> Really enjoying @RapGenius’s latest mix tape, “I Have No Idea How Distributed Systems Work”.
I guess someone didn't take their history lesson: In the opinion of a lot of people here Heroku was very close to perfect. Then they attempted to scale their approach and expand to different platforms. In this process they created a whole different product that they kept marketing as the original thing.
That is the problem.
Solving it isn't really that hard. As a thought experiment consider: 1.) The system was working nicely. Leaving it that way and adding no further customers would have left rapgenius happy. 2.) Adding a new, completely separate pool could serve more customers with the same needs as rapgenius.
I'm not saying this is an optimal soulution, I'm just pointing out that unless they were loosing money in their previous configuration, Heroku didn't need to change to the new architecture, -they chose to.
Sometimes. But I don't understand why they couldn't partition to sidestep those orders of magnitude. Since you have actual knowledge of the system, could you give the 30-second version? It looks from the outside like they just didn't make nonblocking load balancing a priority, rather than that feature being harder than the rest of their work.
Same here, I don't understand. The problem is that at a given size they can't use their "intelligent routing" anymore, but afaik no customer of theirs has that size, so why don't they just make as many copies of "old Heroku" as needed? Then they can just use the DNS to select the right shard, and route within shards.
It's like: "Sorry, we're full, go see our competitor. Oh, and by the way, our competitor is us." You're never too large, problem solved.
I don't want to reveal specific (and perhaps confidential) information about Heroku's architecture, but I can tell you a few things about working in AWS in general.
One: routing traffic in AWS typically means ELB. ELB doesn't necessarily give you fine-grained control over per-application routing.
Two: Proxies don't always send a single HTTP request per TCP connection.
Three: In streaming-data startups, I think it's pretty common that a customer does something inefficient, scales rapidly over the course of a week or two, and then realizes too late that their initial design is no longer suitable for their traffic load. Sometimes a single customer makes up a shockingly large proportion of your traffic load--and this load is hard to predict.
Four: The routing infrastructure for any given app still requires multiple load balancers in multiple availability zones. That means shards are more expensive--in terms of nodes and cost.
Five: Big systems come with lots of moving parts. It might be impractical to create an isolated, fault-tolerant copy of two hundred services for each reasonably-sized customer. There are... all sorts of issues with distributing state.
Thank you for the insight. 3, 4 and 5 are probably the reasons why they don't do it. They could, but it would be harder to operate, a bit more expensive and a lot less elastic. And maybe some customers at some points in time are, in fact, too large for that strategy.
As for 1, they do use ELB now, I don't know if they did during the "intelligent routing" era. It is only possible to create up to 10 different ELBs with a standard AWS account, but something as large as Heroku does not have the same limits.
I don't really understand point 2, could you explain what you mean? I can see how keep-alive can be a problem with some configurations but if you use the DNS to select the shard it shouldn't be a problem (you have one balancer per shard, with ELB it means different CNAME targets).
I feel like Heroku might get some benefit from looking into Lagrange System's load balancing technology ... not suggesting they buy it persay, but they have a pretty compelling way of doing things without the need for node-to-node coordination.
The point "they created a whole different product that they kept marketing as the original thing" is valid, but pretty much everything else you wrote was wrong.
The system could only be left alone if none of their customers grew and they didn't add any other customers. RapGenius alone may have grown enough to necessitate architectural changes.
The poor (no?) communication about the changes is the only thing they did wrong.
I'm now working on my third distributed high performance enterprise storage cluster. SCSI requires a certain (high) level of consistency per LU. And availability... and I'm delivering performance?
What? How could that be possible?
This blog post has so many assumptions about how nodes can and should behave that it's almost unreadable.
Faulty network? Get two fabrics. Nodes going down? RDMA to non volatile ram, and fail the I/O to the other node. This works for all your banks, airlines, governments, etc.
Heroku could do much better, but really: most of these startups should be hiring some ops people and design their own architectures already!
You're right: reliable fault-tolerance between two nodes in datacenters with dedicated physical hardware and isolated network links is easier than distributing state over a hundred geographically disparate nodes in in virtualized, multitenant environments backed by unreliable hardware abstractions.
My point was to complain about what RapGenius needed by describing an extreme that doesn't exhibit the behaviors your post describes. However you were speaking in terms of Heroku, and my post reads like it's trying to deride that. My comment reads pretty awfully, actually.
I guess I'm just frustrated with how much I hear about cloud services solving the "ops problem" when in reality all I see are people ignoring having a rigorous architecture for their applications.
There are extremes that solve just about any problem RapGenius is facing, because I bet you their traffic, I/O and CPU profiles are not that difficult of a problem to solve for their specific case.
I highly doubt that RapGenious needs over a hundred geographically disparate nodes in a virtualized multitenant environment, (notably because they are the one tenant!), but somehow that's what they're using and they don't understand what it means for them.
I'm sorry that previous comment sucked, and possibly sorry for this one.
Heroku operates in EC2, which is an Amazon service providing virtual machines spread across several datacenters. Rapgenius' nodes, as well as all of Heroku's internal infrastructure (e.g. routing) run as EC2 virtual machines. EC2 VMs are multitenant environments because you share them with other virtual machines. The disk, CPU, and network are all virtualized, shared resources, with wildly varying latency, throughput, and reliability characteristics.
RapGenius doesn't need a hundred nodes to do their routing, but Heroku does, because they're responsible for lots of customers pushing a large volume of traffic. Their routing infrastructure needs to share global state about which dynos are available for which applications, (and which versions of those applications) belong to a given HTTP request, and that routing infrastructure is broadly distributed. I'd phrase their routing TCP load as "nontrivial", in the sense that if I had to build a system like this on physical hardware in, say, Portland, I'd start by buying five floors in the Pittock building.
That's not to say Heroku's architecture is optimal, just that their problem is not as easy as it may appear.
[edit] As for why companies choose to run in a heavily virtualized environment which has so many drawbacks... it comes down to a tradeoff in time, personnel, and costs. Running in EC2 allows for dramatically shorter lead times in hardware acquisition--and when your customers can increase their traffic by an order of magnitude without warning, I think that comes in handy. It also frees them from running their own power, network, physical security, hardware acquisition pipeline, associated vendor contracts, etc. I suspect both Heroku and RapGenius have weighed these costs carefully, but I don't really know their specific constraints.
I don't understand this post. It starts off by insulting rapgenius for wanting working intelligent routing, and concludes by showing a way to hook up intelligent routers at scale and maintain performance.
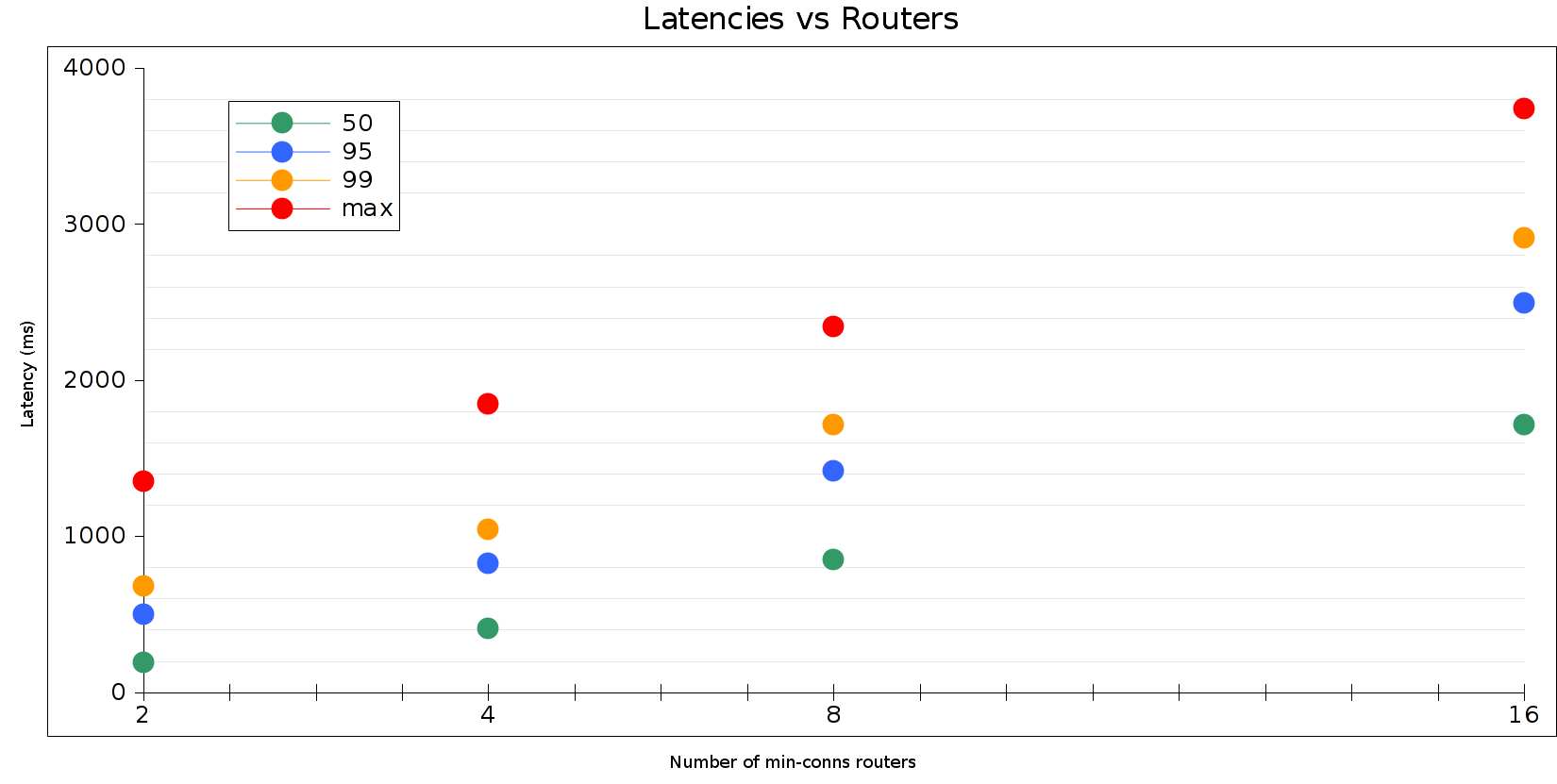
These simulations take roughly a minute or so each, for the samples I used in the post. I avoided filling in the chart because I was pressed for time. I'm unemployed and already spent ~40 hours on the post, haha.
Consistency applies because a least-conns load balancer requires state: it needs to know how many connections are open for each node. A distributed least-conns load balancer requires distributed state.
This is problematic because the convergence times for state like "connection counts" between load balancers in different datacenters could be significantly higher than the rate at which that state itself is changing, and the cost to getting that state wrong is significantly higher latencies. That's where you start having to make CAP and latency tradeoffs.
While I didn't state thate it is CAP isn't applicable one interesting point is that CAP concerns itself with distributed computer systems.
While I guess almost all systems built on top of heroku almost by definition needs to be distributed in some way heroku itself doesn't need to be. (Not saying it isn't.)
{kind=link}
I guess someone didn't take their history lesson: In the opinion of a lot of people here Heroku was very close to perfect. Then they attempted to scale their approach and expand to different platforms. In this process they created a whole different product that they kept marketing as the original thing.
That is the problem.
Solving it isn't really that hard. As a thought experiment consider: 1.) The system was working nicely. Leaving it that way and adding no further customers would have left rapgenius happy. 2.) Adding a new, completely separate pool could serve more customers with the same needs as rapgenius.
I'm not saying this is an optimal soulution, I'm just pointing out that unless they were loosing money in their previous configuration, Heroku didn't need to change to the new architecture, -they chose to.