Imagine you are a junior software developer who is entering a relatively large and complex project with 150,000 lines of code. It is not some web software, but something way more complex, say an embedded system, or a navigation system, or a digital camera, or maybe a complex device for medical imaging. It is a lot of code in different languages. What you know is that the major aspects are working but there still might be some problems.
And of course, management is eager for you to get stuff up and running, as the project is already severely delayed, needs to be shipped as soon as possible, and the customers and investors are getting impatient.
There is only one problem - all the three senior engineers which were working on the codebase have left suddenly, only their manager is still there, and you have to start with reading and understanding the code, and what needs to be done. It is somewhat commented, but, of course, it is not easy to understand. And as it looks, the previous developers did not had any time to leave you proper technical documentation! What are you going to tell the manager?
But then, suddenly, a fairy godmother appears, which has a magic wand in her hand. It is a kind and witty documentation fairy, and she says: "I will fulfil you a single wish. By my magical powers, I will give you exactly the documentation which you think is most important. It can be anything you want. Anything! The only condition is, it must not be more than a good software developer can produce in a month."
What do you wish for?
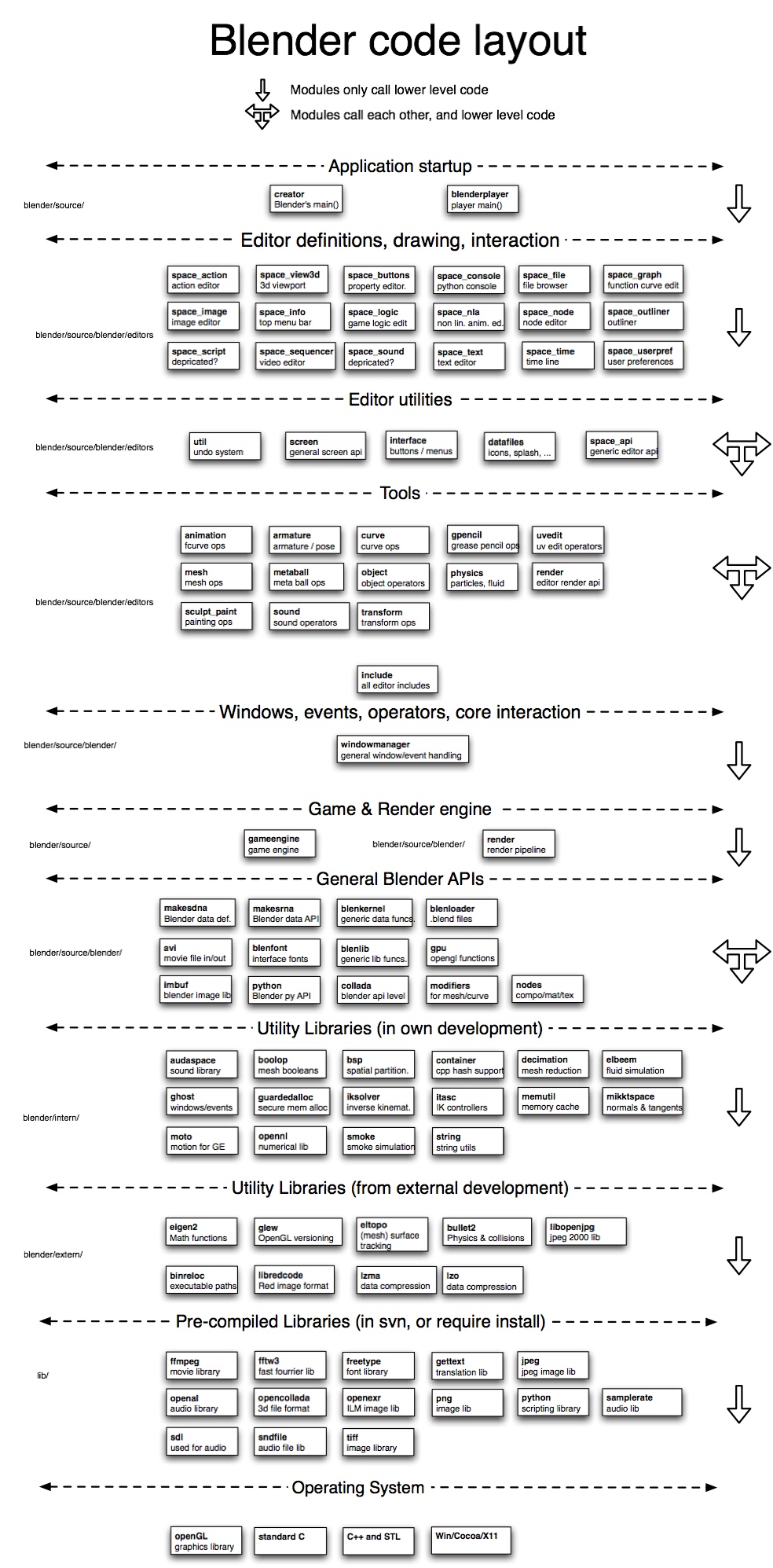{kind=link}
* Glossary for any special terminology that can't just be googled - especially project specific terminology that may be confusing, and double especially terms or phrases which are used slightly differently to the way everybody else uses them (e.g. 'user' means something slightly different almost everywhere).
* Lots of "why" describing why the software behaves in ways that seem surprising at first glance.