves.
(First congrats on a great looking project and really good copywriting/teaser.)
I think this sort of highly interactive environment is best suited for languages without side effects at all.
I.e. purely functional language as you see it in a spreadsheet.
Allowing any language (JS, Python and so on) gives problems with how to handle errors, show variable values that change over time, how to handle programs that take a long time to evaluate (or never evaluates), how to handle programs that modify the environment (i.e env.x = env.x + 1) and so on.
A lot of Carbide's widgets depend on having access to a program's parse tree, which (to the extent of my understanding) a lot of these protocols (Jupyter/MS's Language Server Protocol) don't provide.
In order to inspect an expression, we have to be able to take the document, parse it into an abstract syntax tree, determine branches which are expressions, and annotate them so that a code generator can wrap it in some log invocation.
It'd be great if it were possible to apply "one simple trick" and support a hundred different languages all at once, but in this case I don't think the existing abstractions really suffice.
You've done a wonderful job. It takes courage to think in completely new directions, actually do something about it and then give it away- like a Buddha.
Sorry about the naysayers. Please remember that most of us on this forum are wannabes trying to one-up each other to make up for our failures. Don't blame us, we're all humans... :(
It looks like y'all are really aiming for Bret Victor-style direct manipulation, which is a bit more ambitious, but Tonic has incorporated some similar ideas, including time-traveling debugging, and it seems like there's a lot of overlap around the more basic features, like the automagical approach to packaging and the data visualization stuff.
I think Tonic is great, and the stuff they've done with CRIU for pausing resuming computation is really clever. On the surface, Tonic is meant for building NodeJS services, whereas Carbide is focused on things which run in the browser.
One aspect of Tonic that I find really interesting is the attention they've paid to reproducibility.
Traditional notebook programming environments (Mathematica and Jupyter) are sensitive to the order of execution of the cells, which often makes it kinda hard to reproduce results. This stems from the fact that cells are used for two things— controlling what gets executed, and as a means for visualizing output.
As far as I'm aware, Tonic is designed so that there is only one way that a program can execute, so there's any notebook is automatically trivially reproducible. This has the side effect of making every notebook essentially equivalent to a single file which is evaluated in-order. Essentially, they've made it so cells only mediate what output is displayed, and not what gets executed.
Carbide takes the opposite approach— leaving cells to only control what gets executed, and introducing something else (probes) to visualize output within a cell.
I know it sounds crazy, but hear me out. I would love to hack on adding VR support to something like this. A real Minority Report development environment is something I've always dreamed of having.
No promises, but I can't get experimenting without source. Wink :).
This is something I dreamed about it too, another thing I dreamed about was speaking what I wanted and the computed programmed it for me. I think I might be closer to telling the computer what to develop and have it open up in Carbide then the first idea, because I'll probably need a Unity behind the Carbide and I don't want that, will be heavy as hell.
This looks great. I really love tonicdev [1], but I'm reluctant to use it on production data because it's SaaS [2]. If you open-sourced this and I can run it "behind the firewall", that would be awesome.
[1] https://tonicdev.com
[2] I don't want to share production keys with Yet Another SaaS
I'm normally pretty cynical about these sorts of efforts but this seems pretty compelling.
One pet peeve about the site, please consider adding a "Who" section or note. One of the first things I look for in an interesting site or project is the "human face" of it, so to speak.
> We're thinking of releasing Carbide as open source in the coming weeks if there's a community interested in building stuff on top of it.
I'm really interested in things like Carbide, and I'm finding it inspirational as a user interface experiment. But I'll be sticking with Jupyter for the time being on my current project — I think we would be kind of dumb to build stuff we cared about on top of it if it's not open source; without open source, you don't have a community, you just have consumers.
FWIW the jet-engine mode is still active on my laptop now.
Great job, I think the idea of adding different languages or widgets should have an "App" concept were people plugin technologies. That way there can be various githubs of projects separate from the main project were people contribute at free will, that would be really awesome and great for the project.
Best Regards,
The page is surprisingly uninformative. It took me good 5 minutes of looking for "download" button before realizing that it's an in-browser IDE. A big "Try it now" button on top of the page would do wonders. A short, one sentence description of what it is would also be helpful, because "new kind of programming environment" reminds something from managers' meeting slides. Anyway, good job and thanks for making it available to us, I was looking for something like this few months back, I'll sure give it a try.
Yeah, I saw ⌘-Enter in the bottom-right of every example and immediately thought "too bad I can't even try this on my machine". But I kept scrolling and clicked one of the "Example Notebooks" half-expecting it'll download a project file or something but luckily it turned out to run the editor in my browser.
"We haven't launched support for other programming languages yet (rest assured it's on our roadmap)"
"Our roadmap" is a link, but does not work… There however is a "Future" section near the page bottom, with screenshots that indicate support for Python, MIT Scheme, and something called Watlab.
It seems that the author addressed that in the very first bullet point on that page:
> Carbide is a new kind of programming environment which (as obligatory in this day and age):
> • Requires no installation or setup
(It's also followed by the mention of Javascript and all the browser screenshots reinforce the point.)
The first analogy that came to my mind is that this is a similar environment to Wolfram Alpha but more focused on experimenting around with programming concepts.
Looks like a cool project, but I can't scroll very far down the site before my browser crashes. I've reproduced this several times, here's the terminal output if it helps:
$ conkeror https://alpha.trycarbide.com
......
JavaScript strict warning: https://alpha.trycarbide.com/, line 603: SyntaxError: test for equality (==) mistyped as assignment (=)?
JavaScript strict warning: https://alpha.trycarbide.com/, line 604: SyntaxError: test for equality (==) mistyped as assignment (=)?
JavaScript strict warning: https://alpha.trycarbide.com/, line 605: SyntaxError: test for equality (==) mistyped as assignment (=)?
JavaScript strict warning: https://alpha.trycarbide.com/, line 606: SyntaxError: test for equality (==) mistyped as assignment (=)?
JavaScript strict warning: https://eponymous-labs.github.io/carbide-splash/static/main.js, line 162: SyntaxError: in strict mode code, functions may be declared only at top level or immediately within another function
JavaScript strict warning: https://eponymous-labs.github.io/carbide-splash/static/main.js, line 201: ReferenceError: assignment to undeclared variable diff
Console error: [JavaScript Warning: "window.controllers is deprecated. Do not use it for UA detection." {file: "chrome://conkeror/content/window.js" line: 331}]
Category: DOM Core
Segmentation fault
I know how this line of defense plays out with my customers if their customers' browsers segfault on a page I wrote...
I fix the page ASAP to prevent the segfault and then file a bug to the browser developers. If I don't, I lose the customer and somebody else will fix the page anyway, maybe not filing the bug because it doesn't make money.
Just how do you "fix a segfault" in your page? Do you immediately replicate the user's exact computing environment, all down to the specific operating system and perhaps browser plugins which might contribute, install a specific version of the this obscure browser (Conkeror?) with debug symbols, fire up GDB and understand why the complex C++ crashed based on the core dump?
That seems like an unlikely amount of effort. IME If you have some "enterprise" tool with enterprise clients, there's typically going to be a list of browsers which are supported and tested by QA.
Having been in similar situations, I think he means that he does indeed replicate the bug (which isn't usually as bad as you make it sound) and then write different code that doesn't trigger that bug in the browser.
It isn't always possible, and in that case we do blame the browser in the end, but it usually is possible to work around it. It's ugly, but it's necessary to keep your customers happy.
I think that something like this will probably be the future of programming, but Carbide itself needs to dial it back and focus on which data visualizations give the biggest bang for the least obtrusiveness.
Apple's been moving in a similar direction with Swift playgrounds, and recent Java IDEs (IntelliJ, and I think Eclipse) will display the values of variables next to the line of code when you pause in the debugger. These are both useful features. They get cluttered really quickly, though, and in the playground case take you out of your normal development flow.
If you want this to be impactful, focus on delivering information at your fingertips without delivering information overload. The core idea of being able to inspect & manipulate run-time values alongside the code that generates them is sound. The implementation - with lots of fancy gadgets that overshadow the code itself - needs some design love.
> I think that something like this will probably be the future of programming
Wait, no, that can't be. Maybe the future of programming for a subset of tasks (like UI programming). What I'm doing in 95% of my time does not benefit at all with 'visual programming'. Displaying values when you stop the debugger is completely different and also quite limited in my case, because I'm working with distributed systems, heavily multithreaded programs, etc. -- as many-many other devs. In these cases, this kind of visual programming doesn't make too much sense (or I can't see how it would).
Visualization is a very 'local' thing, it helps you understand the narrow context of what you're working on, but when working with large systems, you need to have the map in your head. Or something like that.
(Note: I think this is cool, I'm just arguing with the notion that this is the future of programming. It's a bit like saying that the future of mathematics is gnuplot. :) )
I'm finding that an increasingly large portion of the programming I do involves:
a.) Looking at data graphs to understand the "shape" of my data, eg. plugging a distribution into Weka, Matplotlib, or Kibana.
b.) Looking at examples of this data, eg. running a SQL, Dremel, or ElasticSearch query or visiting a source website.
c.) Inspecting the state of my UI, eg. via React DevTools or Chrome Inspector.
d.) Looking at the internal state of my algorithms, eg. if I'm writing a parser, which state in the state machine am I in, what's my current input token, and why does the code think that it should switch to a state other than the one I expect?
Even for distributed systems, this stuff is important. I spent 5 years at Google, and the best distributed systems engineers there never went with their intuition, they measured. Google had some wonderful tools to trace & visualize the set of RPCs that would be kicked off by a user request, including all latencies and where the critical path lay. I really miss having them now, and distributed systems work would be much easier if that information was inline with your function calls.
I believe that these categories of work - data science, distributed systems, increasingly stateful UIs - will become increasingly important in the software industry of the next 10-15 years, so yes, I do think this is "the future" of programming. It won't be everywhere, and it will take time to figure out how to represent this in a way that's useful and reduces development friction, but it'll be an increasing growth industry.
>"Visualization is a very 'local' thing, it helps you understand the narrow context of what you're working on, but when working with large systems, you need to have the map in your head"
This reasoning is equivalent to "a car is great for getting across town, but if you're travelling long distances you need to have a horse-drawn vehicle".
Just because the current wave of "visual programming" approaches (which are taken directly from Bret Victor, who works on these types of programming issues, with little if anything added) only solve problems associated with more UI-centred tasks, doesn't mean they have to stay there.
If you're able to keep a mental map of the system structure in your head it means it can be visualised in some way. I agree completely it needs to be done in a way that is context-specific (which is why the current solutions wouldn't help you, as they're not specific to your context).
It's interesting that you're bringing this up, though, as there's clearly room for expansion of this for programming situations that aren't things centred around stuff like UI. I'd actually love to see a visualisation specifically tailored to multithreaded programming
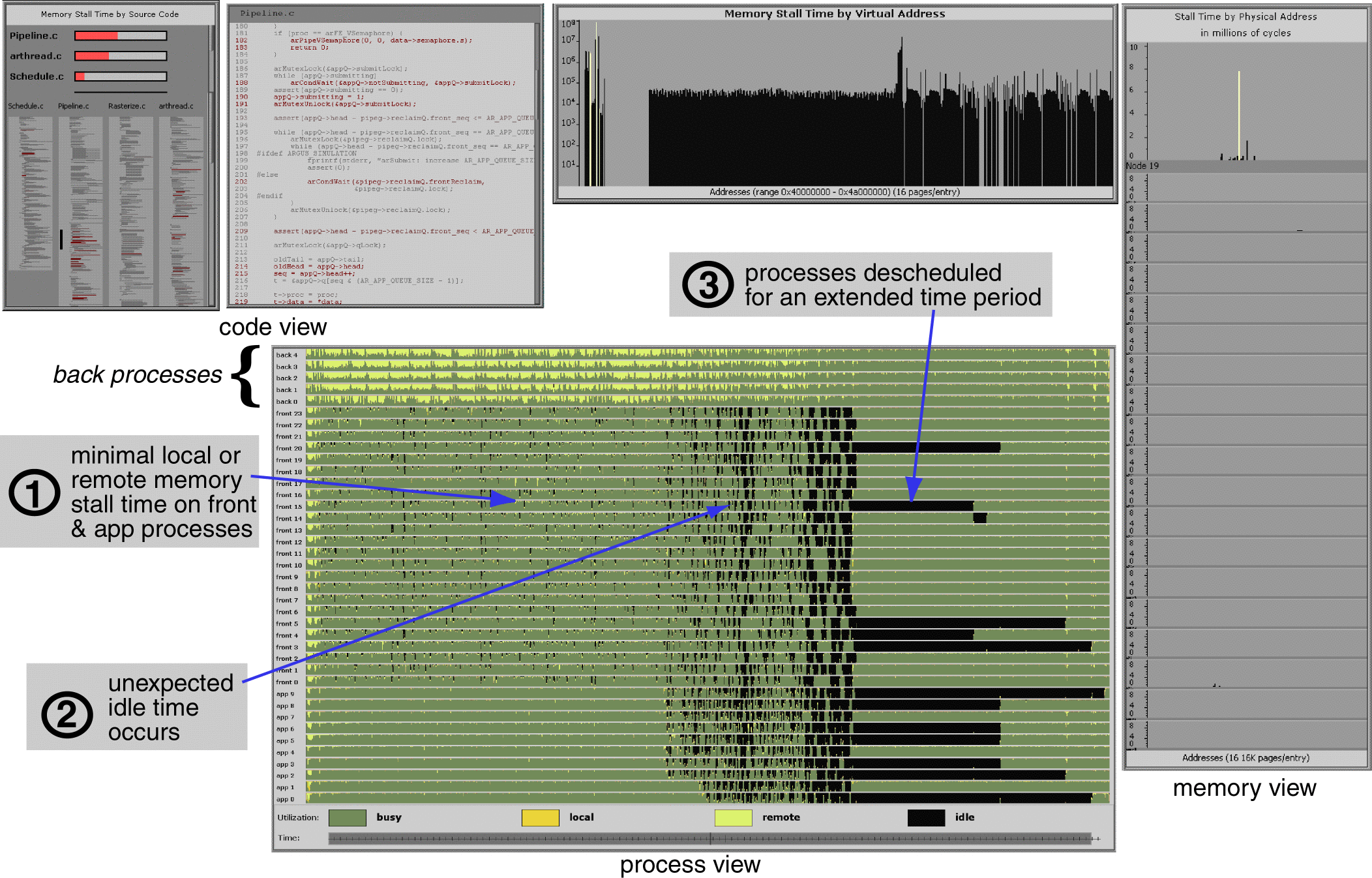
There was a whole research project at Stanford (Rivet - https://graphics.stanford.edu/projects/rivet/) which combined visualizations of code and hardware during execution and was able to keep history (here's an example where they were looking at memory stall issues -https://graphics.stanford.edu/projects/rivet/images/mview.gi...). And importantly, all the data and views were linked - for example, selecting a region of time when the CPU was stalled for memory would highlight the particular code in the source view that was currently executing. The system was used to analyze mobile networks, memory profiling, superscalar processors, and even debug the design of a GPU.
As an aside, a subsequent project in the lab called Polaris, built on the same system, became the precursor to Tableau (a business intelligence tool).
The power of visualization is that it can take abstract data and map it to visual features that our visual system can make sense of automatically without much cognitive load. An example I often like to give - imagine you were searching through my comment to count the number of 'e' letters. You would have to perform a linear scan. But now imagine the 'e's were red. You would almost instantaneously be able to jump from 'e' to 'e' and count them.
Fantastic set of info thanks! I especially love the linking idea; I think it's key to understanding things from multiple perspectives, especially if you're the only one/one of a few working on something.
Yeah quick visual decoding definitely needs to be the point of any visualisation. Its core intent should be to impart clarity, particularly when it comes to large datasets, because unlike machines we just can't process a lot of data in its raw form.
Sadly, many visualisations seem to miss this and sometimes even further complicate things.
Yes, exactly, the linking is really important. You can think of visualization as a mapping from an arbitrary space representing data to a 1d or 2D space representing pixel or image coordinates. That's what most charting software can do easily. However, the reverse transform is as important for interaction, and enables the user to work with the data instead of pixels on the screen. It's similar to Bret Victor's ideas around interacting with live code - without the inverse transform this becomes very difficult, as the user then has to compute it mentally - either by looking at the axes and legends in the case of charts, or the source code/variable viewer/stack view in e case of code, before going back to the original data.
While contextual information is also important, a lot of different abstract data types can be mapped to a fairly basic set of chart types (bar graphs, line charts, and scatter plots can handle most categorical/numerical/temporal combinations). For example, in the memory stall example above, there are only 2 types of visualization - bar charts and the source code views, yet in combination they provide various projections of a 5 dimensional space ('code position' x 'memory address' x 'processor' x 'metric[memory stall time]' x 'time'). The main issue is there is no easy tool to quickly construct/deconstruct multiple different projections of a high-dimensional space with linkage between them (here's a 2007 survey - http://www-devel.cs.ubc.ca/~tmm/courses/533-11/readings/cmvs...)
Definitely interesting. The best visualisations can encode information in multiple dimensions though, often as high as 5 or 6 (Minard's graphic of the march of Napolean is probably the most well-known example, encoding data in about 5 dimensions I think: https://images.thoughtbot.com/analyzing-minards-visualizatio...)
That linking logic is an interesting point though... you almost need a Flow-like system that can link the data display of one visualisation to another (or all the others). A tool like that would be very useful.
Well, Minard's graphic is actually 2 charts - the top one maps distance/abstract geography (2 dimensions), size of the army, and time/direction of movement. The bottom one maps the temperature to time during Napolean's retreat. It's tough to encode more than 3 separate dimensions on a chart (usually 2 spatial axes and a color/shape/size axis) and have it still be useful for analysis/presentation.
> (...) without delivering information overload (...)
This is something I guess I'm of opposite opinion to you. I love the ideas Carbide shows, but for the "future of programming", I want those to be tools, not toys. The concept of information overload is something that shows up when your primary focus is selling something to people, as opposed to build something actually useful for them.
Consider e.g. the cockpit of an airplane, or a dashboard in a powerplant. Those are cases of - by modern UX standards - extreme information overload. But they are so "cluttered" for a reason - the user has to make a bigger investment initially to learn what is where, but then he's capable of much more efficient work. For the same reason, Tufte argues good information graphics are data-dense - if your goal is to learn or explore the data, it's better to have it all visible simultaneously.
I don't disagree, but a key point is contextual relevance. "Software engineering" consists of many different discrete tasks; I want information relevant to data science when I'm looking at data, while I want information related to internal program state when I'm debugging a complex algorithm. Integrating them together with the development experience - and predicting what is most useful when - will be challenging.
> I think that something like this will probably be the future of programming
Not a chance: Carbide still relies on textual programming languages.
What's the most popular programming environment in the world? Spreadsheets, which are visual.
If you want billions of new people to be doing "programming", then the Unix-based, textual programming paradigms we use today aren't going to cut it. Most people cannot "blindly manipulate symbols" in their head (as Bret Victor memorably put it), and Carbide doesn't change that fundamental fact.
It's nice to see people doing something new (I'm all for innovation), but let's not kid ourselves that this is a game changer that will bring new programmers into the fold.
This is not something I want; if a product I use is available only via a web site and the company goes under, the product goes away with it. If it's installed on my hard drive, I can keep using the product.
I'd probably forget about it for that reason too. I mean, literally forget.
My bookmarks and bookmark toolbar are littered already. If I could download it I'd have more of a chance of being reminded to see it and use it. Plus I'd feel it'd be more secure, and I'd be able to work when offline (e.g. commuting/travelling), so I wouldn't use it for those reasons.
It looks like it has some interesting ideas though (I especially like the look of the nested debugging thing with probes).
This looks like it could be cool. I'm mostly a plaintext editor kind of programmer but a IDE that helps me get my job done better would obviously be the better solution.
There's... a lot happening here though. What does:
> Comments live in a Rich Text sidebar #LiterateProgramming
mean? I played around with some samples and it seems that there's a method for displaying text or something?
I was hoping it'd be an inline `// yeah I know doing +1 looks wrong but it's because` --> automatic transcribing over to a sidebar but I don't know what's actually happening.
What does:
> Imports modules automatically from NPM or GitHub
mean? Does it mean "import" in the sense that you don't have to write the import statement, or in the `npm install` sense? What happens if I misspell a package name and there is a malicious package under that name? Will it auto install and auto run the post install scripts??
When did rich text and literate programming become synonymous? It seems to have been very recently.
The best literate programming environment around is emacs org mode and it's plenty text. I'm pretty sure Bjarne Stroustrup would be a plaint text kind of guy.
I was pretty excited about LightTable (which has some similar ideas) when it started out, but then Chris Granger went on to another project and LightTable was left hanging. They open-sourced it, but developer uptake was slow initially and there wasn't much progress. Commits/pull requests seem to be better now (2 years on), but e.g. the blog is still very much inactive, and the last release is more than half a year ago.
So for me, I'd only try yet another IDE if I have enough confidence that it will live long enough. The commitment of the original team is of course a big factor, but as was seen with LightTable and other projects, that can change quickly. So I would require that either
- it is commercial and has enough investment/backing,
- it is open-sourced and gets enough dev uptake quickly, or
- I believe so much in the concept that I'd try it even if the other two points are not satisfied.
Speaking of functionality, however, there isn't any mention of refactoring capacities. To me, that's probably the #1 feature why I'd use an IDE instead of just an editor in the first place. I'd consider the in-place partial debugging display only as a nice add-on, but nothing I would throw out a mature IDE with proper refactoring, search (for definitions, references) and other typical IDE functionality for.
I'm curious about how the backwards computations work - how do you detect when the backwards computation can be easily calculated? For example, if we hash some input string and then change the value of the hash, it should be very difficult to do the backwards computation.
Does it literally do gradient descent on the input to try to match the output (as is suggested by the backpropagation terminology?) Can it handle discrete valued outputs?
I read further down the page - they use a quasi newton method to find inputs that minimize the (squared?) distance between the desired output and the output of the guessed input.
I guess this can only really be expected to work well when there is a input that perfectly matches the output in a convex neighborhood of the starting point. Pretty cool!
Looks like they also have support for a few other types of data, but it's not described in the documentation. Apparently there is support for the backwards computations on strings, nested objects, and you can declare inverses for functions. There's also something mysterious called "cascading approaches".
I'm super interested to know more about how this works!
Second - I'm at a loss for exactly what it does. Sorry. I get the 1000 mile-high view, and I get some of the super specific examples. But I'm not sure how it applies to most js progamming which is much more mundane than the very specific examples given.
Maybe you could add a section that takes a much more 'basic' introductory approach?
https://alpha.trycarbide.com/new is the link to try it out. Not sure why it's getting so much hate, the widgets are just icing on the cake, it's like tonic.dev on steroids. You only need to look at the Python community to see how powerful notebooks can be.
This seems like a really cool idea. Sort of like Jupyter notebooks the way they should be done.
I agree with the sentiment that the website could be a bit more comprehensive. I saw "requires no installation" immediately, but then I started looking for a link to actually try it out and couldn't find it. And only then I realized that you can only try it on example notebooks. Or can I write my own code and I just didn't find the way to do it?
I tried a couple of example notebooks and unfortunately it was painfully slow to do anything. XOR network cell took some 5 seconds to process. Typing code was laggy, sliders took really long time to update etc. The C-Enter shortcut didn't work, I had to click the button with my mouse. So it seems like you have an awesome project, but it still needs some work.
Pretty much. This IDE looks more polished on the visualization side than others, but JS is the foundation? That's just not gonna work. The language wasn't built with this kind of thing in mind.
it's one thing to be short sighted, and another to be realistic given a bevy of similar past projects that went nowhere. When was the last time you heard about Lighttable?
The Lighttable team realized they were on the wrong path. Eventually, the semantics of imperative languages are completely at odds with the goals of a supercharged development environment like this. That's why they pivoted to Eve: http://github.com/witheve/eve
I'm sure the Carbide guys will figure that out on their own.
You know, my first instinct was - "oh my god, another web IDE, this sucks", but this thought was immediately replaced by "if that's what is the best way to rapidly develop a prototype and distribute it to large audience, then so be it". Someone later (or they themselves) may steal those ideas and redo them in a more "production-quality" environment, but what we need right now is ideas and prototypes to test and explore.
Every time I see a project in this space I wonder why I never got to finish a similar (in spirit) one I had. Multi-language REPL (with "data translation" across languages for specific data types, so you could pass a javascript array to APL, or load a CSV file as a function in APL and send a column as a Javascript array) and built in visualisations for standard types (a matrix could show a heatmap, for instance, vectors barplots or sparklines, specific arrangements of JSON were chord plots).
The goal was just to make a tool where small-scale data munching was easy (so you could get a plot of a small timeseries right now, no matplotlib, no ggplot2, no gnuplot: just having the variable on the screen meant the graph was there automatically) and as painless as possible. Of course, I didn't advance much because I needed to rewrite everything that I had working so it was easy to extend, and I found another shinier thing to work on... But that still sits in my "someday" code folder.
For now, Apache Zeppelin is almost there in terms of what I want, and has spark in it so...
I've had that dream as well, although skipping the multi-language part. Something like an RStudio for python combined with Tableau like interactivity on manipulating and visualizing data (why would you limit yourself to static graphs on a computer, especially when the system already has access to the data!!).
If you can share, what was the shinier thing you found?
One of the things I've been thinking about lately is what are the languages that lend themselves to "true" livecoding. Like what if you want to change the class hierachy while you're already in a game and the objects are moving around? What if you wanna move a door in the in game editor mid-level but merge this edit back at the start of the level?
Turns out livecoding and live property editing interfaces are an entry into thinking about the next question: what are the abstraction and logic storage models that allow for very radical live coding changes as your app is still running and help you explore?
So far I have liked the idea of prototype inheritance but with the objects stored in a reduxy immutable situation. It seems to get at both the functional and OO side of the "expression problem."
This is feels somewhat similar to Swift's playground.
I think every language should have something like this. Now that we've been compiling and highlighting errors in real time for such a long time, it only makes sense to do the same at run time and provide real time visualization of the program in action.
I love instant feedback, it really changes the way you can create code because your cognitive system is unloaded of many assumptions to rely on real results (in-place evaluated feedback). For someone that used to work in Smalltalk this is a move in the right direction in IDE design.
On a mobile webview I noticed that the auto play video took over the screen and opened several instances that I had to keep closing one after another. I didn't get much further after that.
OK. I don't know if Carbide was designed for this or not but I suddenly had a vision of a data viewer widget that is just an entire notebook system with a custom initial state. That would be pretty handy and I could imagine folks chucking it into a web page without extensive work.
For applications I have no expectations that these kinds of systems scale up or give the touted wins. But they are great for easing the exploration process.
This is great. Tools like this are useful when exploring a problem, it's very handy to have the instant feedback. Using the widgets to tweak things is also very cool, I could definitely integrate this into my workflow ( if I can install it locally ).
Feedback: I did not want to read all the texts (it's too much) and just wanted to try it out. But I couldn't easily find out a way to try. After scrolling down a lot, I finally found some example notebooks.
The most interesting feature is how it computes the inverse of the program to yield the inputs that produce a given output. I'm not sure if it's useful but it's cool.
Seems like this would be a great foundation for building a CMS backend interface. I'd try it in that context before calling it a programming environment.
Seems awesome. I will probably never use it because it is not flexible enough to run anywhere and on VPSes without friction, but I sincerely hope you succeed.
{kind=link}
{kind=link}
I'm one of the creators of Carbide, and I'm really excited to share it with you all.
We're thinking of releasing Carbide as open source in the coming weeks if there's a community interested in building stuff on top of it.
One of the areas we'd appreciate help with is adding support for different languages— Python, Scala, Haskell, Rust, etc.
Other than that, general feedback / questions welcome.
We've scrabling to turn off jet-engine mode on the website :)