When training over multiple GPUs, it's hard not to think about Ray (https://docs.ray.io/en/latest/train/train.html). Ray, as an open-source project, has exploded over the last few years and helps with the memory bottleneck by segregating memory and computing.
FYI, I am not affiliated with Ray. However, I did write the following paper on scaling data-parallel training for large ML models ;)
https://openreview.net/pdf?id=rygFWAEFwS
1. There is a lot more we want to do to make Ray better for working with large language models and for making training, serving, and batch inference work well out of the box.
2. The original post is about training, but we actually see even more interest in fine-tuning and serving with LLMs, in part because there are good pre-trained models.
3. For LLMs, we see a lot of interest in Ray + Jax or Ray + TPUs relative to what we see in other use cases.
Yes, but this will largely come down to whether the deep learning framework that you're using (PyTorch, TensorFlow, Jax, etc) works well in that setting. Ray is pretty framework and hardware agnostic and can be used to schedule / scale different ML frameworks on different types of devices (CPUs, GPUs, TPUs, etc), but the actual logic for running code on the accelerators lives in the deep learning framework.
Why isn't there a framework that does all this automatically for you?
I tried torch FSDP but it only managed to increase the memory to something like 150% of 1 GPU.
I eventually ended up sharding my model manually with .cuda() and .to() which works much better, but now I am limited to one module on one GPU and I would like to expand even more, and that would mean spinning up more nodes and splitting the model over how many GPUs manually.
I would be interested if anyone knows of a framework that manages this automatically and just works.
EDIT: BTW I am talking about model sharding not data parallelism which works very well with DDP.
I tried that as well, but maybe I did not use it correctly.
I did not see the full sharding that I was hoping for.
I only saw results similiar to FSDP.
>Why isn't there a framework that does all this automatically for you?
Check MosaicML if it might help in your case. I haven’t tried myself but they’ve most customizations and speed up optimizations I came across in the recent times
Nvidia's NCCL and AMD's RCCL provide parallelism constructs that really are hidden at the framework level (such as PyT).
However, I don't think that you would want to hide model, data, or tensor parallelism. It's too important a consideration for performance and training convergence impact.
At least in scientific computing, I've never observed effective means of automatic parallelism expressed across many nodes despite decades of research. I'm not optimistic this will be effective anytime soon.
Beyond the other answers, I’ll point out that pytorch is developing tools that will make doing this work by hand or implementing in a framework much easier. They’re building a native DTensor implementation and testing out SPMD-style distributed models with pipelining. DTensor is in torch.distributed, and the SPMD code is in the repo called Tau under the pytorch org on github.
Somewhat amazed, dang, that this topic is not discussed more widely here or elsewhere. There is a lot of HPC and DS expertise out there which lacks understanding of ML system architecture (in the sense of the deployed machinery in toto).
Her follow up post [1] is also recommended for those who (like me, are experienced but not in ML) finally had things click because of the OP writeup:
Large Transformer Model Inference Optimization (2023)
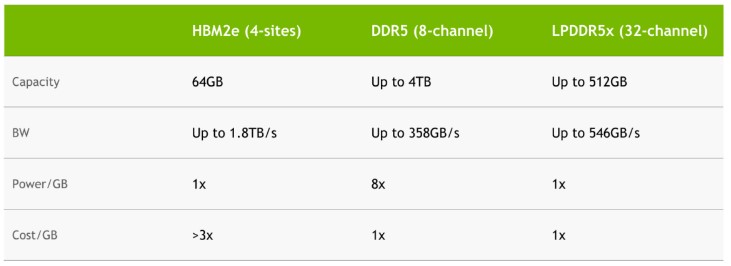
The bandwidth and latency is as much a bottleneck as the capacity is. That's why recent ML and GPU chips have moved to on-package "high-bandwidth memory." Even if you were to add more high-bandwidth memory off-package (via lots of parallel DIMMs, say), it's difficult to actually manage this memory well, because of a host of competing factors, including a) on-chip resources (controllers etc) that must consume area and power to manage the new memory, b) increased design cost for validating handling the extra (crappier than HBM) memory, c) software not knowing how to hide the (much higher) latency of this memory - deep learning isn't as good at memory hierarchies as CPUs are, d) a chip that has spare on-chip bus bandwidth for this kind of thing has wasted bus bandwidth. Et cetera.
So if you are building GPUs or AI accelerators, you tend to just go ahead and build this in.
AMD Radeon Pro SSG had 4 nvme slots on the card itself but that was 2017 but with direct storage API that might be able to have some gains for large models.
I could never get a solid answer wether that was presented as memory to the GPU or just as a PCIE switch with NVME drives hanging off one side and the GPU on another.
In principle they could be used with an API like DirectStorage RDMA or CUDA GPUDirect RDMA (which dates back to Kepler) and in this case they would never need to talk to the CPU, given appropriate software support. But it's not going to be presented as GPU memory ever, it's going to work like a block storage device you can do RDMA requests against, most likely.
Now technically - it all depends on what you mean by "as GPU memory" because PCIe is all RDMA anyway, even CPU-to-GPU is a RDMA operation. That's why there's the whole thing about "resizable BAR" etc - that's the aperture window in CPU memory that gets mapped in from the GPU memory.
So technically yes you can map those SSDs in "as GPU memory" via GPUDirect RDMA block storage (or DirectStorage), but you can do that with a regular NVMe SSD in an adapter card too. The SSG is just a "combo GPU+SSD card" in the same way QNAP makes those "combo network+SSD cards", but with a lot of fanfare/marketing around it.
To be absolutely fair, Fiji/Vega is a good design for that since it doesn't have a bunch of memory packages around it. But it wasn't what AMD trumpeted it as, as the LTT video describes, it was a very specific reaction to the question of 'workstation GPUs are using a lot of memory, HBM can't be scaled as high, how do we put more memory on a Fiji/Vega GPU for workstation users". And AMD's claims that HBM meant you could just swap everything around and not have to worry about framebuffer size were never true, the PCIe bus itself is not fast enough for that.
{kind=link}
FYI, I am not affiliated with Ray. However, I did write the following paper on scaling data-parallel training for large ML models ;) https://openreview.net/pdf?id=rygFWAEFwS
Also, another one of my papers talks about distributed training while reducing the communication bottleneck for distributed training: https://dl.acm.org/doi/pdf/10.1145/3447548.3467080