This blog post is quite different than Cloudflare's old pipeline. I can think of three fundamental differences.
(1) Cloudflare's pipeline used an old version of Citus. On that version, Citus was still a proprietary database that forked from Postgres. Since then, Citus became an extension of Postgres (not a fork) and went open source.
(2) Features highlighted in this blog post weren't available in the old version of Citus. Example features are hash distribution, distributed roll-ups, and sharding by site_id and partitioning by time.
These features help in two ways: (a) They simplify the overall pipeline quite a bit. You don't need to rely on a single Postgres node and Kafka queues to do roll-ups. (b) Your end to end price-performance improves by 4-5x. You can ingest larger volumes of data through sharding + time partitioning. You can also do parallel roll-ups inside the database. Neither of these were possible back in the day.
Postgres streaming replication and Citus' HA solutions have come a long way in the past three years. These points shouldn't be an issue in newer versions.
Overall, the database space is an exciting market, where products continuously evolve. This blog post presents a reference architecture that uses new features in Citus - that have been added in the past three years and that our customers are using today.
In a follow up blog post https://blog.cloudflare.com/http-analytics-for-6m-requests-p... Cloudflare released the following image https://blog.cloudflare.com/content/images/2018/03/Old-syste... with 'single instance PostgreSQL database (a.k.a. RollupDB), accepted aggregates from Zoneagg consumers and wrote them into temporary tables per partition per minute' as the description for the single Postgres instance depicted. The aggregation system described in the Citus blog distributes the aggregation work over multiple Postgres instances.
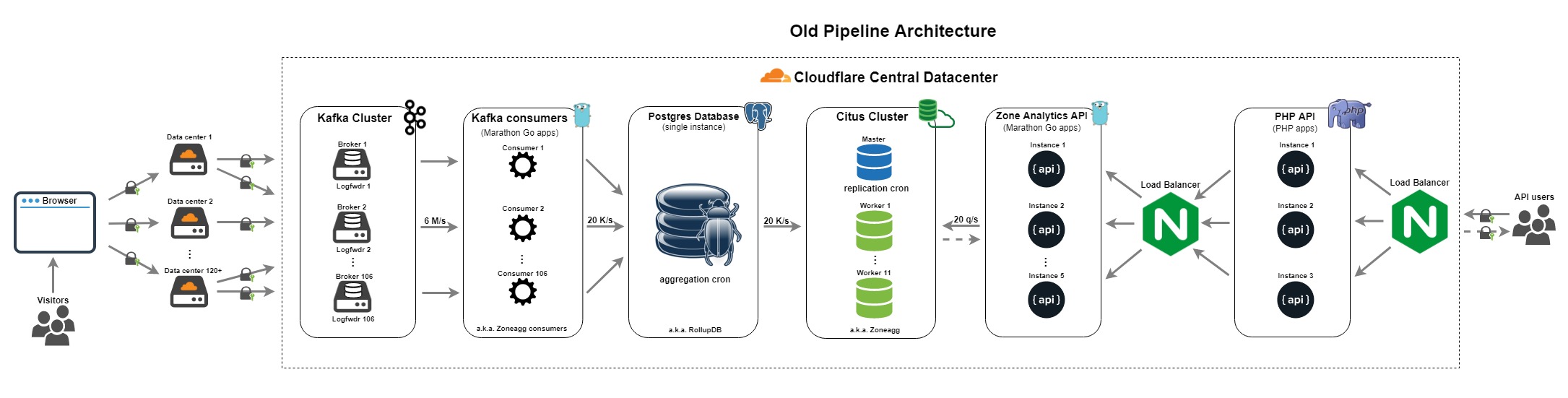{kind=link}
> We tested this approach for a CDN use case and found that a 4-node Citus database cluster can simultaneously:
> - Ingest and aggregate over a million rows per second
> - Keep the rollup table up-to-date within ~10s
> - Answer analytical queries in under 10ms.