Some things I don't particularly like in this diagram:
* I don't consider 307 and 308 to be irrelevant. Even if many browsers today are safe against method-change attacks, it's always better to be explicit.
* I don't see why 304 would only be used if "implementing a web server". Many web applications do their own Last-Modified or E-Tag checking behind the web server (and for good reason).
* There are also non-webserver reasons you'd use 408 and 413.
Also
> I don’t find this argument compelling, if for no other
> reason than this: in a world where everyone is moving
> to HTTPS, we’ve forbidden any proxy or caching nodes
> that are not under direct control of the server.
What? Even if you are controlling the cache, I don't see why you would want to make your job more difficult by having to explicitly control it when HTTP can do much of the job for you. (Not to mention there are cases, specifically AWS and cloud services, where you wouldn't have direct control of your proxy cache, but are still using HTTPS.)
Otherwise I'm glad to see some people still think using a variety of HTTP status codes appropriately is a good idea. It makes services easier to use and more intuitive.
Also, permanent redirects need a big caveat: if you screw them up you will have a bad day, because they are nearly impossible to fix - browsers take "permanent" literally. Better to use temporary redirects with sensible but limited lifetime.
Doesn't HTTPS explicitly support an intercepting, deep-inspecting, proxy? So if I want to reduce bandwidth at my site - or scan for malware, I can install a SSL-certificate my clients trust, and proxy the HTTPS connections, with eg. squid? Just because there are many nefarious uses of an SSL proxy/mitm, doesn't mean that there aren't good uses for it too?
As bandwidth to even home users go up, the need for local caching proxies might go down -- but at the same time, Netflix is an example of how the current architecture of the Internet isn't enough if you want to do individual media streaming (they maintain their own caches, but that just means that if one wanted to distribute a few TB of hd video, say an independent documentary series, or even a video diary, one might expect to either have to pay a high bandwidth bill, or do some "proximity caching"). Alternatives exist of course, such as using a torrent for distribution -- but throwing out all ideas of content proxying "beacause TLS" seems misguided.
The Go standard library HTTP client (net/http) changes POST/PUT redirects to GET[1] and it's super annoying.
EDIT: Here's the rationale (from [2]):
"I think the underlying principle of the matter is that if the client is going to resend the POST request body data, then RFC 2616 wants clients to get the user's consent. The trouble is that most client implementations did not resend the POST data when following 301 or 302 redirects. So the principle of getting user consent doesn't really apply.
RFC 7231 (HTTP/1.1 June 2014) changes this. It ratifies the common behavior of 301 and 302 (to not re-POST), and in doing so it leaves it up to the client to determine when it is safe to automatically redirect."
Hard to get behind an argument on status codes being pointless when the article itself cites the usefulness of wisely chosen status codes, such as "201 Created, 429 Too Many Requests, and 503 Service Unavilable".
I've created and used many a RESTful API and can vouch the ones that just return 200 even in cases of error are a big pain in the neck.
This is usually done (IMO) as a shortcut on the hand of the service provider, lack of knowledge on the conventional codes that should be used, or for the sake of more flexibility when endpoints change.
However, all of those reasons just push more work onto the service consumers. Lack of standardized status codes means the consumer must have customized error detection, which is more susceptible to changes as the provider pushes out updates.
One that bugs me, is IIS with .Net projects, such as WCF where condition validation fails returns a 500 error, instead of a 400... I've come to implement a global exception handler to inspect the exceptions to handle these things, so only actual server-side errors return 500... others will wrap out.
Mainly because I got tired of seeing certain classes of errors showing up in my main error logs, when they are being caught, but throwing 500 errors... mainly pen-test/bots trying to get in.
HTTP status codes are also useful for infosec people during breach investigations. Sometimes all that's available is access logs, and those codes can provide a lot of context.
I've seen APIs that always return 200 because the iOS app that was the API consumer couldn't handle non-200 responses (something about it being harder to get the response body IIRC).
Dunno bout iOS but I know Java's built-in HTTP library requires you do something like `if (status<400) { stream = getResponseStream() } else { stream = getErrorStream()}`. It's so silly.
> I’m not completely sure they do matter.
> There’s a lot of smart people at Facebook and they
> built an API that only ever returns 200.
This is the best bit of the article.
Most (many?) APIs, whether or not their authors call them REST, are single URL APIs that you throw JSON/YAML/whatever at. If the caller is going to get back a serialized status message (["Not found"]), then the HTTP request was successful, and it should return 200.
I'm not sure why people insist on spreading their APIs out between the transport and content layer.
If the API is indeed RESTful, and it complies with the concept that a URI represents an address of a specific resource, then returning 200 even when the resource was not found does not make any sense. The request was not "successful", rather the request failed to find what it was looking for!
That said, "single URL APIs that you throw JSON/YAML/whatever at" are not RESTful anyway. For a non-REST API, then it may make sense to return 200 even if something was not found, but it is still not a good idea to just ignore the properties of the upper-level protocol your data is ferried on.
> I'm not sure why people insist on spreading their APIs out between the transport and content layer.
HTTP is not the transport layer. It's an application protocol meant to convey application data. People spread their API over it because that's how it's supposed to be used. If you're just using HTTP as a means to toss random data between computers, you should consider TCP.
On the client side, whether a GET returned a successful (2xx) or error (4xx/5xx) status is observable for cross-origin requests. This can leak information about the user, particularly if you have cookie-authenticated resources that 503 depending on the user's identity (e.g. Facebook 503ing if you're not friends with X). This can be resolved by requiring a CSRF token or fancy header, but that muddles the RESTful semantics.
A common solution is to make your public API RESTful and authenticated differently from your browser cookie sessions, and make the private web APIs always return 200.
403 would be the proper status if the user was authenticated but forbidden. 503 would imply an error on the server and that the service is unavailable.
Here the 403 is appropriate because the user is logged in and trusted to some degree by your system, but isn't allowed to access that URI.
If the user were unauthenticated and tried to access the same URL, he should get a 401 for Unauthorized, which is the same response he should get for every URI in your system, thus exposing nothing about your underlying service.
> GitHub returns 404 instead of 403 to prevent these information leaks.
This behavior is explicitly permitted by the standard, FWIW: An origin server that wishes to "hide" the current existence of a forbidden target resource MAY instead respond with a status code of 404 (Not Found).
Ah yes, thank you, that should have been 403. I suspect a 401 would still leak info, as the <img> or <script> tag will let you differentiate between a 200 and other failing status.
I'm not sure I follow how something that's wrapped in a TLS session can leak information if it's returned as an encrypted header, but not if it's returned as an encrypted body?
That's by design - allowing arbitrary TCP in a browser is just asking for security and DDoS problems.
> HTTP works through proxies
So does TCP (SOCKS).
> Web servers
Using web server wouldn't make sense if you were using straight TCP.
The real reasons HTTP is used when plain TCP would be more appropriate are:
1) Lazy/stupid firewalls configured to only allow port 80/443. This leads to everyone doing everything over HTTP, moving the problem and making the firewall much less useful.
2) NAT. When the primary benefit of the internet - where each peer is equivalent in the protocol - cannot be counted on, centralized servers (usually using HTTP because of #1) are used instead of direct TCP.
Using an architecture shouldn't be a dogma but a choice. REST is defining a set of constrains that provides a set of benefits. REST emerges because people noticed that the 'Web' was more scalable and robust than other distributed architecture (COBRA, DCOM...).
So if your usecases would benefits from caching, discoverability... then you may want to choose REST.
Reading that old thread really makes me realise how perceptions have changed over time. I think more folks understand how useful REST can be, as it provides a standard set of semantics for talking about resources, and that semantics are pretty widely applicable across various situations.
In that respect, REST is a lot like relational calculus: certainly not a panacea, certainly not universally-applicable, but an extremely useful way to approach a large number of different problems. And just as one should have to justify why one is not using an RDBMS (and there are a huge number of reasons not to!), one should need to think hard before abandoning REST for RPC.
> If the API is indeed RESTful, and it complies with the
> concept that a URI represents an address of a specific
> resource
I suspect the maintainers of both of those APIs are doing it right... ;-)
More seriously, almost every API I've seen that tries to be (or claims to be) RESTFUL is just somewhat randomly distributing parameters between the URI, headers, and a post body.
> HTTP is not the transport layer. It's an application protocol
> meant to convey application data
Nope, it was definitely designed as a transport layer, which describes meta-data about content going both ways. You can tell it's not a real application protocol because people shoe-horn serialized data structures in both directions.
> If the caller is going to get back a serialized status message (["Not found"]), then the HTTP request was successful, and it should return 200.
Now all clients have to implement their own error checks, string parsing, just to discover something that the HTTP layer could have told you explicitly, that the resource requested could not be found.
If an API treats data as resources, then the API should return HTTP status codes that clarifies how the query against the resource was handled.
"Could I have this?" = "404 Not Found" is a great response.
"Could I have this?" = "200 OK" (not really) is a crap response.
Yeah, I hate APIs that return 200 with a JSON (or XML) body that says the response was anything but OK.
Another bugbear is a server suddenly switching content types for errors. If you're on IIS, make sure you're handling your own damn error pages so I don't suddenly have to account for an HTML 500 error page in my javascript code. Cisco's AXL API was a terrible offender for this one.
I've never used IIS, but isn't that confusing protocol codes with content codes?
IMO HTTP status codes should return information about the HTTP transaction, and only about the HTTP transaction.
If you run an API layer on top of that, that's a separate concern.
So "Server busy" should not be in the same space as "That API request was bad."
On my last project I returned 200 for successful transactions, 404 for missing pages, and 444/closed connection for 'Piss off and stop making inept attempts to hack this server, use it as a free proxy, or rack up your SEO stats."
IPs trying any of the latter are blocked by Fail2Ban.
444 seems to have cut down on spam requests from botnets, and it's cheaper than serving a full 404 page.
* Make request
* Has error string message?
* Error
Fairly similar code-paths. If there was a very consistent implementation of REST API's and how they worked/responded this argument might have more legs; because client libraries could have a shared base libraries which handled this logic. As it is, API specific libraries have to implement error handling logic so it doesn't really matter.
The problem there is that error strings tend to change over time... an error match today may fail tomorrow.
Additionally too many clients think that error messages are safe to be shown to end users. In reality error messages are seldom to never fit to be shown to end users, not least because they're not localised, but also because the target audience for an error message for an API is the developer, not the end user.
What's the problem with including an additional user-friendly, alert-friendly, localized message in the payload? That's a much better general solution than trying to figure out which nonsensical HTTP status code to return.
How does an API know the context surrounding a message to be presented?
i.e. is the client a mobile one? Does it have limited space to display a message? Is the client actually a desktop client calling the API with specialist needs to show a system dialog with specific properties filled that is more than just a single error string?
An API is an interface to interact with the web application, beyond providing the means to interact with resources it should make few to no assumptions about how clients of the API will act, their environment or constraints, their locale requirements, or anything.
The client is best placed to decide how to communicate to the end user, and the best thing the API can do is provide clean and unequivocal instruction to the client that something has happened so that the client can do it's job of handling it how it feels is best.
This just complicates the handling of the request on the client for no apparent benefit. And there are many more HTTP codes besides 404 which are mostly meaningless (payment required, anyone?), or fit very poorly within the application logic. It is a layer of legacy cruft that is best avoided. Non-200 codes should indicate some exceptional situation on the server and could be handled client-side as "server configuration exception".
A lot of client libraries throw exceptions when a non-200 status code is returned, something that plenty of newbies and not-so-great developers struggle with.
I imagine that always returning 200 drastically cuts down on support costs and basically-irrelevant forum posts, regardless of the technical rights and wrongs of doing so.
>an exception is better than a silent failure in almost all situations.
>this is an argument for not using 200 for all; not against
The practical side of me disagrees.
Experience bears out that plenty of developers are at a loss when e.g. a login callback page shows an unhandled exception error despite error-checking code being in place and running against the response's "error" node or whatever is used.
The problem is that there just aren't enough people out there that can understand the entire stack, and the end result is that people who've paid (good/bad) money for development - and their end users - end up with services that'd otherwise be decently functional showing the odd exception error instead.
(the technical side of me agrees with you absolutely!)
> Most (many?) APIs, whether or not their authors call them REST, are single URL APIs that you throw JSON/YAML/whatever at. If the caller is going to get back a serialized status message (["Not found"]), then the HTTP request was successful, and it should return 200.
Having spent three years of my life writing tooling to deal with such a vendor's API, I would really, really prefer that people avoid this anti-pattern. REST is a really nice idea, and it works out tremendously well in practice. RPC-over-HTTP is not such a nice idea, and it works out rather painfully in practice.
As an aside, the mere fact that the message is serialised doesn't mean that HTTP and rest are inapplicable: HTML, XML, JSON, YAML, protobufs, s-expressions &c. are all just different forms of serialisation which can be applied to data. The RESTful way to indicate Not Found is to return a 404 status code, with a body which is useful to the client in some way. A human being might accept plain text or HTML; a programmatic client might accept a JSON or protobuf response, and probably doesn't even need one for a 404.
Having spent more than three years of my life writing tooling to deal with such a vendors APIs, I wish people would stick more closely to the pattern of error messages in 200 responses. The application stack is not the webserver and I don't rely on status codes when dealing with the api through various transports.
> Why doesn't rpc over http work out well in practice?
It's not so much the nature of HTTP as the nature of RPC. RPC is all about calling remote procedures (hence the name); the issue is that there's almost always some internal state which is being mutated. REST makes clear what that state is, and provides reasonably clean semantics for idempotent updates; RPC tends to obscure that state. RPC can certainly be done right (after all, REST can be thought of as a constrained form of RPC…), but in many cases REST is the right level of abstraction to work at.
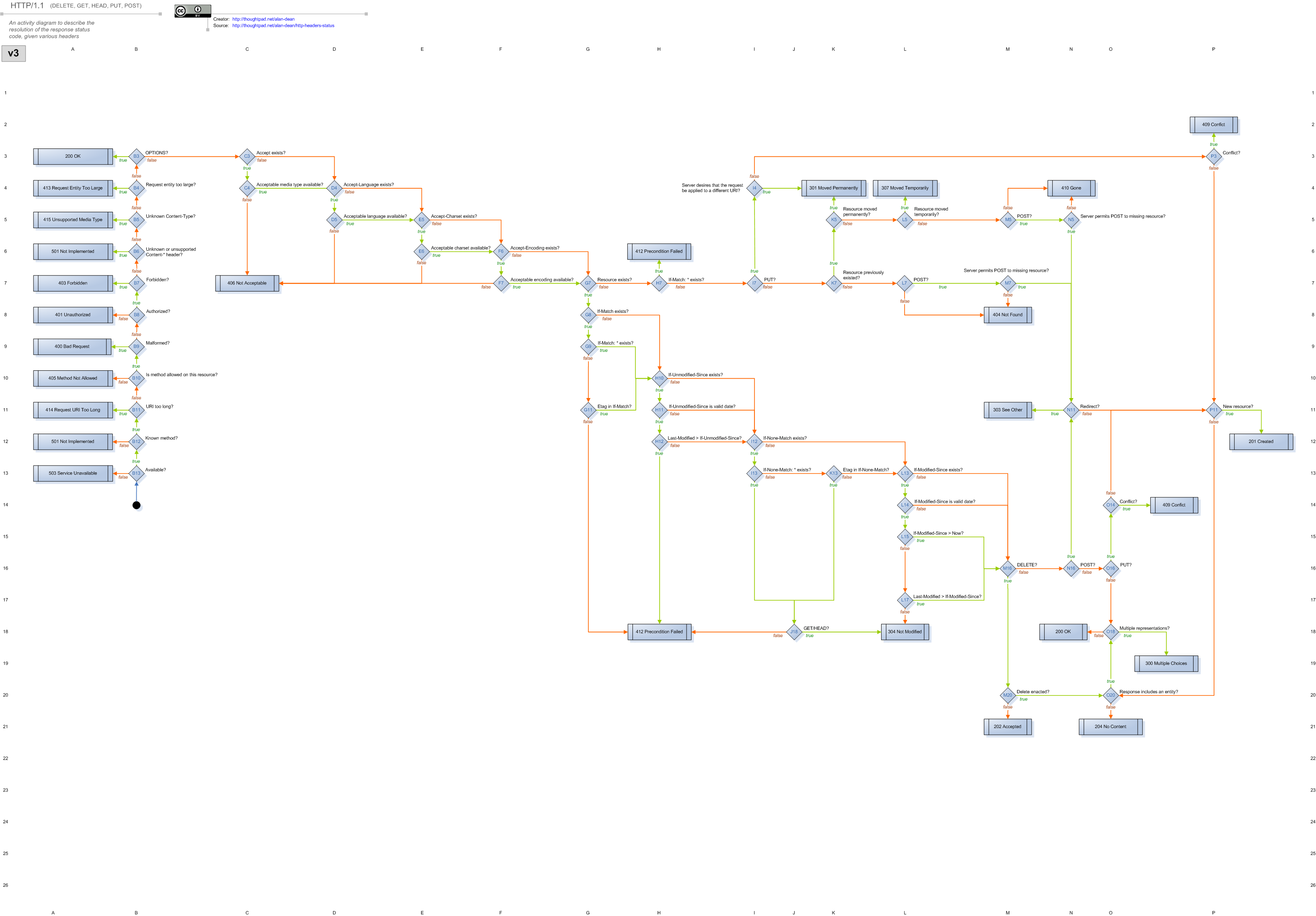
This is actual code drawn out as a state diagram.
It's officially available for Erlang and Ruby.
(Disclaimer: I am one of the "maintainers" of the Ruby version)
It's good to see more diagrams/flowcharts on the matter, but beyond that - for those that understand the power of abstraction between layers, but you think there should be a simple straightforward to spit out the correct http status code while you worry about the semantics alone: https://github.com/for-GET/http-decision-diagram
* an old PoC in NodeJS exists that reads the states/transitions from a JSON file and calls the correct callbacks in the correct order. Implement the callbacks (semantics) and you're done.
I really love Atlassian APIs. JSON request gone wrong? Here you have an error in XML! But I geuss that's expected when your documentation only has XML examples.
What about a request for non-existing resource (a file)? That's a 200 OK with an HTML for you! Also, the content of the HTML is "<h1>200 OK</h1>".
Luckily most of the functionality in their products is not implemented through the APIs...
>I really love Atlassian APIs. JSON request gone wrong? Here you have an error in XML!
There's a company I work with that is similar to this: Requests are XML, successful responses are returned as JSON with status 200 (with an empty error status field), errors are returned as XML with status 200, and the error text node is always "An error occured [sic] with your request".
Edit: This comment comes off as overly critical. I really do love these diagrams, I've just had this argument so many times with people I find it frustrating.
I completely disagree with this part of the diagram:
If the resource is secret then the entire guessable path should return a 401 or a 403, not a 404. Knowing whether something exists is a privilege that a user needs to authenticate in order to gain. This isn't just an academic distinction. Github does 404s for unauthenticated requests and python's default http client (at least for python 2) doesn't send credentials unless it hits a 403 or a 401. Since github sends a 404 you have to hack around the language.
404 means Not Found. But that isn't true. The real status code is Forbidden and it should be used on all possible urls that follow a guessable pattern.
I think that you have a point as far as staying true to what the status codes mean, but it comes with a price. To make the resource invisible to the user by 404ing instead of 403ing, you protect yourself from people searching for endpoints that return personal info... and all urls are guessable. If you get a hit on some resource in a sea of 404s, you are that much closer to gaining private info.
My whole point was that you should choose your 404s in a way that doesn't allow 403s to give away information.
For example, on Github we know that a user is at github.com/username, we also know that whether or not a user exists is public information. So if we GET github.com/nonexistantuser, that should return a 404.
A user's repo, however is not public information, so when a request is made to github.com/username/nonexistantrepo that should return a 403, unless you have privileges to know that information, if you were, for example that logged in user, only THEN should you give the 404.
I think this overcomplicates this. Based on your thought process github.com/nonexistinguser would throw 404, because well, whether or not a user exists is public information, but the same thing (a resource doesn't exist) github.com/username/nonexistantrepo would throw 403 so you have to check the url and make something conditionally if you are a client...
Also it makes more sense and more simple to me that something I don't know about simply doesn't exists for me. :)
Not bad. The ordering of 4xx status codes isn't that deterministic (often, it's situational), and last time I checked, Twitter uses 429 instead of 420 now (they like standards).
This is the first time I have really noticed the '405 Method Not Allowed' code. This makes it seem like you should explicitly handle every verb, when in cases before I have just left them unimplemented (which typically just results in a 400). Is it considered a best practice to handle all of these other verbs with a '405'?
I personally think it's best practice, although returning a generic 400 isn't _that_ bad. Libraries like Django REST Framework handle this automatically.
Some of the comments here are positing a false dichotomy. The choices aren't between returning 200 with an error code and returning an HTTP code for each error.
I've gone down the path of trying to shoe horn every error condition into a separate HTTP status code and (IMHO) it's a Big Mistake [tm]. You really are confusing transport and application layers and the transport layer simply doesn't have enough codes for what you need.
When something obviously fits into an HTTP status code then sure, use it, particularly when it'll mostly make your client do something sensible.
But you just can't get away from needing error codes that go beyond HTTP status codes for any moderately complex Web application.
"the existing status codes are much too general for a modern website/API... why worry about spending any time on a redundant, not-as-useful HTTP status code?
When pressed for a reason why it is important to use specific status codes, a common reason cited is that HTTP is a layered system and that any proxy, cache, or HTTP library sitting between the client and server will work better when the response code is meaningful. I don’t find this argument compelling, if for no other reason than this: in a world where everyone is moving to HTTPS, we’ve forbidden any proxy or caching nodes that are not under direct control of the server."
I do find this reasoning to be perfectly valid and have implemented many APIs accordingly for quite some time. It has a lot to do with the first place to look when something goes wrong. Does the 404 mean I mistyped the URL or that the Application can't find the Resource? Did the endpoint crash or did I mess up the rewrite in the nginx config?
That said, Michael's counter-argument is well worth consideration. I've generally left HTTP status codes and Application status codes completely separate for any sizable project, but I find this article and argument worthwhile and will continue to reconsider, as I generally do upon every new project, whether using HTTP status codes to represent general application state is worthwhile.
The original point regarding complexity is most important to me, but Michael's diagrams do an excellent job of showing how Application state can be considered an extension of the Protocol in specific cases.
I agree with parent5446 - there are various codes that although they are usually only used by web servers, they are also used in some REST APIs, including mine.
e.g. I return 304 when people query an image 1) Because it is not a static resource but is pulled in from another server and 2) It will never expire because if it changed, a parameter in the URL would also change.
I've been down in the weeds a bit when it comes to authorization. Every resource in my system has its group information in an attribute {:rights {:c [..list of groups], :r [..] :u [..] :d [..]} ....rest of resource...}. In parallel with the resource as above, there is an index table for all of the resources in the system. When a resource, our group of resources is queried, I filter the index table with the groups for the current user and join to the resource table. I can only bring back resources for which the user has rights for the operation.
This means that I can't ever have a 403. All I can return is a 401 or 404 or a 200 with an empty list. I kept fretting about this. Now I feel better. #how-i-stopped-worrying-and-learned-to-love-the-atomic-codes.
I tend to agree with that and even more so looking at these flow charts. Complex error handling is an easy source of bugs. At the very least, return codes should be limited to the minimum information needed to prompt the desired action in browsers, proxies, and search engines.
What if you need to communicate an error reason with your status code? E.G. distinguishing between Forbidden because you don't have some permission and forbidden because you're not friends with some user.
I like to return a error code property for each particular error case in the JSON body of the response. This allows you to determine exactly where in the code the error is from, and also allows the client to do fine-grained error handling in the UI if required. I've also found it incredibly useful to include a unique error ID with each request that is also logged server side, so that you can pinpoint the request in your logs and look up the context including previous and next requests.
Can you just add the reason in the response? Don't need a super specific error code for this. Could also be a 400 since users should not be asking for information on people they are not friends with, that seems like something is wrong with the request.
>Postel's law states that one should be conservative in what one does, but liberal in what one accepts from others; this is great advice for life, but terrible advice for writing software.
This perfectly sums up what I've tried to say about this "robustness principle" for years. Fantastic.
SIP inherits these status code ideas, plus adds super-neato whiz-bang headers, like "Retry-After", that allow comments. Their actual example is "Retry-After: 300 (in a meeting)". It's beyond delusional.
Except.... someone read the spec. They see Retry-After. They then implement it in some big iron that connects to the PSTN. Little SIP VoIP provider comes along, passes along this dumb header, Retry-After. Suddenly, big switch guy is pissed, as Verizon has disabled all his lines as "Retry-After" gets translated into "shutdown trunk" or something. Awesome. Really a round of applause for the IETF there. (You have got to know that these headers came about just sitting around thinking shit up, vs actually trying to implement telephony. That's why SIP says it might be used "to run a chess game", but has a mandatory "Call-ID" field. Oops.)
What code should I use when a user submits an invalid value over a form? Most of the time, I see 400 or 422, or even 403. I've also seen people say it should be 200, because the HTTP request was successfully handled.
It seems like such a common requirement, I'm surprised there's no agreed standard.
400 as far as I understand it is about the request syntax itself. If the error is in semantics (i.e. POSTing a phone number where you expected a date of birth) then the request itself isn't malformed. 403 might be appropriate, but generally concerns authorization more than the ability to process the request -- i.e. trying to POST something the user doesn't have authority to modify would return a 403. If the user is authorized for the specific request, and the request is valid syntactically, but the semantics of the request body makes no sense, then the entity of the request can't be processed and 422 is what you should return.
I'm not sure I follow. The client would receive those errors because they are errors on the clients side; the client should ensure that they are not flooding a service other wise the server will cut them off.
Your simple middleware logic is going to have to examine the 400 error in more detail in order to adjust its request rate e.g. exponential back off.
It's not that the "server is over capacity", its that the specific client is making "too many requests".
Usually "Throttled" response carries some information when you can retry. So simple middleware logic to retry with some generic timeout shouldn't be used, instead the response must be analyzed to find out the exact timeout.
Probably it's a thin line between client problem and server problem.
"429 Too Many Requests" means YOU made too many requests. Retrying will only make it worse. Sounds right to me. You should definitely not simply retry on a 429 response.
Rather than saying what error code I should or shouldn't use because of an out-dated loosely followed spec, maybe tell me based on what modern browsers do.
I actually did this in an app a few years ago, and completely forgot about it for a while. I only remembered when another dev sent a surprised e-mail. Ya gotta make time for fun...
> Coda: On Why Status Codes Matter
> I’m not completely sure they do matter.
> There’s a lot of smart people at Facebook and they built an API that only ever returns 200.
{kind=link}
* I don't consider 307 and 308 to be irrelevant. Even if many browsers today are safe against method-change attacks, it's always better to be explicit.
* I don't see why 304 would only be used if "implementing a web server". Many web applications do their own Last-Modified or E-Tag checking behind the web server (and for good reason).
* There are also non-webserver reasons you'd use 408 and 413.
Also
What? Even if you are controlling the cache, I don't see why you would want to make your job more difficult by having to explicitly control it when HTTP can do much of the job for you. (Not to mention there are cases, specifically AWS and cloud services, where you wouldn't have direct control of your proxy cache, but are still using HTTPS.)Otherwise I'm glad to see some people still think using a variety of HTTP status codes appropriately is a good idea. It makes services easier to use and more intuitive.