Some information from Anandtech's deep dive into Apple's "big" Firestorm core.
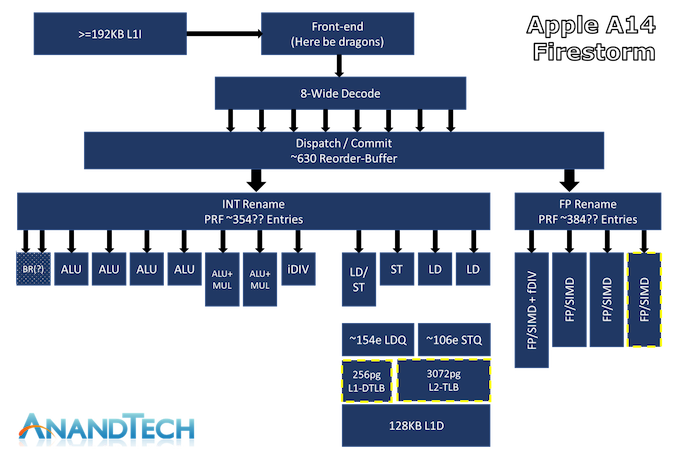
>On the Integer side, whose in-flight instructions and renaming physical register file capacity we estimate at around 354 entries, we find at least 7 execution ports for actual arithmetic operations. These include 4 simple ALUs capable of ADD instructions, 2 complex units which feature also MUL (multiply) capabilities, and what appears to be a dedicated integer division unit. The core is able to handle 2 branches per cycle, which I think is enabled by also one or two dedicated branch forwarding ports, but I wasn’t able to 100% confirm the layout of the design here.
On the floating point and vector execution side of things, the new Firestorm cores are actually more impressive as they a 33% increase in capabilities, enabled by Apple’s addition of a fourth execution pipeline. The FP rename registers here seem to land at 384 entries, which is again comparatively massive. The four 128-bit NEON pipelines thus on paper match the current throughput capabilities of desktop cores from AMD and Intel, albeit with smaller vectors. Floating-point operations throughput here is 1:1 with the pipeline count, meaning Firestorm can do 4 FADDs and 4 FMULs per cycle with respectively 3 and 4 cycles latency. That’s quadruple the per-cycle throughput of Intel CPUs and previous AMD CPUs, and still double that of the recent Zen3, of course, still running at lower frequency. This might be one reason why Apples does so well in browser benchmarks (JavaScript numbers are floating-point doubles).
Vector abilities of the 4 pipelines seem to be identical, with the only instructions that see lower throughput being FP divisions, reciprocals and square-root operations that only have an throughput of 1, on one of the four pipes.
> This might be one reason why Apples does so well in browser benchmarks (JavaScript numbers are floating-point doubles).
Reminder that browsers try to avoid using doubles for the Number type, preferring integers with overflow checks. Much of layout uses fixed point for subpixels, too. Using doubles all the time would be a notable perf regression.
Where are you getting that? I thought Intel was at 180 physical integers registers for the same core microarchitecture shared by both desktops and servers.
If you have a source I'm happy to read it but otherwise I think you're confused. Especially about Intel client and server cores having different numbers of registers. The lowest level difference between them I've heard of that wasn't features being fused off is different L3 cache sizes.
One of the reasons Apple does so well in browser tests is that ARM now has instructions to increasing the performance and decreasing the power draw of JavaScript operations.
It’s simply matching the c86 float to int conversion, because JS specifies that behavior in the spec - all this instruction does is even the playing field it isn’t some magic instruction that does more than x86 does.
At a logic level there are no changes to the expensive part of rounding, only changes to the overflow values in the result.
WebKit measured this to be an improvement of less than 2%. So it is certainly "one of the reasons", but certainly not a driving one. (Plus, it's ARMv8.3+.)
JSC didn't even use that instruction when most of the benchmark was done. It has absolutely nothing to do with it, the idea floated or amplified by Grubber / DaringFireball which I believe he never actually goes back to correct it even after the fact was shown.
Much like his idea of $149 AirPods were made close to BOM cost. And that is how the whole world went on to believe all the wrong information.
If you drop backwards compatibility, you can get a lot of headroom for better performance.
Apple is in a unique position of being able to force a new architecture on its customers, without losing them. They have done it twice. They even aren't exactly compatible with normal ARM, due to a special agreement with ARM Holdings.
Intel had I960, quite cool and successful, and could not capitalize on it in the long term for low-power devices. Intel bought rights to ARM, and could not capitalize on it in the long term either, even though ARM was well-suited for battery-powered devices, and sold it!
Intel used to be the king of data centres, using an architecture from 1980s, extended and pimped up to the brim — but still beholden by backwards compatibility. And a king it still is. But this pillar seems to shake more and more.
I don't think this is a result of poor engineering. It was, to my mind, a set of business bets, which worked well, until they didn't any more.
Apple's CPUs are compatible at the userspace level with normal ARM. At the kernel level, I only know of one architectural violation so far (other than adding custom optional stuff): the M1 has the HCR_EL2.E2H bit forced to 1, which forces hypervisors to use VHE mode (non-VHE operation is not supported, which is a violation of the arch spec). This only matters for hypervisors, as regular OS operation doesn't care about this.
It is true that Apple implemented a bunch of custom optional features (some of which are, arguably, in violation of architectural expectations), and they definitely have some kind of deal with ARM to be able to do this, but from a developer perspective they are all optional and can be ignored. I don't think Apple exposes any of them directly to iOS/macOS developers. They only use them internally in their own software and libraries (some are for Rosetta, some are used in Accelerate.framework, some are used to implement MAP_JIT and pthread_jit_write_protect_np, some are only used by the kernel).
Their AMX instructions, and those decompress instructions you found in user space are the exact kinds of things even regular architectural license holders aren't allowed to do, even hidden behind a library.
They very clearly have a special, Apple-only relationship with ARM.
AMX is available in userspace, but only used by their Accelerate.framework library. Apple does not document or expect them to be used by any apps, and I expect they'd reject any App Store submissions that use them, as I doubt they guarantee their continued existence in their current form in future CPUs.
FWIW, the compresssion instructions are used by the kernel, and I don't even know if they work from userspace. I've only ever tried them in EL2.
I'm not sure if this is the right spec, but it repeatedly references a section "Behavior of HCR_EL2.E2H" that I can't find anywhere in the 4700-page PDF "Arm® Architecture Registers, Armv8, for Armv8-A architecture profile"
Gah, I copied that link wrong. I meant to reference https://cpu.fyi/d/98dfae#G23.11082057, which is that specific section about HCR_EL2.E2H's behavior.
One of the advantages of the M1 is that instructions are fixed size. With x86 you need to deal with instructions that can be anything between 1 and 15 bytes.
As I understood it, it means you can't look at the next insn before decoding the current one enough to know where the next one starts. Meanwhile, arm can decode insns in parallel.
Now I wonder why x64 can't re-encode the instructions: Put a flag somewhere that enables the new encoding, but keep the semantics. This would make costs for the switch low. There will be some trouble, e.g you can't use full 64bit values. But mostly it seems manageable.
> As I understood it, it means you can't look at the next insn before decoding the current one enough to know where the next one starts. Meanwhile, arm can decode insns in parallel.
You're right but not for this reason. The important part is the pre decode, which does exactly this merging of bytes in macro ops. Each cycle, skylake can convert max 16 bytes in max 6 macro ops. These macro ops are then passed to the insn decoders.
Which is impressive, if you think about it. But it is also complicated machinery for a part that's basically free when insns are fixed width and you wire the buffer straight to the instruction decoders. Expanding the pre decoder to 32 bytes would take a lot of hardware, while fixed width just means a few more wires.
The same technique could be extended to cover all of them and and it's not so difficult to implement this in verilog.
As long as this state machine runs at the same throughput as the icache bandwidth then it is not the bottleneck. It shouldn't be too difficult to achieve that.
But it is definitely extra complexity, and requires space and power.
Note how this returns a length, i.e. you can't start the state machine for predecoding the next instruction until you finished decoding the current one. This means longer delays when predecoding more macro ops. I don't know what the gate propagation delays are compared to the length of a clock, but this is a very critical path, so I assume it will hurt.
Then again, both Intel and AMD make it work, so there must be a way, if you're willing to pay the hardware cost. Now I think about it, the same linear to logarithmic trick for adders can be done here: Put a state machine before every possible byte, and throw away any result where the previous predecoder said skip
That's a good solution and it probably wouldn't be too expensive, relative to a Xeon.
This also demonstrates where it really hurts is when you want to do something low cost, and very low power, with a small die. And that's where ARM and RISCV shine. The same ISA (and therefore toolchain, in theory), can do everything from the tiniest microcontroller to the huge server. This is not the case for x86.
The implication of their comment is x86_64 is EoL and a new architecture is necessary to continue improvements (this is not my own opinion, just how I read the comment)
Did they really try though? The Surface RT always felt like a tentative "what do you think?" that got thrown under the bus pretty quick as soon as there was any whining.
When Apple rolls out a product, there's some transitional overlap, but you can see them getting ready to burn their viking ships in that period. Microsoft's efforts always have lacked that kind of commit factor. IMO.
> If you drop backwards compatibility, you can get a lot of headroom for better performance.
Far less than a lot of people probably think though. AMD has an excellent x86 core, faster single threaded and throughput than the M1, on a generation older process technology, and quite possibly a smaller design and development budget than Apple, although not so power efficient.
>Apple is in a unique position of being able to force a new architecture on its customers, without losing them.
Apple's, in marketing speak, brand permission has given them extraordinary latitude over the past 15 to 20 years. They've been able to get off with making abrupt transitions and other relatively wrenching choices that tech pubs and doubtless forums like this wailed about but which their customers were mostly fine with. Things that Microsoft and WinTel laptops, for example, couldn't with respect to ports, limited options, etc. couldn't.
The difference there is Apple's customer is the actual end customer, the user, while Microsoft's customer is the OEM. It's the OEM Microsoft sell the software to (generally speaking), and who actually decides what devices get made and what their features are, not Microsoft.
As a result Microsoft has to worry about what the OEMs want and how they will use the product. In contrast Apple only cares what the end user wants, what their experience is, what features they get and how they work.
An OEM cares about whether they're making ARM laptops or Intel laptops. They care about and want input into the implementation details. An end user doesn't care if Photoshop is running on an ARM chip or an Intel chip, they care about how well it runs and what the battery life is. They (generally speaking) don't care about the implementation details.
Apple moved from 68k to PPC, and then to Intel. Binary transitions like those are not new, and are made easier by an OS that is architecture agnostic from very early on.
It's not so hard for the OS to be architecture agnostic. Linux runs on lots of architectures, and also Windows NT was portable enough to run on MIPS early on and also runs on ARM in addition to x86.
The main challenge is seamlessly migrating users to the new platform and Apple did a great job at it using Rosetta.
Both Linux and especially Windows struggle at this because they lack something as well integrated as Rosetta and require all applications to be recompiled to a new architecture.
Microsoft could have ported Office to MIPS, Alpha, PPC, and Itanium. I don’t think IE ever had a PPC port. The same applies to Visual Studio. When Alphas started appearing, that’s all I needed to be happy - a way to use email, to browse the web and use Altavista, and Visual Studio so I could write programs. It’d be a different story.
Holy crap, man - I read two sentences into your comment before literally hitting reply to say ‘as a long-time Mac and iOS dev this is one of the most logical and undeniable statements I’ve ever heard’.
I read the rest after typing this.
Intel was...it was king.
To be honest - Apple actually got some pretty damn good performance out of the PowerPC chips and architecture - my Quad-Core G5 tower with 16GB RAM is still used for finalization of my music projects, due to its insanely smooth performance - and tbh coming from a very experienced user of modern Macs it still kicks ass.
To be fair said phone company is the largest public company in the world by market cap, using a process provided by the eleventh largest public company in the world by market cap.
Well, the roots of the technology came from PA Semi, which was founded with big names who had a long tradition and experience in the industry. They specialized in high performance power efficient processors for embedded, which happens to fit very well with what smartphones need. But their very first design (a PowerPC front end, before Apple bought them) was already quite impressive.
Strap a lot of cash and volume behind that after they get bought, and the results speak for themselves. There is no shame in it. Intel has been stumbling at the moment, but others were stumbling in the decade from Core 2 to Skylake.
I mean they acquired PA more than a decade ago now, and have released multiple new generations of chips since then, how long do we keep saying PA is the source of all the performance?
PA Semi hasn’t been a company for quite some time now. They have joined a team of Apple engineers, and that team has changed quite a bit in the last decade. It currently does not have much in common with PA Semi when it still existed.
To be fair, the x86 is a completely shit architecture, no matter how many billions of dollars and billions of transistors you throw at it. There are clearly so many things that x86 does that no sane person would do if making a clean design today.
"There are clearly so many things that x86 does that no sane person would do if making a clean design today"
and
"x86 has been a continuously supported backwards compatible architecture for 35 years, and enabled the existence of most computers for most of those 35 years"
are basically saying the same thing. Depending on which way you look at it, Intel can feel bad about it, or feel good about it.
I bet there's more than one integer division unit per core.
When I've been micro-optimizing performance-critical code, integer division shows up as a hot spot regularly. I assume most developers don't think about the performance implications of coding up a / or % between two runtime values, preventing the compiler from doing any strength reduction. Apple must have seen this in their surely voluminous profiling of real-world applications.
I think you got the point most people miss - apple had a unique ability to profile every app on the Mac and iOS App Store, possibly in an automated way, as part of the app submission pipeline. Intel and AMD could go out and profile real work applications, and I’m sure they do, but to get to the same level of breadth is probably not possible.
It's also worth noting that Apple truly has the whole stack under their roof, including the team that maintains their C compiler and optimises LLVM's ARM machine code output. Intel has their own C compiler too, but one wonders to what extent they can profile real commercial software compiled using it, and feed that profiling knowledge back to the silicon designers in a useful way. The existence of AVX-512 makes me doubtful of that.
Let's enumerate what Apple has access to in more detail:
- third-party apps (in bytecode form)
- first-party apps
- the kernel
- a vast array of performance-critical libraries
- c/swift compilers
- machine code optimizers
- silicon design
- product stakeholders
The difference is that with Apple, the interaction between the various layers in the stack would be much lower friction than between Intel, AMD and Microsoft. The Apple Silicon team are truly single-customer. Equally as importantly, the Apple Product teams are truly single-buyer (eventually) and unlike Microsoft which has to split loyalties between Intel, AMD, ARM, and three dozen OEMs with their own motherboard designs tying all these bits together.
And unlike Intel or Microsoft, everyone at every layer of Apple knows that their success will ultimately be judged on the same, singular metric: the quality/performance of the Apple product being released in September, and then the Apple product being released next March. That kind of unified focus is almost unheard of in the commodity PC space.
Right. Intel controls silicon design, and a compiler hardly anyone uses.
To get the same level as access as Apple, Intel would have to cut a deal with Microsoft for access to their most sensitive telemetry data (and - likely - also to modify windows to collect more).
I think it's quite unlikely that MS would agree to that readily, if at all.
But because Intel (mostly) sells commodity parts, any effort improving compilers has a limited ability to benefit Intel without also benefiting competitors (i.e. AMD Ryzen/Epyc). Compiler improvements also benefit owners of existing devices, which reduces the pressure for customers to trigger a hardware upgrade cycle. However you cut it, improving x86 compilers doesn't improve Intel's profitability in a competitive x86-dominant market.
Apple doesn't have any such conflicting motivations because they sell the product rather than commodity parts. For Apple, improving the compiler as a unified part of the Apple Silicon development process means they can sell a better product with the same unit cost, with only residual benefit to competitors that don't have access to Apple Silicon hardware.
All the Intel development tools have been freely available to everyone for a while now...
A large part of them are based on Open Source components like gcc or llvm, and most modifications have been contributed upstream.
It's the packaging of all tools and libraries that Intel provides, extending to much more than "a compiler".
It's true that having a single stack makes things more efficient, but it also makes the process less adaptive. Although Apple seems to have a policy of buying out/copying successful software and integrating them into the OS, they can't buy everything. So eventually the more open/diverse ecosystem is going to have the better value proposition - a computer is a general-purpose device, and the less it can do the less useful it is. Of course this assumes Apple never gets market dominance where it surpasses all other companies combined, but phone sales are maybe 20% of the market and the laptop sales are only 8% of the market, so this doesn't seem likely to happen.
tl;dr 80 developers working on an open stack, even with coordination friction, are going to outperform 20 developers on a closed stack.
Your tl;dr assumes that the 80 developers are going to coordinate at all as opposed to silo themselves with duplicative efforts (e.g. GCC, Clang, MSVC; Intel Core, AMD Ryzen; Windows, Linux, BSD).
It also assumes that more developers is inherently better. For a rebuttal, see The Mythical Man Month.
I see duplication as a good thing. For every app on the App Store there are 1.5 Android apps. These extra apps mostly likely do similar things, but they offer extra features or perhaps are implemented more efficiently. In comparison the Apple apps will not offer these extra features/performance, following a one-size-fits-all approach. The more diverse ecosystem wins, because people have never really prioritized eye candy over usefulness. Of course, economically Apple development is more profitable, the same way that COBOL development is more profitable than webdev, but this is only a short term effect.
You're thinking about it wrong. It's not 1 app on iOS for every 1.5 apps on Android. For any given app in a competitive space, there are probably twenty choices on iOS and thirty choices on Android.
It's fair to say that three choices is better than two, but every additional choice will have diminishing returns. And at some point, the chances of an additional choice having any novel appraoach or distinctive features approaches zero.
Sure, I just meant there's a Microsoft store so if the there was something particularly advantageous to having access to an app store, Intel or AMD are not completely in the wilderness here.
Not completely in the wilderness sure. But they also have many operating systems to consider. The other obvious ones are Linux, BSD, and, until very recently, macOS. Are you sure it's possible to do a micro-optimization for one without nerfing the others?
Does the actual machine code doing computations really differ that much based on the OS? I'd guess the differences are just that you call different libraries and maybe a different calling convention, but nothing that would impact code running single-threaded without preemptions much.
This is almost perfectly backwards. Intel does this sort of profiling _extensively_, and it guides their decision making to a fault. Apple's advantage in this regard is that the CPU architects can (and do) ask people writing software "if we made X faster, what could you do with it that you don't do today because it is slow?" That will never show up in a trace.
I'm a little skeptical of this, this is the same as saying Tesla is going to have self-driving because they can record all the decisions current Teslas make. The truth is that it's very path dependent. For Tesla this means you can't optmize getting into the scenario in the first place and for Apple it means you can't actually know which code path will actually be regularly used.
For the general market perhaps - but let's say you're contracted to build self-driving trucks for UPS in particular and realize that UPS trucks almost never turn left[1] you could probably leverage that to decrease sensor density on one area of the vehicle since it's not as often used by your expected market - the vehicle might occasionally need to pause and do some extra work to make up for that deficiency but when the vehicle is on the happy path it can save some time.
This example is pretty artificial - I can't really think of an optimization you could make knowing that you rarely turn left (maybe something with the axel?) but yea - more data means that you can turn your product to behave better in optimal situations - this comes at a cost but if you have a big stack of data you can make it so that your product generally wins that trade off most of the time.
> This example is pretty artificial - I can't really think of an optimization you could make knowing that you rarely turn left (maybe something with the axel?)
A real-world example are old NASCAR race cars. Optimized heavily for turning left, they were quite good at it at the expense of turning right.
The fact that Intel and AMD apparently don't prioritize integer division could suggest that their profiling suggests it's not worth it, but with Apple's transistor budget at the moment they can afford it.
Also keep in mind that this Xeon might not be really made for number crunching (not really sure)?
> The fact that Intel and AMD apparently don't prioritize integer division could suggest that their profiling suggests it's not worth it, but with Apple's transistor budget at the moment they can afford it.
An other possibility is that Apple has a very different profiling base e.g. iOS applications, whereas Intel and AMD would have more artificial workloads, or be bound by workloads / profiles from scientific computing or the like (video games)?
Intel greatly improved their divider implementation between Skylake and Icelake. The measurements in the OP are on Skylake-SP, prior to these improvements.
Apple's chip designers have the advantage, I assume, of being able to wander down a hallway and ask what the telemetry from iOS and MacOS devices are telling them about real-world use.
They also have the advantage of controlling the compiler used by effectively the entire development ecosystem. And have groomed that ecosystem through carrots and sticks to upgrade their compilers and rebuild their applications regularly (or use bitcode!)
A compiler code generator that knows about a hypothetical two divide units (or just a much more efficient single unit) could be much more effective statically scheduling around them.
I’d guess that the bulk of the software running on the highest margin Intel Xeons was compiled some years ago and tuned for microarchitectures even older.
>A compiler code generator that knows about a hypothetical two divide units (or just a much more efficient single unit) could be much more effective statically scheduling around them.
I'm still completely blind to how they are actually used but GCC and LLVM both have pretty good internal representations of the microarchitecture they are compiling for. If I ever work it out I'll write a blog post about it, but this is an area where GCC and LLVM are both equally impenetrable.
I meant the actual scheduling algorithm - from what I can tell GCC seems to basically use an SM based in order scheduler with the aim of not stalling the decoder. Currently, I'm mostly interested in basic block scheduling rather than trace scheduling or anything of that order.
Most of Intel's volume is probably shipped to customers who either don't care or buy a lot of CPUs in one go, so the advantage of this probably isn't quite as apparent as you'd imagine.
What can definitely play a role is that (I don't think it's as much of a problem these days, but it definitely has been in the past) is the standard "benchmark" suites that chipmakers can beat each other over the head with e.g. I think it was Itanium that had a bunch of integer functional units mainly for the purpose of getting better SPEC numbers rather than working on the things that actually make programs fast (MEMORY) - I was maybe 1 or 2 when this chip came out, so this is nth-hand gossip, however.
If it was intended to be used in the cloud for example it's going to be doing more work but probably designed around a memory-bound load rather than integer throughput.
I'd quibble with whether folks understand the performance implications. I think most people know division is expensive. It's just non trivial to remove it. If it was that easy to replace, it would be done in hardware and division wouldn't be expensive anymore.
I thought "division is slow" was one of the more widely-known performance heuristics. I genuinely wonder how much of the division load in typical programs is an essential part of the problem vs. programmers not knowing/caring about slow division.
> When I've been micro-optimizing performance-critical code, integer division shows up as a hot spot regularly.
Now I'm really curious. In my experience, integer division practically never happens (except by powers of 2 that are easily optimized down to a shift), to the point where I was frowning in puzzlement about why Apple spent resources optimizing it.
How is the code you are looking at, bottlenecking on integer division? What on earth is it doing, to make that a frequent operation?
AnandTech says there is one separate integer division unit in the A14 Firestorm which is what the M1 is based on. The article even mentions an increase in latency for integer division for the A14.
This is probably the most unusual CPU comparison I've ever seen.
The Xeon processor that he's comparing against is a six thousand dollar processor from two years ago that is absolutely destroyed by modern processors that cost less than one eighth of the price.
It is expensive because it is designed for 8-processor systems, with 4.5TB memory support, and it runs cores that are glacially slow individually, but meant to make up for it by the massive amount of them (24).
Finally, the test is effectively a single-core test, since he's measuring the execution units.
I think Apple deserves some kudos for having delivered a chip that would be competitive on the open market (if it were available as such), but all of these ridiculous comparisons just don't paint a picture that has any dose of reality.
The M1 is one process node ahead of AMD and two process nodes ahead of Intel. With this advantage, the M1 is performance equivalent[1] to AMD Zen 2 processors (3XXX series, which is one architecture behind) but much more expensive. They are price equivalent[2] to AMD Zen 3 processors, but much slower total performance (though the M1 has about a 25% perf-per-watt lead against the 5600X when limited to the same power envelope). The integrated graphics, however, is a step above.
And before I get downvoted to hell, the easiest way to see the actual performance of the M1 as compared to other processors is to look at Apple-to-Apple comparisons (pun partially intended) by comparing benchmarks from an Apple M1 to an Apple Intel, and looking at that same processor off of the Apple platform compared against other processors.
If you look at Phoronix Apple M1 to Apple i7-8700B benchmarks (ignoring Rosetta benchmarks since those unfairly favor Intel), you'll see that they perform similarly (in some cases Intel pulls ahead, in some cases the M1 pulls ahead, and in some cases they tie). Then when you compare that 6-core processor to a modern AMD six core processor (5600X), the AMD processor is 33% faster in single-core and 80% faster in multi-core benchmarks.
1. Cut out the synthetic benchmarks, because they are provably biased (e.g. intel biased userbenchmark). Look for application benchmarks that depend on compute, like file compression, or software compiles, or even real-workload browser benchmarks)
2. At MSRP, before current issues with chip availability
Because anyone can plug the C++ into compiler explorer (godbolt) and get a result. He linked to compiler explorer a couple times in the article as well.
Phoronix recently did some benchmarks with AVX512 and while it was (modestly if I recall) faster, it was horribly worse in terms of performance per watt.
I really hope AMD doesn't adopt AVX512 and if they do I hope it's just the minimum for software compatibility.
On a related note, my Ryzen 2400G does not benefit from recompiling code with -march=x86-64-v3 in fact it seems a tiny bit slower. I assume Zen2 and 3 will actually run faster with that option.
If intel get on a smaller node that would benefit these wide registers energy wise. Like early AVX2 also would downclock, and run hotter. Its one of the reasons the VZEROUPPER instruction exists so the hardware can power down the upper half of these registers when not in use. If recall AVX2 on amd was basical just running 128bit hardware twice till Zen 2.
As the nodes get denser i am sure AVX512 will perform better power and heat wise.
As for AMD adding support I am sure they will just for compatibility reason.
> Speculatively, AVX512 processes multiplies serially, one 256-bit lane at a time, losing half its parallelism.
Sort of, in Skylake AVX512 fuses the 256-bit p0 and p1 together for one 512-bit µop, and p5 becomes 512-bit wide. So theoretically you get 2x 512-bit pipelines versus AVX2's 3x 256-bit pipelines (two of which can do multiplies.)
Unfortunately, p5 doesn't support integer multiplies, even in SKUs where p5 does support 512-bit floating-point multiplies. So AVX512 has no additional throughput for integer multiplies on current implementations.
p5 can do 512 bit operations, but not 256 bit, e.g. look at Skylake-AVX512 and Cascadelake (Xeon benched in the blog post was Cascadelake) ports for vaddpd:
The 256 bit and 512 bit versions both have a reciprocal throughput of 0.5 cycles/op, using p01 for 256 bit and p05 for 512 bit (where, as you note p0 for 512 bit really means both 0 and 1).
So, given the same clock speed, this multiplication should have twice the throughput with 512 bit vectors as with 256 bit.
This isn't true for those CPUs without p5, like icelake-client, tigerlake, and rocketlake. But should be true for the Xeon ridiculousfish benchmarked on.
If I'm reading this analysis [1] correctly, M1 has only one integer divider, but it appears to be almost fully pipelined as it can indeed start a new divide every other clock cycle.
The latency is also impressively good even at 64 bits, but the benchmark should not be div-latency bound in any case as, each division can be started without waiting for the previous division to finish.
edit: of course it is possible that internally the divider is not fully pipelined, but there are actually multiple dividers. It is only exposed as a single unit (i.e only a single port) because it wouldn't be able to start more than one operation per clock cycle in any case. If I had to guess, the additional SIMD dividers are repurposed for this, but that doesn't explain why 64 bit still has the same throughput as 32bit.
edit2: SIMD is on the same port as fdiv, not integer. fdiv has a throughput of 1 div per clock cycle!
Great and interesting work! The slowness of division operations is overlooked too often IMHO and is key to (my approach to) avoiding things like integer overflows (there may be a better way than dividing TYPE_MAX by one of the operands but I don't know an alternate technique). Pretty impressive if the M1 really can achieve two-clock-cycle division on a consistent basis.
May I offer a nitpicking correction? 1.058ns compared to 6.998ns is an 85% savings, not 88%. The listing you have suggests that going down to 1.058ns is a bigger speed-up than going down to 0.891ns.
(PS - Verizon's sale of Yahoo has been in the news lately so I thought of you and the other regulars of the Programming chat room the other day. Hope all is well.)
Depending on what you’re doing, you can usually just use the compiler intrinsics and check for overflow aka, `__builtin_mul_overflow` and similar instead of guarding against it.
Useful to know, but if we don't care about portability we can just write a function in assembler that checks the carry or overflow flag or whatever the architecture's equivalent is.
No, you can't. The status register is not part of the ABI on any major architecture. There is no guarantee that the compiler won't clobber those flags before (or during!) the function call.
I use compilers other than GCC more often than I use architectures other than x86_64 or aarch64. Using a GCC built-in is less of a good fit for me than using a small .s file in my project. YMMV.
Generally clang and GCC share the same set of builtins/annotations and most compilers offer similar sets of intrinsics (ICC generally also targets GCC/clang as a comparability target). I’m genuinely curious what compiler you encounter where this is an issue (MSVC?). Also For what it’s worth the optimizer generally can detect these kinds of patterns and replace them so even regular c/c++ code without intrinsics can generate the same thing.
" Is the hardware divider pipelined, is there more than one per core?"
Chaining the divisions (as a series of dependencies) would enable one to see the full latency of a single divide. You could use this data to estimate the number of divide units on the core.
In my real world benchmarks I’ve observed the same: the jump from avx2 to Avx512 is usually underwhelming. Is this widely recognized and understood or just anecdotal?
On the Xeon Phi, IIRC, it was an improvement. When it was added to larger power hungrier cores, it initial required downclocking for thermals, which defeated the purpose somewhat. I hear newer cores can do it with less impactful power limitation measures.
There was a time when division was expensive enough to look for alternatives, but nowadays with the M1 it seems that adding even one or two adds or shifts may end up to be more expensive than division. My goodness, how times have changed!
* Per core, the two processors actually (keep in mind based on Intel's TDP figure) have a roughly similar power budget i.e. 205/26 vs. 39/(4 or 8 depending on if you count the bigs, littles or both), so taking into account that the Apple processor is on a process that is something like 4 or 5 times denser it's not that surprising to me that its faster.
There are multiple choices used by different implementors. Quadratically convergent iterations like Newton-Raphson and Goldschmidt, and digit-by-digit algorithms like SRT are all common choices represented in mainstream hardware designs and software libraries (for both floating-point and integer).
Do you think the very fast division on M1 has any implications for 128/64 narrowing division as well? Do you know of a faster way than the method by Moller and Granlund? Do you plan on to include 128/64 division in libdivide?
And I asked this question before but the parent post got flagged so I'm trying once more: at the very bottom of the Labor of Division (Episode V) post [1], is it really possible for the second `qhat` (i.e. `q0`) to be off by 2? Do you have any examples of that?
I haven't yet read the Moller and Granlund paper, but its narrowing division using precomputed reciprocal would be a natural fit for libdivide. (libdivide does have a narrowing divide, but it is Algorithm D based).
Regarding the second question, it is possible to be off by 2. Consider (base 10) 500 ÷ 59. The estimated quotient qhat is 50 ÷ 5 = 10, but the true digit is 8. So if our partial remainder is 50, we'll be off by 2 in the second digit.
On Skylake-SP's AVX-512, instructions that previously were dispatched to port 0 or 1 get instead dispatched to ports 0 _and_ 1. So instructions like vpsrlq get zero net speedup from switching to AVX-512 from AVX2. Instructions that previously ran on ports 0,1,5 will now run on ports 0 and 5, for a speedup of at best 1.33.
Multiplication will depend on whether the chip has one or two FMA units. If so, you can run vpmuludq on ports 0 and 5, which is a 2x speedup compared to AVX2's ports 0 and 1. This 8275CL Xeon does have 2 FMA units.
All other things being equal, we have on average, and counting only the differing instructions, a throughput of ~2.27 instructions per cycle on the AVX2 loop, whereas it is somewhere around ~1.45-1.60 for AVX-512, depending whether you have 1 or 2 FMA units to run multiplications on port 5.
So based on this approximation, the AVX-512 code should probably run around 2*(1.5/2.27) ~ 1.33 times faster. Add to this that vpmuludq is actually one of the most thermally insensitive instructions around and will reduce your core's frequency by 100-200 MHz, and the small speedup you see is more or less explainable. (I actually do see some more noticeable speedup here when switching to AVX-512; 0.25 vs 0.21).
PS: The Intel Icelake and later chips also manage to achieve a throughput of 1/2 divisions per cycle for 32-bit divisors, and 1/3 divisions per cycle for 64-bit divisors.
PPS: Some of your functions could use blends. For example,
FWIW, llvm-mca estimates 448 clock cycles per 100 iterations of the AVX2 loop vs 528 cycles for the AVX512 loop with `-mcpu=cascadelake`. That suggests the AVX512 loop should be about 2*(448/528)=1.85 times faster.
llvm-mca is highly unreliable when it comes to AVX-512. It thinks 3 512-bit vpaddd, vpsubd can be run per cycle. Adjusting for that you get 622 cycles instead of 528.
* Would be wise to compare x86_64 under Rosetta as it'll support some AVX translation if I remember correctly.
* I didn't see use of Apple's accelerate framework. To comply with ARM64 additional custom Apple magic is within Private extensions / ops that should use higher level frameworks such as Accelerate
Rosetta2 supports up through SSE2. That's the latest instruction set to no longer be patented as of around 2020. They can use x86_64 only because AMD released x86_64 spec in 1999 (even though actual chips came much later).
I think a more likely explanation is that they supported everything that fits in 128 bit registers (the same as ARM NEON). Trying to emulate code using 256 bit registers on a machine with 128 bit registers is probably difficult and pathologically slow in some cases.
Has someone actually found out what instructions do what? I assume we won't get to play with them ourselves unless they get the Microsoft treatment over the hidden APIs
There may not be hidden APIs. They could only use those custom instructions inside public functions that everybody can call, such as those in the Accelerate framework.
I consider the hidden instructions to be at least close enough to being an API to not bother using another term (AFAICT legally ISA patents aren't considered APIs)
Sounds great but being limited to using an Apple OS is a show-stopper issue. I'd rather have a less good processor and using an OS that does not put constraint onto my usage
The Asahi Linux project already has upstreamed basic support, and hardware drivers are now being worked on. It's only a matter of time until M1 macs are practically usable devices on alternative OSes!
I don't contend that the time is finite but "usable" given that it's not only Apple hardware but new Apple hardware with from what I've heard slightly janky peripherals, may be relative.
Leaked info of M1X suggest slightly higher clock frequency and twice as many high performance cores. But 32GB memory which I think is very welcome for many.
Funny, what size screen are you on? My wife said the same and tbh I didn't even notice it was a paper towel (funny gag) on my desktop system. I may have just not paid attention.
I have just started to use a Mac M1 Mini, and am disappointed. It's incredibly slow to download or install anything. Hangs all the time, takes like 5 hours to install Xcode (it's done but the UI hangs leaving you to believe it has more to do). Hangs when cloning a git repo. Gets stuck anywhere and everywhere. Have to force kill everything and restart to knock some sense into it. I was always respectful of Mac users because Windows has had its problems in the past, but after using a Mac for the first time, I hate it more than ever.
I'm sorry you are having a bad experience. If you spend any time reading on the internet, you can easily see that your experience is a rare exception. Apple gives you 14 days to return it, no questions asked. I assume you returned a computer with so many issues. Good luck with your next computer choice.
uhhh... your mac might be broken. I have one and my friend has one. We both engage in cpu/gpu intensive workloads and this just doesn't happen. Still within the return window? Would be interesting to find out your fan is DOA or something like that...
Yeah it's pretty much brand new and for sure within the return window. Maybe there's something wrong with it. I was expecting cool fireworks for sure, but it's been nothing but a PITA thus far.
It should not be performing like this. I bought a base spec m1 mac mini for testing apple silicon applications on and it has ended up displacing a 2019 16" MBP unexpectedly - the mac mini is far faster in real world usage for me, and your workflow is exactly what I'm doing with it.
Just another to pile on, my 8gb m1 mba has made me stop using my xps 15 with 32gb of ram... that sounds maybe like a storage issue? yeah take it back!!
It's very difficult to follow and engage in technical posts like these benchmarking micro-instructions and so on, where on the face of it the product is simply falling on its face in the most basic use-cases.
Go to the store. You are not in any way getting the typical experience. This thing is by far the fastest computer I have ever touched in terms of UX responsiveness.
{kind=link}
>On the Integer side, whose in-flight instructions and renaming physical register file capacity we estimate at around 354 entries, we find at least 7 execution ports for actual arithmetic operations. These include 4 simple ALUs capable of ADD instructions, 2 complex units which feature also MUL (multiply) capabilities, and what appears to be a dedicated integer division unit. The core is able to handle 2 branches per cycle, which I think is enabled by also one or two dedicated branch forwarding ports, but I wasn’t able to 100% confirm the layout of the design here.
On the floating point and vector execution side of things, the new Firestorm cores are actually more impressive as they a 33% increase in capabilities, enabled by Apple’s addition of a fourth execution pipeline. The FP rename registers here seem to land at 384 entries, which is again comparatively massive. The four 128-bit NEON pipelines thus on paper match the current throughput capabilities of desktop cores from AMD and Intel, albeit with smaller vectors. Floating-point operations throughput here is 1:1 with the pipeline count, meaning Firestorm can do 4 FADDs and 4 FMULs per cycle with respectively 3 and 4 cycles latency. That’s quadruple the per-cycle throughput of Intel CPUs and previous AMD CPUs, and still double that of the recent Zen3, of course, still running at lower frequency. This might be one reason why Apples does so well in browser benchmarks (JavaScript numbers are floating-point doubles).
Vector abilities of the 4 pipelines seem to be identical, with the only instructions that see lower throughput being FP divisions, reciprocals and square-root operations that only have an throughput of 1, on one of the four pipes.
https://www.anandtech.com/show/16226/apple-silicon-m1-a14-de...