How do we generalize this solution such that it helps programmers building compiler platforms like LLVM and Roslyn? How will it help programmers researching neural networks? How will it help programmers writing line of business applications? Databases? Apps? Financial backends?
In many (but certainly not all) of these domains, we already visualise (parts of) them in 2D (as charts), so I see no reason why this wouldn't apply here too.
In my opinion, its not so important to solve the issue for every problem domain one might program in, but rather to do so for as many as are applicable. Just because a tool doesn't help with X, doesn't mean its a failure if it improves on Y.
But most things we see are 2D outputs (webpages, world if you close one eye, text console,..).
I think the closer we are to the bret Victor's ideal (of seeing what you do directly) is this: https://www.youtube.com/watch?v=xsSnOQynTHs (react-hot-loader + redux). And this is already practical.
Another nice tool who's the near his ideal is the chrome dev console: visual interaction, live edit, start/stop debugging,..
But the amount of code that deals directly with producing such output is usually very low, as a proportion of the total amount of code in the system. Having a pane on the right say '825' next to the 'printf("%d\n", do_the_actual_work(foo, bar));' in my code isn't useful. I already get that from the terminal. The place where the benefit would actually appear is visualizing the parts of the code that are doing the complex and error-prone tasks in the system.
If you're a frontend web developer, then sure, it could be useful for you. But with the kind of stuff I do personally, the 2D output demonstrated in the article is irrelevant. Most stuff is much more abstract, and has zero relationship to direct production of visual output. It looks cool and all, but ultimately I feel like it's focusing on the easy problem rather than the important one.
There are a few examples in there of visualizing the values in a for loop over time, but again, I feel like this is unrealistic. The proportion of my code that only executes for a fixed number of iterations that is easily determined at compile-time is negligible. As is iteration over a fixed, compile-time set of values. Most code lives inside functions that can be called with different combinations of parameters, interspersed with multiple nested loops and conditionals at different levels in the call stack, etc. Visualizing something like that in a useful way is much more difficult. If they can show an example of that, I'd be very interested. Until then, it seems more like a toy. A very interesting, promising toy, but still a toy.
The unit test example gets a bit closer, but it's still just dealing with the output of all the code that actually does the work, not the details of that code itself. A tool like this should be helping you with the hard tasks rather than the easy ones, because the easy ones are already, well, easy.
I'm not trying to be hostile, it certainly looks cool, and it looks like it could potentially be very useful in the future. It's just that currently it doesn't look like it would have any practical utility for me.
Chrome dev tool is a mess of half baked, half implemented, inconsistent ideas.
Take the CSS editing, incredibly annoying, impractical, opaque behaviour. Or every option using regexes so just to exclude some files you have to muck around with the bloody things. Or the hover to display local value of variables kinda working, but not always, but highlighting usually works, but watch variables are stupidly in the tiny width window to the right so you can't read the end of the variable name which is usually the really important bit.
And don't even get me started about their shitty redesign of the files making it harded to find the local files, the only ones you actually care about, and giving far too much visibility to external libraries.
But then they do genius things like unobtrusively display the method input variables.
Don't get me wrong, dev tools is useful, but quite obviously designed by a programmer who's experimenting with various different UX paradigms. Chrome dev tools is a joke when you put it against a real dev tool like visual studio.
Attempts like these might be barking up the wrong tree.
People who are going to be successful in bootstrapping themselves from 0 to dev are going to naturally grasp logic, state, or any other general programming concept. (Not master, but grasp).
What people need is a real problem they can solve with programming: automate an office process, build a website, crunch some numbers, etc. And this is usually best done on a stack that has solutions for these problems. That's why "the future" of learning to program looks more like this: http://automatetheboringstuff.com/ than a noob-IDE.
Depending on where you sat in history, every programmer tool was considered something for 'noobs'.
Von Neuman considered an assembler a waste.
Fortran was considered bad by many because you weren't working with the instructions the computer was running.
Auto-completion, debuggers, syntax highlighting, fast compilation, interpreters, virtual machines and GUI building interfaces have all been derided by someone as terrible because everyone should man up and get closer to the metal.
It has never been on the right side of history to refuse to embrace new tools that make creating software easier.
Thats not the point of what Bret has been trying to advocate IMO. Instead he is trying to establish better frameworks for thinking about programming by providing a better feedback loop.
Smalltalk was the pinnacle of programatic pedagogy. Hypercard was the easiest way for regular humans to use computers for computer-like automations.
But, then you run into the "No Real Programmer" problem. The nerds take over, hyper-complicate everything, then we're back to nobody understanding anything. (Also see: "No Real Unix User" when people say "Well, I don't consider OS X users to be unix users.")
The other major tool I'd put up there with Smalltalk and Hypercard is Excel, at least when it comes to automation of real-world business problems. To an extent, it made a large enough set of problems easy enough to solve that tools have stagnated as a result.
I don't think it's about bootstrapping to dev. I think it's about allowing people to solve certain problems using programming, but in a different way from what we're used to. It's about visualizing explorative programming. That's the way I understand it.
A few years ago (2012) I was taken aback by the Unreal Engine development process. Their IDE features a running game with all elements being selectable and interactively editable. In one video fragment [1] they hop to Visual Studio where they change gravity. After a few seconds of compilation, the game's code is updated.
In the second example how does a live programming
system synthesize a "Person" object?
Most data types should have `example` methods. They're too useful not to have, for documentation generation as well as live programming. `Person` in this case should definitely have one.
What if there are multiple constructors?
What if it depends on ten other objects
when being created?
Each of those other objects should also have `example` methods. Person's example method should use those, possibly modifying them after they're called so that they make more sense in the context of a `Person`.
What if this object only originates from
a database? Should the user constantly create
these objects by hand when they want to edit
any function in their program?
Zomg no. Make `example` methods. The idea of having beginners program without static types and immutability seems misguided to me, because it makes them keep the whole program in their head instead of just the function they're working on. The idea of making them keep the whole program in their head _while also not having an example of what they're operating on_ is just silly.
EDIT: PPS: If any lispers are reading this, I'd be curious to hear how you generate example objects at the REPL. Since the lisp community places such a high priority on REPL programming maybe it's already explored this area in depth.
If any lispers are reading this, I'd be curious to hear how you generate example objects at the REPL. Since the lisp community places such a high priority on REPL programming maybe it's already explored this area in depth.
Clojure is my language of choice. What I've been doing so far is keep sample data in my unit test files. I then use a mixture of running code direct from my editor [0], importing the sample data from my (non-editor) REPL [1] and actually running the unit tests.
Its worth noting that this usually happens in reverse: I construct the data in the REPL while experimenting and then copy it to the unit tests after for reuse.
how does a live programming system synthesize a "Person" object?
That just got me thinking. In Clojure, we generally use raw data (primitives, maps, lists, sets, vectors) rather than hiding behind objects, so synthesizing them is the same as any other data.
Realistically, there would generally be a constructor function, but most functions are deterministic pure functions. I feel like OO languages may be harder to make play nice with live programming because OO hides a lot of stuff and encourages impurity.
[0] I can eval the entire file, the form that the cursor is on, or I can eval code I type into a REPL.
[1] (require '[my-test-namespace.my-test-file :as alias]) Then access alias/sample-data
So we sort of run into an issue here with "What people should do" vs. "What people actually do".
The creator of such a tool needs to design their tool around the reality of "What people actually do". And in our current target language C#, there is not an existing culture around building example methods. (And often people don't even have unit tests).
The biggest challenges we've faced when building Alive are running into problems like this one, where there isn't a clear, nice solution.
One of the other problems is that people keep trying to find the one perfect tool or solution that will work for all cases. This is the wrong attitude.
When manipulating any kind of object in the real world there are a series of tools. Each has their own feel, way you interact with it, and is used for a specific purpose. A hammer, saw, sander, file, router, nail, all do different things. The interface to them is unique.
Programming needs to follow this model. Each scenario is different so they need to be handled separately. Allow for a comprehensive general framework and then people create tools for each scenario. The tools can be general purpose or very specific.
Work with the general purpose AST with tons of annotations (comments, 2D coordinates for visual layout tools like NoFlow style, etc).
Also, depending on what you are focusing on at the time you may want a different view of the code. Think how architecture is different. Framers have their own annotation. Then there are plumbing and electrical overlays. There are also wireframes and fully rendered views. Top, bottom, orthogonal, perspective, etc. You get the idea.
Start with model, view, controller. Each is unique. It can be visualized and written differently. Right now we use the same text based language to describe each and to read each.
When you have a general purpose AST then the code can be "read" in different modes (each with their own strengths and weaknesses).
Also, sometimes is is easier to write in one form and read in another. For example, writing math using post-fix is really easy but reading it requires too much managing of the stack state in your head (cognitive overload). For reading, mathematical notation would work better.
> How do we generalize this solution such that it helps programmers building compiler platforms like LLVM and Roslyn? How will it help programmers researching neural networks? How will it help programmers writing line of business applications? Databases? Apps? Financial backends?
I've given this idea quite a bit of thought. I've been wanting to do something in this space but haven't had the time to work on it yet.
The idea I have proposed but haven't seen implemented anywhere is to follow what I call the "workbench model".
The problem is we are "programming blind". Instead of thinking of programming as a series of abstract steps in a recipe, just start with some sample input and manipulate it towards the output.
When you want to do woodworking you use a hammer, saw, sander, etc and manipulate it directly. It's intuitive and you can see what you are doing. The result is immediate. Modern programming is like writing G-code to run though a CNC machine.
Instead of defining things in terms of a series of steps and trying to figure out how to visual that, flip it around and do it the other way. Pass in some parameters and let the user manipulate it however they want in real time. Record the steps they used to go from input to output (like a macro). There is your function. This also works quite well, but is not limited to, a postfix environment like Factor (or the HP-48 calculator RPN language if are more familiar with that).
Now obviously there are multiple input scenarios that need to be handled uniquely. How do we do that? Simple, run each case separately and use pattern matching to qualify your actions.
Ideally, this would be combined with "first-class citizen tests" (another pattern I came up). Basically, when you define a function you give it some sample inputs for the different scenarios and edge cases. You specify the outputs for each corresponding input. When working on the function you choose an input and then work towards the output. When the output is correct it turns green automatically. This happens in real time as you are manipulating the input values. It also tests the other input scenarios as well. If one or more of the other inputs don't match the required output then you add more pattern matching. When all tests are green your function is done.
Personally, I would be wary of any IDE that attempted to interpret what my code is doing for me. Each person probably has a different mental image or interpretation of how their code works, and enforcing a singular interpretation of code via IDE might only enable people to 'learn' how to program within that environment. Teach a man to fish.
You have a computer right in front of you, why not use it to figure out what your code is doing rather than do the mental gymnastics in your head! This reminds of a story, I think it was dijkstra or maybe Knuth, who was lamenting that their students were being too sloppy because they got to program on interactive terminals and not the punch cards of yesterday. Programming without an IDE is the same...it's using punchcards when something much better is available.
The same could be said about other types of abstractions, such as using a compiler versus assembly. In the vast majority of circumstances, developers get far more accomplished using higher level abstractions and frameworks.
In very extreme circumstances, portions of an application may need to be rewritten at a lower level for optimizations, but that doesn't negate the value provided by abstractions that allow the developer to be more productive expressing higher level concepts while the computer handles the tedium of how those concepts are translated into machine code.
I think the difference here is that in the movement towards 'smart' IDE's, they attempt to go beyond the purely semantic meaning of the code and deduce what the interpreted meaning of it is. I'm all for what is in this article as far as it pertains to more interpretations of the semantic meaning.
The term "IDE" tends to evoke images of highly unwieldy and inflexible mammoths like Eclipse and NetBeans.
Is Acme an IDE? Is Emacs an IDE? One has the plumber, the other has the buffer. They're both small abstractions that can be relentlessly scaled to greatly complex and intelligent workflows.
In contrast, I do not consider the standard IDE to be a great leap. They're actually quite static and the visualization tools they provide through graph structures are primitive for any real white-box analysis.
Kernel developers don't use and IDE for the Linux kernel, and they are arguably some of the best programmers in the world. Great programmers use vim or emacs, because the imagery in their mind is far more powerful than anything an IDE could display. Besides, any screen real estate used for "interpretive" purposes is just an annoyance.
Are they the best developers, and if so how do you measure that?
> Great programmers use vim or emacs
This another form of No True Scotsman, and not a valid argument.
> because the imagery in their mind is far more powerful than anything an IDE could display
How do you know, and how do you measure this? Surely, you would admit that Vi and Emacs are better than pen and paper, or punch cards, right? So does it not follow that Vi and Emacs could be improved upon? Or are they the pinnacle of inputting instructions into a computer? If they are which one is better? Why? How do we measure that?
The steering wheel could be improved upon in some theoretical sense, but the chances are that any new car steered by, say, an iPad is much worse and definitely isn't going to be used in races any time soon.
These kind of generalizations aren't helpful, simply because they aren't true. Are vi and emacs still going to be in wide use 500 years from now? Likely not. Then it stands to reason that there might be a way to improve upon them.
I use an IDE because I don't have to sink an inordinate amount of time into customizing my environment, since that activity doesn't deliver any value to the folks that pay me. I'd prefer to let a really smart team of engineers set those tools up for me. I do not, however, assume that anybody that doesn't use an IDE must be inferior.
Is Visual Studio going to be in use 500 years from now? Light Table? No.
The people who made Visual Studio have not made something that is smarter for everyone's work. Maybe your work just doesn't require any customization. That doesn't mean nobody should ever want customization.
> That doesn't mean nobody should ever want customization.
I fail to see where I made that claim. IDE's are also customizable - I would argue that they are, in fact, much more customizable than either vim or emacs, simply because of the breadth of features one may customize. I was addressing the parent's claim that "great programmers use vim or emacs."
I'm sure everybody thinks about their code in different ways, but that doesn't seem to bother people when they use syntax highlighting. Similarly, Victoresque "code interpretations" can be just another layer, to use when it's useful and to ignore when it's not.
> I would be wary of any IDE that attempted to interpret what my code is doing for me
Actually, there is explicit interpretation in any IDE. It's just the level of abstraction that Mr. Victor has articulated. Generally speaking, the programming world is tethered to the notion that programming makes the most sense through logical linguistic feats, but under the surface of anything code-driven or lingual is an implicit type of semiotic.
It looks impressive, but only in these superficial simple examples. If we have really complex problem, i.e., designing distributed algorithm, we need to create domain specific visualizations and these bells and whistles won't help us.
I may understate Bret Victor's thesis and may overstate Josh Varty's counterargument but I believe JV's criticisms are not applicable to BV's particular essay.
Some key quotes from each for context:
>Bret Victor: "How do we get people to understand programming?"[1]
>Josh Varty: "Problems getting to Learnable Programming [...] However, we need to stop and think deeply about how this system would handle typical code. How do we generalize this solution such that it helps programmers building compiler platforms like LLVM and Roslyn? How will it help programmers researching neural networks? How will it help programmers writing line of business applications? Databases? Apps? Financial backends? The vast majority of functions in today's codebases do not map nicely to a 2D output."
I see BV's essay focused on learning programming for people unfamiliar with programming. For non-programmers, even simple syntax such as "x=0; x=x+1" looks strange and beginners can't hold in their head what it does. So instead trying to teach beginners the LOGO programming language to move turtles around on the screen or BASIC language of "10 PRINT "HELLO" \n 20 GOTO 10", Brett shows a visualization where code syntax update its 2d output in a realtime feedback loop. This can help novices make the leap from abstract syntax in a text editor to the concrete changes in the output.
Josh Varty is going beyond the scope of newbies learning programming concepts. He's trying to generalize it to working practitioners who already understand programming and make the "Learnable Programming Model" work for any arbitrary code to any type of visualization (beyond 2D if necessary). The "live coding for everything" is an interesting concept to pursue but I don't believe Brett's essay had this wide of a scope.
I don't believe working programmers who have already mastered how "programming syntax maps to changing machine state" needs visualizations for every line of source code. However, JV's generalized scope is applicable for working programmers to verify code for correctness and do sanity checks on what they think the code is doing.[2] However JV's ideas are not necessary for working programmers to understand programming.
In one case, JV uses this as example:
var result = DoTaxes(person);
The professional programmer (not the "learning programmer") doesn't need a clever realtime visualization to "understand" DoTaxes() in the BV sense. The programmer already has some idea that it probably has some code that performs multiplication and addition. Possibly even a lookup table for different countries or taxing authorities. The realtime visualization would help the professional programmer verify what the code actually does. Since realtime isn't available today, programmers get by with watch windows in visual debuggers, or manually insert printf()/console.log() statements. However, the programmer doesn't need BV visualizations to grok the compsci topics of the changing machine state inside DoTaxes().
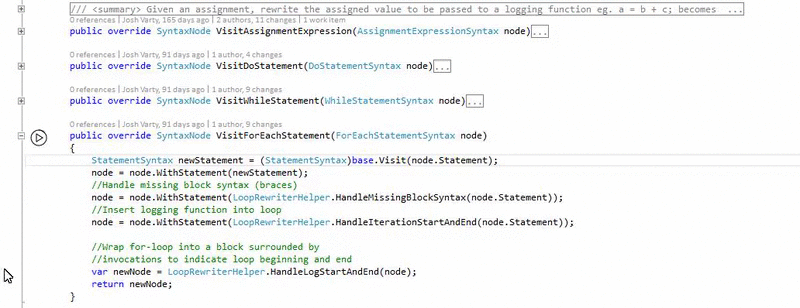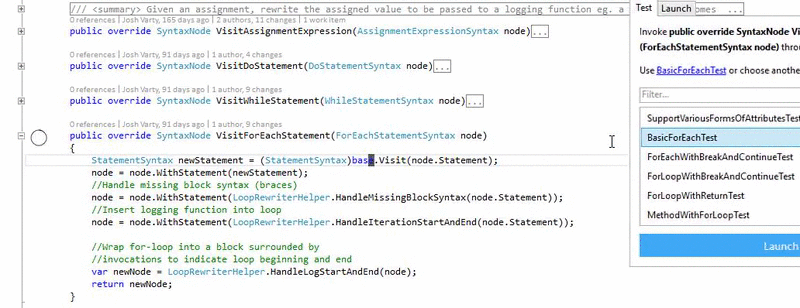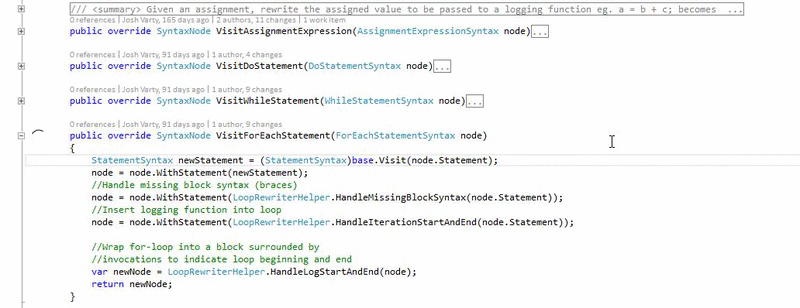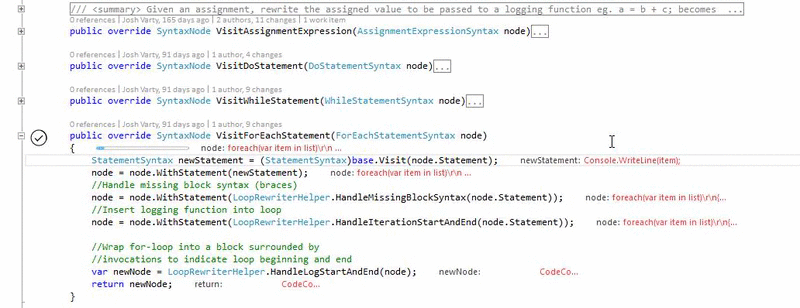
[2]See how JV's ALIVE demo visualization serves a different cognitive function from BV's. Those little red annotations are helpful for professional programmers to verify behaviors but not for beginners to grok compsci: https://embed.gyazo.com/4dc7ac656863cbd02a8e213598f85a4f.gif
The learnable programming essay is quite expansive. On the one hand, the premise is about learning to program, on the other hand, veteran programmers will see many features that they want in their programming experience in spite of already knowing how to program. So it is a bit tough to separate those concepts.
The live programming story is a bit more general, it is about merging editing and debugging into one fluid activity allowing you to aim your code like a water hose at a problem, hitting it easily because your feedback loop is continuous. See Hancock's dissertation for that story.
In his response he told me to read the section "These are not training wheels" near the end of the blog.
Here he says:
>A frequent question about the sort of techniques presented here is, "How does this scale to real-world programming?" This is a reasonable question, but it's somewhat like asking how the internal combustion engine will benefit horses. The question assumes the wrong kind of change.
>Here is a more useful attitude: Programming has to work like this. Programmers must be able to read the vocabulary, follow the flow, and see the state. Programmers have to create by reacting and create by abstracting. Assume that these are requirements. Given these requirements, how do we redesign programming?
I think the ideas he explores can apply more generally outside of creating environment for learning. And my understanding is that Bret believes they should apply to programming in general as well.
>And my understanding is that Bret believes they should apply to programming in general as well.
Yes I agree, but I think his 2D visualizations that you criticized were focused on "learning programming".[1]
BV wasn't saying that extending it into "non-learning" scenarios for professional programmers must be a 2D feedback loop. Consider a new programming language with specialized syntax or a library of functions for moving a physical robot in 3D space. The feedback loop could be a live Bluetooth or wifi connection to a articulating robot arm on the programmer's desk. I wouldn't think BV would criticize that and say, "no, the robot arm must be 2d image on the screen".
[1]key phrase of "presented in context for learning" from BV: "These design principles were presented in the context of systems for learning,"
The problem isn't things that we know how to visualize but do not fit the 2D model, the problem is the things that we do not know how to visualize well (which is most of the data in our programs). Visualizing the output of a program that does a 2D drawing is easy, because it's already visual. The hard part is doing it for general programming, and the essay is handwaving around that. I think the answer is that for each domain, or even for each data structure, visualizing it well is itself a complex research problem.
Article suggests that only Alive and Light Table provide this form of programming interaction. However, many (certainly not all) of the features in this article are a part of the Swift Playgrounds in recent iterations of Xcode, which were probably inspired by this work. Just worth pointing out.
Update: I missed the part further down in the article where the Playgrounds were indeed mentioned. Whoops.
>The ideas are quite old, much older than Bret Victor's work.
Absolutely. Your work in particular predates Bret's and I've enjoyed reading it and hope it catches on and inspires more folks at Microsoft and Microsoft Research! :)
I think what makes Bret's work a little different than the linked work is that Bret's work managed to escape academia and appeal to an audience that might not have otherwise been exposed to these ideas in the first place.
It is great that Bret's work made the ideas more mainstream, but on my research for Xerox PARC's work I would say the ideas go back at very least to the interactive coding available on Smalltalk, Interlisp-D and Mesa/Cedar.
Interactive coding is with us since the early 80's, the ideas just failed to go mainstream.
Live programming goes way beyond smalltalk fix and continue, morphic directness, or a LISP REPL. We've caught up to that past, it is now time to go further. And of course, no one is really quite sure what the lisp machines ever did really, it's not like they have a video on YouTube :)
It is better to have that argument with Gilad Bracha, I guess.
I think most of the amazement came from the time they were in. In that time this was truly revolutionary. Having a whole OS based on it is still arguably revolutionary, but from a programming/IDE perspective I don't think they are anything special any more. As far as I know a modern Lisp + Emacs gives you roughly the same experience.
Not sure what you mean by "live editing of inline data structures" here (care to give an example?), but the interactive debugger in Emacs/SLIME can do quite a lot of nice things, including modifying arbitrary data on the fly, live.
For instance, if I have a hashtable returned from a function I called in REPL, I can inspect it and modify its values and properties. Also, within the REPL itself, text is "smart" and copy-paste tracks references, so I can paste the "unreadable objects" (i.e. #<Foo 0xCAFECAFE>) directly into REPL calls and have it work, because SLIME will track the reference linked to a particular piece of text output.
The presentation based REPL in Emacs + SLIME was inspired by the Symbolics Lisp Machine presentation feature.
But I can assure you, there is a difference of a REPL feature in an editor and a GUI using it system wide, as on the Lisp Machine. Both in depth of the features, integration and the feel of the user interface.
Check out this video (which I made some time ago), which shows the presentation UI from an application perspective (here a document authoring system) and as a bonus, the application integrates Zmacs (the Emacs of the Lisp Machine)...
Think of the Documentation Examiner a version of Emacs Info. Think of Concordia as a version of an Emacs buffer editing documentation records. The listener a version of the Slime listener. You can also a short glimpse of the graphics editor, IIRC.
>Live programming goes way beyond smalltalk fix and continue, morphic directness, or a LISP REPL. We've caught up to that past
Actually we didn't. The vast majority of programmers doesn't have access even to those -- and even those that do don't have it in any much advanced way compared to those older environments.
I still wish Chris Hancock would get more credit, his work on live programming was really 10 years too early. It is a beautifully written thesis, and hardly very academic, but rather very pragmatic and useful. I just wish it came with videos, but I guess YouTube wasn't around back then :)
> This attitude is a losing one. For all its warts, bumps, pains and bugs, programming today works somewhat decently enough.
Sometimes pragmatism is the enemy of progress. As stated earlier in the article, you don't get the combustion engine by thinking how we can make horse drawn carriages faster.
Thiel also recommends this approach in Zero to One.
I urge the people working on this to recognize that we all don't think the same. (I know, you don't claim that we do, but I don't see these counter points expressed often).
I can't explain how I think, but it isn't visual, and doesn't seem to involve language much. Probably the closest is to say I think in math and geometry. That doesn't make any descriptive sense, but it is what I experience.
I fell deeply in love with math, and then programming. A few words and control structures, and you have Turing completeness! It's as beautiful as language. Minimizing expression is sometimes far more powerful than unconstrained expression. I can hold these structures in my head, and so can most programmers that I know. Pictures are a pale, weak thing in comparison. "The Illustrated Guide to Kant's Critique of Pure Reason" has never been published (SFAIK), and for good reason. The simplest rules of grammar allows us to generate and express extremely complicated and nuanced ideas. Ya, sure, we could make a nice chart of synthetic/analytic and a priori/posterior, and I think Kant did that, but beyond that what do pictures get you? I bet there are visual thinkers reading this that have rebuttals or examples, and that is great. Einstein was a great admirer of Kant, and was a visual thinker, so I imagine him raising objections! But I think in the end the visualizations may have illustrate power, but rarely investigative power. Einstein put the lie to that with his work in Relativity, but he was an extraordinarily unique thinker (he did his work visually, and then struggled to get the math to prove his ideas).
Anyway, my somewhat inarticulate argument is that programming languages was the great invention. Anything that is Turing complete lets us express anything computable.
I think if you can find ways to complement that it will be a great contribution to knowledge. But I don't think you can replace or improve upon a Turing complete language (unsupported assertion requires citation here!). It would be great to be proven wrong.
I use computer languages to do math, computer vision, and AI type stuff. Others uses it for different things. It all works. There is no universal visual paradigm to replace it. Engineering is optimization in multi-dimensions. Visualization limits us to 2 or imperfectly, 3 dimensions. So you can sort of slice out representations of this large, multidimensional space, but you are now working like the blind men on the elephant. You'll never get the complete 'picture'. You are just sort of poking at it with a stick. Whereas with a couple of equations I can describe the entire space AND now have powerful tools to explore that space, describe it, and determine its properties. I think back to one of Bret's videos where he uses a live environment to compute the trajectory for a character in a video game. In math that is known as the 'shooting method'. It kind of works, for some problems. There is also a universe of problems for which it doesn't work. How can you even tell if it works or not visually? The language of math gives us that tool.
I love pictures, and produce charts all the time for my math code. But they do not replace the math, they illustrate it. I do my work in math, and in state, and in sw architecture, and sometimes use visual tools to help check the work. There is no language of visualizations, and without one you will either be illustrating the work of math and computer languages (which is not a bad thing, I'll happily use the tools when appropriate) or severely limiting what we can do. I don't work or think in 2D or 3D space and cannot be limited to such a restricted view (pun intended). I work in small spaces usually (R^18 or so) and visualization is a non-starter except as a great way to learn some of the concepts. I know plenty of you work in far larger spaces.
tl;dr: the amazing advance was Turing complete languages; visualizations are not Turing complete; languages are powerful, visualizations do not have a language and hence aren't analyzable unless your name is Einstein.
I'm going to reply to myself to share some history.
I came up when things like 'structured analysis' and 'Yourdon diagrams' were a thing. I was repeatedly told that if I wasn't doing this I was "hacking" in the pejorative sense.
These diagrams were the worst hack that I've ever seen. There is no language, there is no verification, you can literally draw anything. There were case tools that attempted to balance all your arrow so that all ins had an out, and so on, but it was just a disaster. Hack, hack, hack.
In contrast, in code I could quickly express up an API design. It was concrete, it was testable, it was understandable, and it was a 1-to-1 match to what the eventual code would be. It was wonderfully, powerfully expressive. It wasn't limited to 2D, I could express complicated relationships without someone arguing "these lines cross, move this over there to improve the layout", and other nonsense that had nothing to do with solving the problem.
It was not a language, it didn't have a grammar, and it was untestable. It was extraordinarily limited. You couldn't show that this module is used by 10 different modules in different situations. You could express impossible things. You had no way to analyze it for correctness. Sure, there were case tools that put in things like state diagrams and simulation and such, but it was all just terrible. It was either impossibly constrained, or impossibly free-form.
In contrast, my stubbed API's were an exact representation of my ideas. If I want to test a hypothesis, I'd just implement part of the API, stub out parts that weren't important, and have running proof of my ideas. I was doing a lot of concurrent stuff then, and this was important. Visual depictions were incredibly cumbersome, untestable, and were just terrible, terrible hacks.
I went through more than one project where we spent a tremendous amount of time generating these things, they collapsed under their own weight (you just can't reason well about these things once relationships go past 2D), they'd all get discarded, and then the real design work would begin, in code.
I argue, without proof, that without a language visual types of design will always have these problems. I also argue that it is not incumbent on me to provide that proof. The power of Turing complete languages and math has been proven. A viable alternative needs to prove not only that it is equal to the existing approach, but is better in some important way.
I don't see much guidance either. It appears from the brief guidance text ("Purchase a license for yourself" vs "Purchase a license for others." that "Individual" is for personal use, and "Enterprise" for use within a legal entity employing multiple individuals - but I am grasping for straws here.
{kind=link}