Sidenote: around half/a third of the article is on how to deal with Google IAM Auth. This is one of the things that puts me back the most from the modern Big Cloud and keeps me on Heroku, that it's such a behemoth of services and combination that you need such a complex setup for a very "simple" tool.
I like/prefer it a lot when you can simply put up a script, press 3 buttons and voila you have a fully working url. Even Google used to do that, I've built two libraries around Google's services, npm's `translate`[1] and `drive-db`[2], the former I no longer test on Google Translate even though it's supposed to be supported and the later it's using a more obscure plain JSON API to avoid Google Auth.
This is a great idea and wouldn't be too hard to port to a local solution, e.g. using Tesseract or similar. The idea of tuning your handwriting and using a markup language designed to be easily written by hand to make it easier to do the OCR, instead of trying to be perfectly general, is actually a great idea.
I can imagine one necessary enhancement (I would find it necessary anyway) would be to support crossing-through words with a line to "erase" them.
I guess my point is that this project is interesting because it doesn't depend so strongly on the OCR being perfect, as he's allowing to prescribe a handwriting style that helps it along. I just think it's a nice compromise, and something that I hadn't thought of previously.
Obviously the tech can always be improved, but I find this to be a secondary concern. Ideas can still be cool without worrying about implementation details. For instance, if the PoC works well enough, but you want better performance, then you can train a new OCR system specifically for it. You can break the project down into pieces, where each piece is an interesting challenge. Meanwhile getting 80% performance out of an existing solution allows you to build up a dataset to be used for improving it.
Ha I was going to say, I was trying to read receipts and Tesseract was having problems, those are machine-printed not hand written. Granted supposed to clean up/up contrast/etc... but yeah. Scanning a screenshot of a website though accuracy is almost 100% every time eg. just black/white text.
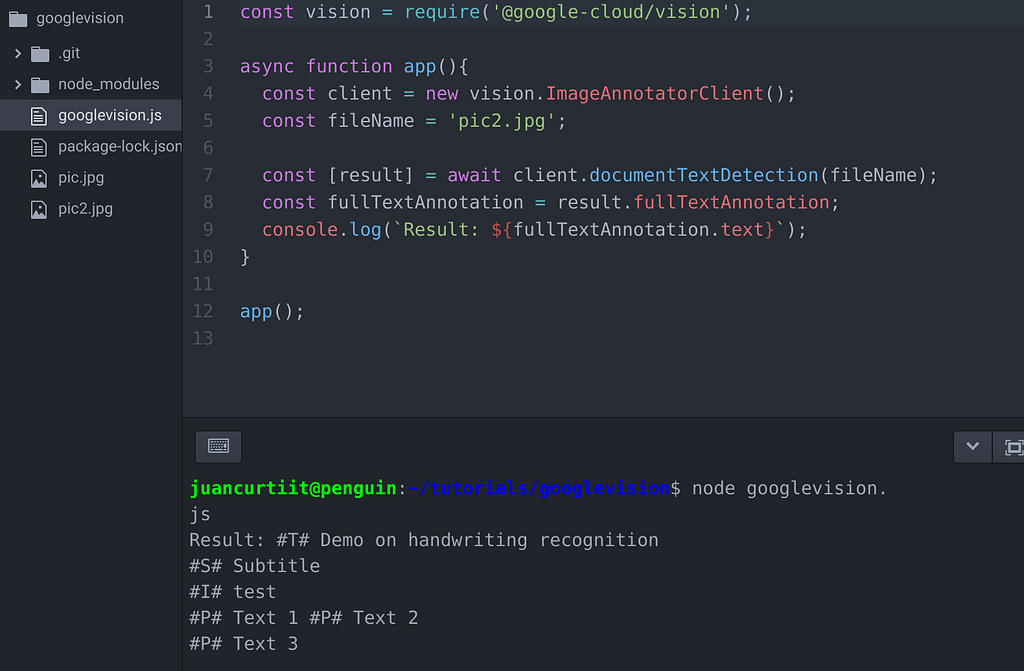
It's usually better to segment the text on the image (and twek the perspective if necessary) to help tesseract extract the text. All the "easy" preprocessing that can be done beforehand helps a lot. I understand that Google Vision Services doesn't need these kind of adjustments (or maybe they do them automatically?), which makes for an easier time/less code, but setting up the account sure looks like a lot of work from the article!
That's a good tip about the segmenting text, will have to keep that in mind next time.
I like the local aspect, one project I have in mind is a hand writing to printed letters for note taking/tablets. Not a new concept I think one drive has it, but it would be neat to train it on your own writing.
Nice tutorial, but seems like it would be much easier (and more user friendly) to concert to markdown instead of using his pseudo-tags for HTML. The only thing perhaps you'd need to handle differently than native Markdown is significant whitespace, but that seems like it would just need some minimal changes.
I completely agree, this would be suited so well for Markdown! Funnily enough I have been wanting to add this feature into a knowledge management app [1] I've been building. There have been so many times where our users have written something on paper and want to save it digitally to work on and organise later.
I used rocketbook for a time and it worked really well. Just the erasing and having to use specific pages to take notes on meant I couldn't just grab anything to take notes on and archive it with search capabilities.
This seems like it could be nice to tinker with building something similar.
I prefer hand written notes but prefer to be able recall the notes digitally from a search.
How long will Google keep supporting this API, though?
And, it's getting old, but why does Google need to know any notes I write down. My desktop computer and phone seem powerful enough to do any OCR with the right software.
I don't want to have to use a Google account and to share my images and notes and text with Google and the US government.
Also - I agree with other commenters that it'll probably be a better idea to obtain the "unparsed" markup (or should I say - markdown?) rather than generating HTML.
{kind=link}
{kind=link}
I wrote this app to scan the labels and read them out loud so my grandpa can manage his life.
https://www.helpmereadthis.com/
It’s open source, so feel free to steal code.